Meta-Harness: AIエージェントの性能を引き出す最適化手法

大規模言語モデル(LLM)を活用したシステムを開発していると、「モデル単体は高性能なのに、システムに組み込むと思うように精度が出ない」という壁にぶつかることがよくあります。これは、システムの最終的な性能が、モデルの重みそのものだけでなく、プロンプト構築や情報検索、文脈管理などを担う「ハーネス(周辺コード)」の設計に強く依存しているためです。
これまで、こうしたハーネスの最適化には、実行結果をスコアや短い要約テキストに圧縮してLLMにフィードバックする手法が主流でした。しかし、タスクが複雑になるほど、圧縮された情報だけでは「システムのどの部分がボトルネックになって失敗したのか」という根本的な原因を特定することが困難になります。
この記事では、この課題に対する新しいアプローチとして提案された「Meta-Harness」を紹介します。これは、過去の生ソースコードや詳細な実行トレースをファイルシステム経由で探索エージェントに直接読み込ませ、原因分析とコードの修正を自動で進める最適化手法です。
1. Meta-Harnessの基本概念とアーキテクチャ
ファイルシステム経由の生ログ解析
これまでのプロンプト最適化やコード改善の手法は、直前の実行結果を短いサマリテキストやスコアに圧縮して、LLMにフィードバックするアプローチが主流でした。しかし、記憶管理や情報検索などの複雑な処理が絡み合うハーネスの最適化においては、この「情報の圧縮」が足かせになります。「あるステップでの小さな文脈の欠落が、数十ステップ後の致命的な失敗を引き起こす」といったように、長期間にわたる処理では結果のサマリだけから根本原因を特定することが非常に難しいからです。
Meta-Harnessは、この問題を解決するために「ファイルシステム経由の生ログ解析」というアプローチを採用しています。過去のすべてのソースコード、スコア、そして数百万トークンにも及ぶ生の実行トレースを圧縮せずに、そのままファイルシステムに保存します。そして、探索エージェント(コーディングエージェント)が grep や cat といったエンジニアにお馴染みのコマンドを用いて、膨大なログの中から必要な情報を自由に検索・分析します。情報がサマリによって欠落しないため、エージェントは「どのコードの変更が、どのようなバグを引き起こしたのか」を具体的な実行結果から正確にたどり、的確な修正案を提示できるようになります。
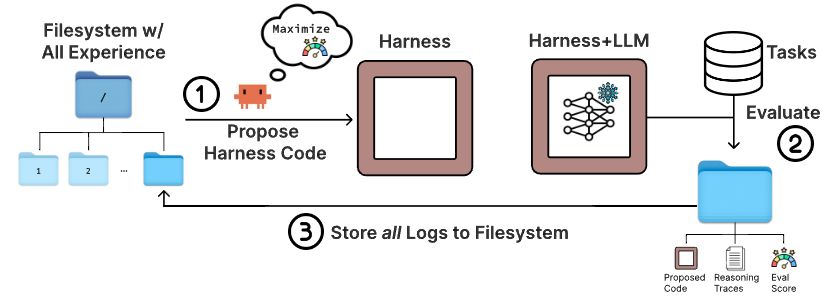
パレートフロンティアに基づく最適化
また、LLMシステムの実運用を考えると、単純な「正答率(Accuracy)」だけを追い求めるわけにはいきません。プロンプトに含める情報(コンテキスト)を増やせば精度は上がる傾向にありますが、同時にAPIの利用コストや推論のレイテンシも増加してしまいます。
そこでMeta-Harnessでは、精度とコンテキスト長(消費トークン数)のトレードオフを評価し、「パレートフロンティア」に基づく最適化を実施します。パレートフロンティアとは、一方の指標を悪化させずに他方の指標をこれ以上改善できない、最適な選択肢の集合(境界線)のことです。この概念を取り入れて様々な候補を評価することで、「とにかく精度を最大化したい」「少し精度は落ちてもいいから、軽量で高速に動くハーネスが欲しい」といった、実際のプロジェクトの用途や予算に合わせた最適な構成を柔軟に選択できるようになります。
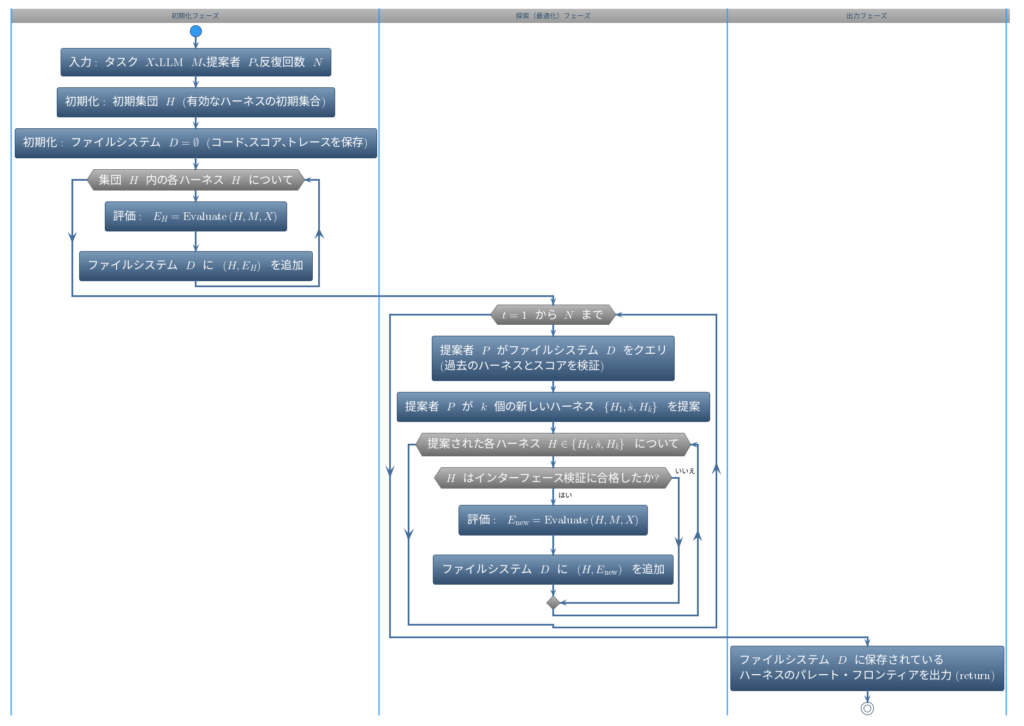
アルゴリズム
- 初期化フェーズ: 最初に有効なハーネスの初期集団(\(\mathcal{H}\))と、これまでの履歴を保存するためのファイルシステム(\(\mathcal{D}\))を準備し、初期集団の各ハーネスを評価してファイルシステムに記録します。
- 探索(最適化)フェーズ: 反復処理(\(N\)回)の中で、コーディングエージェントである提案者(\(P\))がファイルシステムから過去のコードやスコア、実行トレースをクエリして検証します。
- 提案と評価: 提案者が新たに\(k\)個のハーネスを提案し、それぞれがインターフェース検証に合格した場合のみ評価を実行し、その結果をファイルシステムに追加します。
- 出力: 最終的に、蓄積された結果の中から最も優れたハーネス群(パレート・フロンティア)を返します。
2. 探索と最適化の運用設計
Meta-Harnessの枠組みを実際のプロジェクトに適用するにあたり、効率よく探索ループを回すための運用設計が欠かせません。ここでは、実践から得られた具体的なノウハウを4つの観点からご紹介します。
探索エージェント(Proposer)の「スキル」定義
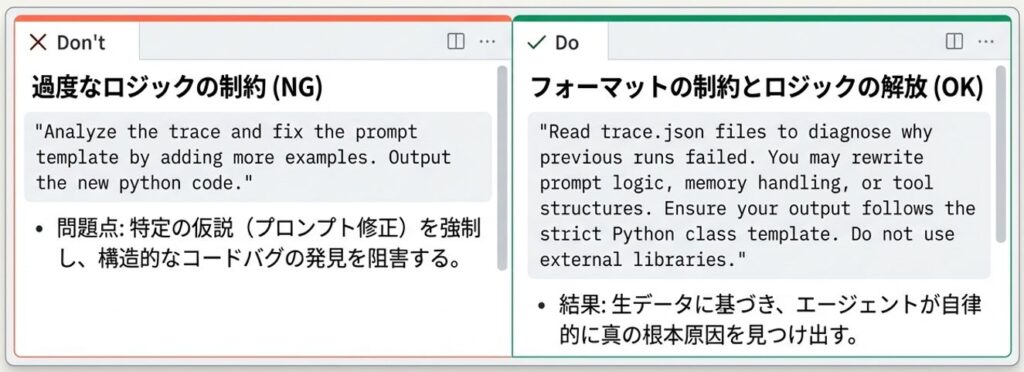
探索を主導するエージェント(Proposer)には、自然言語で記述した「スキル(Skill)」を与えて動作をコントロールします。このスキル定義は、探索の成否を分ける最も重要な要素です。
コツは、「出力形式」や「禁止事項」といった制約は厳密に定義しつつ、「どのようにバグを診断するか」というアプローチ自体はエージェントの自由に任せることです。
- 指定すべきこと: ディレクトリ構造、利用可能なCLIコマンド、最終的なコードの出力形式、最適化の目標、および変更してはいけないファイルなどの禁止事項。
- 任せるべきこと: どの過去ログを参照し、どのようにスコアやトレースを比較するかという具体的な分析手順。
これにより、エージェントは過去の様々な実行トレースを自由に探索し、想定外の根本原因を自律的に発見できるようになります。
探索用データセットの最適化
評価のたびに大規模なデータセットを処理していては、時間とAPIコストが膨れ上がってしまいます。そのため、探索用には50〜100件程度の少数のデータセットを構築するのが効果的です。
具体的な構築手順としては、まず「Few-shotプロンプティング」などのシンプルなベースラインを用意します。そして、そのベースラインモデルが間違えやすい、難易度の高い問題だけをフィルタリングしてデータセットにまとめます。すでに正解できる簡単な問題を含めても最適化の余地が少ないため、少数の難しいデータに絞り込むことで、少ない評価回数(コスト)でモデルの改善度合いを明確に測ることができるようになります。
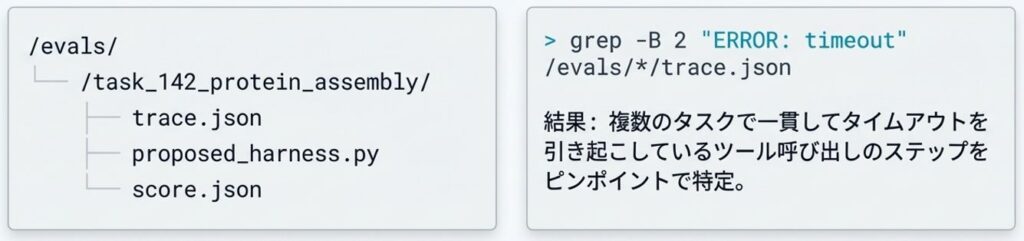
検索・分析に最適化したログ構造
エージェントはファイルシステムを通じて過去の履歴を分析するため、ログの保存形式が探索の効率を大きく左右します。
- 機械可読なフォーマット: コード、スコア、生の実行トレースはJSONなどの機械可読な形式で保存します。
- 整理されたディレクトリ構造: 階層的にフォルダを整理し、一貫性のあるファイル名を付けることで、エージェントが正規表現(Regex)検索などを活用して必要な情報を簡単に抽出できるようにします。
- 専用の軽量CLIツール: さらに、パレートフロンティア上のモデルを一覧表示したり、過去の実行結果の差分(Diff)を比較したりできる簡単なCLIツールを用意しておくと、エージェントがログの海に迷うことなく、無駄なトークン消費を抑えながら効率よくナビゲーションできるようになります。
軽量なバリデーションの導入
新しく提案されたハーネスを本格的な評価パイプラインに投入する前に、数秒で終わる軽量なバリデーションテストを組み込むことを強く推奨します。
モジュールのインポートやクラスのインスタンス化が正常にできるか、あるいはごく少数のテストデータでメソッドが動作するかといった簡単なチェックを実施するスクリプトを用意しておきます。これにより、文法エラーや明らかに機能しないコードを即座に弾くことができ、時間のかかる評価環境で無駄なリソースやAPIコストを消費してしまう事態を未然に防げます。

3. エージェントの制御とツール実装 (Agentic Coding)
このセクションでは、Meta-Harnessの実際のコードベースから読み取れる、エージェントを安定的かつ効率的に動作させるための実践的な実装テクニックを3つご紹介します。
ネイティブなTool Callingへの移行
従来のLLMエージェント開発では、モデルにJSONやXML形式でテキストを出力させ、それをシステム側でパース(解析)してコマンドを実行するアプローチがよくとられていました。しかし、この方法はLLMの出力フォーマット崩れやエスケープ処理のミスなどによって、システム全体が不安定になりやすいという課題を抱えています。
そこで実装上強く推奨されるのが、LLMが提供するネイティブな「Tool Calling(関数呼び出し)」機能への完全な移行です。具体的には、以下のようなツールをAPIのパラメーターとして明確に定義してエージェントに提供します。
execute_commands: ターミナルでコマンドを実行するimage_read: 画像ファイルを読み込み、視覚的な情報を得るtask_complete: タスクの完了をシステムに宣言する
これにより、面倒なパース処理から解放され、より堅牢で安定した制御ループを構築できるようになります。
マーカーを用いた早期完了検知
エージェントがターミナルでコマンドを実行する際、「実行完了までどれくらい待つべきか」をシステム側が判断するのは困難です。安全を見て待機時間(Sleep)を長めに設定すると無駄な待ち時間が増え、逆に短くするとコマンドの実行途中で出力を切り取ってしまいます。
これを解決する賢いテクニックが「マーカーを用いた早期完了検知」です。エージェントがコマンドを実行する際、その直後に echo '**CMDEND**1**' のような一意のマーカーテキストを出力するコマンドをシステム側で自動的に連結して送信します。そして、短い間隔でターミナルの出力をポーリング(監視)し、このマーカーが出現した瞬間に「コマンドが完了した」と判定して次の処理に進みます。この工夫を取り入れることで、実行時の無駄な待機時間を大幅に削減し、エージェントの動作を高速化できます。
環境スナップショット(Environment Bootstrapping)
エージェントに新しい環境でタスクを与えると、最初の数ターンを pwd(現在のディレクトリの確認)や ls(ファイル一覧の確認)、python3 --version といった「環境の調査」だけで消費してしまうことがよくあります。タスクの実行回数に制限がある場合やAPIコストを考慮すると、これは大きなロスになります。
この無駄を防ぐために有効なのが、「環境スナップショット(Environment Bootstrapping)」と呼ばれる手法です。これは、エージェントへの初回プロンプトを実行する前に、システム側で自動的に軽量なシェルコマンドを走らせ、以下のような環境情報を収集してプロンプトに注入する仕組みです。
- 現在の作業ディレクトリと、主要なディレクトリ内のファイル一覧
- 利用可能なプログラミング言語(Python, GCC, Nodeなど)
- 利用可能なパッケージマネージャー(pip, apt-getなど)とメモリの空き状況
これにより、エージェントは最初から環境の前提条件を完全に把握した状態でスタートできるため、不要な初期探索を2〜5ターンほど省くことができ、本質的なタスクの解決にすぐさま取り組めるようになります。
4. プロンプト構築と検索パイプライン (Retrieval & Context)
LLMの精度を最大限に引き出すためには、プロンプトに含めるコンテキスト(文脈情報)の質が鍵を握ります。ここでは、動的な情報検索(Retrieval)を組み合わせて高品質なコンテキストを構築しつつ、APIコストを抑える実践的なパイプラインの設計手法を解説します。
動的な対照例を用いたコンテキスト構築
テキスト分類タスクにおいて、固定の例を提示するだけの単純なFew-shotプロンプティングには限界があります。システムが自律的に発見した最適化手法の中には、モデルの仮の予測(ドラフト)に基づいて動的にプロンプトを組み立てる戦略が存在します。
代表的なアプローチとして以下の2つが挙げられます。
- Draft Verification(ドラフト検証): 最初に数件の類似データを検索して、モデルに「仮の予測(ドラフト)」を立てさせます。その後、その予測と同じラベルを持つ「関連例(Confirmers)」と、あえて異なるラベルを持つ「対照的な例(Challengers)」を追加で検索してプロンプトに組み込み、モデルに回答を維持するか修正するかを最終確認させます。
- Label-Primed Query(ラベル先行クエリ): 最初にすべてのクラスラベルを提示して、モデルに全体像を把握させます。さらに、現在の入力に似ているもののラベルが異なる「対照的なペア(Contrastive pairs)」を提示することで、モデルが境界線(どこからが別の分類になるのか)を正確に判断できるように支援します。
ハイブリッドな検索(RAG)パイプライン
検索拡張生成(RAG: Retrieval-Augmented Generation)を構築する際、すべての質問に対して同じ検索アルゴリズムを適用するのは非効率です。例えば数学の問題を解くシステムでは、問題文に含まれるキーワードや正規表現(Regex)の字句を解析し、問題を「幾何」や「整数論」といったドメインごとに分類する軽量なルーターの導入が効果的です。
これにより、分野ごとに最適な検索ルールを動的に切り替えることが可能になります。
- 組合せ数学: 多数の候補を取得してから重複を排除し、難易度で再ランク付け(Reranking)を実施して上位数件に絞り込みます。
- 幾何: 複雑な再ランク付けは避け、構造的に一致する少数の検索結果をそのまま提示します。
このように、入力の特性に合わせて検索件数や再ランク付けのルールを柔軟に変化させる戦略が、様々なタスクにおいてRAGの精度向上に直結します。
プロンプトキャッシュによる最適化
上記のような高度なコンテキスト構築を実装すると、必然的にプロンプトが長くなり、APIの利用コストや応答速度(レイテンシ)の悪化を招きます。
この課題を解決する実装パターンとして、Anthropic APIなどが提供するプロンプトキャッシュ機能の活用が挙げられます。システムの実装では、会話履歴の最新のメッセージ群に対して cache_control: {"type": "ephemeral"} というプロパティを動的に付与する仕組みが組み込まれています。構築した複雑なコンテキストをシステム側で効率的にキャッシュすることで、長いプロンプトを使用する際のコストとレイテンシの増加を大幅に抑制しながら、高度なプロンプトエンジニアリングを実運用で活用できるようになります。
5. デバッグと継続的改善
複雑なLLMシステムでは、良かれと思って加えた変更が予期せぬバグを引き起こすことがよくあります。ここでは、実行ログを詳細に分析することで、システムを継続的に改善していくための実践的なデバッグ手法をご紹介します。
交絡(Confounding)要因の特定と切り分け
ハーネスを修正した結果、システムの性能が低下(リグレッション)してしまうことがあります。このとき、複数の変更を同時に加えていると、何が原因なのかを特定するのが難しくなります。
実際のシステム探索の過程でも、コードの構造的なバグ修正とプロンプトの変更を同時に実施した結果、スコアが大幅に低下するケースがありました。しかし、過去のすべての実行トレースを振り返ることで、真の失敗原因は構造の修正ではなく、「プロンプトにクリーンアップの指示を追加したこと」にあると特定できました。このように、失敗の根本原因が「プロンプト」にあるのか「制御コード」にあるのかをログから切り分け、疑わしい変更を一つずつ元に戻して仮説を検証していくアプローチが、確実な性能改善に繋がります。
状態遷移バグの特定と修正
エージェントに自律的な行動を任せると、予期せぬ状態遷移のバグに直面することがあります。
典型的な例として、タスク自体は正しく完了しているにもかかわらず、エージェントが「念のための確認作業」を何度も繰り返してしまい、無限ループに陥るというバグがありました。生の実行ログを分析すると、エージェントが確認コマンドを実行するたびに、システム側の「完了待ちフラグ(_pending_completion)」が意図せずリセットされていることが判明しました。結果として、エージェントは毎回最初の確認プロセスに戻されてしまっていたのです。
この場合、該当する不要なフラグリセットのコードを削除することで、エージェントはスムーズにタスクを終了できるようになります。生の実行トレースを追いかけることで、こうした「モデルの思考」と「システムの状態」のズレによるバグを素早く発見し、適切なコード修正に結びつけることができます。
おわりに
LLMの性能を真に引き出すためには、モデル自体の改善に留まらず、その周辺を支える「ハーネス」のアーキテクチャを持続的にアップデートしていくことが不可欠です。
今回ご紹介したように、実行ログの構造化やネイティブなTool Callingへの移行、プロンプトキャッシュ機構の導入といった、システムの深層に踏み込んだコードレベルの最適化に取り組むことが、より安定した実運用システムをもたらします。
エージェントを用いた自動探索手法「Meta-Harness」から得られた数々の実践的なナレッジは、AIの自律的な進化の可能性を示すだけでなく、私たち人間のLLMエンジニアにとっても大変価値のあるものです。これらの知見は、皆さんが今後さらに堅牢でスケーラブルなAIアプリケーションを構築していくための強力な指針となるはずです。
More Information
- arXiv:2603.28052, Yoonho Lee et al., 「Meta-Harness: End-to-End Optimization of Model Harnesses」, https://arxiv.org/abs/2603.28052
関連記事

LSNet-人間の視覚から着想を得た軽量かつ高性能な畳込みニューラルネットワーク
近年、コンピュータビジョンの分野では、目覚ましい発展を遂げた深層学習モデルが、その計算コストの高さから、実用的な課題に直面しています。特に、リアルタイム性が求められるアプリケーションや、計算資源に制約のあるモバイルデバイ […]

Code as Agent Harness: AIエージェントを自律駆動させるためのアーキテクチャ
LLM(大規模言語モデル)の進化により、AIエージェントの開発が急速に進んでいます。しかし、複雑なタスクを長期間にわたって自律的に実行させるには、自然言語による指示だけでは限界があります。 現在、LLMにとって「コード」 […]

距離学習入門 ~様々なタスクに応用できる機械学習手法~
距離学習(Metric Learning)は、データ間の類似度を学習する 機械学習の一手法です。従来の教師あり学習が、与えられたデータから特定のラベルや値を予測することを目的とするのに対し、距離学習は、データ間の関係性そ […]