BERT-as-a-Judge: LLM評価の精度と効率を両立する新手法

LLMを活用したシステム開発において、モデルの生成した回答が正しいかを正確に評価するプロセスは、システムの信頼性を担保する上で非常に重要です。従来、回答の判定には正規表現(Regex)などを利用した字面の一致に頼る手法が一般的でした。しかし、この手法では、LLMが指定したフォーマットから少しでも逸脱すると、意味的には正解であっても不正解として処理されてしまうという課題があります。
一方で、別のLLMに意味的な正しさを判定させる「LLM-as-a-Judge」というアプローチも普及しつつあります。この手法はフォーマットの揺れには強いものの、計算コストが非常に高く、評価を大規模に実施するのは難しいのが実情です。
この記事では、論文「BERT-as-a-Judge: A Robust Alternative to Lexical Methods for Efficient Reference-Based LLM Evaluation」を参考に、これらの中間を埋める最適解として提案された新手法について解説します。エンコーダベースの評価モデルである「BERT-as-a-Judge」の仕組みと、その技術的な利点について詳しく見ていきましょう。
1. 従来の評価手法が抱える課題
LLMの評価において、特定のフォーマットで回答を出力させ、正規表現(Regex)などを用いて文字列を抽出・判定するアプローチは広く採用されています。しかし、この手法や、別のLLMを評価者とするアプローチには、実用上の大きな課題が存在します。
問題解決能力とフォーマット遵守の混同
正規表現による厳密な字面ベースの評価では、モデルが本質的に持っている「問題を解く力」と、「指定されたフォーマットに従う力」が混同されてしまいます。つまり、意味的には正しい回答を生成できているにもかかわらず、指定された形式から少しでも外れると不正解として扱われてしまいます。
フォーマット遵守能力のばらつき
出力フォーマットを正しく守れるかどうかは、モデルのサイズや開発元(ファミリー)、そして様々なタスクの性質に大きく依存します。例えば、パラメータ数が数100億クラスの大規模なモデル(例: Llama-3 70B)であっても、自由記述が求められるような数学タスクにおいては、指定フォーマットを逸脱してしまい、回答の抽出(パース)に失敗する割合が60%を超えるケースも確認されています。
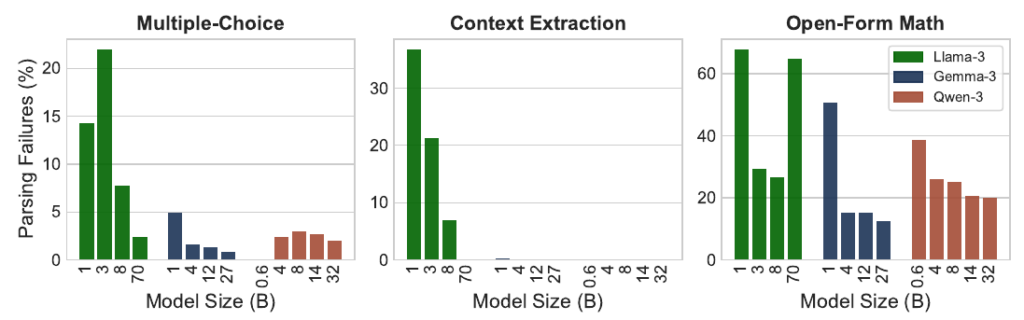
リーダーボードランキングの歪み
フォーマットの揺れによって不正解と判定されるケースが多発すると、モデルの実際の性能が大きく過小評価されてしまいます。その結果、単なる出力フォーマットの癖や、厳密な文字列の一致判定が原因で、モデルの実力を示すリーダーボードのランキングが不当に歪められてしまうという実害が発生しています。
厳密なフォーマット指定(Strictモード)の弊害
評価システム側の都合に合わせて、LLMに厳密なフォーマットでの出力を強制(Strictモード)すると、別の問題が生じます。モデルが回答を導き出す過程で、思考のプロセスを文章として書き出す中間推論(Chain-of-Thought)を実施する機会が奪われてしまうためです。これにより、モデルが本来発揮できるはずのパフォーマンス自体が大きく低下してしまうというジレンマを抱えています。
| Task | Log-lik. | Strict | Soft | Free |
|---|---|---|---|---|
| Multiple-Choice | ||||
| ARC-Challenge | 46.3 | 74.4 | 76.2 | 75.0 |
| ARC-Easy | 65.0 | 84.6 | 84.9 | 84.4 |
| GPQA | 25.9 | 32.3 | 31.8 | 28.8 |
| MMLU | 39.9 | 59.4 | 62.0 | 60.5 |
| MMLU-Pro | 21.1 | 38.0 | 44.3 | 42.6 |
| TruthfulQA | 33.2 | 51.3 | 51.6 | 51.3 |
| Context Extraction | ||||
| CoQA | – | 71.3 | 76.5 | 86.7 |
| DROP | – | 48.4 | 60.2 | 64.5 |
| HotpotQA | – | 66.0 | 71.0 | 82.4 |
| SQuAD-v2 | – | 44.7 | 53.5 | 62.0 |
| Open-Form Math | ||||
| AIME24 | – | 18.1 | 19.8 | 18.1 |
| AIME25 | – | 13.2 | 14.4 | 15.7 |
| ASDiv | – | 68.8 | 81.5 | 82.1 |
| GSM8K | – | 43.1 | 73.6 | 73.6 |
| Math | – | 49.3 | 60.2 | 57.3 |
LLM-as-a-Judgeの限界
正規表現の限界を克服するため、別の生成モデルを用いて意味的な正しさを判定する「LLM-as-a-Judge」という手法も注目されています。しかし、大規模な生成モデルを評価プロセスに組み込むと、推論にかかる計算コスト(FLOPs)が非常に高くなってしまいます。一方で、コストを抑えようと10億パラメータ未満の小規模なモデルを評価者に採用すると、評価能力が極端に落ちてしまい、結果として正規表現ベースの評価精度すら下回ってしまうことが分かっています。
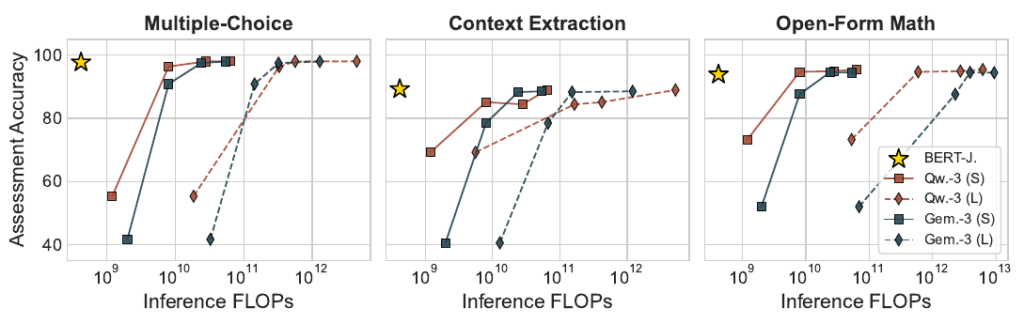
2. BERT-as-a-Judgeの技術的概要
従来の評価手法が抱える課題を解決する最適解として提案されたのが、「BERT-as-a-Judge」と呼ばれるエンコーダベースの評価手法です。ここでは、その技術的な仕組みと特徴について解説します。
評価のメカニズム
BERT-as-a-Judgeは、言語モデルが生成した回答の正誤を「テキスト分類タスク」として判定します。具体的には、「質問(Question)」、「モデルが生成した候補回答(Candidate)」、そして「正解となる参照回答(Reference)」の3つをセット(トリプレット)にしてモデルに入力し、その候補回答が意味的に正しいかどうかを評価します。字面の一致に頼るのではなく、与えられた情報に基づく正誤判定を実施する点が大きな特徴です。
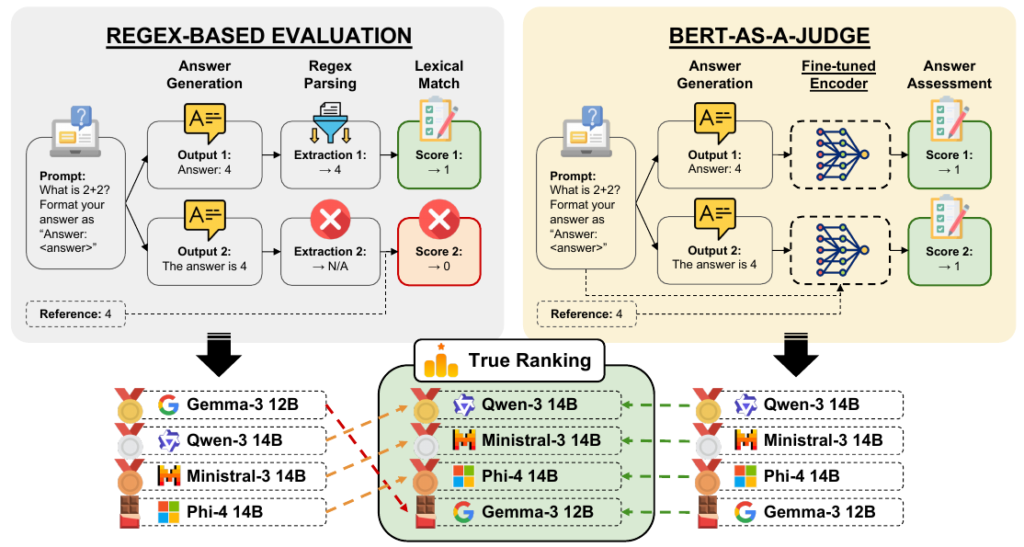
軽量エンコーダの活用
この評価器のベースとして、パラメータ数が約2.1億(210M)と比較的軽量な「EuroBERT」というエンコーダモデルが採用されています。BERTに代表されるエンコーダモデルは、文章を前後両方の文脈から読み解く「双方向アテンション」という仕組みを持っています。この仕組みを活用することで、回答フレーズの構造的な違いや、語彙の選択といった出力表現の揺らぎに対しても、堅牢で正確な評価が可能になります。
学習データの高い信頼性
BERT-as-a-Judgeを評価器として機能させるための微調整(ファインチューニング)には、「Llama-Nemotron」と呼ばれる別の強力なモデルによって自動生成された合成ラベルが用いられています。自動生成されたデータで学習させることに不安を感じるかもしれませんが、人間による評価結果と比較したところ、約97.5%という極めて高い一致率を示しました。この結果は、合成ラベルを用いた学習データであっても、評価器としての根本的な信頼性を十分に担保できていることを証明しています。
3. 4つの技術的利点
ここでは、BERT-as-a-Judgeを採用することで得られる具体的な4つのメリットを整理します。
タスクを問わない圧倒的な高精度
この手法は、複数選択(Multiple-Choice)、文章からの文脈抽出(Context Extraction)、そして自由記述が求められる数学(Open-Form Math)といった様々なタスクカテゴリーにおいて、正規表現ベースの手法を大幅に上回る評価精度を達成しています。特定の出力フォーマットに縛られず、純粋な「回答の正しさ」を正確に判定できるため、モデルの実態に即した評価が可能です。
| Task | Regex | LLM-Judge | BERT-Judge |
|---|---|---|---|
| Multiple-Choice | |||
| ARC-Challenge | 89.0 | 50.2 | 99.4 |
| ARC-Easy | 88.2 | 54.0 | 99.7 |
| MMLU | 88.1 | 50.3 | 98.5 |
| GPQA | 86.5 | 66.2 | 93.5 |
| MMLU-Pro | 88.8 | 57.1 | 96.5 |
| TruthfulQA | 92.5 | 54.5 | 98.6 |
| Context Extraction | |||
| HotpotQA | 75.6 | 70.0 | 90.9 |
| SQuAD-v2 | 72.3 | 62.5 | 89.3 |
| CoQA | 67.0 | 75.2 | 88.1 |
| DROP | 77.0 | 69.3 | 88.6 |
| Open-Form Math | |||
| GSM8K | 94.4 | 71.3 | 98.8 |
| Math | 73.4 | 58.9 | 93.7 |
| AIME24 | 87.8 | 77.9 | 90.0 |
| AIME25 | 91.8 | 83.0 | 91.4 |
| ASDiv | 89.2 | 75.5 | 95.3 |
劇的な計算コスト削減(高効率な FLOPs )
大規模なモデル(Qwen-3やGemma-3など)を評価者に据える手法と同等の精度を維持しつつ、推論に必要な計算コスト( FLOPs : 浮動小数点演算回数)を劇的に抑えることができます。例えば、Apple M1チップを搭載した一般的なマシンのCPU上であっても、1サンプルあたり約200ミリ秒という驚異的な軽さで動作します。継続的インテグレーションなどで大量の評価プロセスを日常的に回す環境でも、インフラコストの肥大化を防ぐことができます。
驚異的なデータ効率
独自の評価器を構築するための学習プロセスも非常に効率的です。複数選択や数学タスクであれば、わずか10万件の学習データを用意するだけで、実用に耐えうる十分な評価精度( Accuracy )に到達します。この学習にかかる計算コストは、GPUを約2時間稼働させる程度で済みます。そのため、計算リソースや準備期間が限られているプロジェクトでも速やかに導入を進められます。
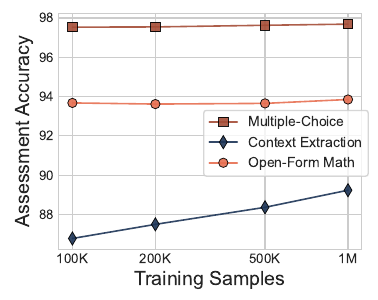
未知のモデルへの汎化性能と運用安定性
学習時のデータには含まれていない、未知のモデルが生成したテキストに対しても高い評価精度を維持できる優れた汎化性能を備えています。また、運用面での大きな強みとして、判定の境界線となる閾値に対する安定性が挙げられます。通常、確率を出力する分類モデルはタスクごとに閾値を微調整する必要がありますが、この手法は閾値を変動させても精度が極めて安定しているため、タスクごとに最適値を調整する運用上の手間を省くことができます。

4. ベストプラクティス
BERT-as-a-Judgeを実際の開発現場に導入し、その効果を最大化するための実用的なベストプラクティスを5つ紹介します。
ハイブリッド評価によるコスト最適化
すべての評価をBERT-as-a-Judgeで実施するのではなく、まずは従来の正規表現による評価を試みる「ハイブリッド運用」が有効です。正規表現による回答の抽出(パース)に失敗した場合にのみ、フォールバックとしてBERT-as-a-Judgeを利用します。これにより、評価にかかる計算コスト(オーバーヘッド)を低く抑えつつ、正規表現単体で評価するよりも大幅に精度を回復させることができます。リソースが限られている環境での現実的な妥協案として非常におすすめです。
プロンプト簡略化のトレードオフを活用
評価モデルへの入力から「質問(Question)」のテキストを省略し、「候補回答」と「参照回答」のみを比較させるアプローチも選択肢の一つです。複数選択や数学のようなタスクであれば、質問を省いても高い評価精度を維持できるため、計算速度をさらに向上させることができます。一方で、文章の読解が求められる文脈抽出タスクなどでは、質問文がないと精度が低下してしまいます。対象となるタスクの特性を深く理解し、速度と精度のバランスに応じたプロンプト設計を進めることが重要です。
| Task Category | Regex | BERT-Judge w/ Q. | BERT-Judge w/o Q. |
|---|---|---|---|
| Multiple-Choice | 88.8 | 97.7 | 97.3 |
| Context Extraction | 73.0 | 89.2 | 84.2 |
| Open-Form Math | 87.3 | 93.9 | 93.9 |
自由記述(Free-form)データでの学習を推奨
独自の評価器を学習(ファインチューニング)させる際は、特定の出力フォーマットに縛られない自由記述形式のデータを用いることを推奨します。あらかじめ整形されたデータよりも、自由な形式の出力データでエンコーダを学習させた方が、運用時に遭遇する様々な出力フォーマットに対して、より堅牢で汎用性の高い評価器を構築できます。
| Task Category | Regex | BERT-J. (Form.) | BERT-J. (Free) |
|---|---|---|---|
| Multiple-Choice | – | 94.0 | 97.6 |
| Context Extraction | – | 84.3 | 91.6 |
| Open-Form Math | – | 93.1 | 93.5 |
回答生成時は「Soft」なプロンプト設定を活用
評価対象のLLMに回答を生成させる際の工夫も重要です。厳密なフォーマットのみを強制するのではなく、思考プロセスを書き出す中間推論(Chain-of-Thought)を許容しつつ、最終的な回答フォーマットだけを指定する「Softモード」を採用してみてください。これにより、モデルが本来持っている性能を最大限に引き出しつつ、後続のシステムによる評価の自動化をスムーズに両立させることができます。
CI/CDパイプラインへの容易な組み込み
一般的なCPU上であっても1サンプルあたり約200ミリ秒で動作するという圧倒的な軽量さは、実運用において大きな武器となります。この特性を活かすことで、日々の開発サイクルにおける CI/CD パイプラインや、実務での大規模なバッチ自動評価システムへの組み込みが極めて容易になります。評価プロセスのボトルネックを解消し、より迅速なモデルの改善サイクルを回すことが可能になります。
5. Python 実装
BERT-as-a-Judgeは、公式のGitHubリポジトリでソースコードが公開されており、誰でも手軽に自身のプロジェクトへ組み込むことができます。ここでは、環境構築から基本的な使い方までを解説します。
セットアップ
まずはリポジトリをクローンし、Editable Mode でインストールします。
# リポジトリをクローンしてインストール
$ git clone https://github.com/artefactory/BERT-as-a-Judge.git
$ cd BERT-as-a-Judge
$ pip install -e .
# 必須依存ライブラリのインストール
$ pip install torch transformers==4.57.0 datasets tqdmまた、用途に応じて以下のオプションライブラリをインストールすることで、より高度な機能を利用できます。
# 高速な推論バックエンドを有効にしたい場合(推奨)
$ pip install vllm
# 効率的な訓練を行う場合(推奨)
$ pip install accelerate
# RegexJudge を使用した評価を行う場合
$ pip install rouge-score math-verify基本的な使い方
Pythonスクリプトから BERTJudge クラスを呼び出すことで、生成AIの回答(候補)をリファレンス(正解例)と比較し、スコアリングできます。
以下の例では、1つの質問と正解例に対し、複数の回答候補がどれだけ正しいかを判定しています。
from bert_judge.judges import BERTJudge
# 1) Judgeの初期化
# モデルパスには Hugging Face 上のモデルやローカルパスを指定します
judge = BERTJudge(
model_path="artefactory/BERTJudge",
trust_remote_code=True,
dtype="bfloat16",
)
# 2) 質問、リファレンス(正解)、および評価対象の回答候補を定義
question = "フランスの首都は何ですか?"
reference = "パリ"
candidates = [
"パリ。",
"フランスの首都はパリです。",
"パリとロンドンのどちらか迷っていますが、パリだと思います。",
"ロンドン。",
"フランスの首都はロンドンです。",
"パリとロンドンのどちらか迷っていますが、ロンドンだと思います。",
]
# 3) スコアの予測(各候補に対して 0.0〜1.0 のスコアが算出されます)
scores = judge.predict(
questions=[question] * len(candidates),
references=[reference] * len(candidates),
candidates=candidates,
batch_size=1,
)
print(scores) # 出力: [0.9522, 0.9923, 0.9334, 0.2053, 0.2473, 0.1727]
出力されたスコアを見ると、「パリ」を含む正しい回答には高い値が、誤った都市(ロンドン)を挙げている回答には低い値が割り当てられていることがわかります。このように、文言が完全に一致していなくても、意味的な妥当性を考慮した柔軟な評価が可能です。
さらなる活用
BERT-as-a-Judgeのリポジトリでは、今回紹介したPython API以外にも以下のような強力な機能が提供されています。
- CLIツール: 大規模なデータセットに対する一括生成や評価をコマンドラインから実行できます。
- カスタムタスクの追加: 独自のデータ形式に合わせた評価タスクを簡単に定義できます。
- 独自モデルの学習: 自身のドメインに特化したデータを用いて、
BERTJudge自体をファインチューニングするワークフローも用意されています。
おわりに
LLMを活用したシステム開発において、正規表現による評価の脆さや、生成モデルを用いた「LLM-as-a-Judge」の高コストさは、迅速な開発サイクルを回す上での大きなボトルネックとなります。
今回紹介した「BERT-as-a-Judge」は、エンコーダモデル特有の軽量さと優れた意味理解能力を活用することで、評価パイプラインのスケールと判定の信頼性を高い次元で両立します。
今後、様々なタスクにおいてLLMの出力品質を自動で評価・モニタリングしていく上で、精度と計算コストのジレンマを解消する本手法は、実務的に非常に強力で魅力的な選択肢となるはずです。
More Information
- arXiv:2604.09497, Hippolyte Gisserot-Boukhlef et al., 「BERT-as-a-Judge: A Robust Alternative to Lexical Methods for Efficient Reference-Based LLM Evaluation」, https://arxiv.org/abs/2604.09497
関連記事

深層学習×状態空間モデル: Mambaアーキテクチャの概要
近年、普段の生活やビジネスでは欠かせないAI技術ですが、ChatGPTをはじめとする大規模言語モデル(LLM)の登場で、Transformerと呼ばれるアーキテクチャが注目を集めています。Transformerは、文章や […]

ベイジアンネットワーク入門:pgmpyによる因果探索と因果推論の実践
近年の機械学習(ML)モデルは、ビッグデータ解析において非常に高い予測精度を達成しています。しかし、その意思決定に至るプロセスが不透明な「ブラックボックス」となってしまう課題が指摘されています。データから相関関係を発見す […]

Neuro-Symbolic AI: ブラックボックス時代における信頼性と論理の融合
現在の自然言語処理(NLP)やコンピュータビジョン(CV)の分野では、深層学習モデルが目覚ましい成果を上げています。しかし、これらのモデルはデータ効率の悪さや予測の根拠(説明性)が不透明であるという根本的な課題を抱えてい […]