Agents’ Last Exam (ALE): AIエージェントの合格率は1%未満

近年、AIはMMLUやSWE-benchなどのベンチマークを次々とクリアしていますが、実際の経済活動に直結する長期的な実務への導入はあまり進んでいません。この「実用性の課題」を測るため、実世界におけるワークフローの遂行能力を評価する新たなベンチマーク「Agents’ Last Exam(ALE)」が登場しました。
ALEの「Last Exam(最後の試験)」という名前には、2つの意味が込められています。1つは「これをクリアすれば実務に導入できる水準に達した(Last as competence threshold)」こと、もう1つは「現在のAIがこなせる境界線にある最高難易度(Last as difficulty frontier)」であることです。
OSWorld(GUI操作特化)やGDP-VAL(評価範囲が狭く人手採点)といった既存ベンチマークと比較し、ALEは独自の立ち位置を持っています。13の産業クラスタと55のサブドメインという広範な専門業務を網羅しつつ、人間の介入を不要とする自動検証の仕組みを備えている点が大きな特徴です。
1. ALEのスコープとタスク設計
ALEの最大の特徴は、対象とするタスクが「専門家のリアルな実務」に徹底的にこだわって作られている点です。では、具体的にどのような業務が、どのような基準で選定されているのでしょうか。
現実の職業分類に基づく広範なドメイン
まず、ALEがカバーするタスクの範囲は、アドホックに選ばれたものではありません。米国の連邦職業タクソノミーである「SOC 2018」および「O*NET」という公式な職業データセットを基準に設計されています。これにより、実世界のデジタルな労働市場を反映した13の産業クラスタと、その配下にある55のサブドメインを網羅しています。

タスク設計における3つの原則
AIが実務で使えるレベルにあるかを見極めるため、ALEに採用されるタスクは以下の3つの厳しい原則を満たす必要があります。
- Representativeness(代表性): 専門家が実際に業務で使用するソフトウェアを用いること。たとえば、建築の3Dモデリングであれば、汎用的なAutoCADではなく、専門領域に即したSolidWorksやRhinoを使うといった具合です。
- Complexity(複雑性): 単なる1クリックのUI操作ではなく、時間を要する長期的な成果物の作成であること。そのため、「動画編集ソフトのDaVinci Resolveでカラーフィルタを適用する」といった局所的なアクションは除外されます。
- Verifiability(検証可能性): 成果物が客観的かつ自動で評価可能であること。たとえば、「モンスターのいるRPGをデザインする」というような正解が曖昧なタスクはNGです。「既存のゲームと同じマップやイベントをRPGMaker XPで完全に再現する」といった、参照データと直接比較できる形式が求められます。
5つのゲートを経る厳格な採用プロセス
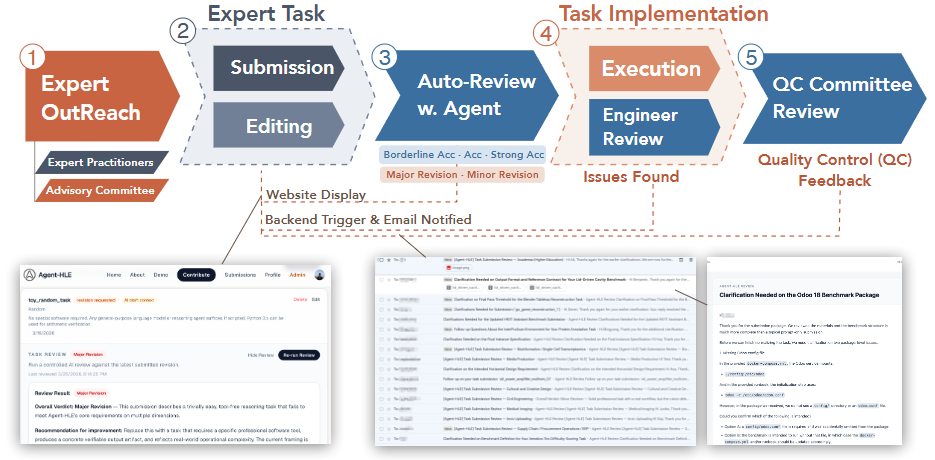
これらの基準を満たすタスクを集めるため、ALEは一般的なクラウドソーシングを利用せず、250名以上の各分野の専門家から実際の過去のプロジェクトを直接収集しています。提案されたタスクは、以下の5つの厳密な関門(ゲート)を経て初めて採用されます。
- Expert OutReach(専門家勧誘): 業界の実務家をアドバイザリー委員会を通じて募る
- Submission(タスク提出): 専門家が専用ポータルから過去のプロジェクトと参照データを提出
- Auto-Review(自動レビュー): AI支援により、要件を満たしているか一次審査を実施
- Execution(実装と実行テスト): エンジニアが実際に環境を構築し、ドライランを実施
- QC Committee Review(品質確認委員会): 専門家委員会による最終的な妥当性・品質のチェック
データセットの汚染(Contamination)防止策
AIベンチマークで常に課題となるのが、評価データがモデルの学習データに混入してしまう「データ汚染」の問題です。ALEはこの課題に対し、非常に堅牢な設計を取り入れています。
採用されたタスクのうち、パブリックに公開されるのは全体の約10%にあたる150タスクのみです。検証済みの残り1,017タスクはプライベートプールに厳重に隔離され、モデルの学習データへの混入を防ぎます。さらに、定期的にタスクをローテーションさせることで、モデルの世代が変わっても常に未知の実務タスクでAIを評価できる仕組みになっています。
2. 決定論的で疎結合な評価アーキテクチャと環境
ALEの評価基盤は、結果の再現性を担保しつつ、様々なモデルや環境を柔軟にテストできるように設計されています。その中核となるのが、3つの疎結合なコンポーネントによるアーキテクチャです。
疎結合に設計された3つのコンポーネント
ALEの評価パイプラインは、以下の3つの要素が互いに独立して機能するように作られています。
- Task Spec(タスク定義): タスクの内容や評価基準を定義する実行可能なファイルです。
- Agent(モデルとハーネス): LLM(大規模言語モデル)と、それを制御するハーネスから構成されます。エージェントはタスクの説明のみを受け取り、環境とやり取りします。
- Environment(評価環境VM): リモートの仮想マシン(VM)上で提供される、タスクを実行するための隔離された環境です。
このようにコンポーネントを分離することで、新しいエージェントの実装や、ローカルからクラウドへの実行環境の差し替えを容易に進めることができます。
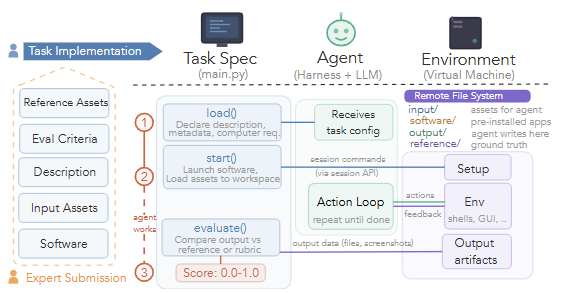
タスクを制御する3つのライフサイクル
Task Specは、環境を決定論的(常に同じ初期状態から始まること)に保つため、以下の3つの関数を通じてタスクのライフサイクルを管理します。
load(): タスクの説明文、必要なメタデータ、そして計算リソースの要件を宣言します。start(): 環境の初期化を実施します。必要なソフトウェアを起動し、アセットをワークスペースにロードして、エージェントが作業を始められる状態を整えます。evaluate(): エージェントの作業終了後に呼び出され、出力された成果物と参照データ(正解)を比較します。その結果を0.0から1.0までのスコアとして算出します。
厳格に管理されたファイルシステム要件
さらに、評価環境であるリモートVM内のファイルシステムは、エージェントの不正を防ぎ、正確な評価を実施するために、4つのディレクトリに厳格に分けられています。
input/: タスクに必要な素材データが置かれます。エージェントは読み取りのみ可能です。software/: タスクの実行に必要なアプリケーションが事前にインストールされています。output/: エージェントが唯一書き込み可能なディレクトリです。最終的な成果物はここに保存されます。reference/: 評価用の正解データが格納されます。このディレクトリはエージェントから完全に隠蔽(アクセス不可)されており、evaluate()関数による採点時のみ使用されます。
この徹底したディレクトリ構造により、エージェントが正解データを盗み見ることを防ぎ、純粋な実務遂行能力を測定できる仕組みになっています。
3. 実務をこなす「GCUA」とハーネスの構造
ALEが対象とする実務タスクは、CLI(コマンドライン)でのコード実行やファイル操作と、GUIを持つ専門ソフトの操作をシームレスに行き来することが求められます。これに対応するため、ALEでは「GCUA (Generalist Computer-Use Agent)」と呼ばれる、より包括的な能力を持つエージェントを評価対象としています。
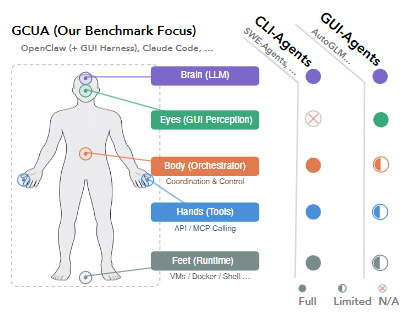
エージェントを構成する5つの機能レイヤー
GCUAの構造を理解するために、AIエージェントの機能を人間の身体に見立てた5つのレイヤーで整理してみましょう。
- Brain(推論): LLMによる推論と計画の立案。
- Eyes(GUI視覚認識): スクリーンショット等を通じた画面の視覚的な理解。
- Body(オーケストレーション): 複数のタスクやツールの実行順序を管理する制御フロー。
- Hands(ツール呼び出し): APIや連携ツールの具体的な実行。
- Feet(実行環境へのアクセス): 仮想環境(VM)やコンテナ、シェルへの直接的なアクセス。
従来のCLIエージェントは画面を見る「Eyes」を持たず、一方でGUIエージェントはタスク管理の「Body」や環境アクセスの「Feet」が限定的でした。しかし、GCUAはこれら5つの層をすべて統合しており、実務で求められるような長期的なワークフローをこなす能力を持ちます。
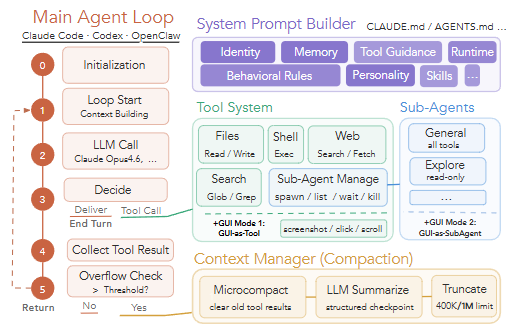
長時間実行を支えるコンテキスト管理
実務タスクは完了までに長い時間がかかるため、エージェントが過去の動作履歴(コンテキスト)をすべて記憶し続けると、LLMの処理上限(トークン数の限界)をすぐに超えてしまいます。そこで、ハーネス(エージェントを制御するシステム)は以下の3段階のアプローチでコンテキストを管理・圧縮しています。
- Microcompact(部分消去): 古くなったツールの実行結果など、直近で不要になった情報をその場で消去します。
- LLM Summarize(要約によるチェックポイント化): LLM自身に過去の会話や作業履歴を要約させ、構造化されたチェックポイントとして保持します。
- Truncate(強制打ち切り): それでも上限(例えば40万や100万トークン)に達した場合は、履歴を強制的に切り捨てて枠を確保します。
GUI操作をツールとして扱う「GUI-as-Tool」
GCUAがマウスやキーボードを操作する際、「GUI-as-Tool」というモードが活躍します。これは、CUA MCP(Model Context Protocol)ブリッジという仕組みを経由して、GUI操作を以下のような具体的な「ツール」の集合としてエージェントに提供するものです。
- Keyboard(キーボード操作): 文字のタイピングや、「Ctrl+C」のようなショートカットキーの入力。
- Mouse(マウス操作): 任意の座標へのクリック、ドラッグ、スクロール。
- Utility(補助機能): 画面のスクリーンショット取得や、現在のカーソル位置の取得、意図的な待機(Wait)。
これにより、エージェントは「画面を見て、目的の場所をクリックする」といった人間と同じデスクトップ操作を、ファイルの読み書きなどと同じように、自身が使えるツールの一つとして自然に使いこなすことができます。
4. 報酬ハッキングを防ぐ様々な評価方式
AIエージェントの評価において、出力された成果物が本当に正しいかを見極めることは非常に困難です。ALEでは、表面的な結果だけを合わせて高得点を得ようとする「報酬ハッキング」を防ぐため、厳格で様々な評価方式を採用しています。
LLM-as-judgeを避ける3つの理由
近年、他のLLMを用いて出力を採点する「LLM-as-judge」という手法が一般的ですが、ALEでは可能な限り決定論的なコード評価(プログラムによる厳密な採点)を推奨しています。その理由は以下の3点です。
- 評価のドリフト: 判定モデルのアップデートによって、過去と現在のスコアが比較できなくなる事態を防ぐため。
- 誤判定の防止: 「全体的に見てどうか」といった曖昧なプロンプトでは、正解とほぼ正解の境界を正確に判別できないため。
- オフライン再実行の容易さ: 決定論的な評価であれば、APIコストをかけずに手元で何度でも再評価を進められるため。
タスクに応じた様々な評価モード
成果物の形式が多岐にわたるため、ALEでは性質に合わせて以下の表のような評価モードを組み合わせて使用します。
| モード | 参照形式 | 実行環境 | 判定者 | 例示タスクワークフロー | 補足説明 |
|---|---|---|---|---|---|
| Exact / hashed value | secret / digest | host | code | cybersecurity/snake_crackme | ― |
| Structured tabular | (項目, 値, 許容誤差) のマニフェスト | host または VM | code | finance/sec_10k_financial_parsing | ― |
| Geometric / spatial | STL / メッシュ / 点群 | VM | code | manufacturing/gcode | 成果物は 3D メッシュ、点群、その他の空間的アーティファクト。スコアリングは表面距離関数を用い、例として 1 万点の表面サンプルを参照 STL と比較し、閾値内の割合に応じて加点する。 |
| Visual appearance | 参照スクリーンショット | host | vision LLM | game/mota_reproduction | 成果物の正しさを人間の目で判断するのが自然なケース(レンダリング画像、再着色写真、UI スクリーンショットなど)。ホストはエージェント生成画像と参照画像を並べ、ビジョン LLM にルーブリック質問で評価させる。 |
| Behavioral / world state | 決定論的な状態ダンプ | VM | code | architecture/parametric_energy_simulation | 成果物はインタラクティブシステムの編集後の状態。スコアリングでは固定軌道でシステムを再実行し、ゲームマップ、シミュレーションログ、NPC イベントなど比較可能な状態をダンプして評価する。 |
| Free-text / semantic | ルーブリック | host | LLM | finance/equity_research_summary(ルーブリック要素) | 成果物は文章レポート。スコアリングは yes/no または段階評価のサブ基準からなるルーブリックを用い、LLM が判定する。 |
| Executable artifact | テストセット / オラクルプログラム | host または VM | code | data_computer_science/data_pipeline_etl_instance_1 | 成果物はプログラム、モデル、パイプラインなど。スコアリングは保持されたテストセットまたはオラクルに対して実行し、インスタンスごとの正答率を集計する。 |
Gate-and-scoreと連続的なスコア計算
評価結果は単なる合格・不合格ではなく、0.0から1.0までの連続的なスコアとして算出されます。ここで重要なのが「Gate-and-score(ゲートとスコア)」という仕組みです,。たとえば「コンパイルエラーがない」「ツールパス(機械の動作経路)が衝突していない」といった必須条件(ハードゲート)を満たさない限り、どれだけ最終形状が似ていても0点となります。これにより、表面的に取り繕った結果による報酬ハッキングを防ぎます。
ハードゲートを通過した後は、許容誤差に基づいた「Weighted rubric(重み付けされた評価基準)」でスコアを計算します。たとえば、3Dモデルの表面誤差を評価する場合、以下のような数式が用いられます。
$$\text{score} = 0.70 \cdot \text{frac_within}(0.3\text{mm}) + 0.30 \cdot \text{frac_within}(2.0\text{mm})$$
この数式は、「誤差0.3mm以内に収まっている部分の割合を70%、2.0mm以内の部分を30%として評価する」ことを意味しており、成果物の品質をより正確に数値化し連続的な最終スコアを算出します。
VM-side verifierによる評価の工夫
評価をさらに難しくするのが、CADカーネルなどホスト側の環境に持ち出せない巨大な専門ソフトウェアの存在です。この場合、ALEは評価スクリプトを仮想マシン(VM)側にアップロードして実行させ、その結果をJSON形式のテキストとして標準出力を介してホスト側に返却する「VM-side verifier」という仕組みを採用しています。
LLM判定の工夫(Targeted probes)
どうしてもコード評価ができず、LLMによる視覚的な判定が必要な場合でも、「全体的に良いか?」といった抽象的なプロンプトは使用しません,。「左上の角にオレンジの円があるか?」といった、具体的なアンカー(証拠)に基づく「Yes/No」形式の質問(Targeted probes)を複数投げかけ、その結果をプログラムで集計してスコア化することで、評価のブレを最小限に抑えています。
5. 実験結果 – なぜ最新モデルでも惨敗するのか
ALEでは、評価にかかるコストと目的に合わせてタスクを3つの難易度(ティア)に分割しています。短期的な進捗を測る「Near-Term(67タスク)」、すべての専門領域をカバーする「Full-Spectrum(55タスク)」、そして最難関となる「Last-Exam(38タスク)」です。
合格率1%未満という厳しい現実
最新のLLM(GPT-5.5やClaude Opusなど)を搭載したエージェントを使用しても、実務の境界線となる「Last-Exam」ティアでの完全な合格率(Pass Rate)は平均して1%未満に留まっています。実際に、多くのエージェント構成では、この難易度のタスクを最後まで完遂できた割合は0%という結果でした。

分野によるスコアの差と不自然な行動
タスクの分野によって、エージェントの成績には明確な偏りがあります。計算・数理科学(Computational Math)などの分野では比較的高得点を出しますが、教育(Education)などの分野ではスコアが低迷しています。これは、基盤となるモデルの学習データがプログラミングやコード関連のタスクに大きく偏っていることが要因として指摘されています。 また、エージェントの操作方法にも癖が見られます。本来はGUI(グラフィカルな画面操作)を使って進めるべきタスクであっても、エージェントは無理にBashなどのCLI(コマンド入力)ツールで代替しようとする傾向があります。

失敗の根本原因は「操作ミス」ではない
なぜエージェントは実務タスクを完了できないのでしょうか。エラーを分析した結果、失敗の約4分の3は「Understanding(専門的なドメイン知識の理解不足)」と「Approach(誤った戦略の選択や途中での中断)」の組み合わせであることが分かりました。つまり、マウスのクリック位置を間違えるような「Execution(実行・操作ミス)」でつまずいているケースは少数派です。 さらに別の分析から、エージェントを制御する仕組み(ハーネス)の工夫よりも、基盤となるLLM自体の能力差の方が、最終的なベンチマークスコアに3倍以上の大きな影響を与えていることも示されています。
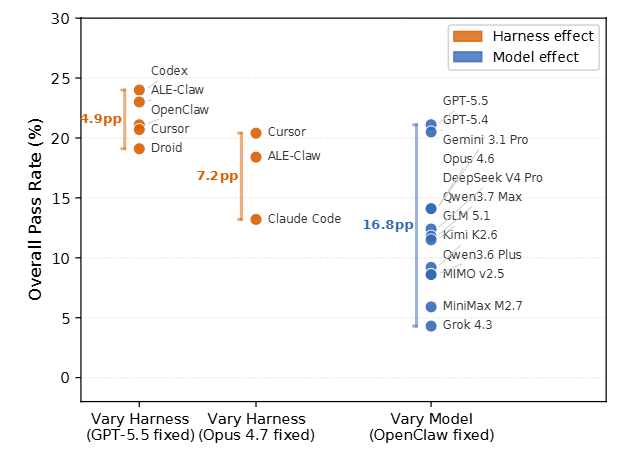
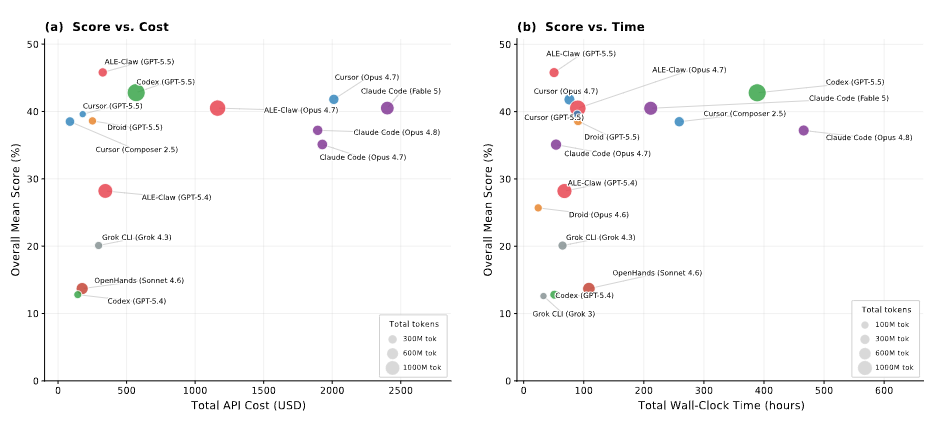
リソースを注ぎ込んでも結果は伴わない
もう一つの重要な発見は、「計算資源をかければスコアが上がるわけではない」ということです。タスクの実行においてAPIコスト、処理時間、消費トークン数を増やしても、必ずしもタスクの平均スコア向上には相関しないことが確認されています。ただ単に大量の情報を処理するのではなく、的確にツールを呼び出し、必要なコンテキストだけを効率よく管理する能力が求められています。
6. 実務タスクの採点事例
ALEで採用されている「ハードゲート(必須要件)」という仕組みが、実際の採点でどれほど厳しく機能しているか、論文内で紹介されている具体的な事例を通じて見ていきましょう。
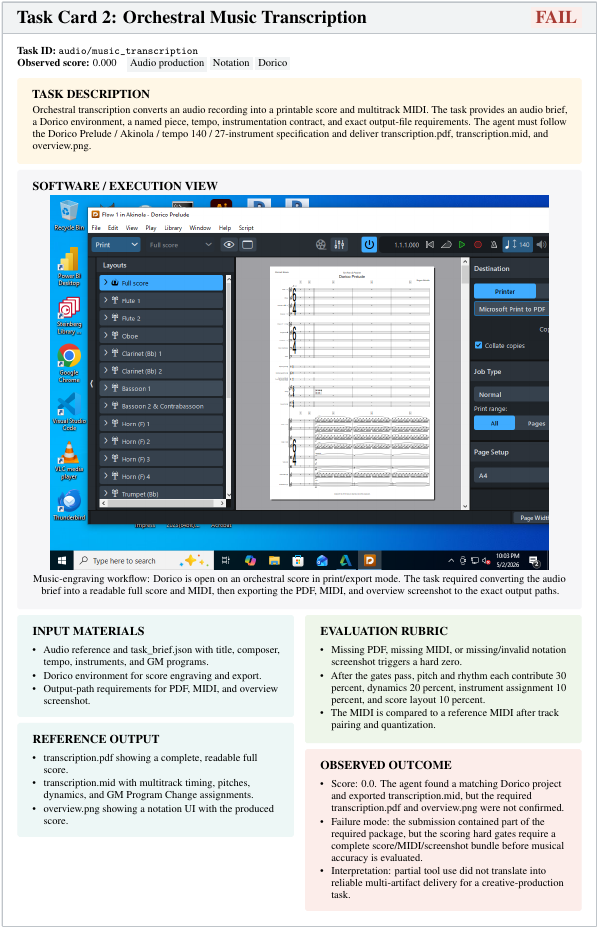
事例1: 音楽の書き起こし(Task Card 2)
オーディオデータから楽譜(PDF)とMIDIデータなどを作成するタスクです。あるエージェントは、専用ソフトを操作してMIDIファイルの出力には成功しました。しかし、最終的な成果物として指定されていたPDF楽譜とスクリーンショットが欠けていたため、ハードゲートの判定によりスコアは容赦なく0点となっています。部分的にツールを使いこなせていても、提出物のパッケージが完全に揃っていなければ、音楽的な正確性の採点にすら進めません。
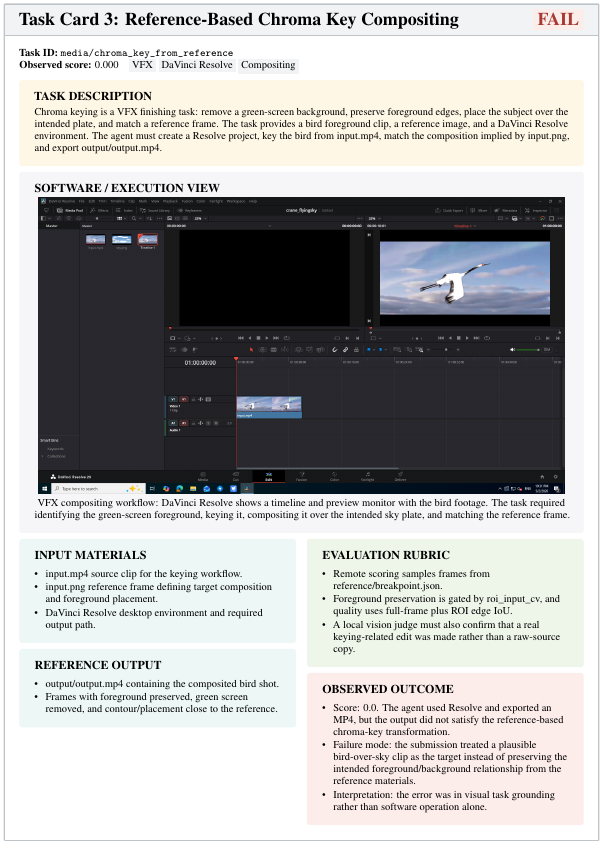
事例2: VFXのクロマキー合成(Task Card 3)
動画編集ソフト(DaVinci Resolve)を使用し、グリーンバックの被写体を切り抜いてリファレンス(参照用)画像通りに背景と合成するタスクです。エージェントはソフトを操作し、動画(MP4ファイル)の出力までは進めました。しかし、指定されたリファレンスの意図を正しく視覚的に理解できておらず、ただもっともらしい別の合成動画を出力してしまったため、これも0点と判定されています。
おわりに
Agents’ Last Exam (ALE) が浮き彫りにしたのは、最新のAIモデルであっても、実際の経済活動に直結する長期的な専門業務を完遂するにはまだ多くの課題が残されているという厳しい現実です。最高難易度での合格率が1%未満という結果は、AIが「抽象的な試験問題を解く」段階から「リアルな実務を遂行する」段階へ移行する壁の高さを示しています。
また、失敗の大部分が表面的な操作ミスではなく、専門知識の欠如や戦略の誤りであったことから、今後のAIエージェント開発が進むべき方向性も明確になりました。今後は、単に基盤モデルの処理能力を向上させるだけでなく、特定の専門ドメインにおける深い知識の統合と、複雑な作業を的確に進められる頑健なワークフロー設計が強く求められます。
ALEという「最後の試験」をAIが安定してクリアした時こそ、私たちの働き方が真の意味で変革を迎える瞬間になるのかもしれません。
More Information
- arXiv:2606.05405, Yiyou Sun et al., 「Agents’ Last Exam」, https://arxiv.org/abs/2606.05405
関連記事

LLMの学習と推論のメカニズム: なぜプロンプトで性能が変わるのか?
大規模言語モデル(LLM)は、「Next Sentence Prediction (NSP)」という極めてシンプルな目的で学習されているにもかかわらず、驚くほど高度な文脈理解や推論能力を発揮します。さらに興味深いことに、 […]

画像認識アーキテクチャの進化大全: CNN・ViT・Mamba・MLPの比較
AI技術の急速な進歩により、画像認識は私たちの生活に深く浸透し、顔認証、自動運転、医療画像診断など、多岐にわたる分野で革新をもたらしています。この画像認識技術の発展を支えているのが、ディープラーニングにおけるモデルアーキ […]

強化学習の世界を俯瞰してみる - 基礎から最前線の課題・応用・トレンドまで
強化学習(RL)は、エージェントが試行錯誤を通じて最適な行動を学習する機械学習の一分野です。近年、囲碁やビデオゲーム、大規模言語モデル(LLM)の制御など、多岐にわたる分野で著しい進展を遂げ、応用されています。 特に、深 […]