コンテキスト・エンジニアリングの構造化手法

AIを使っていて、「期待した結果が返ってこない」、「何度もやり取りを繰り返してしまう」と感じたことはないでしょうか。多くの場合、その原因は「プロンプトの書き方」ではなく、AIに与える「コンテキスト(背景情報)の不完全さ」にあります。
たとえば、AIにレポート作成を依頼する際、短い指示だけでは一般的なテンプレートしか出力されません。しかし、過去のレポート例やフォーマットの制約事項などをあらかじめまとめて渡しておけば、1回目の出力から実用的なものが得られます。つまり、より良い出力を得るためには、AIに何をさせるか(プロンプト)以上に、どのような前提情報を渡すか(コンテキスト)が重要になります。
この記事では、プロンプトの工夫から一歩踏み込み、AIに与える情報を適切にパッケージ化し、作業プロセスを分割して進める「コンテキスト・エンジニアリング」の実践的な構造化手法について解説します。
1. プロンプト・エンジニアリング vs コンテキスト・エンジニアリング
AIを活用する上で、「プロンプト・エンジニアリング」という言葉は広く知られています。しかし、プロンプトの工夫だけでは解決できない課題も少なくありません。ここでは、従来の手法と「コンテキスト・エンジニアリング」の違いを3つの観点から整理します。
- プロンプト・エンジニアリングの限界: 従来のプロンプト・エンジニアリングは、主にAIに対する「指示の出し方」に焦点を当ててきました。プロンプトとはいわば「命令」であり、AIにどのようなトーンや形式で出力させるかを細かく調整する技術です。しかし、どんなに的確な指示を出しても、作業に必要な背景情報や具体例といった「コンテキスト(前提となる情報)」が不足していれば、AIはタスクを正しく実行できません。
- 機械から機械へのコンテキスト共有(RAGとエージェント): コンテキストの重要性が認知されるにつれ、RAG (Retrieval-Augmented Generation: 検索拡張生成) や、AIエージェントフレームワークが普及してきました。LangChainやAutoGPTといったフレームワークは、AIシステムが自律的にタスクを分解し、情報を保持する点で非常に強力です。しかし、これらは「機械が別の機械(AIコンポーネント)にコンテキストを渡す仕組み」に主眼が置かれています。つまり、システム内部での情報処理の自動化を目的としているのが特徴です。
- 人間からAIへの情報編成プロセス: これらに対し、コンテキスト・エンジニアリングは、「人間がAIに渡す情報ペイロード(ひとまとまりのデータ)をいかに設計し、順序立てて組み立てるか」という、人間側の情報編成プロセスに焦点を当てています。既存のツールやフレームワークが解決していない「人間がどのように情報を準備すべきか」という課題に取り組む点が大きく異なります。
実務において、人間はAIツールに対してどのような情報を渡し、それにどのような役割(たとえば「絶対に守るべきルール」なのか「形式の参考資料」なのか)を持たせるかを決定しなければなりません。コンテキストの構造化手法は、この情報収集とパッケージ化のプロセスに、明確な役割定義や優先順位付けといった構造を持ち込みます。これにより、属人的になりがちなAIとのやり取りを、再現性のあるプロセスへと昇華させます。
| 比較軸 | Prompt Engineering | Context Engineering |
|---|---|---|
| 焦点 | モデルへの「指示・命令」 | モデルに渡す「情報パッケージの設計」 |
| 依存先 | 人間の短期記憶と会話履歴 | 定義・バージョン管理された「ファイル」 |
| 品質保証 | 修正指示による事後的な調整 | パイプラインによる段階的な検証と統制 |
| 初回成功率 | 32%(アドホックな使用時) | 55.0%(構造化された適用時) |
2. コンテキストを構成する5つの役割と優先順位
AIに大量の参考資料を読み込ませたにもかかわらず、的外れな回答が返ってきた経験はないでしょうか。これは、AIが「どの情報を優先して処理すべきか」を理解できていないために起こります。
コンテキスト・エンジニアリングでは、AIに渡す情報を単なるテキストの羅列ではなく、明確な役割を持つ「パッケージ」として構造化します。具体的には、情報を以下の5つの役割に分類し、絶対的な優先順位を設定します。
- Authority(権威 – 優先度1):絶対に守るべき要件やルールです。要件定義書、設計ドキュメント、プロジェクトのガイドラインなどが該当します。
- Exemplar(実例 – 優先度2):望ましい出力形式の参考となるパターンや、過去の成功例です。
- Constraint(制約 – 優先度3):文字数制限や禁止事項、特定のフォーマット指定などの制限事項です。
- Rubric(評価基準 – 優先度4):出力の品質を評価するためのチェックリストや完了の定義です。
- Metadata(メタデータ – 優先度5):今回のリクエスト固有の情報(プロジェクト名など)や、AIへの日常的な指示文(プロンプト)です。
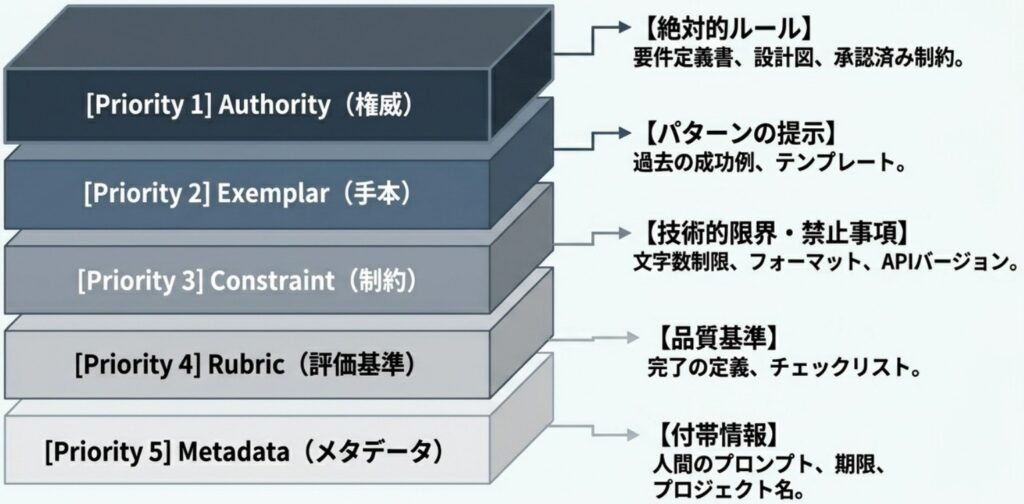
一番の優先事項は「権威(Authority)」である
ここで特筆すべきは、人間がその場で入力する日常的な指示文(プロンプト)は、最も優先度が低い「Metadata」に分類されるという点です。これは直感に反するかもしれませんが、情報同士の矛盾を解決する上で非常に重要です。
たとえば、15ページの分量と8つのセクション構成を義務付けるルール(Authority)をAIに渡しているとします。その際、プロンプトで「簡潔に5ページ以内でまとめてください」と指示した場合、AIはどうすべきでしょうか。優先順位が設定されていなければ、AIは直近の指示であるプロンプトに従ってしまい、本来の要件を満たさない不十分な出力を返してしまうことが多くなります。しかし、優先順位を明確にしておけば、「Authorityの要件が優先されるため、15ページで出力する」という正しい判断を下すことができます。プロンプトはあくまで作業のきっかけであり、出力を支配するのは「権威(Authority)」です。
量より構造と「実例(Exemplar)」の活用
コンテキストを充実させようとして、関係のありそうなファイルを無闇に大量に添付するのは逆効果です。実証データによれば、明確な「Authority(権威)」を含まない4つのファイル群よりも、「Authority」と「Constraint(制約)」に絞り込んだ2つのファイル群の方が、AIははるかに精度の高い出力を返します。情報量が多ければ良いのではなく、情報の構造が重要になります。
さらに、AIの認識のブレを防ぐために有効なのが、「Exemplar(実例)」の活用です。言葉だけで「フォーマルかつ親しみやすいトーンで」と指示するよりも、実際にそのトーンで書かれた過去の成果物を「実例」として一緒に提供する方が、AIははるかに正確に意図を汲み取ります。最も重要な「Authority(権威)」を中心に据えつつ、望ましい「実例」を添えて構造的な情報パッケージにすることで、AIの出力品質は劇的に安定します。
3. 品質のばらつきを防ぐ4段階のパイプラインと監査
AIへの依頼を進める際、プロンプトを入力していきなり最終成果物を出力させてはいないでしょうか。複雑なタスクになるほど、この「一発勝負」のアプローチは品質のばらつきを生み出します。
コンテキスト・エンジニアリングでは、ソフトウェア開発のプロセスのように、AIとの作業プロセスを以下の4つのステージに分割して進めます。
- Reviewer(要件整理): 既存の資料や要件を読み込み、何が必要で何が不足しているか、どのような制約があるかを整理します。
- Design(設計): Reviewerの整理に基づき、目次構成やアーキテクチャなどの「設計書」を作成します。
- Builder(構築): 設計書に従って、実際のコンテンツやコードを作成します。
- Auditor(検証): 成果物が設計書や要件を満たしているかを客観的に評価します。

要件整理の徹底と設計の重要性
実証データによると、AIの出力が「それらしいが、一般的な内容にとどまる(役に立たない)」ケースの多くは、最初の「Reviewer(要件整理)」をスキップしたことが原因です。また、「Design(設計)」のプロセスを飛ばしていきなり構築に取り組むと、AIが独自に構成を推測してしまい、全体として一貫性のない成果物が出来上がってしまいます。
ここで重要なのは、構築(Builder)フェーズに入る前に、AI自身に設計書を作らせるということです。この設計書が、前章で触れた最優先の「権威(Authority)」ファイルとして機能し、後の構築作業のブレを強力に防ぎます。
クロスツール検証(Auditor)の導入
検証フェーズにおいて最も重要なルールがあります。それは「構築したAI自身に監査をさせてはいけない」ということです。人間が自分の書いた文章のミスに気づきにくいのと同様に、AIも自身の出力した結果を正当化する傾向があり、特有の死角(たとえば存在しない架空の論文を引用してしまう等)を見逃しがちです。
そのため、構築用と監査用で異なるAIツールを用いて相互検証を実施します。たとえば、「Claudeが文章を構築し、ChatGPTがその文章を要件定義書と照らし合わせて監査する」といったクロスツールのアプローチが非常に有効です。異なるツールを使うことで、単一のAIでは見落としてしまうような論理の飛躍や矛盾を発見しやすくなります。
根本的解決を促す3つのフィードバックループ
もしAuditorが成果物にエラーや修正点を発見した場合、ただBuilderに「直して」と指示するだけでは不十分です。エラーの性質に応じて、適切なステージに立ち戻る(イテレーションを回す)必要があります。
| エラーの性質 | 立ち戻るステージ | 具体例 |
|---|---|---|
| 実行のミス | Builder(構築) | 設計書にあるセクションが欠落している、事実と異なる情報が含まれている |
| 構造のミス | Design(設計) | 指定された要件を満たすには、そもそもの構成案や設計に無理がある |
| 前提の欠落 | Reviewer(要件整理) | 新たな制約事項が発覚した、根拠となる情報や前提が根本的に足りていない |
つまり、AIとの協働を単一の指示から「4段階のパイプライン」へと構造化し、エラー時には適切なフェーズへ立ち戻ることで、様々なタスクにおいて一貫した高品質な成果物を安定して得られるようになります。
4. 実証データと数理モデルによる評価(批判的考察)
コンテキスト・エンジニアリングは単なる概念ではなく、実際の業務データに基づく裏付けがあります。既存研究で報告されている200件の操作データ(ClaudeやChatGPTなどを活用)の分析例を見ると、その具体的な効果が確認できます。
事前準備なしに場当たり的な指示を入力したベースラインと、本手法の構造化パッケージを適用した場合を比較すると、以下の改善がみられました,。
- 初回合格率: 1回目の出力でそのまま採用できる割合が、32%から55%へと大幅に向上。
- 平均反復修正回数: 修正を指示する回数が、平均3.8回から2.0回へと減少。
つまり、プロンプトを何度も微調整して修正を繰り返す作業から解放され、より少ない回数で実用的な出力を得られるようになります。
直感的な工夫を裏付ける数理モデル
さらに興味深いのは、こうした直感的なアプローチが、信頼性工学の数理モデルによって事後的に説明できるという点です。
たとえば、構築フェーズと監査フェーズで異なるAIツールを用いる「クロスツール検証」は、信頼性工学における「N-version多様性(N-version diversity)」という概念に合致しています。これは、「独立して開発された複数のシステムに同じ仕様を処理させると、それぞれ異なる盲点を持つため、全体としてエラーの検出率が高まる」という原理です。異なるAIを組み合わせることで、単一のAIでは見逃してしまうエラーを発見しやすくなる理由が、理論的にも裏付けられています。
実証データに対する批判的考察と制約
一方で、これらの結果を解釈する際には、いくつかの客観的な制約事項も踏まえる必要があります。
第一に、この実証データは「単一の熟練オペレーターによる観察記録」に基づいています。つまり、経験の浅いユーザーや異なる作業スタイルを持つ人が実践した場合に、全く同じ効果が得られるかどうかはまだ検証されていません。
第二に、今回のデータは無作為化された厳密な対照実験によって取得されたものではありません。そのため、品質向上の要因が「手法の導入」そのものによるのか、それとも「オペレーター自身のスキル向上」などの外部要因によるのか、厳密な因果関係の証明には至っていないという制約が残ります,。
本手法は非常に強力で実用的なアプローチですが、どのような状況でも必ず成功する手法ではなく、前提や限界を持った一つの枠組みとして捉える視点も重要です。
5. 実務へ導入するための具体的なヒント(継続的改善)
コンテキスト・エンジニアリングの構造を理解したところで、実際に日々の業務へ導入し、継続的に改善していくための4つの具体的なヒントを紹介します。
- ファイルベースでの指示(プロンプトからの脱却): AIへの依頼は、チャット画面での口頭説明(プロンプト)で済ませるのではなく、要件や正解の形を明確なファイルとして整理し、アップロードすることが最も効果的です。実証データにおいても、チャット上で言葉を使って要件を伝えるより、最優先の権威(Authority)ドキュメントとして明確なファイルを添付した方が、初回で期待通りの結果が得られる確率が圧倒的に高くなることが示されています。プロンプトを長々と書く労力を、ファイルの整備に向けるのが成功の第一歩です。
- 明文化と「マスターリファレンス」の活用: 「AI特有の不自然な言い回しを避ける」「特定のフォーマットを厳守する」といった、個人的にAIに求める品質基準や禁止用語は、「運用者権限ドキュメント(Operator Authority)」として明文化し、毎回AIに読み込ませましょう。さらに、数日間にわたるような長期間の業務では、AIの記憶力に頼ってはいけません。これまでの決定事項や設計の変更点をまとめた「マスターリファレンス」というファイルを一つ作り、業務が進むたびに更新してAIに与え続けることで、常に最新の前提条件を正確に共有できます。
- ツールの特性に合わせた意図的な使い分け: すべての作業を1つのAIで完結させる必要はありません。タスクの特性に合わせて、AIツールを意図的に使い分けることが重要です。たとえば、大量のファイルを読み込んで複雑な成果物を構築する作業は「Claude」に任せ、対話的なフィードバックや検証(Auditor)には「ChatGPT」を使用し、ソースコードのリポジトリ操作には専用の「Codex」を活用する、といったアプローチが実務では非常に効果的です。
- 成功パターンのテンプレート化(Type Library): うまくいった情報パッケージの構成は、その場限りにせず、業務領域ごとにテンプレート化(Type Library)していくことを推奨します。たとえば、「議事録の要約用」「コードレビュー用」といった用途別に、どのような情報と制約をセットで渡すべきかを蓄積し、次の類似業務で再利用します。実績のあるテンプレートを使い回すことで、ゼロから指示を考える手間が省け、AIを活用するたびに継続的な業務効率の向上が期待できます。
おわりに
コンテキスト・エンジニアリングの実践とは、AIへの指示を場当たり的に行う段階から脱却し、AIに渡す情報と作業プロセスを構造化する「エンジニアリング」へと昇華させる取り組みです。
期待通りの出力を安定して得るためには、AIの能力やプロンプトのテクニックに頼るだけでなく、人間側が提供する背景情報の質と構造を整える必要があります。本記事で解説した手法の根底にあるのは、「AIの振る舞いを適切に制御するためには、まずAIに与える情報そのものを制御しなければならない」という原則です。
属人的な指示の繰り返しから、明確な情報の優先順位と検証段階を持つプロセスへと移行することで、AIとの協働はより確実なものになります。日々の業務におけるAI活用の見直しと、継続的な品質改善のヒントとしてぜひご活用ください。
More Information
- arXiv:2604.04258, Elias Calboreanu, 「Context Engineering: A Practitioner Methodology for Structured Human-AI Collaboration」, https://arxiv.org/abs/2604.04258
関連記事

LangChain×ローカルLLMで試すText-to-SQL入門
「あのデータが見たいけど、SQLなんて書けない…」そんな悩みを抱えていませんか?日々増え続ける膨大なデータの中から必要な情報を引き出すスキルは、現代のビジネスにおいてますます重要になっています。しかし、専門知識であるSQ […]

YOLOv12: アテンション機構による高速物体検出
近年、深層学習を用いたコンピュータービジョンは目覚ましい進化を遂げ、私たちの生活やビジネスに大きな変革をもたらしています。特に物体検出技術は、自動運転、監視システム、医療画像解析など、幅広い分野で不可欠な技術となっていま […]

宇宙物理学×深層学習:基礎アーキテクチャからAIエージェントまでを概観する
現代の天文学は、Vera C. Rubin天文台やRoman宇宙望遠鏡などに代表される次世代の観測サーベイの稼働により、かつてない規模のデータ主導型科学へと急激に移行しています。こうした膨大なデータを前にして、従来の解析 […]