宇宙物理学研究の新たなパラダイム: AIサイエンティストと Human-in-the-Loop
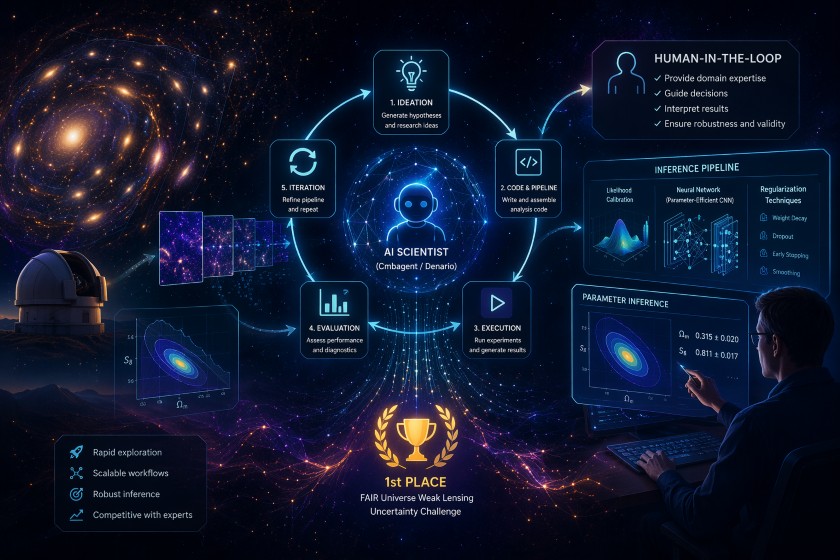
現代の宇宙物理学におけるデータ解析は、データ表現やモデルの構造、最適化戦略といった高次元の「方法論的設計空間」を人間が網羅的に探索することが困難になっています。そのため、大規模言語モデル(LLM)を活用した自律型エージェントによる研究支援が、新たなアプローチとして注目を集めています。
この記事で取り上げる「弱い重力レンズ効果」のパラメータ推定コンペティションも、そうした複雑な探索を要する課題の一つです。このタスクは、ノイズを含む限られたデータ(低データ領域)からパラメータの点推定を行うだけでなく、「適切に較正された不確実性の定量化(Uncertainty Quantification)」を同時に達成することが求められる特殊な設定となっています。
ここでは、『Competing with AI Scientists: Agent-Driven Approach to Astrophysics Research』を参考に、AIエージェントと人間がどのように協働し、最高水準の研究パイプラインを構築したのか、その重要なトピックと実践的な観点を紐解いていきます。
1. パラメータ推定コンペティションの概要
前提となる基本概念
本題に入る前に、対象となる物理現象と技術について簡潔に整理します。
- 弱い重力レンズ効果 (Weak Gravitational Lensing): 遠くの銀河から発せられた光が、観測者に届くまでの間に存在する物質の重力によって曲げられる現象です。歪みのあるガラス越しに景色を見る状況を想像すると分かりやすいかもしれません。このわずかな光の歪みを統計的に測定することで、宇宙の物質の不均一な分布を探ることができます。
- LLMとAIエージェント: 大規模言語モデル(LLM)は膨大なテキストデータを学習し、文脈に応じた文章を出力するAIです。AIエージェントは、このLLMを「頭脳」として組み込み、目標に向けて自律的に計画を立て、プログラムの記述・実行や結果の評価といった様々なツールを操作しながらタスクを進めるシステムを指します。
推論の全体像
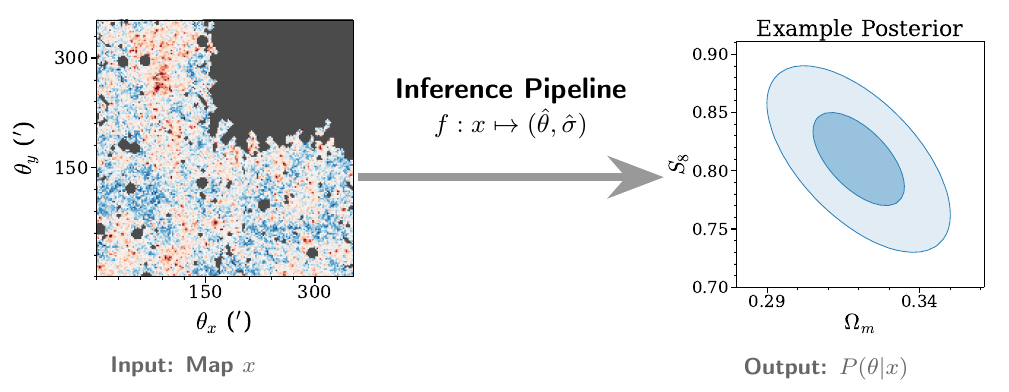
今回のコンペティション(FAIR Universe Weak Lensing Uncertainty Challenge)では、ピクセルレベルのノイズを含む弱い重力レンズ効果のシミュレーションマップ(画像データ)を入力として扱います。構築する推論パイプライン \(f\) の役割は、この入力マップ \(x\) から、以下の2つの重要な宇宙論パラメータを推定することです。
- 物質密度 \(\Omega_m\): 宇宙全体に占める物質の割合
- クラスタリング振幅 \(S_8\): 物質密度のゆらぎの大きさ
単にこれら2つのパラメータの点推定値(予測値)\(\hat{\theta} = (\hat{\Omega}_m, \hat{S}_8)\) を出力するだけでなく、予測の不確実性(標準偏差)\(\hat{\sigma} = (\hat{\sigma}_{\Omega_m}, \hat{\sigma}_{S_8})\) を同時に出力し、最終的にパラメータの事後分布を導き出す一連の流れを構築します。
最適化のターゲット(評価指標)
このタスクの最も特殊な点は、モデルの性能を評価する「スコア関数」の設計にあります。単に予測値と正解の誤差を小さくするだけでは高得点を得られません。
コンペティションのスコア関数は、点推定の正確さと、予測された不確実性の較正(キャリブレーション)の両方を同時に評価するように設計されています。具体的には、以下の2つの要素を組み合わせた「Modified Kullback-Leibler (KL) Divergence」として定式化されています。
- 不確実性に対するペナルティ(ガウス対数尤度): 予測した不確実性の分布が真の分布からどれほどズレているかを評価します。予測にバイアスがある場合や、不確実性の見積もりが甘い(あるいは過剰である)場合にペナルティを与えます。
- 点推定の平均二乗誤差(MSE): 予測値自体のズレを評価する項であり、精度の低い点推定に対して強いペナルティ(重み付け \(\lambda = 10^3\))を課します。
AIエージェントは、この複雑なスコア関数を最大化するような推論パイプライン \(f^*\) を、高次元の設計空間の中から自律的に探索するという難題に取り組むことになります。
2. エージェントの自律的探索とその限界
前章で触れた複雑な設計空間を探索するため、マルチエージェントシステム「Cmbagent」を導入します。ここでは、エージェントがどのように自律的な探索を進めるのか、その仕組みと直面した限界について解説します。
エージェントの仕組みと動作モード
Cmbagentは、タスクの性質に応じて主に以下の2つの動作モードを使い分けます。
- One-Shotモード: コード生成などを担う特定のエージェント(例えばエンジニア役)に直接タスクを割り当てるモードです。コードの生成と実行のサイクルを、終了条件を満たすまで集中的に繰り返します。
- Planning & Controlモード: より複雑なタスクに対応するためのモードです。まずプランナーとレビュアーが複雑な研究タスクを小さなサブタスクに分解して計画を立てます(Planning)。その後、コントロール機能が複数の専門エージェントを管理し、それぞれのサブタスクを順次実行していきます(Control)。
自律的リサーチ・ループ
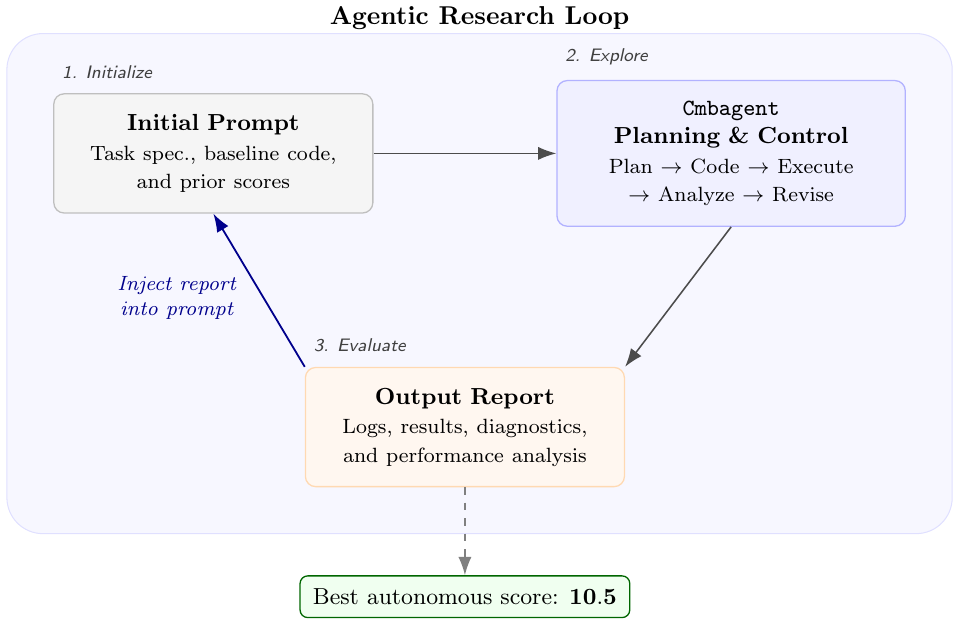
自律的なパイプラインの探索は、主に「Planning & Control」モードを用いて進められました。具体的には、以下のような自律的リサーチ・ループを構築しています。
- 初期設定: タスクの仕様やベースラインとなるコード、過去のスコアなどをプロンプトとして与えます。
- 実行サイクル: エージェントは「計画(Plan)→ コーディング(Code)→ 実行(Execute)→ 分析(Analyze)→ 修正(Revise)」というサイクルを自律的に回します。
- プロンプトへのフィードバック: 実行後に出力される分析レポート(ログやエラー診断、パフォーマンスの評価など)を次の初期プロンプトに組み込み、再び探索ループを開始します。
このように、過去の失敗や分析結果を文脈として保持しながら、エージェント自身が仮説の検証と修正を繰り返す仕組みとなっています。
複数LLMのアンサンブルによる探索空間の拡大
探索をより効果的に進めるための工夫として、単一の言語モデルに依存せず、複数のLLMを組み合わせるアンサンブルのアプローチが採られました。Cmbagentのベースモデルに加え、GPT-5やGemini-2.5、Claude-4.5といった様々なLLMを利用しています。
単一のプロンプトやモデルのみを使用した場合、提案されるパイプラインの設計が非常に狭い範囲のアイデアに偏ってしまう傾向がありました。しかし、多様なLLMに対してアプローチを実施することで、それぞれが異なる視点から提案を行うため、探索できる方法論的設計空間が大幅に拡大しました。
自律探索の失敗傾向と限界
このような高度な自律的リサーチ・ループと複数LLMの活用を実施したにもかかわらず、完全な自律探索だけではコンペティションで上位に入るような専門家レベルの性能には到達しませんでした。
その主な原因は、エージェントが陥りやすい「失敗の傾向」にあります。完全自律の設定に任せた場合、エージェントは層が深くパラメータ数が非常に多い「ResNet」のような非効率な大規模モデルに固執する傾向が見られました。さらに、そのモデルでスコアが伸び悩んだ際、パラメータ効率が良くより適した別の軽量なモデル(代替案)を探索するのではなく、「さらに層の深い大規模なResNetを試す」といったパフォーマンスが飽和した方向へ進んでしまうことが多かったのです。
この結果は、AIエージェントが様々な手法を高速に検証することはできても、「現在の方向性が根本的に有望かどうか」という定性的な評価を行い、自律的に軌道修正することには限界があることを示唆しています。
3. Human-in-the-Loopの重要性
AIエージェントの自律的な探索が限界に直面したとき、人間の専門知識がどのように推論パイプラインを最適化に導いたのか、その具体的なプロセスと採用された手法について解説します。
人間の介入による軌道修正と成果
前章で触れた通り、完全自律探索ではエージェントが非効率な大規模モデルに固執する傾向がありました。そこで人間の研究者が介入し、生産性の低い探索を早期に打ち切り、よりパラメータ効率の良い軽量モデルの採用を促すプロンプトを与えることで、AIの探索の軌道修正を実施しました。結果として、この「Human-in-the-Loop」のアプローチにより見出された最終パイプラインは、「FAIR Universe Weak Lensing Uncertainty Challenge」において他の専門家チームを抑え、1位の性能に到達しました。
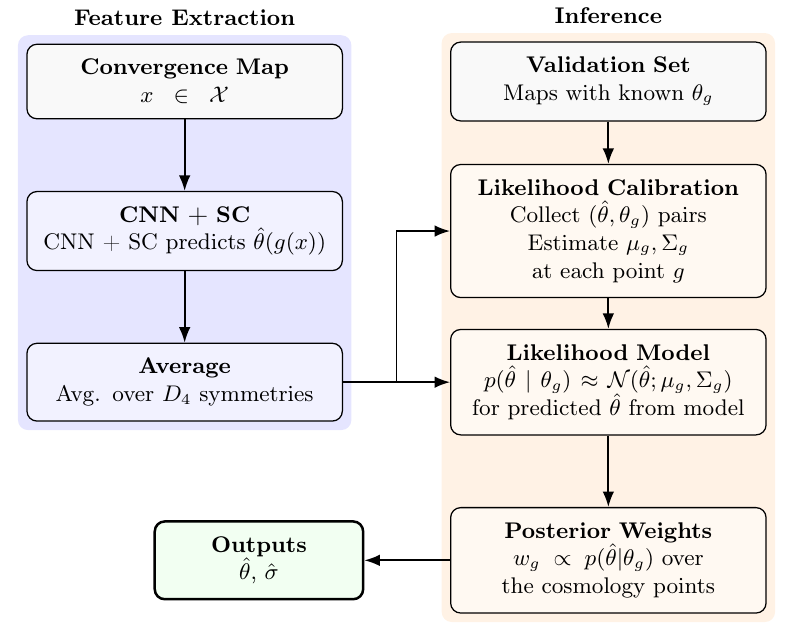
要約統計量としてのCNN予測と尤度較正
見出された最終パイプラインの大きな特徴は、CNN(畳み込みニューラルネットワーク)の出力を直接的な最終推定値としてではなく、「要約統計量」として扱った点です。CNNが予測した生の数値には系統的なバイアスが含まれるため、既知の宇宙論パラメータを持つ検証用データセットを用いて「事後確率の尤度補正(Likelihood Calibration)」を実施しました。各宇宙論パラメータのグリッドポイントにおいて、CNNの予測値がどのように分布するかを経験的に評価し、信頼性の高い不確実性の定量化を達成しています。
軽量CNNのアンサンブルとInceptionアーキテクチャ
限られたデータしか利用できない「低データ領域」において、多数のパラメータを持つ大規模モデル(例えば数十層のResNetなど)は過学習のリスクを高めます。これを防ぐため、パラメータ数の少ない軽量なCNNを複数組み合わせる「アンサンブル」の手法が採用されました。また、宇宙論的推論では、銀河のクラスタリングのような小さなスケールから、コズミックウェブのような大きなスケールまで、様々なスケールの特徴を抽出する必要があります。そのため、サイズの異なる複数のカーネル(フィルタ)を並列に備えた「Inception」アーキテクチャが、このタスクに非常に適していることが示されました。
散乱共分散(SC)を用いたバイアス補正
CNNの予測に内在する系統的なバイアスをさらに低減させるため、「散乱共分散(Scattering Covariances: SC)」に基づく手法が組み込まれました。具体的には、主成分分析(PCA)を用いてSCの次元を大幅に圧縮(630次元から64次元へ)し、その特徴量を入力とする軽量なMLP(多層パーセプトロン)を学習させ、CNNの予測値に対する小さな補正項として加算する工夫を施しています。
D4対称性を用いたデータ拡張(TTA)
低データ領域での性能向上には、データ拡張が極めて重要な役割を果たします。今回のパイプラインでは、訓練時だけでなく推論時(テスト時)にも、画像の回転や反転を含む \(D_4\) 対称性(二面体群)を用いた「テスト時データ拡張(Test-Time Augmentation: TTA)」を実施しています。入力マップに対して様々な対称変換を適用し、得られた複数の予測値をパラメータ空間で平均化することで、予測の安定性と精度を大幅に向上させました。
カーネル平滑化と共分散行列の安定化
尤度補正のプロセスにおいて、有限のデータから得られる経験的な平均や共分散は、統計的なノイズの影響を受けやすくなります。これを抑えるため、パラメータ空間上の近隣の宇宙論ポイント間で情報を平均化する「カーネル平滑化(Kernel Smoothing)」を取り入れました。さらに、金融分野などで用いられるLedoit-Wolfシュリンケージと呼ばれる手法を利用して共分散行列を正則化(安定化)することで、データ不足に起因する見せかけの相関を減らし、より安定した精度の高い推論を実現しています。
4. 限界の認識と今後の展望
今回構築された推論パイプラインはコンペティションで優れた成果を収めましたが、AIエージェントによるアプローチが抱えるいくつかの限界についても考察しましょう。
未知のパラメータ領域での性能低下
構築されたモデルは、学習データに含まれる宇宙論パラメータの組み合わせやその近傍(On-grid)では高い性能を発揮しました。しかし、学習データに存在しない未知のパラメータ領域(Off-grid)に対して推論を実施した際、特に周辺の学習データ密度が低い領域において、精度が大幅に低下することが確認されました。これは、現在のパイプラインがデータ密度の高い領域に強く依存していることを意味しており、あらゆるパラメータ空間で均一に信頼できる推論を行うためには、より網羅的で高密度なシミュレーションデータが必要になるという課題を示しています。

スカラー指標のないタスクへの適用限界
さらに根本的な課題として、今回のコンペティションには最適化の目標となる明確な「スカラーの評価指標(スコア関数)」が用意されていた点が挙げられます。エージェントはこの指標を頼りに様々な手法を比較・検証することができました。しかし、実際の科学的探求において、私たちが直面する問いは必ずしも単一の最適化問題として定式化できるとは限りません。明確な評価指標に還元できない一般的な研究タスクに対して、このようなエージェントシステムをどのように適用し、その結果を評価していくかは、今後の重要な研究テーマとなります。
エージェントの進化の方向性
これらの限界を乗り越え、自律型エージェントをさらに強力な研究パートナーへと進化させるための改善計画を示します。
- 適応的なプランニングの強化: コードの実行結果やエラーからのフィードバックを用いて、エージェントが自身の計画を動的に見直し、反省する機能(反復的プランニング)の導入。
- タスク特化型のサブエージェント: 複雑な問題を分割し、特定のサブタスクに関連する文脈のみを持たせた専門的なサブエージェント(「ContextMaker」など)を必要に応じて生成し、連携させる機能の追加。
こうした機能拡張により、タスクの実行中にエージェント自身が計画を進化させ、より自律的かつ高度な研究支援が可能になると期待されています。
おわりに
今回見てきたように、AIエージェントは自律的に様々な手法を検証できる強力なツールですが、人間の専門家を完全に置き換えるものではありません。むしろ、人間の理解や判断と適切に組み合わせることで、科学的発見を大幅に加速させる「Force Multiplier(能力の増幅器)」として機能します。
限られたデータ領域での軽量モデルのアンサンブル、不確実性の尤度補正、そして物理的対称性を生かしたデータ拡張といった本事例の知見は、他の複雑な推論タスクにも広く応用可能です。このような人間とAIエージェントの協働プロセスや具体的な技術要素を、新たな研究テーマにどのように組み込み、発展させることができるでしょうか。AIを強力な研究パートナーとして迎える、次世代の研究パイプラインをぜひ構想してみてください。
More Information
- arXiv:2604.09621, Thomas Borrett et al., 「Competing with AI Scientists: Agent-Driven Approach to Astrophysics Research」, https://arxiv.org/abs/2604.09621
関連記事

LLM×シンボリック回帰: 科学的発見を加速する次世代アプローチ
観測データから物理法則や数学的関係式を導き出すシンボリック回帰(SR: Symbolic Regression)をご存知でしょうか?従来の手法では、探索空間の組み合わせ爆発や、事前知識をシステムに組み込む難しさが長年の課 […]

PINN入門: 物理法則を組み込んだAIで微分方程式を解く
近年、ディープラーニングの技術は目覚ましい進歩を遂げ、画像認識、自然言語処理、ロボティクスなど、多岐にわたる実世界の問題解決に応用されています。しかし、複雑な物理現象や数学的な問題、特に微分方程式の解決においては、従来の […]

PySR: シンボリック回帰とは何か?
シンボリック回帰(Symbolic Regression、記号回帰とも呼ばれます)は、データを説明する数式を自動的に見つけ出す機械学習手法です。この手法では、関数の形式を事前に決めることなく、与えられたデータに最も合う数 […]