MinT: LLMを効率的に管理する次世代インフラ
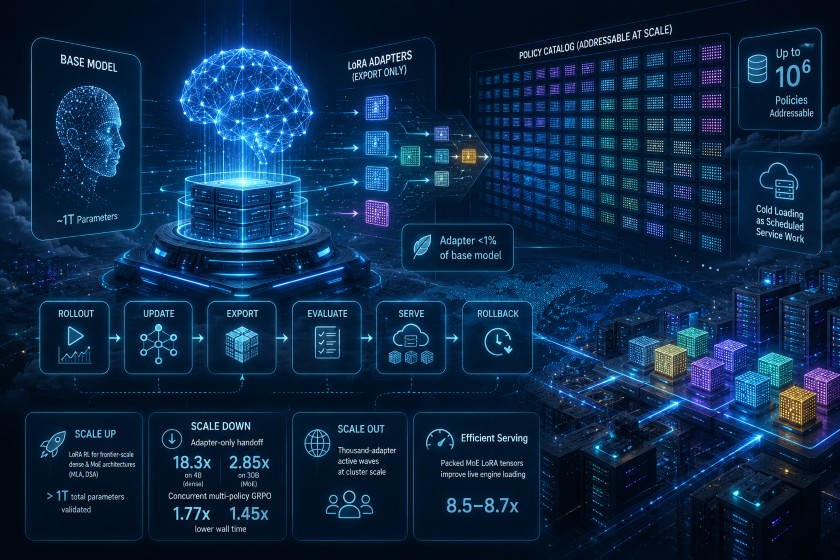
近年、LLM(大規模言語モデル)の運用において、タスクやユーザーごとにモデルを微調整してデプロイする機会が増加しています。しかし、細分化されたバリアントごとにフルサイズのチェックポイントをコピーしたり移動させたりする従来の手法では、ストレージや計算資源を激しく消費し、スケーラビリティに深刻な課題が生じてしまいます。
こうした運用上の限界を解決するために、Mind Labが開発した次世代システムが「MinT(MindLab Toolkit)」です。
MinTは、巨大なベースモデルを常にメモリ上に常駐させ、軽量なLoRA(Low-Rank Adaptation)アダプターのみを管理およびロードするアプローチを採用しています。これにより、不要なデータの複製を省き、数百万規模に及ぶ膨大なLLMの挙動(ポリシー)を単一の基盤で効率的に運用できるマネージドインフラストラクチャを実現しています。
1. MinTの基本概念と全体アーキテクチャ
LLMの継続的な学習やデプロイを進めるうえで、学習環境と推論環境をどう接続するかはインフラ設計の大きな悩みの種です。MinTは、この課題を解決するために独自のアプローチと明確なアーキテクチャの分離を採用しています。
ここでは、MinTを支える3つの重要な基本概念と構造について整理しましょう。
- 推論へのハンドオフの極小化: 従来のフルファインチューニングや、ベースモデルにアダプターをマージする手法とは異なり、MinTは学習側から推論側へフルサイズのチェックポイントを移動させません。ベースモデルを推論エンジンに常駐させたまま、「エクスポートされたLoRAアダプター(リビジョン)」の軽量な差分データのみを転送して適用します。この設計により、数GB〜数十GBに及ぶ不要なデータ移動が削減され、推論への切り替え処理が極めて迅速に完了します。
- ポリシー管理の分離: MinTは、様々なAIの挙動(ポリシー)を効率的に管理するため、データの実体と管理情報を明確に切り離しています。
- アダプターリビジョン (Adapter Revision): 推論や評価で実際に動作する、特定の学習ステップで固定・エクスポートされたLoRAテンソルの実行ファイル(実体)です。
- ポリシーレコード (Policy Record): 対象となるベースモデルのバージョン、LoRAのランク指定、各ファイルの保存先などを記録した管理用のメタデータです。 これらを分離することで、フルモデルの複製を防ぎつつ、数百万規模のポリシーを正確に追跡・復元できる状態を維持しています。
- アーキテクチャの役割分担 分散処理の複雑さをユーザーから隠蔽するため、システム全体は大きく2つの層に分割されています。
- サービスプレーン (Service Plane): クライアントリクエスト(API呼び出し)の受付、ジョブのキューイング、メタデータの解決、リソースの割り当てといった全体管理を担います。
- コンピュートプレーン (Compute Plane): 実際の重い計算処理を担当します。単一ワーカーでの
PEFTや、分散学習フレームワークであるMegatronを用いた学習、そしてvLLMを活用した推論を実行します。
このように責任範囲を分割することで、エンジニアはインフラの複雑な制御やノード間のデータ移動を気にすることなく、シンプルなインターフェース経由で大規模なLLMの学習やサービングを実施できるようになっています。

2. アダプターのライフサイクルとリソース管理
MinTが数百万規模もの膨大なAIモデル(ポリシー)を単一のインフラで処理できる秘密は、アダプターの効率的なライフサイクル管理と、洗練されたリソースの階層構造にあります。
推論リクエストから実際にLLMが応答を返すまで、アダプターは以下の3つのキャッシュ階層を行き来しながら運用されます。
- 共有ストレージ (Durable catalog): 数百万のアダプターを永続的に保存しておく大容量の保管庫です。
- CPUキャッシュ (CPU adapter cache): 推論エンジン(アクター)のメモリ上に一時的に保持され、迅速な読み込みに備える中間層です。
- GPUバッチ (GPU batch): 実際の推論(デコード)ステップで即座に計算に利用される最前線の領域です。
この階層構造により、リクエスト時の処理速度とリソース消費のバランスを最適化しています。

Hot path と Cold path の使い分け
ユーザーからリクエストが到着した際、対象のアダプターがすでにGPUバッチに存在していれば、即座に推論を開始します(Hot path)。一方で、アダプターが手元に存在しない場合は、共有ストレージからCPUへ、そして最終的にGPUへとデータを取得・ロードするプロセス(Cold path)を辿ります。MinTは、このCold pathを単なるファイル読み込みではなく、スケジュールされたジョブとして管理することで、システム全体への急激な負荷集中を防いでいます。
分散環境からのシームレスなエクスポート
さらに大規模なモデルの学習では、Megatron のような分散学習フレームワークを用いて、計算を複数のGPUに分割する「テンソル並列」や「エキスパート並列」が実施されます。しかし、分散された断片的なデータは、そのままでは推論エンジン(vLLM)で動かすことができません。 そこでMinTは、学習完了時に分散したデータを集約(Gather)し、必要に応じて重複するデータを排除して再構築します。最終的に1つの標準的な PEFT 形式のファイルとしてエクスポートすることで、複雑な分散学習の裏側を意識させることなく、推論エンジンへスムーズに受け渡す仕組みを実現しています。

3. Scale Down(ハンドオフとリソースの最小化)
MinTが掲げる3つの拡張軸のうち、「Scale Down」は、学習環境から推論環境へのデータ移動(ハンドオフ)や、計算リソースの消費を極限まで最小化するためのアプローチです。これを実現するために、システム内部では以下のような工夫が取り入れられています。
- タイムスライス方式による学習リソースの最適化: 1つのGPU上で複数のポリシー(AIの挙動)を学習する場合、ポリシーごとに巨大なベースモデルを複製してしまうと、メモリを激しく消費してしまいます。そこでMinTは、ベースモデルの重みをGPUに常駐させたまま、個々のLoRAテンソルやオプティマイザ状態のみをメモリ上で入れ替える(スワップする)「タイムスライス方式」を採用しています。これにより、限られたメモリ領域で様々なポリシーの学習を効率的に進めることが可能です。
- 並行トレーニング (Concurrent Training) の効率化: この洗練されたリソース管理の仕組みは、複数のモデルを同時に学習させる際に大きな効果を発揮します。実際に、3つの GRPO (Group Relative Policy Optimization) ポリシーを並行して学習させた実験では、逐次実行と比較して、ピーク時のメモリ消費を一切増やすことなく、全体の実行時間を大幅に短縮できることが確認されました。具体的には、4Bモデルで1.77倍、30Bモデルで1.45倍の高速化が実測されています。
- ハンドオフにおける準備時間の圧倒的な短縮: 学習完了後、推論環境へモデルを引き渡す際のデータ移動も最小化されています。従来のモデルマージ手法を数式で表すと、ベースモデル \(W\) に学習済みのLoRAアダプター \(L_i\) を足し合わせた巨大なモデル \(W’_i = W + L_i\) を作成し、その重い \(W’_i\) 全体をネットワーク越しに移動させる必要がありました。一方、MinTは軽量な \(L_i\) のみを移動させ、推論エンジン側で常駐しているベースモデルに直接適用します。この手法により、不要なデータの移動や展開処理が省略され、マージしてロードする従来手法と比較して、推論開始までの準備時間を4Bモデルで18.3倍、30Bモデルで2.85倍も高速化することに成功しています。
4. Scale Up(大規模・多様なパラダイムへの対応)
MinTの強力な拡張軸である「Scale Up」は、モデルの規模や学習手法が拡大しても、一貫したインフラ基盤を維持できる点にあります。具体的には、以下の3つの高度な要件に無理なく対応しています。
- トレーニング手法の汎用性: SFT(教師ありファインチューニング)、DPO(直接選好最適化)、そしてGRPO(グループ相対方策最適化)といった全く異なる学習パラダイムを適用する場面でも、MinTのアダプターライフサイクルやエクスポートの仕組みに一切変更を加える必要がありません。同一のプラットフォーム上で、様々な学習プロセスをシームレスに進めることが可能です。
- 大規模MoEモデルでの強化学習とルーティング: パラメータ数が1兆(1T)クラスに達するKimi K2や、Qwen3(30Bおよび235B)といった巨大なMoE(Mixture-of-Experts)モデルの強化学習においても、MinTはAIME24などのベンチマークで高いスコア向上を実現しています。またMoEモデル特有の課題として、推論時と学習時で選択されるエキスパート(経路)がずれてしまう問題が存在します。MinTは、推論時のルートを記録して学習時に再利用する「R3」という手法を取り入れることで、この不安定さを解消しています。
- AutoResearchによる厳密な評価サイクル: システム上でモデル評価を自動化する「AutoResearch」の事例として、LawBenchを用いた検証結果が報告されています。この検証では、プロキシ(簡易)タスクで最高スコアを叩き出した有望な候補が、フルベンチマーク評価に進んだ結果、タスク分布の乖離によって最終的に「棄却」されるという事象が発生しました。MinTを利用すれば、このような厳密な仮説検証サイクルであっても、インフラを分けることなく単一のシステム上で自動的かつ安全に回すことができます。
5. Scale Out(サービング規模の拡大と最適化)
MinTの3つ目の拡張軸である「Scale Out」は、膨大な数のポリシーを効率的に推論エンジンへ提供(サービング)するための仕組みです。システム全体でのリクエスト処理能力を高めるため、階層ごとのリソース管理とロード処理の最適化を進めています。
- 階層ごとのスケール 推論リクエストを迅速に処理するためのキャッシュ階層は、それぞれ異なるスケールとライフサイクルを持っています。
- アドレス可能なカタログ (Addressable catalog): 共有ストレージ上で最大100万規模のポリシー(アダプター)を永続的に保持する大容量の保管庫です。
- CPUキャッシュ: 推論アクターの実行中のみ維持され、1つのエンジンあたり数百規模のアダプターを素早く読み込める状態にしておきます。
- GPUバッチ: 1回のデコードステップの間に、最大64個の個別アダプターを推論の最前線となるスロットに保持します。
- キャッシュの局所性と負荷 特定のアダプターが繰り返し呼び出されるトラフィックでは、CPUキャッシュが有効に機能し、システムは安定して動作します。しかし、常に異なる様々なアダプターがリクエストされるような「局所性が弱い」トラフィック環境下では、ある一定数を超えるとキャッシュ可能な上限に達してしまい、レイテンシが顕著に上昇してボトルネックが顕在化します。
- コールドロードとパッキング手法 キャッシュに存在しない複数の異なるアダプターが同時にリクエストされた場合(コールドロード)、それらを一つずつ直列に読み込むため、待機時間が「階段状 (Staircase)」に増加してしまう課題があります。 さらにMoEモデルのLoRAでは、数万個の細かなテンソルを展開する処理が重いオーバーヘッドを生み出します。この課題に対し、MinTは細かいテンソルをまとめる「パッキング表現 (Packed representation)」という手法を取り入れています。たとえば約3万7000個のテンソルを600個台に変換することで、データ全体のサイズはそのままに、オブジェクトの展開にかかる負荷を削減し、ロード速度を8.5倍〜8.7倍に向上させています。
おわりに
MinTは、LLMのバリアントごとにフルサイズのモデルを管理する従来のボトルネックを解消し、マルチテナント環境における学習とサービングの実用性を飛躍的に高めるシステムです。
アーキテクチャの明確な分離やベースモデルの常駐化、タイムスライス方式の学習、そして効率的なコールドロード設計を組み合わせることで、システム全体のリソース消費を最小化します。これにより、1兆パラメータ規模の巨大なモデルや、最大100万規模のポリシー管理にも無理なく対応可能です。
今後、特定のタスクに特化したモデルや、パーソナライズされた様々なAIエージェントを継続的に運用・評価していくうえで、MinTのような「アダプター中心」のインフラストラクチャは、次世代の実用的スタンダードとなる技術となり得ます。
More Information
- arXiv:2605.13779, Mind Lab, 「MinT: Managed Infrastructure for Training and Serving Millions of LLMs」, https://arxiv.org/abs/2605.13779
関連記事
【LLM活用】LangChainとLLMLinguaでプロンプト圧縮
近年、ChatGPTをはじめとする大規模言語モデル(LLM)が、私たちの生活に大きな変化をもたらしています。これらのモデルは、膨大な量のテキストデータを学習することで、人間と自然な対話をしたり、文章を生成したりすることが […]

LLMLingua: LLMのためのプロンプト圧縮技術
昨今、大規模言語モデル(LLM)は、様々なアプリケーションで活用されています。LLMの能力を最大限に引き出すため、Chain-of-Thought (CoT) や In-Context Learning (ICL)、Re […]

Conversational Search入門: LLM時代の検索技術最前線
現代のデジタル社会において、検索エンジンは情報アクセスに不可欠な存在となっています。しかし、単一のキーワードや短いフレーズに依存する従来の検索では、ユーザーの複雑で曖昧な情報ニーズに十分に応えきれません。 近年、人工知能 […]