Helixで実践する透明性と信頼性の高い機械学習
現代科学では膨大なデータが生まれ、機械学習(ML)の活用が不可欠な一方で、その分析結果の「透明性」と「信頼性」が重要課題となっています。特に、データサイエンスの専門知識がなくても、分析プロセスを理解し、結果を効果的に活用できるツールの需要が高まっています。
この課題に応えるのが、オープンソースでPythonベースのMLフレームワークである「Helix」です。Helixは、表形式の科学データに特化し、データ前処理からモデル解釈までを再現可能かつ解釈可能な形で統合します。直感的なGUIを通じて分析過程を記録し、FAIR原則(Findable, Accessible, Interoperable, Reusable)に準拠することで、実務者のML活用を支援し、成果の信頼性を保証します。
本記事では、Helixが「透明性と信頼性の高い機械学習」をどのように実現するのか、その詳細を解説します。
Helixとは?
現代の科学研究では日々膨大なデータが生成され、機械学習(ML)の活用は不可欠になっています。しかし、その分析結果の透明性と信頼性を確保し、データサイエンスの専門家ではない実務者でも活用できるツールが求められています。このようなニーズに応えるべく開発されたのが、オープンソースのPythonベースMLフレームワーク「Helix」です。
科学データ分析のための包括的フレームワーク
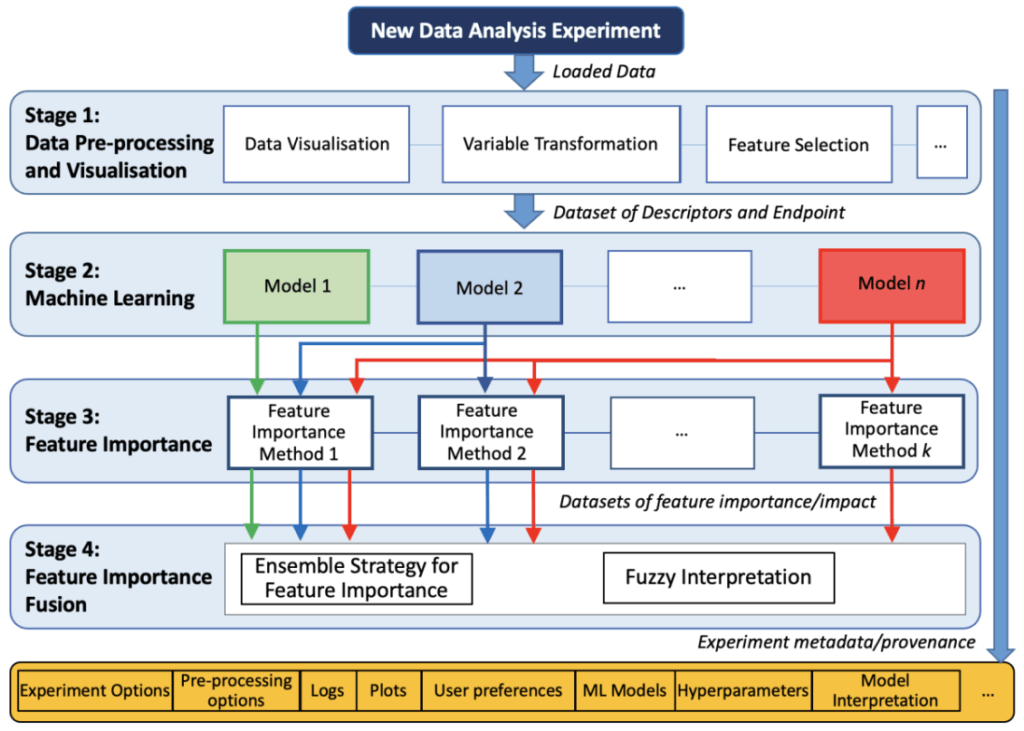
Helixは、表形式の科学データに特化した、再現可能で解釈可能な機械学習ワークフローを促進するためのオープンソースかつ拡張性の高いソフトウェアフレームワークです。その主な目的は、透明性の高い実験データ分析の来歴(Provenance)を確保することにあります。これにより、データ変換や手法の選択を含む分析プロセス全体が、関連するステークホルダーにとって文書化され、アクセス可能で、再現性があり、理解しやすい状態となることを保証します。
Helixは、もともとバイオマテリアル発見における定量的構造-特性関係(QSPR)モデリングのために開発されましたが、表形式の分類または回帰タスクに幅広く適用可能です。
主な機能モジュール
Helixプラットフォームは、以下の主要なモジュールで構成されており、機械学習のライフサイクル全体をサポートします:
- 標準化されたデータ前処理:データの正規化、変換、特徴選択の機能を提供します。
- 可視化:データセットの概要、正規性テスト、目的変数の分布、相関ヒートマップ、ペアプロット、t-SNEプロットなど、多様な統計情報やグラフを用いてデータを探索・分析できます。
- 機械学習モデルの訓練:ランダムフォレスト、勾配ブースティング、サポートベクターマシン、ロジスティック回帰(分類問題用)、多重線形回帰(回帰問題用)などのアルゴリズムをサポートし、ハイパーパラメーター最適化のオプションも提供します。
- 評価:各アルゴリズムの性能指標や予測結果、モデルの性能を示すプロットを確認できます。
- 解釈:モデルの意思決定においてどの変数が最も重要か、また変数の値が最終的な予測に与える影響といった情報を提供します。順列重要度、SHAP、LIMEといったグローバルおよびローカルな特徴量重要度手法を実装しており、自然言語の「if-then」ルールを用いた解釈も可能です。
- 結果の検証:すべての分析結果はHelixのインターフェース内で要約して視覚化され、分析ワークフローの監査やチーム間のコミュニケーションを促進します。
- モデル予測(デプロイ):訓練済みモデルを使用して新しいデータに対して予測を実行できます。
これらの機能は、Streamlitによって実装された直感的なグラフィカルユーザーインターフェース(GUI)を通じてアクセス可能であり、OSを選ばずにWebブラウザから直接利用できます。
「透明性と信頼性」を支えるProvenance(来歴管理)
Helixは、FAIR(Findable, Accessible, Interoperable, Reusable)原則に準拠しています。この原則に基づき、データ分析ワークフローの来歴を体系的に捕捉・保存することで、分析プロセスが透明で追跡可能かつ再現可能であることを保証します。
機械学習パイプラインの各段階—データ前処理の決定、モデルの構成、性能指標、特徴量重要度の結果など—で詳細なメタデータを記録することで、研究者は以前の分析を再確認し、監査することができ、チームメンバー、プロジェクト、機関全体での知識移転と再利用を促進します。この構造化された分析選択の記録は、Helixの出力をより広範な計算エコシステムに統合することで、相互運用性もサポートします。
専門家をエンパワーメントする設計思想
Helixは、データサイエンスの正式な訓練を受けていない研究者でも、意味のある実用的な洞察を引き出せるように支援することを目的としています。使いやすさ、柔軟性、方法論的な厳密さのバランスを取ることで、ドメイン科学者の参入障壁を下げ、彼らがコード開発に時間を費やすのではなく、分析結果の解釈と利用に集中できるようにします。
分析の来歴が自動的に記録されることで、厳密な報告が可能となり、成果の信頼性と再現性の信頼性が高まります。これにより、特に生物材料科学、工学、化学、ヘルスケア、生命科学といった分野で、データ駆動型の発見を加速し、合理的な設計と意思決定をサポートすることが期待されています。
Helixの使い方
Helixは、データ分析の専門知識がない実務者でも、直感的なGUIを通じて、機械学習ワークフローを簡単に実行できるように設計されています。ここでは、Helixをインストールして、実際にデータ分析を行うまでの主要なステップを順に解説します。
インストールと起動
Helixの使用を開始するには、まず使用している環境にインストールする必要があります。
- 前提条件:
- Python 3.11 または 3.12 が必要
- 事前にOpenMPのインストールが必要
- Macを使用している場合:
brew install libomp - Linux (Ubuntu)を使用している場合:
sudo apt install libomp-dev
- Macを使用している場合:
- インストール方法:
pipを使ってHelixをインストール:pip install helix-ai
- Helixの起動:
- ターミナルで以下のコマンドを実行:
helix
- ターミナルで以下のコマンドを実行:

新規実験の作成
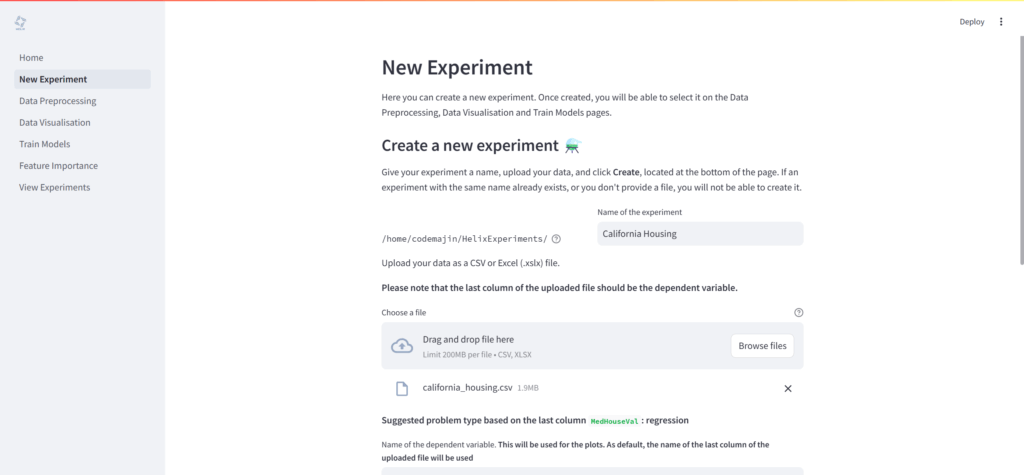
Helixで分析を始めるには、「New Experiment」ページで新しい実験を設定します。
- 実験名とデータファイルの指定:
- 実験の名前を入力し、分析に使用するCSVまたはXLSX形式のデータファイルを選択
- すでに同じ名前の実験が保存されている場合、新しい実験を作成することはできない
- ターゲット変数と問題タイプの選択:
- 予測したい「目的変数(dependent variable)」の名前を指定
- プロットの表示にも使用される
- 問題の種類を「Classification(分類)」または「Regression(回帰)」から選択
- 予測したい「目的変数(dependent variable)」の名前を指定
- ランダムシードの設定:
- 結果の再現性を確保するために、ランダムシードを指定
- プロット設定の構成:
- 生成されるプロットの保存設定、幅、高さ、解像度(DPI)、軸ラベルの回転角度、フォントサイズ、配色などを細かくカスタマイズ可能
- 「Create」ボタンを押下:
- すべての設定が完了したら、「Create」ボタンをクリックして実験設定を保存
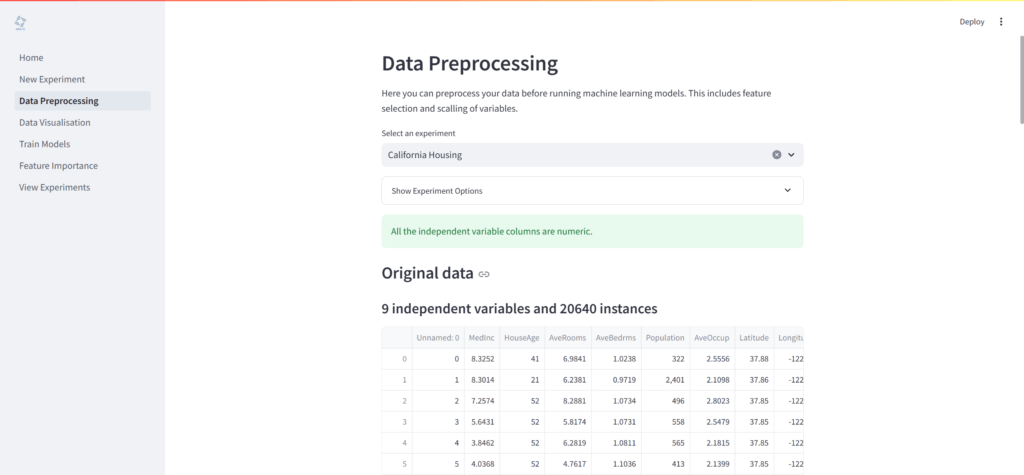
データの前処理
データの前処理は、機械学習モデルの性能に大きく影響する重要なステップです。Helixでは、「Preprocessing your data」ページで以下の処理を行えます。
- 独立変数の正規化:
- Standardisation(標準化): 各変数の平均を0、値を-1から1の間にスケーリング
- Minmax: 各変数の値を0から1の間にスケーリング
- None: 正規化を適応しない
- 目的変数の変換(回帰問題のみ):
- Log(自然対数)、Square-root(平方根)、Minmax、Standardisation、None から選択可能
- 分類問題の場合、目的変数の正規化はできない
- 特徴量選択:
- データセットから不要な特徴量を除去し、モデルの複雑性を軽減する
- Variance threshold: 分散が低い特徴量を除去
- Correlation threshold: 互いに相関の高い特徴量を除去
- Lasso Feature Selection: LASSOアルゴリズムを用いて特徴量を選択
- データセットから不要な特徴量を除去し、モデルの複雑性を軽減する
- 実行:
- 設定後、「Run Data Preprocessing」をクリックすると、前処理が実行され、処理されたデータのコピーが実験フォルダに保存される。
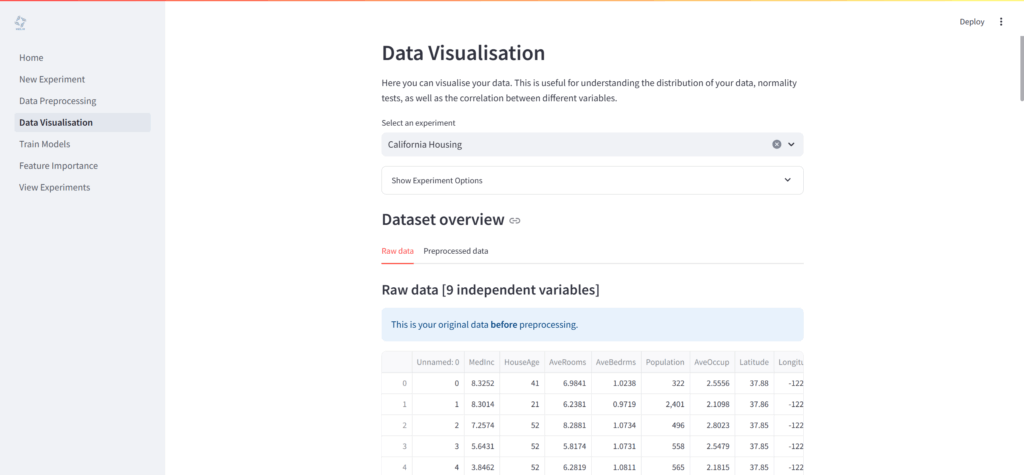
データの可視化
「Data Visualisation」ページでは、データセットを視覚的に探索・分析するための多様なツールが提供されています。
- データセットの概要: 前処理前後のデータ概要、各変数の正規性テスト結果を確認可能
- 目的変数の分布: ヒストグラムやKDE(カーネル密度推定)を用いて、目的変数の分布を可視化
- 相関ヒートマップ: 選択した特徴量間の相関関係を視覚的に把握できる
- ペアプロット: 選択した特徴量間の散布図を網羅的に表示し、傾向や相互作用を特定
- t-SNEプロット: 高次元データを2次元で可視化し、データポイントのクラスタリングや構造を理解するのに役立つ。
- 可視化の保存: 生成された各プロットは個別に保存でき、報告書やプレゼンテーションに活用可能
機械学習モデルの訓練
「Train Models」ページでは、データセットを用いて様々な機械学習モデルを訓練・評価できます。
- ハイパーパラメータ最適化:
- デフォルトでは、ハイパーパラメータの自動検索(分類問題では精度、回帰問題ではR2スコアに基づき最適化)が有効
- 手動でハイパーパラメータを設定することも可能
- サポートされているアルゴリズム:
- Helixは、以下の主要なアルゴリズムをサポートしている。
- 分類問題: ランダムフォレスト、勾配ブースティング(XGBoost)、サポートベクターマシン、ロジスティック回帰
- 回帰問題: ランダムフォレスト、勾配ブースティング(XGBoost)、サポートベクターマシン、多重線形回帰
- Helixは、以下の主要なアルゴリズムをサポートしている。
- モデルの選択と設定: 訓練したいモデルを選択し、必要に応じてハイパーパラメータを設定
- 出力の保存: 訓練されたモデルと関連するプロットをディスクに保存するオプションあり
- 訓練の実行: 「Run Training」ボタンをクリックすると、モデルの訓練と評価が開始され、各アルゴリズムの性能指標や予測結果が表示される

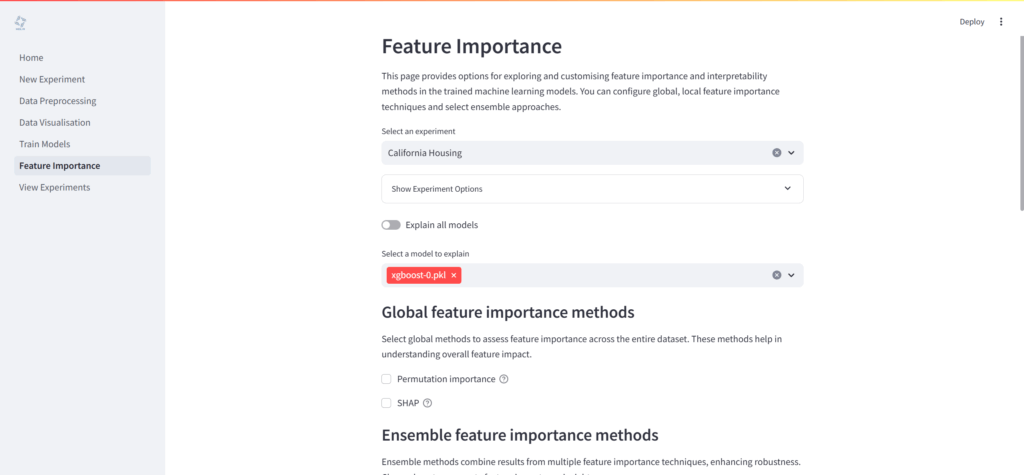
モデルの解釈(特徴量重要度)
「Feature Importance」ページでは、訓練済みモデルがどのように意思決定を行っているかを解釈するためのツールが提供されます。
- グローバル特徴量重要度: モデル全体における各特徴量の影響度を評価
- Permutation importance
- SHAP (SHapley Additive exPlanations)
- アンサンブル特徴量重要度:
- 複数のグローバル特徴量重要度手法の結果を組み合わせて、より堅牢な重要度スコアを生成(例:平均、多数決)。
- ローカル特徴量重要度: 個々の予測に対して、どの特徴量が最も影響を与えたかを詳細に分析
- LIME (Local Interpretable Model-agnostic Explanation)
- SHAP
- ファジー特徴量融合:
- Helixの独自の機能として、自然言語の「if-then」ルールを用いて、複雑なモデルの意思決定を人間が読みやすい形で解釈することが可能
- 特に非線形モデルにおける特徴量間の相乗効果を理解するのに役立つ
- 実行: 設定後、「Run Feature Importance」ボタンをクリックすると分析が実行され、解釈結果が可視化される
結果の閲覧とモデルの再利用
Helixは、分析の透明性と再現性を高めるために、すべての結果とプロセスを詳細に記録します。
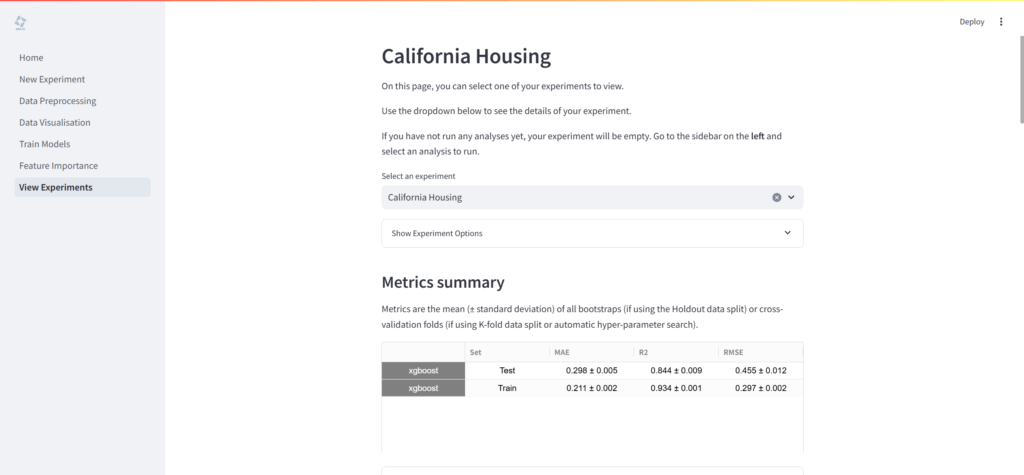
- 実験結果の閲覧:
- 「View Experiments」ページでは、すべての分析結果(訓練されたモデルの性能指標、生成されたプロット、特徴量重要度の結果など)をまとめて確認可能
- 分析ワークフローの監査やチーム内での情報共有が容易になる
- 来歴管理(Provenance Tracking):
- Helixは、FAIR原則に準拠し、データ前処理の選択、モデル構成、性能指標、特徴量重要度の結果など、機械学習パイプラインの各段階の詳細なメタデータを自動的に記録し、ローカルフォルダに保存
- これにより、分析プロセスが透明で追跡可能かつ再現可能であることが保証され、過去の分析の再確認や、知識の移転と再利用が促進される
- モデルのデプロイ(予測への利用):
- HelixのGUIには「Predict」ページがあり、訓練済みのモデルを使用して新しいデータに対して予測を実行できます。ユーザーは独立変数を含むCSVファイルを提供し、Helixは元の訓練データと同じ変換を適用して予測を生成
- また、訓練済みモデルは .pkl(pickleファイル) 形式でローカルに保存されるため、必要に応じて 外部のPythonスクリプト から読み込んで再利用することも可能
- この際、元の訓練データと同じ前処理を新しいデータに適用することが重要
おわりに
これまでに解説した通り、Helixは表形式データに対する再現性と解釈性に優れた機械学習ワークフローを、データサイエンスの専門知識が少ない実務者でも直感的に利用できるよう設計されたオープンソースフレームワークです。データの前処理から可視化、モデル訓練、解釈、そして結果の包括的な閲覧・再利用に至るまで、一貫した統合環境を提供します。
特に、FAIR原則に準拠し、分析の各段階における詳細な来歴(プロブナンス)を自動記録することで、分析の透明性、追跡可能性、再現性を保証します。生体材料科学、化学、医療といった多岐にわたる分野での応用事例が示すように、Helixは複雑な科学データの分析を加速し、実践的な洞察を導き出す強力な手段となります。今後、より高度な機能拡張も期待されており、研究現場におけるデータ駆動型発見の重要な基盤となります。
More Information
- arXiv:2507.17791, Eduardo Aguilar-Bejarano et al., 「Helix 1.0: An Open-Source Framework for Reproducible and Interpretable Machine Learning on Tabular Scientific Data」, https://www.arxiv.org/abs/2507.17791
関連記事

Code as Agent Harness: AIエージェントを自律駆動させるためのアーキテクチャ
LLM(大規模言語モデル)の進化により、AIエージェントの開発が急速に進んでいます。しかし、複雑なタスクを長期間にわたって自律的に実行させるには、自然言語による指示だけでは限界があります。 現在、LLMにとって「コード」 […]

MinT: LLMを効率的に管理する次世代インフラ
近年、LLM(大規模言語モデル)の運用において、タスクやユーザーごとにモデルを微調整してデプロイする機会が増加しています。しかし、細分化されたバリアントごとにフルサイズのチェックポイントをコピーしたり移動させたりする従来 […]

GradCAM: 深層学習モデルの判断根拠を可視化してみる
深層学習は、画像認識、自然言語処理など、様々な分野で応用されています。しかし、深層学習モデルは、非常に複雑な構造のため、なぜそのような判断を下すのか、その根拠を人間が理解することが困難です。 このブラックボックスである機 […]