Code as Agent Harness: AIエージェントを自律駆動させるためのアーキテクチャ

LLM(大規模言語モデル)の進化により、AIエージェントの開発が急速に進んでいます。しかし、複雑なタスクを長期間にわたって自律的に実行させるには、自然言語による指示だけでは限界があります。
現在、LLMにとって「コード」はもはや生成される最終成果物ではありません。むしろ、エージェントが推論し、行動し、環境モデリングや検証を実施するための「操作基盤(Operational Substrate)」へとパラダイムシフトが起きています。コードには、自然言語にはない「実行可能(Executable)」「観察・調査可能(Inspectable)」「状態保持(Stateful)」という3つの特性があります。これらの特性が、エージェントの長期にわたる信頼性を担保する足場(Harness)として機能します。
この記事では、スタンフォード大学などの研究者らが発表した論文『Code as Agent Harness』を元に、この新しい設計思想を紐解きます。具体的には、(1)LLMと環境を繋ぐ「インターフェース」、(2)自律稼働を支える「メカニズム」、(3)マルチエージェントへの「拡張」という3つのレイヤーから、エージェント設計の全体像を解説します。
1. LLMと環境を繋ぐ「Harness Interface」
AIエージェントに複雑なタスクを自律的に進めさせるためには、LLMの出力と外部のタスク環境を接続する仕組みが必要です。この「Harness Interface」において、コードは単なるテキストではなく、エージェントの思考や行動を実行可能かつ検証可能な構造へと変換する役割を担います。具体的には、以下の3つの観点でコードが活用されています。
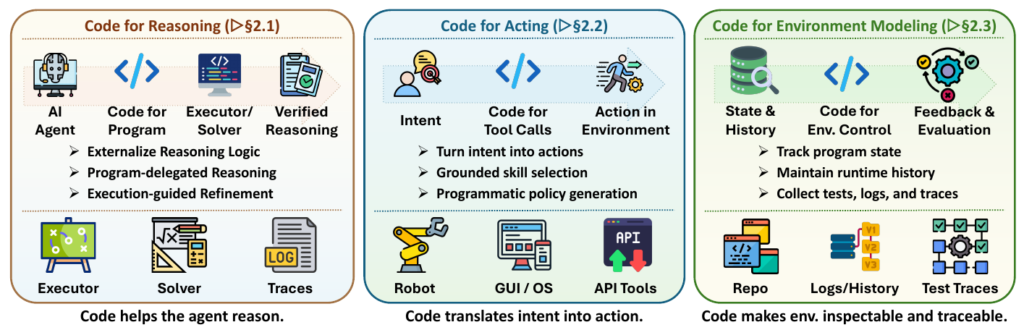
推論のためのコード (Code for Reasoning)
従来のLLMは、思考プロセスを自然言語で展開してきましたが、複雑な論理計算や数値計算を正確に処理するには限界がありました。そこで、コードを推論の基盤として扱う以下のパターンの採用が進んでいます。
- 委譲(Program-Delegated): LLMが直接答えを推測するのではなく、計算手順をPythonなどのプログラムとして出力し、外部のインタープリタに処理を委ねる手法です。これにより、正確で検証可能な結果を得ることができます。
- 形式的検証(Formal Verification): Leanなどの証明支援ツールやソルバーと連携し、生成した推論ステップを機械的に検証するアプローチです。自然言語の柔軟性と、コードによる厳密性を組み合わせることで、論理の飛躍を防ぎます。
- 反復的推論(Iterative Code-Grounded): コードを実行し、そのトレース(実行履歴)やエラー出力をフィードバックとして受け取ります。これを元にLLMが自身の推論を修正し、反復的に正解へと近づけていく実装パターンです。
行動のためのコード (Code for Acting)
推論の次に、LLMが導き出した「意図」を、現実の物理環境やソフトウェア上で具体的なアクションへと変換(グラウンディング)する必要があります。ここでコードは、行動を定義するインターフェースとして機能します。
- プログラム可能なポリシー(Programmatic Policy): 単に「前に進む」「クリックする」といった自然言語の指示を出すのではなく、ロボットの制御APIやGUIの操作コマンドを直接呼び出すプログラムを生成します。例えば、画面の構造を解析して特定のボタンを押すスクリプトを出力するなど、抽象的な目的を「実行可能なポリシー」として具体化します。これにより、エージェントは制約の多い環境下でも、実行結果を監視しながら確実に行動を実施できるようになります。
環境モデリングのためのコード (Code for Environment Modeling)
さらに、エージェントが長期的なタスクを完遂するためには、変化し続けるタスク環境をエージェント自身が正しく把握できる仕組みが不可欠です。
- 構造化された環境表現: 環境を単なるテキストの羅列としてではなく、プログラムとして処理できる「構造化された状態」として扱います。例えば、ソフトウェア開発におけるリポジトリのファイル構成、実行ログ、テストコード、あるいはWeb画面のDOMツリーなどをコードの形式で表現します。
- これにより、エージェントは現在のシステム状態を正確に観察し、自身の行動がもたらした変化を「テストの成功・失敗」などの明確な指標で検証できるようになります。
このように、コードは推論を確かめ、行動を定義し、様々な環境の状態を把握するための、包括的なインターフェースとして機能しています。
2. 自律稼働を支える5つの「Harness Mechanisms」
エージェントが単発のタスクを超えて、複雑な作業を長期間にわたって自律的に進めるためには、単なる指示の実行以上の仕組みが必要です。ここでは、エージェントの安定稼働と進化を支える5つのシステムメカニズム(Harness Mechanisms)について解説します。
1. Planning (計画): LLMにとって、複雑なタスクを一度に解決することは困難です。そのため、タスクをどのように進めるかを管理する「計画」のメカニズムが重要になります。用途に応じて、以下の4つのアプローチが使い分けられています。
- 直線的分解 (Linear Decomposition): タスクをステップバイステップの直線的な手順に分解し、順次進めていく基本的な手法です。
- 構造的計画 (Structure-grounded): ソフトウェアの依存関係グラフなど、環境の構造をベースにして手順を組み立てることで、手戻りを防ぎます。
- 探索ベース (Search-based): 複数の解決パスを同時に探索し、結果を比較検討しながら最適な手順を選択します。
- オーケストレーション (Orchestration-based): 複数のエージェントの役割分担や、フィードバックループを連携させることで、システム全体として計画を進行させます。
2. Memory & Context (メモリとコンテキスト管理): 長時間の作業では、膨大な状態や履歴を適切に管理する必要があります。
- 5つのメモリ: 進行中の作業状態を保つ「作業メモリ」、コードベースの構造から情報を引き出す「セマンティックメモリ」、過去の失敗と成功を活かす「経験メモリ」、検証済みの知識を保持する「長期メモリ」、そして複数エージェント間で状態を同期する「マルチエージェントメモリ」 が定義されています。
- Context Compaction / State Offloading (ログ圧縮と退避): LLMが一度に読み込める情報量(コンテキスト)には限界があります。そのため、実行ログを要約して圧縮し、詳細なデータはデータベースなどの外部に退避させる設計方針が不可欠です。
3. Tool Use (ツール利用): エージェントが外部環境に干渉するためのインターフェースです。単なる関数の呼び出しを超えて、以下の4つのパラダイムに分類されます。
- 機能指向 (Function-Oriented): 必要なAPIや外部ドキュメントを検索し、情報を補完します。
- 環境対話 (Environment-Interaction): リポジトリの編集や、ターミナル、ブラウザなどの実行環境と直接やり取りを実施します。
- 検証主導 (Verification-Driven): テストの生成や静的解析ツールなどを呼び出し、自身のコードを検証するための確実なフィードバックを得ます。
- ワークフロー制御 (Workflow-Orchestration): これらの複数のツールやアクセス権限、実行ポリシーを束ねて、安全なワークフローとして統括します。
4. Harness Control (PEVループ): AIの予測不能な動きをシステムとして制御するために、Plan(計画)、Execute(実行)、Verify(検証)からなる「PEVループ」を実装します。 具体的には、意図を明確にして計画を立て(Plan)、隔離されたサンドボックス環境内で安全にコードを実行し(Execute)、テストや静的解析といった決定論的なセンサーで結果を検証します(Verify)。このサイバネティック(自動制御的)なループにより、エラーを検知して修復する一連の流れが自動化されます。
5. Agentic Harness Engineering (自己進化・最適化) エージェントを動かす「足場(Harness)」自体を、システムが自動的に改善していくパイプラインです。 ここでは、プロンプト、実行コスト、使用したツール、エラー内容といった「深いテレメトリ(Deep Telemetry)」を詳細に収集します。そして、専用の「進化エージェント(Evolution Agent)」がこれらのログを分析し、ツール定義や検索戦略、ワークフローの構成自体を継続的かつ安全に最適化していきます。

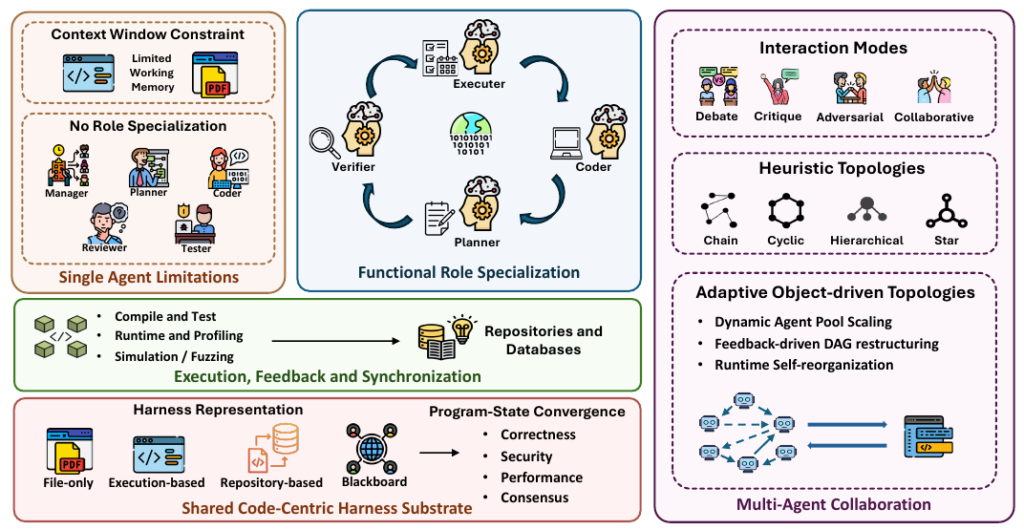
3. マルチエージェントによる「Scaling the Harness」
複雑なソフトウェア開発を進める上で、単一のAIエージェントでは処理できる情報量(コンテキスト長)や専門性に限界が生じます。そこで、システム全体をスケールさせるために、複数のエージェントを協調させる「マルチエージェント」のアプローチが不可欠となります。ここでは、エージェント同士を連携させるための3つの設計観点を解説します。
役割分担とワークフロートポロジー
人間の開発チームと同様に、AIエージェントにも専門的な役割を与えて協調させます。
- 機能的役割分担: 全体の進行を管理する「Manager」、タスクを細分化する「Planner」、コードを生成する「Coder」、品質を担保する「Reviewer」や「Tester」といった具合に役割を分割します。
- ワークフロートポロジー: これらの役割をどのように繋ぐかという構造(トポロジー)の設計がシステムの効率を左右します。
- Chain型: 計画、実装、テストと順次進行していく、ウォーターフォールのような構造です。
- Cyclic型: エラーが検出された場合に、コーダーとテスターの間で修正ループを何度も回すアジャイル的な構造です。
- Debate型: 複数のエージェントが解決策について議論を交わし、合意を形成してから次の処理へと進む構造です。
共有プログラム状態 (Shared Program State)
複数のエージェントが並行して作業を進めると、各エージェントが認識している「現在のシステムの前提」に乖離(State divergence)が生じる危険性があります。これを防ぐため、エージェント間で状態を正確に共有するためのアーキテクチャが採用されています。
- ファイルベース (Implicit / File-only): メッセージ履歴や最新のファイルのみを直接受け渡す簡易な方式ですが、複雑なプロジェクトでは状態を見失う限界があります。
- リポジトリベース: ディレクトリ構造やファイル間の依存関係、変更履歴などを保持し、エージェントがコードベース全体の文脈を把握できるようにするアプローチです。
- 共有ブラックボード (Shared Blackboard): すべてのエージェントが読み書きできる「共有の掲示板」のような永続的なデータ構造を用意し、そこで常に最新の全体状態を同期し続ける設計です。
実行フィードバックによるシステム同期
複数のエージェントが協調して作業を完了させるためには、「いつタスクが完了したとみなすか(収束条件)」を明確にする必要があります。ここでは、自然言語でのエージェント同士の合意に頼るのではなく、コードの「実行結果」を客観的な同期指標として利用します。
- テスト主導の収束: 用意された単体テストや結合テストがすべて「Pass(合格)」した時点を、システム全体のタスク完了条件とみなします。
- コンパイル・静的解析のフィードバック: テストの前段階として、コンパイルエラーや静的解析による警告を収集し、これらがゼロになるまで特定の修正ループを回し続けます。
- スコアベースの判定: テストカバレッジやシミュレーションの精度といった定量的なスコアを算出し、目標スコアに達した段階で最良のコードを選択して処理を完了させる仕組みです。
このように、単なる会話の連携にとどまらず、共有されたコードの「状態」と「実行結果」を基盤(足場)に据えることで、マルチエージェントシステムは長期間にわたる複雑な開発を自律的に進めることができるようになっています。
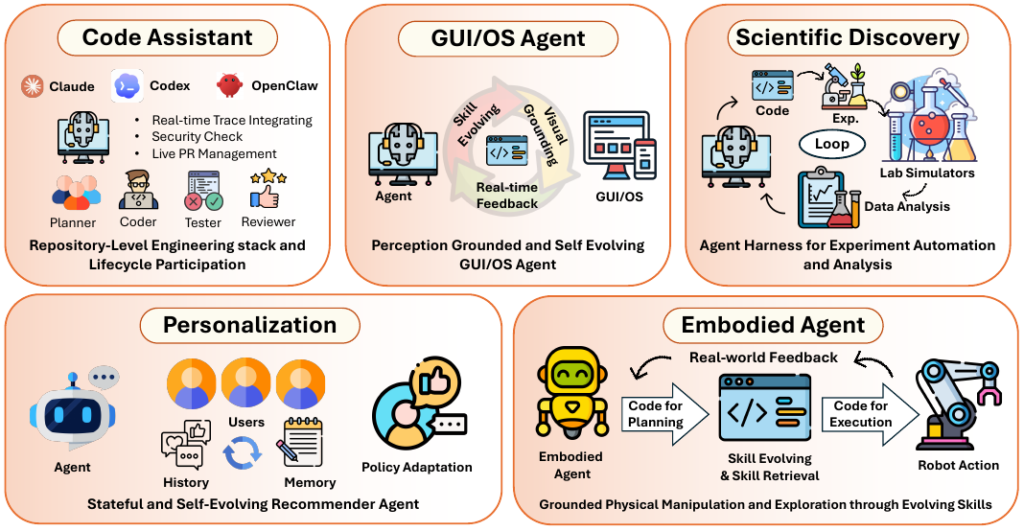
4. 5つの応用領域と未解決課題
これまで解説してきた「Harness(足場)」の設計思想は、すでに様々な現実のアプリケーションで実装が進められています。本章では、代表的な5つの応用領域と、エージェントをさらに発展させるための未解決課題(Open Problems)を整理します。
5つの応用領域
コードを操作基盤とするエージェントは、主に以下の領域で活躍し始めています。
- ソフトウェア開発(コーディングアシスタント): 単発のコード生成にとどまらず、リポジトリ全体を把握し、テストやコードレビューを含めた開発ワークフロー全体を自律的に進めます。
- ブラウザ・OS操作(GUI/OS): 画面のレンダリング結果やDOMツリーを解析し、プログラム可能なコマンドを通じて人間と同じようにソフトウェアを操作します。
- 自律型科学発見(Scientific Discovery): 仮説の立案、シミュレーション、データ分析といった研究プロセスを「実行可能なパイプライン」として管理し、科学的発見のループを回します。
- エンボディド・エージェント(Embodied Agents): ロボットなどの物理的な制約を持つ環境下において、抽象的な指示を実行可能なアクション(スキル)へと変換し、安全な動作を担保します。
- パーソナライゼーション(Personalization): ユーザーの嗜好や行動履歴をプログラム可能な「状態」として保持し、推薦アルゴリズムやポリシーを継続的に適応させていきます。
未解決の課題 (Open Problems)
これらのシステムを実社会で長期間かつ安全に稼働させるためには、以下の課題を克服する必要があります。
- Oracle Adequacy(評価指標の妥当性): 現在のシステム評価は「最終的なタスクが成功したか」に偏りがちです。しかし実際には、長期間の実行信頼性、メモリの維持能力、エラーからの回復力など、「ハーネス自体の性能」を総合的に評価する指標の確立が求められています。
- Semantic Verification(意味的な検証の強化): 「テストでエラーが出ない=仕様を満たしている」という過信を防ぐ必要があります。単体テストだけでなく、静的解析やファジング、人間のレビューなど、複数の検証スタックを組み合わせて確実性を高めるアプローチが不可欠です。
- Safety & HITL(安全性と人間の承認): 本番環境への変更や物理デバイスの操作など、リスクの高いアクションを実施する際の権限管理が課題です。人間の承認(Human-in-the-Loop)を単なる一時的な割り込みではなく、システム内の「永続的な状態」や監査ログとして組み込む設計が重要になります。
- Multimodal Grounding(マルチモーダルな文脈の紐づけと圧縮): GUIのスクリーンショットや物理的なセンサーからのフィードバックは、情報量が膨大でノイズを含みがちです。これらの視覚的・物理的な情報をどのように圧縮してコンテキストに維持し、具体的な実行コードと正しく結びつけるか(グラウンディング)が、実環境での稼働に向けた大きな壁となっています。
おわりに
今回は、AIエージェントにおけるコードの役割が、単なる出力結果からシステム全体を支える「足場(Harness)」へと変化している全体像を解説しました。
結論として、コードは単体の「言語モデル」を、長期間にわたって安全に稼働する「信頼性の高い自律システム」へと昇華させるための強力なインフラストラクチャです。自然言語の曖昧さを排除し、エージェントの思考や行動を、システムが直接検証可能な形へと変換します。
これからのAI開発において、LLM自体の性能向上をただ待つアプローチはもはや十分ではありません。エージェントと環境を繋ぐインターフェースを整備し、自律稼働のメカニズムを構築し、マルチエージェントの協調を設計する「Harness Engineering(足場のエンジニアリング)」こそが新たな主戦場となります。ぜひ、今後のプロジェクトにおいて、この新しいアーキテクチャの視点を取り入れてみてください。
More Information
- arXiv:2605.18747, Xuying Ning et al., 「Code as Agent Harness」, https://arxiv.org/abs/2605.18747
関連記事

ローカルLLMはソフトウェア開発に活用できるのか?
近年、大規模言語モデル(LLM)の進化は目覚ましく、多くの分野でその活用が期待されています。しかし、その強力な性能を享受するには、クラウドベースでの運用が主流であり、API利用コストや外部APIへソースコードを送信するこ […]

強化学習の世界を俯瞰してみる - 基礎から最前線の課題・応用・トレンドまで
強化学習(RL)は、エージェントが試行錯誤を通じて最適な行動を学習する機械学習の一分野です。近年、囲碁やビデオゲーム、大規模言語モデル(LLM)の制御など、多岐にわたる分野で著しい進展を遂げ、応用されています。 特に、深 […]

LLMの学習と推論のメカニズム: なぜプロンプトで性能が変わるのか?
大規模言語モデル(LLM)は、「Next Sentence Prediction (NSP)」という極めてシンプルな目的で学習されているにもかかわらず、驚くほど高度な文脈理解や推論能力を発揮します。さらに興味深いことに、 […]