音声ディープフェイク検出の最前線
深層学習の目覚ましい進化は、音声合成技術に革命をもたらしました。これは、パーソナライズされた仮想アシスタントの実現や、発話能力を失った方々が再び「声」を取り戻す手助けをするなど、計り知れない利益をもたらす可能性を秘めています。しかし、その強力さゆえに、この技術は諸刃の剣ともなり得ます。金融詐欺、偽情報の拡散、個人の評判毀損といった悪意ある目的に利用される深刻な脅威を内包しています。実際に、企業のCEOの声を模倣したディープフェイク音声による不正送金事件の報告は、その危険性を明確に示しています。
本物の人間の声と合成された音声との境界線は、生成技術の向上に伴い、ますます曖昧になっています。私たちの聴覚だけでは、その違いを見分けることが困難になりつつあり、堅牢な自動検出システムの開発が喫緊の課題です。生成技術と検出技術が互いに高め合いながら進化する、いわば「軍拡競争」 の時代において、検出技術の継続的な発展は不可欠と言えます。
今回は、音声のディープフェイクに焦点を当てて、このテーマの最前線で何が起きているのか、本記事で深掘りしていきます。
音声ディープフェイクの作り方
音声ディープフェイクの脅威を深く理解するためには、まずその生成技術の仕組みを知ることが不可欠です。これらの技術は急速に進化しており、本物の音声と区別することがますます困難になっています。主要な生成技術は以下の通りです。
特定の声を複製するボイスクローニング
ボイスクローニング (Voice Cloning) は、特定の個人の声を忠実に複製する技術です。この技術には、参照音声の量やモデルの学習方法によっていくつかの段階があります。
- Few-shotクローニング: 数秒から数分程度の少量の参照音声を用いて、事前に学習された多話者Text-to-Speech (TTS) モデルをファインチューニングする手法です。多くの商用サービスで採用されています。
- Zero-shotクローニング: このアプローチは、モデルのファインチューニングを一切必要とせず、わずか数秒(3~6秒程度)の参照音声から話者の声の特徴を捉えたスタイルベクトルをその場で抽出し、未知の話者の声を即座に合成します。YourTTSやXTTSがこの分野の代表例であり、極めて少量のデータで高品質なクローンを可能にするため、悪用のリスクが非常に高い技術とされています。
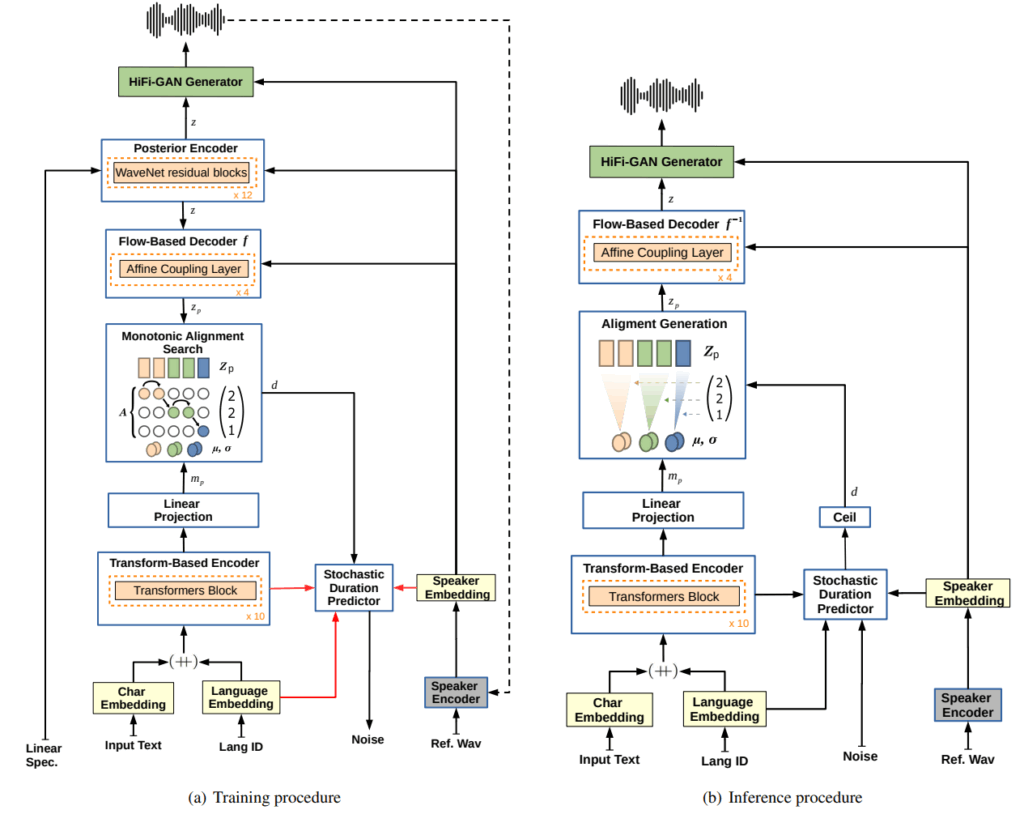
音声ディープフェイクの基盤となるText-to-Speech (TTS) 合成
Text-to-Speech (TTS) 合成は、与えられたテキストから人工的に音声を生成する技術であり、多くの音声ディープフェイクの基盤となっています。以前は、Tacotronのような音響モデルがメルスペクトログラムを生成し、WaveNetのようなニューラルボコーダが最終的な音声波形を生成する2段階のパラダイムが主流でした。しかし近年では、VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)のように、音響モデルとボコーダーを単一のモデルに統合し、テキストから音声波形までを直接生成するエンドツーエンド (End-to-End) のアプローチが主流となっています。これにより、高品質な音声を高速に生成できるようになりました。
高品質な音声を生成する拡散確率モデル
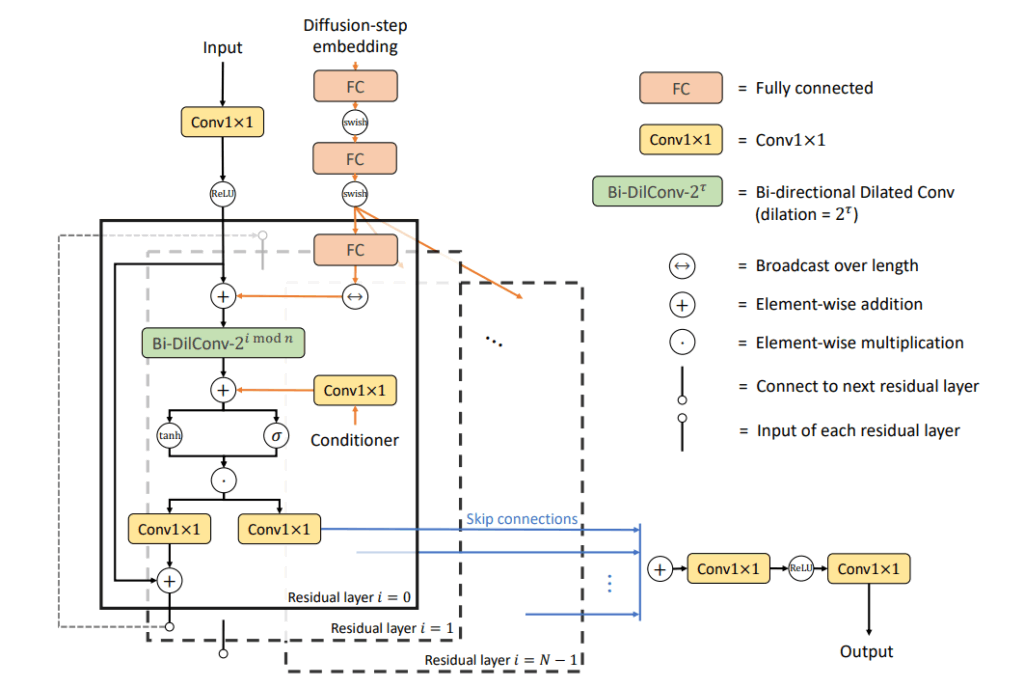
音声生成の品質を飛躍的に向上させた先進的なアーキテクチャの一つに、拡散確率モデル (Diffusion Probabilistic Models, DPM) があります。このモデルは、ランダムなノイズから出発し、学習した分布に従って徐々にノイズを除去していくことで、最終的にクリーンな音声信号を復元します。WaveGradやDiffWaveといったモデルが代表的であり、その生成品質は非常に高い忠実度を誇りますが、一般的に多数の反復ステップを必要とするため、生成速度が遅いという欠点も抱えています。
これらの生成技術の理解は、ディープフェイク音声の特性を把握し、より効果的な検出手法を開発するための出発点となります。生成技術が進化し続ける「軍拡競争」の中で、検出技術もまた、これらの巧妙な生成メカニズムに対応する形で進化していく必要があります。
ディープフェイク検出技術
音声ディープフェイクの脅威に対抗するため、多様な検出手法が開発されてきました。これらの技術は、初期のアーティファクト検出から、より高度な真正性検証へと進化を遂げています。
深層学習アーキテクチャの活用
ディープフェイク検出の基盤となるのは、深層学習アーキテクチャです。
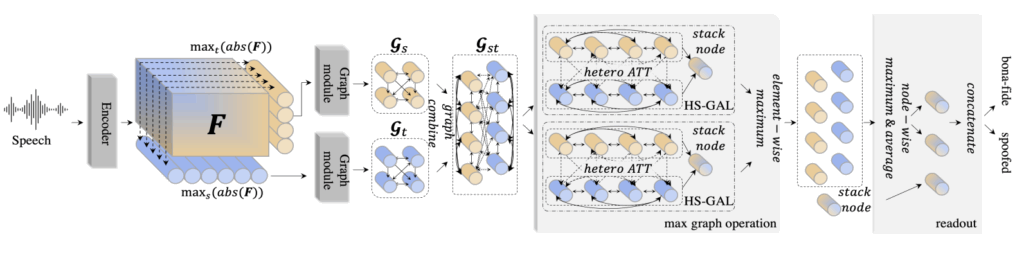
- 畳み込みニューラルネットワーク(CNN): スペクトログラム(MFCCやLFCCなど)のような音声の視覚的表現内の局所的なパターンやテクスチャを捉えるのに優れています。これにより、生成音声に現れる微細な周波数特性の異常を検出できます。
- Transformerモデル: 自然言語処理で大きな成功を収めたTransformerは、音声シーケンス内の長距離にわたる時間的依存関係を捉える自己注意機構(Self-Attention)を備えています。これにより、CNNやRNNでは見逃されがちな、発話全体にわたる微妙な韻律の不整合や不自然さを効果的に検出することが可能です。RawformerやAASISTなどが代表的なモデルとして挙げられます。
自己教師あり学習(SSL)パラダイムへの転換
最も重要な技術的トレンドの一つが、自己教師あり学習(Self-Supervised Learning, SSL)パラダイムの活用です。Wav2Vec2、HuBERT、XLS-Rといった大規模なSSLモデルは、ラベル付けされていない膨大な量の音声データから、音声の普遍的な表現を学習します。
このアプローチは、検出のパラダイムを根本的に変えました。初期の検出手法が、生成モデルが残す特定の「アーティファクト(欠陥)」を探す「間違い探し」に主眼を置いていたのに対し、SSLベースの現代的な手法は、むしろ「真正性の検証」へと移行しています。生成モデルが高度化し、GANや拡散モデルによって生成される音声が本物の音声に酷似するようになった現在、従来の単純なアーティファクトはほとんど見られません。
SSLモデルは、膨大な量の本物の人間の音声データからその根源的な構造を学習するため、その内部表現は「本物の音声とは何か」という強力なモデルを形成します。したがって、SSLモデルを特徴抽出器として用いることで、検出器は与えられた音声サンプルが、この学習された「本物の音声の多様体」からどれだけ逸脱しているかを効果的に測定できます。この逸脱度が大きいほど、たとえ未知の生成モデルによる新しいタイプのアーティファクトであっても、ディープフェイクである可能性が高いと判断でき、未知の攻撃に対しても高い汎化性能を示します。
マルチモーダル検出による強化
多くのディープフェイクは、映像と音声の両方を含む動画コンテンツとして流通します。このような場合、音声ストリームと映像ストリームを同時に分析するマルチモーダル検出が、特に効果的な検出手法として注目されています。
特に効果的なのは、口の動きと音声の非同期性(lip-sync inconsistency)を検出する手法です。映像中の人物の口の動きと、再生される音声の音素が時間的に一致していない場合、それはディープフェイクである強力な証拠となり得ます。このアプローチは、音声が差し替えられたり、映像の口の動きが不自然に生成されたりした場合に特に有効です。
これらの多様な検出技術は、ディープフェイク音声の巧妙化に対応し、より堅牢で汎用的なシステムを構築するための重要な柱となっています。
実世界における検出の課題
音声ディープフェイク検出技術はベンチマークにおいて高い性能を示していますが、実世界で運用する際には深刻な課題に直面します。これは、実験室環境と実際の応用シナリオとの間に存在する「汎化ギャップ」、多様な音質劣化、そして検出器を欺くための「敵対的攻撃」という三つの主要な障壁に起因します。
汎化ギャップ
最も重要な課題の一つが「汎化ギャップ (Generalization Gap)」です。ASVspoofチャレンジのような特定のデータセットで学習・評価されたモデルは、インターネット上から収集された「In-the-Wild」データセットのような、多様な未知のデータに対しては検出精度が劇的に低下することが多くの研究で報告されています。
これは、モデルが学習データセットの作成に用いられた限られた種類の生成器が持つ、特異なアーティファクトを過剰に学習(過学習)してしまうことに起因します。例えば、ある研究ではモデルの性能が43%も低下した事例や、精度がランダムな推測と大差ないレベルまで落ち込む例も示されており、この問題の深刻さを物語っています。
ASVspoofの過去のデータセットは、ノイズ印加、符号化、圧縮、伝送によるアーティファクトが比較的少ない高品質なものであり、このようなクリーンなデータに特化した学習は、実世界の複雑な条件に一般化できないCMソリューションの開発を促進する可能性があります。特にASVspoof 2021 DFタスクでは、検出ソリューションが異なるソースデータセット間で一般化できないという結果も出ています。

音質劣化
実世界の音声は、背景ノイズ、室内の反響、非可逆圧縮、多様な伝送チャネルなどによって音質が劣化しています。このような劣化は、検出器が手がかりとするはずの微細なアーティファクトを破壊またはマスキングしてしまうため、検出性能が著しく低下します。
ASVspoof 2021チャレンジでは、この課題に対処するため、Logical Access (LA) タスクでVoIPやPSTNを含む実際の電話システムを介した伝送、物理アクセス (PA) タスクで実物理空間でのリプレイ攻撃、Deepfake (DF) タスクでメディアストレージで一般的に使用される異なる非可逆コーデックで処理された音声データが導入されました。
これらのタスクは、圧縮、パケット損失、多様な帯域幅やビットレートから生じるアーティファクト、そして実環境での録音における変動に対する検出器のロバスト性を評価することを目的としています。また、非音声セグメント(無音区間など)の有無も、LAおよびDFタスクにおいて検出性能に影響を与えることが示されており、これらのセグメントがない場合、パフォーマンスが大幅に低下することが報告されています。
敵対的攻撃
深層学習ベースの検出器は「敵対的攻撃 (Adversarial Attacks)」に対して脆弱であるという、もう一つの深刻な課題を抱えています。これは、人間にはほとんど知覚できない微小なノイズ(摂動)をディープフェイク音声に加えることで、検出器を騙して誤分類を引き起こさせることが可能であるというものです。
最新の研究では、SOTA(State-of-the-Art)の音声ディープフェイク検出(ADD)システムが、このような摂動によって著しい脆弱性を示すことが明らかになっています。例えば、ホワイトボックスシナリオでは検出精度が98%から26%に、グレーボックスシナリオでは92%から54%に、ブラックボックスシナリオでは94%から84%にまで低下する事例が報告されています。
また、「In-the-Wild」および「WaveFake」データセットでテストされた場合、性能低下はそれぞれ91%から46%、94%から67%に達しました。これらの攻撃は、書き起こしの意味内容や人間の知覚にはほとんど影響を与えずに、検出器を欺くことが可能です。CloneShieldのような防御フレームワークは、人間には知覚できない摂動を導入することで、ゼロショットボイスクローニングによる不正な音声複製を妨害することを目指しています。
これらの課題は、音声ディープフェイク検出技術が実世界で信頼性高く機能するための大きな障壁となっており、今後の研究において克服すべき最重要課題とされています。
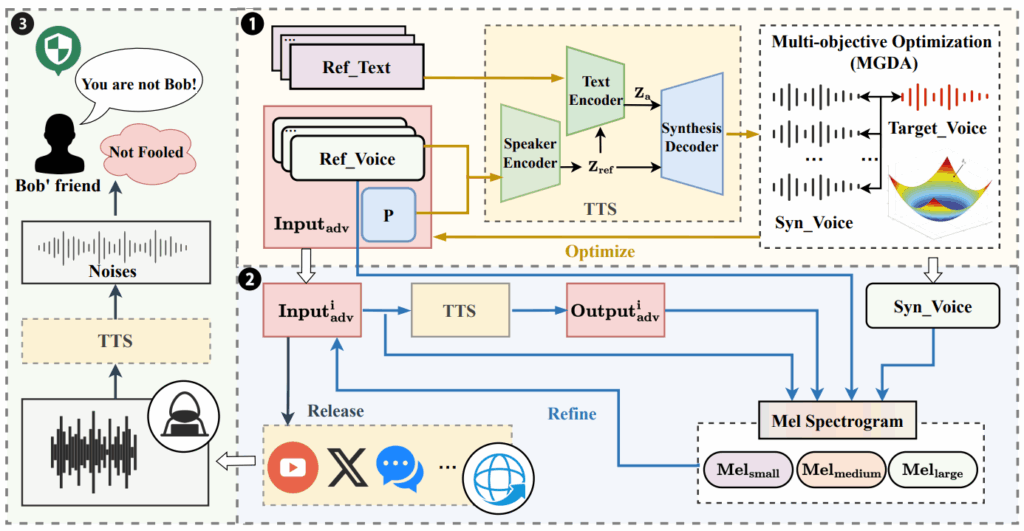
新たな脅威と防御戦略
音声ディープフェイクを巡る技術的な攻防は、今後さらに激化することが予想されます。特に、拡散モデル (Diffusion Models) によって生成される音声は、その極めて高い忠実度から、従来の生成手法が残していた典型的なスペクトル上のアーティファクトをほとんど含んでいません。これは、敵対的生成ネットワーク(GAN)などの初期の生成モデルと比較して、より高い視覚的忠実度、制御性、検出に対する頑健性を提供するため、拡散モデルは支配的なパラダイムとして台頭しています。このため、既存のアーティファクト検出に依存していた多くの検出システムは、無力化される可能性があります。
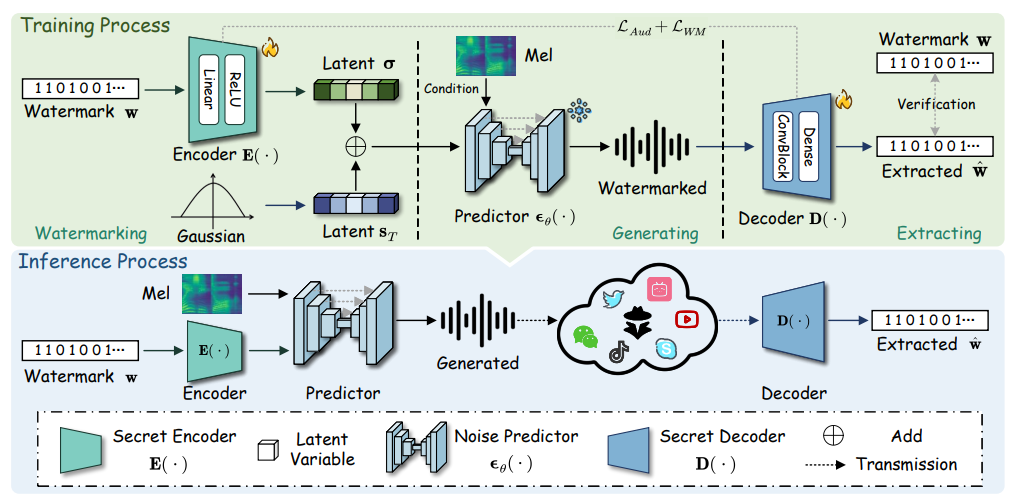
このような受動的な検出の限界に直面し、研究の焦点はより能動的・予防的なアプローチへと移りつつあります。これには、生成される音声に人間には知覚できない電子透かし(ウォーターマーク)を埋め込む技術や、生成モデル自体に固有の「指紋」を持たせ、どのモデルによって生成されたかを特定可能にするモデル帰属(model attribution)技術が含まれます。例えば、GROOTは拡散モデルベースの音声にロバストな電子透かしを埋め込み、複合的な攻撃に対しても約95%の抽出精度を達成しています。P2Markのようなパラメータレベルの透かし技術は、モデルの重みに直接透かしを埋め込み、後から変更可能でありながらモデルから分離できない形で著作権保護と追跡を可能にします。このような能動的なアプローチは、単なる技術的変化以上の戦略的なパラダイムシフトであり、問題解決の責任をコンテンツの「検出者」から「生成者」へと移行させるものです。また、明示的な透かしを使用せずにTTSモデルと識別器の共同学習を通じてトレーサビリティを向上させる研究も進んでいます。
今後の研究では、以下の方向性が重要視されています。第一に、汎化性能の向上です。未知の生成モデルや多様な音響条件(「in-the-wild」データセットなど)に対するロバスト性を高めるための、ドメイン適応技術の深化が求められます。第二に、敵対的頑健性の強化です。深層学習ベースの検出器は、人間には知覚できない微小なノイズ(摂動)による敵対的攻撃に対して脆弱であることが知られており、その精度が98%から26%に、あるいは91%から46%にまで劇的に低下する事例が報告されています。これに対抗するため、より効果的な防御策や攻撃検知メカニズムの開発が不可欠です。第三に、説明可能なAI(XAI)の導入です。検出モデルの判断根拠を人間が理解できる形で提示することで、システムの信頼性を向上させ、法執行機関などでの実用化を促進します。最後に、軽量モデルの開発も重要であり、計算資源が限られたエッジデバイス(スマートフォンなど)上で動作可能な、高効率な検出モデルが求められています。
おわりに
音声ディープフェイク技術は、今後も生成と検出の絶え間ない「軍拡競争」の中で進化を続けると予想されます。この技術的競争は、デジタル社会における「信頼」の概念そのものを問い直し、深刻な社会的課題を提起しています。この複雑な問題に対処するためには、単に技術的な解決策を追求するだけでなく、より広範な社会的枠組みの構築が不可欠であると指摘されています。
特に、生成AIサービスを提供するプラットフォームには、自社の技術が悪用されるリスクを低減するための責任が求められます。これには、生成されるコンテンツに人間には知覚できない電子透かし(ウォーターマーク)を埋め込む技術 や、生成モデル自体に固有の「指紋」を持たせてどのモデルによって生成されたかを特定可能にするモデル帰属(model attribution)技術といった、プロアクティブな防御戦略を積極的に導入することが含まれます。これにより、問題解決の責任がコンテンツの「検出者」から「生成者」へと移行する、戦略的なパラダイムシフトが実現されます。
この終わりのない攻防に効果的に対抗するためには、研究者、企業、政策立案者、そして一般社会が連携し、技術的、倫理的、法的な側面から多角的に取り組んでいくことが不可欠です。
More Information
- arXiv:2102.05630, Giuseppe Ruggiero et al., 「Voice Cloning: a Multi-Speaker Text-to-Speech Synthesis Approach based on Transfer Learning」, https://arxiv.org/abs/2102.05630
- arXiv:2210.02437, Xuechen Liu et al., 「ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild」, https://arxiv.org/abs/2210.02437
- arXiv:2303.13336, Chenshuang Zhang et al., 「A Survey on Audio Diffusion Models: Text To Speech Synthesis and Enhancement in Generative AI」, https://arxiv.org/abs/2303.13336
- arXiv:2308.14970, Jiangyan Yi et al., 「Audio Deepfake Detection: A Survey」, https://arxiv.org/abs/2308.14970
- arXiv:2402.00892, Shijia Liao et al., 「EVA-GAN: Enhanced Various Audio Generation via Scalable Generative Adversarial Networks」, https://arxiv.org/abs/2402.00892
- arXiv:2404.13914, Menglu Li et al., 「A Survey on Speech Deepfake Detection」, https://arxiv.org/abs/2404.13914
- arXiv:2406.06965, Ping Liu et al., 「Evolving from Single-modal to Multi-modal Facial Deepfake Detection: Progress and Challenges」, https://arxiv.org/abs/2406.06965
- arXiv:2407.10471, Weizhi Liu et al., 「GROOT: Generating Robust Watermark for Diffusion-Model-Based Audio Synthesis」, https://arxiv.org/abs/2407.10471
- arXiv:2501.11902, Muhammad Umar Farooq et al., 「Transferable Adversarial Attacks on Audio Deepfake Detection」, https://arxiv.org/abs/2501.11902
- arXiv:2504.05197, Yong Ren et al., 「P2Mark: Plug-and-play Parameter-level Watermarking for Neural Speech Generation」, https://arxiv.org/abs/2504.05197
- arXiv:2504.19197, Sandipan Dhar et al., 「Generative Adversarial Network based Voice Conversion: Techniques, Challenges, and Recent Advancements」, https://arxiv.org/abs/2504.19197
- arXiv:2505.00579, Hussam Azzuni et al., 「Voice Cloning: Comprehensive Survey」, https://arxiv.org/abs/2505.00579
- arXiv:2505.09091, Zeeshan Ahmad et al., 「DPN-GAN: Inducing Periodic Activations in Generative Adversarial Networks for High-Fidelity Audio Synthesis」, https://www.arxiv.org/abs/2505.09091
- arXiv:2505.19119, Renyuan Li et al., 「CloneShield: A Framework for Universal Perturbation Against Zero-Shot Voice Cloning」, https://arxiv.org/abs/2505.19119
- arXiv:2506.01020, Ming Meng et al., 「DS-TTS: Zero-Shot Speaker Style Adaptation from Voice Clips via Dynamic Dual-Style Feature Modulation」, https://arxiv.org/abs/2506.01020
- arXiv:2506.03425, Petr Grinberg et al., 「A Data-Driven Diffusion-based Approach for Audio Deepfake Explanations」, https://arxiv.org/abs/2506.03425
- arXiv:2507.03887, Yuxiang Zhao et al., 「Traceable TTS: Toward Watermark-Free TTS with Strong Traceability」, https://arxiv.org/abs/2507.03887
- arXiv:2507.21157, Naseem Khan et al., 「Unmasking Synthetic Realities in Generative AI: A Comprehensive Review of Adversarially Robust Deepfake Detection Systems」, https://arxiv.org/abs/2507.21157
- arXiv:2509.04345, Qizhou Wang et al., 「AUDETER: A Large-scale Dataset for Deepfake Audio Detection in Open Worlds」, https://arxiv.org/abs/2509.04345
関連記事

機械学習における表形式データのオーグメンテーション
機械学習において、表形式データは最も広く使用されているデータ形式の1つです。しかし、高品質な表形式データを大量に取得することは依然として大きな課題となっています。この課題を克服するために、オーグメンテーション技術が注目さ […]

進化する知能: LLMエージェントの最新動向とエンジニアが知るべき技術的視点
近年、LLM(Large Language Model)エージェントがAI分野において急速に注目を集めています。LLMエージェントは、単にユーザーの入力に応答する従来のAIシステムとは異なり、大規模言語モデルを基盤とし、 […]

Tool-Overuse: なぜLLMは内部知識よりも外部ツールを好むのか?
最近、LLMを利用したシステムを開発する中で、「内部知識で答えられるはずの簡単な質問なのに、なぜか外部APIを叩いてレスポンスが遅くなっている」と感じたことはないでしょうか? LLMが外部ツールを呼び出して問題を解決する […]