Tool-Overuse: なぜLLMは内部知識よりも外部ツールを好むのか?

最近、LLMを利用したシステムを開発する中で、「内部知識で答えられるはずの簡単な質問なのに、なぜか外部APIを叩いてレスポンスが遅くなっている」と感じたことはないでしょうか?
LLMが外部ツールを呼び出して問題を解決する仕組みは、「ツール統合推論(TIR: Tool-Integrated Reasoning)」と呼ばれ、モデルの能力を拡張する非常に強力なアプローチです。しかしその一方で、モデルの内部知識だけで解決できる問題に対して不要なツールを実行したり、情報的価値のない無関係なツールを呼び出したりする「ツール過剰利用(Tool-Overuse)」という新たな課題が浮上しています。
この現象を放置すると、回避できたはずのAPIコストの増加やレイテンシ(遅延)の悪化を招き、システムの効率を大きく損ねてしまいます。そこでこの記事では、なぜLLMが自身の知識よりも外部ツールを好んでしまうのか、その根本的なメカニズムを解説します。さらに、この過剰利用を防ぎ、効率的なシステムを構築するために提案されている手法として、知識を考慮した学習手法(K-DPO)やバランス型報酬(Balanced Reward)を紹介します。
1. ツール過剰利用の現状とモデル別の傾向
LLMが外部ツールを利用する際、具体的にどのような「過剰利用」が発生しているのか、まずは現状の課題を整理し、様々なモデルにおいてどのような傾向が見られるのかを確認していきます。
過剰利用の2つのタイプ
ツール過剰利用には、大きく分けて以下の2つのタイプが存在します。
- 冗長な利用(Redundant usage): モデル自身の内部知識だけで十分に解決できる簡単なタスクであるにもかかわらず、外部ツールを呼び出してしまうケースです。これにより、不必要な遅延(レイテンシ)が発生してしまいます。
- 無関係な利用(Irrelevant usage): モデル自身の推論能力が不足している部分を補おうと幻覚(ハルシネーション)を起こし、タスクに全く関係のないツールを呼び出してしまうケースです。これは情報としての価値を生まず、コンテキストの負担を増やすだけになってしまいます。

簡単なタスクにおける弊害
この過剰利用は、特に「簡単なタスク」において深刻な弊害をもたらします。内部知識で解ける簡単な問題に対してツールを呼び出すと、追加された不要なコンテキストがノイズとして働き、モデル本来の自然な推論プロセスを妨げてしまいます。
その結果、ツールを使わずに回答した場合と比較して、正答率が平均で3.29%〜14.48%も低下することが実験により確認されています。本来なら正解できたはずの問題を、不必要にツールに頼ったことで間違えてしまうのです。
モデルごとの傾向の違い
さらに、ツールの過剰利用の度合いは、モデルの学習手法や種類によっても異なります。
- RLVR(強化学習)モデルの罠: ツール利用能力を向上させるために強化学習(RLVR: Reinforcement Learning with Verifiable Rewards)を適用して構築されたモデルは、オープンソース(OSS)のベースモデルと比較して、ツールの呼び出し回数が約65%も増加しています。ツールを活用するように最適化された結果、かえって過剰利用が悪化しやすい傾向にあると言えます。
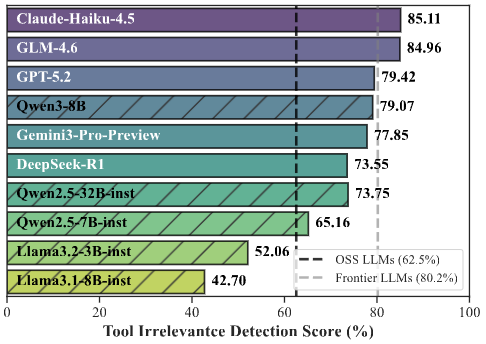
- 最先端(Frontier)APIモデルの限界: 優れた内部能力を持つ最先端のAPIモデルは、OSSモデルよりもツール呼び出しの頻度自体は低く抑えられています。しかし、質問に対して提供されたツールがすべて無関係な場合であっても、最先端モデルは約19.8%の割合で誤って無関係なツールを呼び出してしまうエラーを起こします。なお、OSSモデルではこのエラー率が約37.5%にまで跳ね上がるため、より注意が必要です。
つまり、どんなに高性能なモデルであっても、現在の仕組みのままでは「ツールの無駄遣い」を完全に防ぐことはできていないのが実態です。
2. なぜ過剰利用が起きるのか?
なぜ優秀なはずのLLMが、このような「ツールの無駄遣い」をしてしまうのか、最近の研究から、その背景には大きく分けて2つの根本的なメカニズムが潜んでいることが明らかになっています。
知識の認識的錯覚(Knowledge Epistemic Illusion)
1つ目の原因は、モデルが自身の実際の能力(内部知識)を正しく把握できていないという「認識的錯覚」です。人間で例えるなら、「実は知っているのに、自信がないからとりあえずスマホで検索してしまう」ような状態です。モデルは「自分がどこまで知っているか」の境界を誤認し、外部ツールに盲目的に依存してしまいます。
この現象を確認するため、最近の研究では avg@1024 という指標を用いてモデルの内部知識が測定されています。この指標は、「ツールを一切使わずに1024回独立して回答を生成させた際の正解率」を表す指標です。この数値が1に近いほど、モデルがその問題に対する十分な内部知識を持っていることを意味します。
直感的には、この指標が高い(=自分の中の知識で答えられる)問題ほど、外部ツールを利用する頻度は下がると予想されます。しかしながら、実際の検証では内部知識が豊富な領域でもツールの呼び出し頻度はほとんど減少しませんでした。
さらに深刻なことに、avg@1024が 0.8 や 0.9 を超えるような「内部知識だけで十分に正解できる領域」において外部ツールを呼び出すと、かえってパフォーマンスが低下する現象も確認されています。不要な外部情報が推論のノイズとなってしまい、本来の自然な推論プロセスを妨げてしまうためです。

2.2 結果偏重の報酬トラップ(Outcome-Reward Trap)
2つ目の原因は、モデルを賢くするための「学習方法」そのものに潜む罠です。
現在、ツールを利用する能力を向上させるために、主流な手法としてRLVR(検証可能な報酬を用いた強化学習)という学習方法が採用されています。しかし、この手法の多くは「最終的な答えが合っているかどうか」のみを報酬として評価(最適化)しています。つまり、答えにたどり着くまでの「プロセスの効率性」や「APIの呼び出しコスト」が無視されています。
この問題を可視化するため、課題解決に必要な「最小限のツール呼び出し回数の理論的な上限」を tool@1024 と定義して検証が進められました。
結果として、RLVRによる学習が進むにつれて、モデルのツール呼び出し回数は急激に増加していくことが分かりました。そして最終的には、合理的な上限であるはずの tool@1024 を優に超え、無駄な呼び出しを繰り返すようになってしまいます。
正解にたどり着けばどんなにツールを無駄遣いしても「正解」として高い評価が与えられるため、モデルは「とにかくたくさんツールを使えば良い」という間違った学習を進めてしまうのです。
3. 理論的背景と対策
これまでに紹介した過剰利用のメカニズムを、数学的な意思決定のモデル(理論的背景)から紐解いてみます。なぜLLMは自らツールの過剰利用に陥ってしまうのか、そこには以下の2つの構造的な問題が潜んでいます。
- 構造的な不均衡(Structural Imbalance): 理想的なLLMのツール呼び出しは、「正解したときの報酬」から「推論にかかったコスト(API呼び出しや遅延)」を差し引いた「全体の利益(ユーティリティ)」を最大化するように最適化されます。しかし、現在の主流な学習パラダイムでは、推論コストに対するペナルティが設定されていません。このペナルティが存在しない場合、数学的に見ると、ツールを使用することで正解確率がほんのわずか(たとえば \(10^{-4}\) 程度)でも上がるのであれば、無制限にツールを呼び出すことがモデルにとっての「合理的な最適解」となってしまいます。
- モデルの自信のズレ(Miscalibrated Confidence): 本来であれば、モデルは「自分の内部知識で正解できる確率」と「ツールを使った場合の正解確率」を比較して、ツールを使うべきかを決定するべきです。しかし、LLMは自身の内部知識による正解確率を過小評価する一方で、外部ツールの結果を過大評価(ほぼ100%正しいと過信)してしまうという「キャリブレーションのズレ」を起こしています。この自信の歪みが、先述した「知識の認識的錯覚」を引き起こし、不要なツール呼び出しをさらに加速させてしまいます。
システム設計における対策
こうした理論的背景を踏まえると、AIエージェントやシステムを構築する際には、「LLMが提示する自信(予測確率)は、実際の能力と大きくズレている」という前提に立つ必要があります。
単純にモデルへ強力なツールを渡して自律的な判断に任せるのではなく、この自信と実際の正答率のズレを定期的にモニタリングすることが重要です。そして、無制限な呼び出しを抑制するために、システム側でツール実行に対する明確なペナルティ(コスト評価の係数)を導入したり、実行判断の閾値を適切に設定したりするなどの対策が求められます。
4. ツール過剰利用をいかに防ぐか
ここまでの解説で、ツール過剰利用の背後にある「知識の認識的錯覚」と「結果偏重の報酬トラップ」という2つの原因が見えてきました。では、LLMシステムを構築・調整する際、具体的にどうすればこの過剰利用を防ぐことができるのか、近年の研究で有効性が確認されている2つの実践的なアプローチを紹介します。
知識を考慮したDPO(K-DPO)の適用
1つ目の対策は、モデルの「実際の知識の限界」と「自身が認識している限界」のズレを学習によって修正するアプローチです。これを実現するために、K-DPO(Knowledge-aware Direct Preference Optimization: 知識を考慮した直接的選好最適化)という手法を適用します。
具体的には、同じ質問プロンプトに対して、以下の2つの出力(軌跡)をペアにしたデータを作成し、モデルに学習させます。
- 好ましい出力(Preferred): ツールを全く使わない、あるいは最小限(0〜1回)の利用で正解にたどり着いたプロセス。
- 好ましくない出力(Dispreferred): 内部知識で解けるにもかかわらず、過剰にツールを呼び出して正解したプロセス。
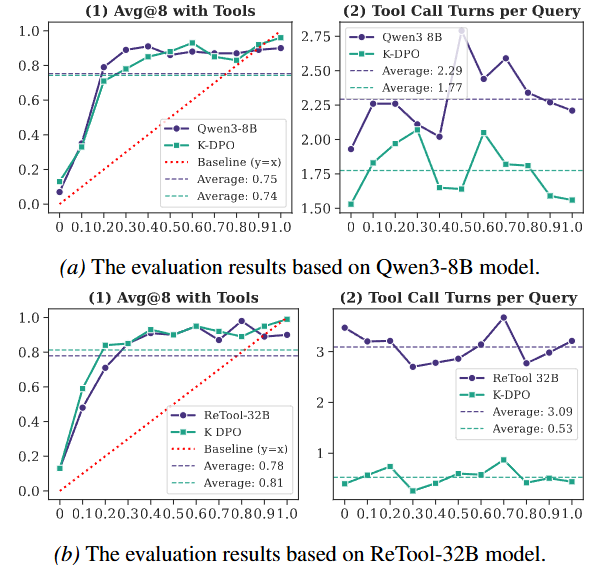
この手法を適用することで、モデルは「自分の知識を信じて自力で回答すべきタイミング」を正しく把握できるようになります。実際の検証では、ある32Bパラメータのモデルにおいて、ツール利用ターン数を82.8%も大幅に削減することに成功しています。さらに、不要なツール呼び出しが減ってコンテキストのノイズが軽くなった結果、全体的な正答率も約3%向上することが確認されています。
効率性を加味したバランス報酬(Balanced Reward)の導入
2つ目の対策は、モデルを賢くするための強化学習のルール(報酬関数)を再設計し、「結果さえ合っていれば良い」というトラップを回避するアプローチです。
従来の学習では最終的な正解に対してのみ報酬を与えていましたが、バランス型報酬(Balanced Reward)では、最終的な正解への報酬(例: +1)に加えて、ツールを1回呼び出すごとに小さなペナルティ(例: -0.05)を課すように設定します。これにより、モデルは「正解を導き出すこと」と「無駄なツール呼び出しによるコストを避けること」のバランスを取りながら推論を進めるようになります。
このバランス報酬を導入した結果、モデルの正答率(評価精度)を犠牲にすることなく、不要なツール呼び出しのターン数を7Bモデルで約66.7%、32Bモデルで約60.7%削減できることが実証されています。ツールへの過剰な依存から脱却し、より効率的で自律的なエージェントを構築するための非常に有効な手段と言えます。

おわりに
LLMエージェントへのツール統合は、モデルの能力を大きく拡張する強力なアプローチです。しかし、この記事で見てきたように、推論コストを考慮せずにシステムを設計してしまうと、理論的にも構造的にも過剰利用に陥るリスクを抱えています。
この課題を乗り越えるためには、まず avg@1024 や tool@1024 といった指標を用いて、システムの挙動や知識の限界を客観的に測定することが重要です。その上で、K-DPOやバランス型報酬(Balanced Reward)といった実践的な手法を適用し、「コスト意識」をモデル自身にしっかりと学習させる必要があります。
自身の内部知識への信頼と、外部ツールへの依存のバランスを適切に取る仕組みを取り入れること、それこそが無駄なAPIコストや遅延を抑え、実用的でスケーラブルなAIエージェントを構築するための鍵となります。
More Information
- arXiv:2604.19749, Yirong Zeng et al., 「The Tool-Overuse Illusion: Why Does LLM Prefer External Tools over Internal Knowledge?」, https://arxiv.org/abs/2604.19749
関連記事

Lightlyで実践 - 自己教師あり学習入門
近年、機械学習プロジェクトで扱うデータ量は増大し続けています。しかし、その膨大なデータすべてに手作業でアノテーション(教師ラベル付け)を行うのは、コストと時間の面で大きな課題です。この「アノテーションの壁」を乗り越える技 […]

Neuro-Symbolic AI: ブラックボックス時代における信頼性と論理の融合
現在の自然言語処理(NLP)やコンピュータビジョン(CV)の分野では、深層学習モデルが目覚ましい成果を上げています。しかし、これらのモデルはデータ効率の悪さや予測の根拠(説明性)が不透明であるという根本的な課題を抱えてい […]

ディープラーニングモデルの量子化: PyTorchによる実践解説
近年、ディープラーニングは画像認識、自然言語処理、音声認識など、多岐にわたる分野で目覚ましい成果を上げています。しかし、これらの高精度なモデルは、しばしば膨大なパラメータ数を持ち、その結果として大きなメモリ消費量や計算コ […]