SWE-chat: 実際の開発者はAIコーディングエージェントをどう使っているのか?
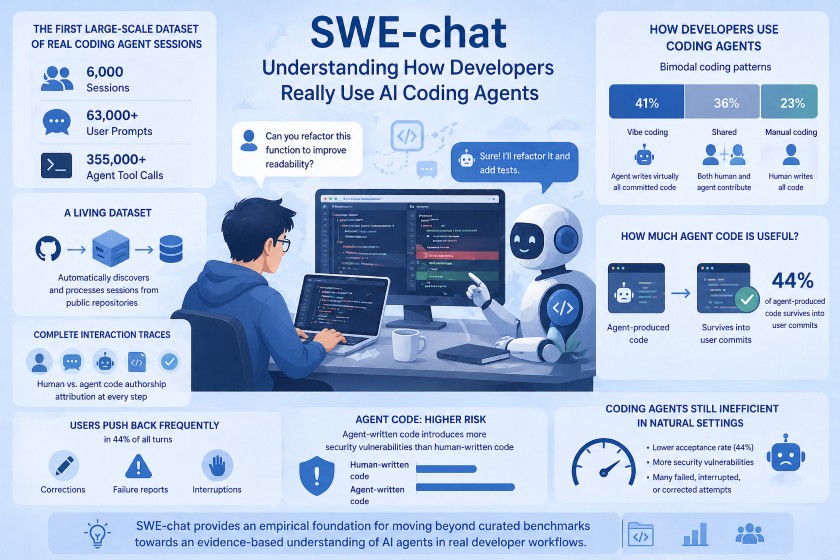
AIコーディングエージェントが急速に普及していますが、実際の開発現場ではどのように使われているのでしょうか?この記事では、現実の利用実態を分析した初の大規模データセット「SWE-chat」から、実践的なインサイトを紹介します。用意されたタスクを解く理想的なベンチマークとは異なり、「開発者がどこでエージェントに頼り、どのような失敗を経験し、どう対処しているのか」というリアルな姿を紐解きます。
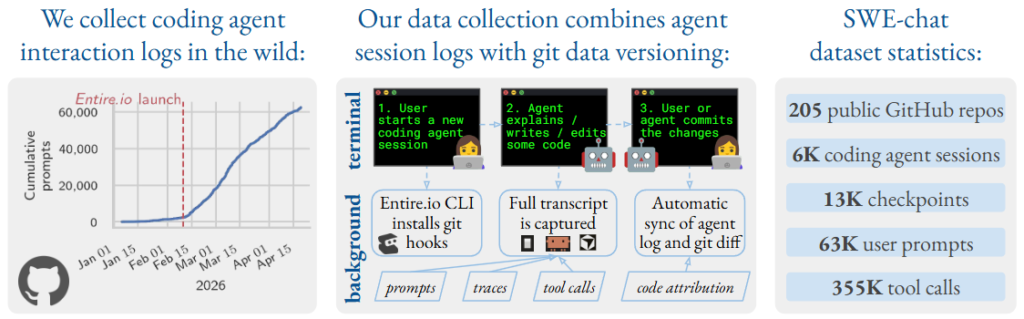
このデータセットは、Entire.ioというCLIツールを導入し、データ収集に同意(オプトイン)したパブリックGitHubリポジトリの開発者から集められています。SWE-smithなどの既存データセットと比較すると、SWE-chatは「ユーザーのプロンプト」や「行レベルでの人間とAIのコードの帰属(どちらが書いたコードか)」までを含めて詳細なやり取りを記録している点が最大の特徴です。これらを踏まえ、AIコーディングエージェントの実態に迫っていきます。
1. エージェントの役割
AIコーディングエージェントと聞くと、まずは「自動でコードを書いてくれる機能」を思い浮かべるかもしれません。しかしながら、実際の開発現場では、もっと様々な用途でエージェントが利用されています。データセット「SWE-chat」の分析から、次のような実態が確認できます。
- 一般的なタスクは「コードの理解」: ユーザーがエージェントに投げかける指示(プロンプト)の意図を分析すると、最も多かったのは「新規コードの作成(Create: 13.4%)」ではなく、「既存コードや挙動の理解(Understand: 19.0%)」です。開発者は、複雑な既存システムの仕様を読み解いたり、他人の書いたコードを解読したりするために、エージェントの力を借りて開発を進めていることがわかります。
- 多用されるBashコマンド: エージェントが裏側で呼び出しているツール(API)のうち、約3分の1はファイルの読み書きではなく、Bashによるコマンド実行が占めています。その中でも特にGitの操作が多く使われています。
さらに、バグの修正(Debug: 13.0%)やルーチン的なGit操作(Git: 13.4%)など、日常的な開発業務全般にエージェントが利用されていることも判明しています。
つまり、現在のAIコーディングエージェントは、単なるコード生成マシーンではなく、コードの解読からバージョン管理まで、開発のあらゆる場面をサポートするツールとして定着しつつあると言えます。理想化されたベンチマークテストではコード生成能力ばかりが注目されがちですが、こうした「日常のサポート業務」への適応力も、今後のエージェント開発において非常に重要な観点となります。
2. コーディングスタイル
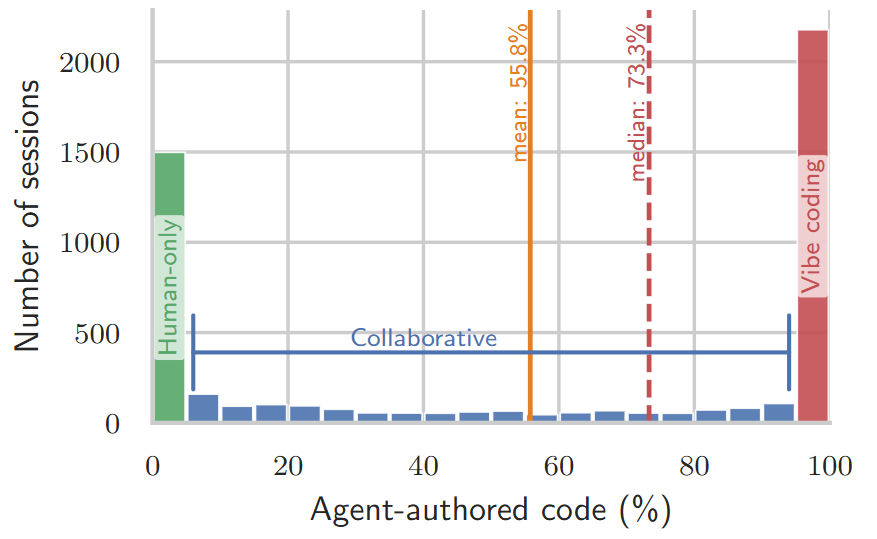
AIエージェントをどのようにコーディングへ組み込んでいるかという点についても、データから興味深い実態が確認できます。コミットされたコード全体においてAIが記述した割合を分析すると、実際の開発現場での利用状況は大きく以下の3つのモードに分類できます。
- 人間のみ(Human-only – 22.7%): 最終的なコードはすべて人間が書き、AIはコードの理解やデバッグ、Git操作などを支えるアシスタントとしてのみ活用するスタイル。
- 協働コーディング(Collaborative – 36.5%): 人間とAIが共同でコードを書き上げるスタイルで、AIの記述割合は 0~99%に収まる。
- バイブコーディング(Vibe coding – 40.8%): コミットされるコードの実に99%以上をAIに記述させるスタイル。
この中でも特に注目すべきは、コーディング作業をAIにほぼ任せ切る「バイブコーディング」の急激な普及です。データ収集を進めた3ヶ月という短い観察期間内だけでも、このスタイルを採用するセッションの割合は約20%から40%超へと倍増しています。
これは、開発者が「部分的にAIにコードを書かせる」段階から、「まずはAIにすべて書かせ、人間がその結果を監督する」という新しい開発スタンダードへと移行しつつあることを示唆しています。中途半端に作業を分担するのではなく、AIの利用スタイルは明確な「二極化」が進んでおり、開発現場におけるエージェントへの依存度は日々高まっていると言えそうです。
3. ユーザーの行動パターン
AIと開発者は、実際にはどのようにコミュニケーションをとっているのでしょうか?データセットのやり取りを分析すると、AIが自律的にタスクを進めているように見える裏側で、開発者が細かく軌道修正を行っている泥臭い実態が浮かび上がってきます。
- 最も一般的なペルソナは「専門家的な粗探し役」: ユーザーの行動特性を分類したところ、最も多数を占めたのは「専門家的な粗探し役(Expert nitpicker)」です。このタイプのユーザーは、最初に決めた目標を変えることなく、AIの出力に対して反復的かつ緻密に「ここはこう直して」「この実装は違う」と細かな修正指示を出し続けます。興味深いことに、AIにほぼすべてを任せる「バイブコーディング」であっても、約半数のユーザーがこの振る舞いを見せています。
- エージェントからの「低い質問率」: AI側の自発的なコミュニケーションは非常に少ないのが現状です。AIが自ら処理を一時停止し、ユーザーに質問や確認を行う(AskUserQuestion)割合は、全体のターンのうち2%未満にとどまっています。AIは確信がないまま作業を進めてしまう傾向があると言えます。
- ユーザーからの「高い介入率」: AIからの質問が少ない一方で、ユーザーは積極的に介入して軌道修正を図っています。ユーザーが自らAIの処理を中断させる割合が約5%、AIの出力に対する修正指示や拒否、エラー報告といった「ダメ出し(Pushback)」を行う割合が約39%に上ります。これらを合わせると、ユーザーは全ターンの約44%において、自らの手でAIの作業に介入していることになります。
このように、実際の開発者は「AIに指示を出して待つだけ」の受動的な存在ではありません。現状のAIコーディングエージェントは、エラーや認識のズレを自己修復する能力がまだ十分ではないため、人間による絶え間ない監視と緻密なフィードバックが不可欠な状態だと言えます。

4. 生成コードの定着率と消費コスト
エージェントとのセッションの多くは成功に終わりますが、その裏で消費されているコストやコードの定着率には課題が残されています。データから見えてきた効率に関する実態は以下の通りです。
- 大半は成功するが、失敗要因は明確: セッションの全体的な成功率は左に偏った(left-skewed)分布を示しており、大半の要求は適切に処理されています。一方で成功率が極端に低いケースでは、「ユーザーによる早期の中断」や「要求と全く無関係なコミットの生成」が主な原因となっています。
- コードの生存率は半分以下: エージェントが生成したコードのうち、最終的にユーザーのコミットに採用されて生き残る割合は、全体でわずか44.3%にとどまります。
- バイブコーディングの非効率性: AIにほぼすべてを任せるバイブコーディングは、実は最も非効率な利用モードです。100行のコードをコミットするのに必要なリソースを比較すると、人間とAIが分担する「協働コーディング」の約3倍の「トークン数」と「コスト」を消費しています。さらに時間の観点でも、協働コーディング(中央値4.8分)より遅く(中央値12.6分)、リソースを大きく消費することが分かります。
- 自律稼働時間の長期化: 1ターンあたりの自律稼働時間の中央値は1分未満と安定しているものの、極端に長い稼働時間(99.9パーセンタイル)は増加傾向にあります。最近では100分を超えてエージェントが自律稼働を続けるケースも出てきています。

5. セキュリティ上のトレードオフ
AIにコーディングを大きく委ねる「バイブコーディング」の普及は、開発スピードを上げる一方で、深刻なセキュリティリスクという影を落としています。データセットの静的解析(Semgrepによる検証)から、AIが生成するコードの安全面におけるトレードオフが浮き彫りになりました。
- 高い脆弱性の導入率: AIにほぼすべてを任せるバイブコーディングによってコミットされたコードは、1,000行あたり0.76件の新たな脆弱性を生み出しています。これは、人間のみが書いたコード(0.08件)の約9倍、人間とAIが協働したコード(0.14件)の約5倍という非常に高いペースです。AIは既存の脆弱性を修正する割合も高いものの、それ以上に新たな脆弱性を生み出してしまっているのが実態です。
- 具体的な脆弱性パターン: 検出された脆弱性の中で最も多数を占めたのは、「サニタイズされていないJavaScriptのパス結合(JavaScript path joining without sanitization)」でした。また、外部からの入力を無害化せずにOSのコマンドとして実行してしまう「OSコマンドインジェクション(CWE-78)」や、「SQLインジェクション(CWE-89)」といった、重大なインシデントに直結するパターンも多数確認されています。たとえば、Pythonの機能(
subprocess.runなど)を利用する際に、ユーザー入力をそのまま文字列として結合して実行してしまうような不用意な実装が、AIによって生成されるケースが報告されています。
AIエージェントは自身の出力に確証が持てない場合でも、自発的にユーザーへ警告を発することはほとんどありません。そのため、AIへの依存度が高まれば高まるほど、コードに潜む危険な実装パターンを見逃さず検知する負担は、すべて人間の開発者に重くのしかかってくることになります。
| Coding mode | Vulnerabilities fixed (per 1K lines) | Vulnerabilities introduced (per 1K lines) |
|---|---|---|
| Human-only | 0.04 | 0.08 |
| Collaborative | 0.08 | 0.14 |
| Vibe coding | 0.52 | 0.76 |
| Overall | 0.06 | 0.11 |
6. これからのAIコーディングエージェント
これまで見てきた通り、エージェントが自発的に質問してくる割合がわずか2%未満であるのに対し、ユーザー側は全体の約44%のターンで介入や拒否をして軌道修正を図っています。この圧倒的な非対称性は、AIが「いつ人間に助けを求めるべきか」を学習するよりも早く、単独で作業を進める能力ばかりを高めてしまった現状を示唆しています。
この問題の大きな原因は、既存のAI評価指標(ベンチマーク)が現実の開発環境を正しく反映していないことにあります。現在のベンチマークの大半は、用意された課題に対して「単発(One-shot)で新規パッチを生成する」能力の測定に偏っています。しかし、これまでのデータが示す通り、実際の開発者のワークフローは「既存コードの理解」が中心であり、かつ「反復的なマルチターン」で作業が進んでいくという実態を完全に見落としています。
こうした現実とのギャップを埋め、より優秀なエージェントを構築していくためには、今後の研究開発において以下の3つの方向性が重要になります。
- 現実のワークフローに基づくベンチマークの作成: コードの解読や複数回にわたるやり取りなど、実際の開発現場での使われ方に即した新たな評価基準を作成してテストを進めること。
- より適応的なインタラクション設計: ユーザーが絶えず監視や「小言」の負担を負うのではなく、AI側から適切なタイミングで確認を促すなど、人間とエージェント間のより良いやり取り(Human-agent interaction)をデザインすること。
- ユーザーシミュレーターの開発: 人間による手動テストのコストを下げるため、現実の開発者のような「緻密な修正指示」を再現できるオフライン評価用のAIシミュレーターを開発すること。
おわりに
SWE-chatのデータが示す通り、AIコーディングエージェントは強力なツールですが、完全な自律稼働にはまだ至っていません。現時点では、AIにコード執筆をほぼ丸投げする「バイブコーディング」よりも、人間とAIが適切に役割を分担する「協働コーディング」の方が、時間・コスト・セキュリティのすべての面で圧倒的に効率的です。
これは裏を返せば、「ソフトウェア開発の専門知識がない人材が、AIに完全に任せてシステムを作れる」段階にはまだないことを意味します。実務でエージェントを最大限に活用するには、夢のような完全自動化を期待するのではなく、出力結果に対する継続的な監視と、反復的な修正作業を前提としたワークフローを設計することが不可欠です。
More Information
- arXiv:2604.20779, Joachim Baumann et al., 「SWE-chat: Coding Agent Interactions From Real Users in the Wild」, https://arxiv.org/abs/2604.20779
関連記事

UnslothではじめるLLMのFine-tuning
大規模言語モデル(LLM)を特定のタスクやドメインに特化させる「ファインチューニング」。その可能性に多くの開発者が惹きつけられる一方で、「膨大な計算コストがかかる」「高性能なGPUがなければ手も足も出ない」といった高いハ […]

Deep Research 完全ガイド: 自律型LLMエージェントとアーキテクチャ
近年、大規模言語モデル(LLM)は、単にテキストを生成するだけでなく、複雑な問題解決を可能にする強力なエージェントへと急速に進化しています。しかし、現実世界の多くのオープンエンドなタスクは、単一のプロンプトや標準的なRA […]

NGBoost – 機械学習における確率分布推定のブースティングアルゴリズム
近年、機械学習は様々な分野で重要な役割を果たしており、その応用範囲はますます広がっています。特に、回帰問題において、従来の機械学習モデルは、与えられた特徴量に基づいて単一の「最も可能性の高い」予測値、つまり点推定を返すこ […]