The Japan Bias: LLMに潜む隠れた文化的バイアス

大規模言語モデル(LLM)が世界中で利用される中で、モデルが出力する回答の「文化的な偏り」はAI開発における重要な課題となっています。これまで、LLMの文化的・地域的バイアスは、主にアメリカやヨーロッパといった欧米の視点に偏っていると考えられてきました。
しかし、特定の正解を持たない自由記述形式のオープンクエスチョンを用いた新たな評価アプローチによって、これまでとは異なる傾向が明らかになりました。それは、多くの最新モデルが「日本」という特定の国に対して強い偏りを示す「Japan Bias」の存在です。
本記事では最新の研究結果を基に、LLMに潜む隠れた文化的バイアスについて技術的な視点から紐解きます。具体的には、「LLMにはどのような地域的バイアスがあるのか」「言語リソースの量がバイアスにどう影響するのか」、そして「学習プロセスのどの段階でバイアスが発生するのか」という3つの疑問に沿って解説を進めます。
1. 評価フレームワークとデータセットの仕様
LLMが持つ「文化的な偏り」を正確に測るためには、どのようなテストが必要でしょうか。従来の評価手法では、あらかじめ「正解」が用意された質問がよく使われていました。しかし、文化には絶対的な正解がないことも多いため、この研究では新しいアプローチを採用しています。
この研究で構築された評価フレームワークの主な特徴は、以下の4点に整理できます。
- オープンな質問データセット「CROQ」の構築: 絶対的な正解を持たない自由記述形式の質問を集めた「CROQ (Culture-Related Open Questions)」というデータセットを作成しました。このデータセットは、宗教や社会構造といった11の主要ドメイン(分野)と、さらに細分化された66のサブトピックで構成されています。
- 幅広い24言語の選定: 言語による偏りも検証するため、ウェブ上のテキストデータ群であるCommonCrawlに含まれるデータ割合や、話者数、語族といった基準をもとに、様々な24言語を選んでいます。英語や中国語のような学習データが豊富な「高リソース言語」から、アムハラ語のようなデータが少ない「低リソース言語」までを幅広く網羅しています。
- 地理的選択を強制するプロンプト設計: モデルの隠れたバイアスを引き出すため、質問文にはあえて特定の国名を含めず、{in region/place} というプレースホルダー(置き換え用の目印となる文字列)を組み込んでいます。これにより、モデル自身に「どの国・地域の文化を前提として回答するか」を強制的に選ばせる仕組みになっています。
- 「Middle」戦略による高精度な回答抽出: モデルが出力した回答から「どの地域が言及されたのか」を自動で判定するために、別のLLMを審査員として活用する「LLM-as-a-Judge(今回はgpt-4o-miniを利用)」という手法を導入しています。判定の指示(プロンプト)には、「Explicit(明示的な言及のみ)」「Infer(文脈からの推論を許容)」「Middle(両者の中間)」の3パターンを比較しました。その結果、明示的な言及を優先しつつも適度な推論を認める「Middle」のルールが、最も高い精度(98%)を示したため、本評価で採用されています。
2. 日本・米国への圧倒的な偏りとトピック別傾向
様々な言語を用いた自由記述のテストを実施した結果、LLMの回答には大きく分けて3つの特徴的な偏りが存在することが分かりました。
- 入力言語と結びつく国(Own country)への強い引きずられ
まず共通して確認されたのは、入力された言語を公用語としている国を前提として回答する傾向です。評価対象となった8つの最先端モデルすべてにおいて、この「自国寄り」の回答は全体の43~78%に達しました。たとえば、日本語で質問すれば日本を、英語で質問すれば米国を無意識に想定して回答を生成しやすいということです。 - 「日本」と「米国」への圧倒的な集中
さらに興味深いのは、上記の「自国への言及」をデータから除外した場合の傾向です。ほぼすべての言語やモデルにおいて、回答の前提となる国が「日本」と「米国」の2カ国に極端に集中することが明らかになりました。特に日本は、8つのモデル中6つのモデルにおいて最も頻繁に言及されており、LLMが日本の文化に対して強い選好を持っていることが浮き彫りになっています。 - トピックによる柔軟な変動
全体を通してみると日本と米国が強い存在感を放ちますが、11のトピック別で分析すると、分野に応じた国々の変動も確認できます。
複雑な比較となるため、主要なトピックにおける傾向を以下の表に整理しました。
| トピック例 | 傾向の概要 |
|---|---|
| 地理 (Geography) / 経済 (Economy) | 日本を抑え、米国への言及が1位に浮上します。 |
| 政治 (Politics) | 中国の存在感が高まり、日本は3位に後退します。 |
| 歴史 (History) | フランスの存在感が高まり、日本は4位に下がります。 |
| 信仰 (Beliefs) | ギリシャへの言及が際立つようになります。 |
3. 分析指標と言語リソース量との相関
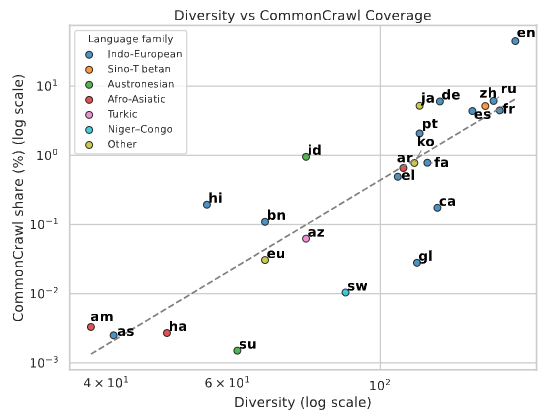
AIの出力が特定の国に偏る要因の一つとして、「学習データの量(言語リソース)」が大きく関係しています。本研究では、各言語がウェブ上のテキストデータ群(CommonCrawl)に占める割合と、モデルの出力における地域的な広がり(Diversity:何カ国に言及したか)との関係を分析しました。
その結果、両者の間には極めて強い正の相関(Spearmanの順位相関係数 \(r_s = 0.843\))が確認されました。これは、学習データが豊富な言語ほど、様々な地域の文化を柔軟に引き出せることを意味します。
言語のリソース量による具体的な違いは、以下の通りです。
- 高リソース言語(英語や中国語など)
出力の広がりを示すDiversityや、回答がどれだけ均等に分散しているかを示すエントロピーという指標が高くなります。そのため、自国への言及だけでなく、日米をはじめとする複数の国の文化を出力できる余裕があります。 - 低リソース言語(アムハラ語やベンガル語など)
Diversityやエントロピーが低く、入力言語が話される国(Own country)への言及に極端に偏るか、あるいは回答そのものを生成できない(NA: Non-Answer)割合が著しく高くなります。
なぜ低リソース言語ではこのような現象が起きるのでしょうか。そのメカニズムとして、訓練データの不足が考えられます。モデルは、その言語での十分な文化的背景を学習できていない場合、未知の地域について無理に語ることを避けます。その結果、より安全で自己言及的な(入力言語に直結する国に限定した)出力へと後退してしまうことが示唆されています。
4. アライメント技術がもたらす副作用
AIの学習が進むほど、より公平でバランスの取れた回答ができるようになると思われがちです。しかし、実際には「アライメント(人間の意図にモデルを合わせる事後学習)」の過程で、かえってバイアスが強まることが分かっています。
この研究では、学習段階による違いを検証するため、事前学習のみを終えたBase(ベース)モデルと、事後学習を経たInstruct(インストラクト)モデルの比較を実施しました。なお、対話形式に最適化されていないBaseモデルの評価には、プロンプト内で回答例をいくつか提示して形式を学習させる ICL (In-Context Learning) という手法を用いて、強制的にQ&A形式で出力させています。
両者を比較した結果、学習フェーズごとに以下の特徴が見られました。
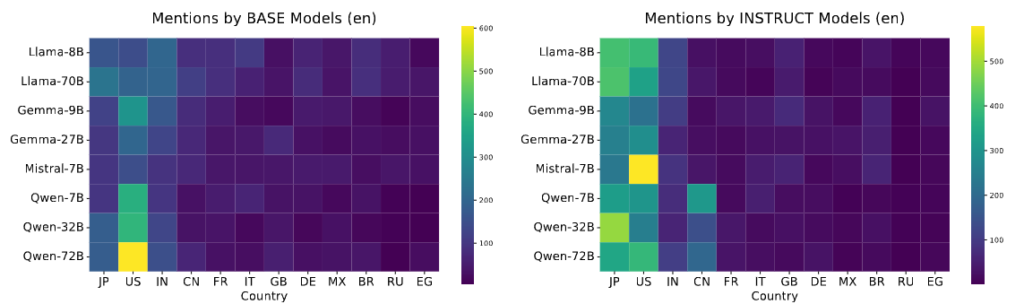
- Baseモデルの段階(事前学習のみ)
日米への言及は多いものの、インドや中国、ヨーロッパなど様々な国へ回答がバランスよく分散しています。エントロピー(回答の均等さ)も高い状態を保っていました。 - Instructモデルの段階(事後学習後)
事後学習(Post-training)を経ることで、特定の国(主に日本と米国)への回答の集中度が劇的に増加しました。興味深いことに、この「日米への集中」という現象は、中国で開発されたQwenなどの欧米圏以外のモデルでも同様に発生しています。
さらに、学習のどのタイミングでバイアスが強まるのかを詳細に調べるため、学習段階を3つに分けて公開している OLMo というモデルを用いて検証を進めました。
| 学習フェーズ | バイアスの変化 |
|---|---|
| 事前学習 (Base) | 比較的バランスの取れた様々な国の文化を出力します。 |
| SFT (Supervised Fine-Tuning: 教師ありファインチューニング) | 特定の国(日米)への集中が最も急激に増幅されるフェーズです。回答の均等さを示すエントロピーが大きく低下します。 |
| Instruction Tuning (指示チューニング) | SFTで発生したバイアスを是正・緩和する役割を果たさず、特定の文化への集中を維持してしまいます。 |
このように、AIを人間の好みに合わせるためのアライメント技術が、結果として「世界の標準的な文化は日米である」という特定の文化への集中を生み出す副作用をもたらしていることが明らかになりました。
5. 評価の限界と倫理的配慮
今回の研究は、LLMに潜む文化的バイアスを明らかにする上で非常に有意義なものですが、いくつか考慮すべき限界や倫理的な配慮事項も存在します。今後の研究や実運用に向けて、以下の3点に留意する必要があります。
- 学習段階における検証言語の偏り: BaseモデルとInstructモデルの学習段階ごとの比較は、現状では英語のプロンプトでのみ検証を進めています。そのため、今回確認された「アライメントによるバイアスの増幅」という現象が、他の様々な言語でも全く同じように発生するのかどうかについては、まだ結論付けられておらず、一般化には限界があります。
- デコードパラメータの影響の未検証: 今回の検証では、各LLMの出力を最も一般的な使われ方に合わせるため、デフォルトの生成設定(デコードパラメータ)を使用しています。そのため、出力のランダム性を制御する Temperature といった数値を変更した場合に、バイアスの偏り方がどう変化するかは検証の対象外となっています。
- AIによる自己バイアス混入への対策 (Human-in-the-loop): この研究では、質問データセット(CROQ)の作成に「GPT-5.1」を、モデルの回答判定に「gpt-4o-mini」を利用しています。ここで問題となるのが、評価用のAI自身が持つバイアスが結果に混入してしまうリスクです。これを防ぐため、データセットの構築過程などにおいて人間が手動でレビューと修正を実施する Human-in-the-loop (人間の判断をシステムに組み込む手法)を取り入れ、AI特有の偏りを排除する工夫が施されています。
おわりに
本研究を通じて、LLMを人間の意図に合わせるための「アライメント(特に教師ありファインチューニング:SFT)」が、意図せずして文化の均質化を招いてしまうという副作用が明らかになりました。モデルの安全性や対話能力を高めるためのプロセスが、結果として「日本」や「米国」といった特定の国に偏った回答を引き起こしているのです。
この事実は、多言語対応やグローバル向けのLLMアプリケーションを開発するエンジニアにとって重要な示唆を与えています。様々な背景を持つユーザーに向けてシステムを構築する際には、アライメントに用いるデータの構成がもたらす地域的な偏りをあらかじめ考慮し、バランスの取れた出力を促すための対策に取り組む必要があります。
More Information
- arXiv:2604.21751, Joseba Fernandez de Landa et al., 「Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs」, https://arxiv.org/abs/2604.21751
関連記事

深層学習×状態空間モデル: Mambaアーキテクチャの概要
近年、普段の生活やビジネスでは欠かせないAI技術ですが、ChatGPTをはじめとする大規模言語モデル(LLM)の登場で、Transformerと呼ばれるアーキテクチャが注目を集めています。Transformerは、文章や […]

ディープラーニングモデルの量子化: PyTorchによる実践解説
近年、ディープラーニングは画像認識、自然言語処理、音声認識など、多岐にわたる分野で目覚ましい成果を上げています。しかし、これらの高精度なモデルは、しばしば膨大なパラメータ数を持ち、その結果として大きなメモリ消費量や計算コ […]

LSNet-人間の視覚から着想を得た軽量かつ高性能な畳込みニューラルネットワーク
近年、コンピュータビジョンの分野では、目覚ましい発展を遂げた深層学習モデルが、その計算コストの高さから、実用的な課題に直面しています。特に、リアルタイム性が求められるアプリケーションや、計算資源に制約のあるモバイルデバイ […]