大規模言語モデルによる知識グラフ構築の最前線

知識グラフ(Knowledge Graphs, KG)は、構造化された知識を表現し、統合し、そして推論するための基盤となるインフラストラクチャとして機能します。意味検索や質問応答など、様々なアプリケーションの土台を支える、極めて重要な要素です。
しかし、従来の知識グラフ構築手法は、ルールベースや統計的なパイプラインに依存していたため、長年の課題を抱えていました。具体的には、特定のドメインを超えた一般化が難しいスケーラビリティ(拡張性)の課題、スキーマ設計に多大な専門家の介入が必要な専門家への過度な依存、そして工程が分断されていることによるエラーの累積的な伝播です。これらの制約が、知識グラフを自己進化し、大規模かつ動的に運用することを妨げていました。
このボトルネックを克服し、知識グラフ構築のあり方を根本から変える変革的なパラダイムをもたらしたのが、大規模言語モデル (Large Language Models, LLMs) の登場です。
LLMは、非構造化テキストから構造化表現を直接作り出す生成的な知識モデリング (Generative knowledge modeling)、自然言語の理解に基づいた意味的な統合 (Semantic unification)、そしてプロンプトを活用して複雑なワークフローを統制する指示駆動型のオーケストレーション (Instruction-driven orchestration)という、3つの鍵となるメカニズムを可能にしました。
その結果、知識グラフ構築は、従来の「ルール駆動型・パイプラインベース」から、「LLM駆動型で、統一的かつ適応的なフレームワーク」へと、根本的なパラダイムシフトを遂げています。この記事では、LLMが牽引する知識グラフ構築の最前線について、その具体的なプロセスと将来の可能性を深く掘り下げて解説します。
従来手法の技術的限界
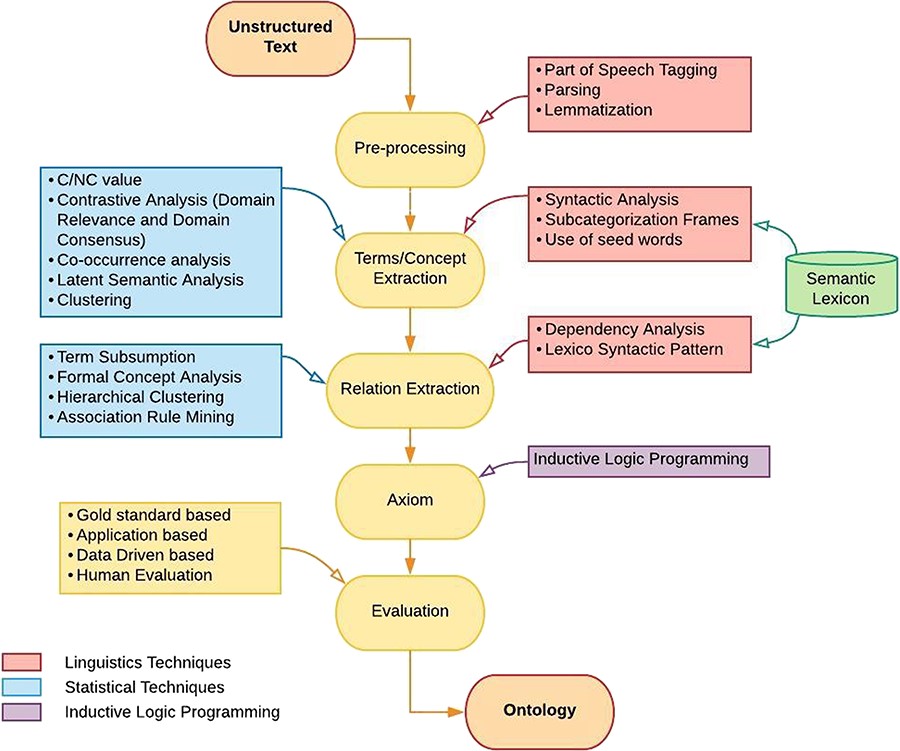
このセクションでは、大規模言語モデルが登場する以前の知識グラフ構築が直面していた構造的な制約と技術的な限界について掘り下げます。従来の構築プロセスは、オントロジー工学(Ontology Engineering, OE)、知識抽出(Knowledge Extraction, KE)、知識融合(Knowledge Fusion, KF)という、3つの主要なコンポーネントから成る階層的なパイプラインに従っていました。
これらの従来のパラダイムは、ルールベース、統計的手法、あるいはシンボリックなアプローチによって実装されていましたが、結果として、以下の3つの根本的な課題を抱えていました。
- スケーラビリティとデータ不足: ルールベースや教師ありシステムは、ドメインを超えた一般化に失敗しがち。
- 専門家への依存と硬直性: スキーマやオントロジー(知識構造)の設計に多大な人的介入が必要であり、適応性に欠けていた。
- パイプラインの断片化: 構築段階が分断されているため、エラーが累積的に伝播してしまう。
オントロジー工学の硬直性
オントロジー工学とは、ドメインの概念、関係、および制約を形式的に定義する作業です。LLMが登場する以前は、オントロジーは主に専門家による手動構築に依存していました。
この体系的なプロセスは、概念的な厳密性と論理的な一貫性を保証する一方で、専門家の介入を必要とし、その結果として、スケーラビリティ(拡張性)が限られていました。特に、大規模なドメインや、継続的に変化する知識ドメインに対しては、柔軟性と効率性を欠いていました。従来のオントロジー工学フレームワークは、その精度と形式的な正確性を保つために、継続的な適応が難しいという制約を抱えています。
知識抽出の制約
知識抽出は、非構造化データや半構造化データから、エンティティ、関係、属性を識別することを目的としています。
初期のアプローチでは、手作業で作成された言語ルールやパターンマッチングに頼っていました。これらは解釈可能であるという利点がありましたが、特定のドメインに特化しすぎており、脆いという技術的な問題がありました。ディープラーニングアーキテクチャの登場後、データ駆動型の特徴学習へと移行したものの、教師あり学習パラダイムの制約として、アノテーション付きデータへの強い依存性や、ドメインをまたいだ汎化性能の低さという課題が残されました。これらの制約が、後の段階でエラーを累積的に広げてしまう原因となっていました。

知識融合の難しさ
知識融合は、異なる知識ソースを統合し、矛盾や重複を解消して一貫性のあるグラフを構築することに焦点を当てています。この中心的な課題は、異なるデータセットのエンティティが同一の実世界オブジェクトを参照しているかどうかを判断する「エンティティ・アライメント(Entity Alignment)」でした。
古典的なアプローチでは、主に語彙的な類似性や構造的な類似性に基づいて融合が行われていました。しかし、この手法では、意味的な違い(セマンティックな異質性)を持つデータの統合や、知識が動的に更新されていく環境への対応に苦慮しました。エンベディングベースの手法も導入されましたが、依然として大規模な統合や動的な知識更新に対する課題は残されていました。
このように、従来の知識グラフ構築は、各段階での厳格なルール設定やデータ依存性により、柔軟性、拡張性、そして適応性に欠けており、自己進化する動的な知識グラフを構築する上での障壁となっていました。

LLMによる構築プロセス
LLMは、プロンプトベースの相互作用を活用することで、従来の知識グラフ構築における断片化された各ステージを、生成的で統一的なフレームワークへと統合しつつあります。LLMは、自然言語による指示駆動型オーケストレーション(Instruction-driven orchestration)を可能にし、知識抽出、構造化、および推論が相互依存的なプロセスとして機能する、統一的かつ適応的なエコシステムを生み出しています。
この変化は、従来の「3層パイプライン」であったオントロジー工学、知識抽出、知識融合のすべてに及んでいます。
スキーマの自動生成: 専門家依存からの脱却
オントロジー工学は、LLMが共同モデラーとして機能することにより、専門家への依存が大幅に削減され、自動化されつつあります。研究は、トップダウンとボトムアップの2つの相補的な方向性で進展しています。
トップダウン・アプローチ – LLMをモデリングアシスタントとして利用
このアプローチは、事前に定義された意味的要件に基づいてオントロジーを開発する従来の知識工学を拡張するものです。LLMは、システム要件や専門家の質問などの自然言語による仕様を、Web Ontology Language といった形式オントロジーに変換することを支援します。
具体的な実装例として、「Ontogenia」フレームワークがあります。このフレームワークでは、メタ認知プロンプト(Metacognitive Prompting)が導入され、モデルがオントロジー合成中に自己反省と構造的な修正を行うことを可能にしました。これにより、LLMは概念の厳密性を保ちつつ、オントロジー設計のライフサイクル全体を半自動化する能力を示しています。
| Metacognitive Promptingステージ | Ontogeniaステージ | 説明 |
| 理解の明確化 | コンピテンシー質問(CQ)の理解 | LLMはCQを解釈し、文脈化する。 |
| 予備的判断 | 文脈の予備的特定 | 論理分析は、CQからのクラスとプロパティの特定をサポートする。 |
| コンピテンシー質問を主語、述語、目的語、および名詞述語に分割する。 | ||
| 批判的評価 | 自分の知識から開始し、これらの制約でオントロジーを拡張する。 | CQを振り返り、ルールと制約を追加してモデルを強化する。 |
| 決定の確認 | 最終的な回答を確認し、その推論を説明する。 | 意思決定プロセスを正当化する。 |
| 信頼性の評価 | 信頼性評価と説明を行い、インスタンスでオントロジーをテストする。 | プロセスを評価し、特定のインスタンスでモデルの正確性をテストする。 |
ボトムアップ・アプローチ – 知識グラフをLLMの動的メモリとして活用
ボトムアップ手法では、知識グラフは人間が解釈するための静的なリポジトリとしてではなく、LLMベースのエージェントシステムにおける事実に基づいた動的なインフラとして捉えられます。
このパラダイムでは、「GraphRAG」 や「OntoRAG」 のようなフレームワークが基盤を築きました。これらは、生データからインスタンスレベルのグラフを生成した後、クラスタリングや一般化を通じてオントロジー的なコンセプトを自動で抽出・誘導します。このプロセスは、特に継続的なスキーマ適応や進化が求められる知識環境において、静的なスキーマ構築から動的なスキーマ適応へと焦点を移すことを可能にしました。
知識抽出: 固定テンプレートを超えた柔軟性
LLM駆動の知識抽出は、「スキーマベース」と「スキーマフリー」という2つの主要なパラダイムに沿って進化しており、従来の知識抽出手法の制約であったデータ不足や汎化性能の低さを克服しています。
スキーマベース抽出 – 精度と整合性を重視
この手法は、明示的なオントロジーを構造的な制約として利用し、抽出の精度と解釈可能性を保証します。最近の進展では、静的な全体スキーマに縛られず、特定のエンティティや文脈に合わせてオントロジー・スニペット(スキーマの部分集合)を動的に選択し、プロンプトを構築する手法(例:「ODKE+」)が登場しています。これにより、厳格な構造的制約を保ちつつも、局所的な適応性が向上しています。

スキーマフリー抽出 – オープンな発見能力と推論の活用
スキーマフリー抽出は、事前定義されたオントロジーに依存せず、生のテキストからエンティティや関係を自律的に発見することを目指します。
技術的なポイントは、ステップバイステップの推論を促すChain-of-Thought (CoT)プロンプティングを組み込み、外部スキーマの代わりに暗黙的またはオンザフライ(その場限り)のスキーマを生成することです。さらに、抽出プロセスを「ChatIE」 のようにマルチターンの対話プロセスとして再構築することで、モデルが反復的にエンティティや関係の候補を洗練させ、より一貫した知識を生成できるようになっています。
知識融合: 推論による精度の高いエンティティ整合
知識融合におけるLLMの役割は、語彙的な類似性に基づく表面的なマッチングから、文脈的推論(Contextual Reasoning)に基づいた高度な意味的整合へと移行しています。
インスタンスレベル融合の進化
エンティティ・アライメント(異なるデータセットの同一実体の特定)は、LLMによって制約付き多肢選択問題 や文脈的推論タスク として再構築されています。
LLMは、エンティティの記述やクラス階層といったRAG(Retrieval-Augmented Generation)ベースの情報を活用することで、構造情報だけでなく、意味的な手がかりを用いて曖昧なエンティティに対するロバストな推論を行うことができます。また、効率化のため、「ComEM」 のように、軽量フィルタリングと大規模LLMによる詳細推論を組み合わせた階層的設計も導入され、大規模な融合タスクにおける高精度と効率性の両立が図られています。
LLMは、知識グラフ構築の全工程において、柔軟性、適応性、そして拡張性を劇的に向上させる、統合的な認知レイヤーとしての役割を確立しつつあると言えます。

知識グラフの応用
知識グラフの構築をLLMが牽引することで、現在のシステム設計に直接的な影響を与え、将来的に新たなAIアプリケーションの可能性を大きく広げています。知識グラフは、言語理解と構造化された推論を融合させる役割を確立しつつあると考えられています。
エージェントシステムの動的知識メモリ
LLMベースのエージェントが自律性を持って動作するためには、有限なコンテキストウィンドウの限界を超える、持続的で構造化されたメモリの確保が必須の課題です。
知識グラフは、エージェントの相互作用に応じて継続的に進化する動的メモリ基盤として機能します。例えば、「A-MEM」のようなフレームワークでは、エージェントの長期的な記憶がコンテキストメタデータで強化された相互接続された「ノート」としてモデリングされ、継続的な再構成と成長を可能にします。また、「Zep」のアーキテクチャでは、時系列知識グラフ(Temporal Knowledge Graph, TKG)を使用し、事実の時間的な妥当性管理や時間認識型の推論、更新をサポートしています。これらの進展は、知識グラフを解釈可能な長期記憶システムとして活用し、エージェントの継続的な学習、マルチエージェントの協調作業、そして自己反省的な推論を実現します。

LLM推論の強化と説明性の向上(RAGのその先へ)
知識グラフは、RAGシステムにおける単なる検索バックボーンという役割を超えて、生の入力とLLMの推論を繋ぐ認知的中間層(Cognitive Middle Layer)として構想されています。
このパラダイムにおいて、知識グラフはLLMに対し、クエリ、プランニング、意思決定のための構造化された足場(Structured Scaffold)を提供し、その生成結果がより解釈可能で根拠のあるものになります。技術的な応用としては、「知識グラフベースのランダムウォーク推論(Random-Walk Reasoning)」などにより、LLMの論理的整合性や因果推論を向上させる可能性が示されています。また、レコメンデーション(例:「CogER」)や、精神衛生診断における予測モデリング(例:「LLM-PKG」)など、高度な推論が求められるドメインで、知識グラフをインタラクティブな推論基盤として利用する手法が活用されています。

マルチモーダルな知識グラフの構築: テキスト以外のデータ統合
LLMとVLM(Vision-Language Model)の共進化に伴い、テキスト、画像、音声、ビデオなどの異種モダリティを、統一された構造化表現に統合するマルチモーダル知識グラフ構築が進行しています。
代表的な研究である「VaLiK」では、事前学習されたVLMをカスケード接続して視覚的特徴をテキスト形式に変換し、クロスモーダル検証モジュールでノイズを除去してマルチモーダル知識グラフを組み立てます。この手法により、手動アノテーションなしでエンティティと画像を連携させることが可能になります。マルチモーダル知識グラフは、知覚的な入力と記号的な推論を結びつけるための礎となり、知識集約的なアプリケーションの可能性を広げる重要な礎石です。

おわりに
今回は、LLMが知識グラフ構築のあり方を根本的に変容させている現状について解説しました。LLMは、従来のルールベースで分断されたパイプラインを、統一的で、適応的で、生成的なフレームワークへと進化させています。
この変革の中心となるトレンドは3点に集約されます。それは、静的なスキーマからデータ駆動型で動的に誘導されるスキーマへの進化、パイプラインの断片化からプロンプト駆動型による生成的な統一への統合、そしてシンボリックな硬直性から意味的適応性への移行です。これらのシフトにより、知識グラフは、単なる知識のかたまりではなく、言語理解と構造化された推論を融合させたインフラストラクチャとして再定義されつつあります。
今後の進展は、スケーラビリティや継続的な適応といった残された課題を克服し、プロンプト設計、マルチモーダル統合、そして知識に基づいた推論 の深化が鍵と考えられています。
More Information
- arXiv:2510.20345, Haonan Bian, 「LLM-empowered knowledge graph construction: A survey」, https://arxiv.org/abs/2510.20345
関連記事

LLM-as-classifier: 階層的テキスト分類器の構築方法
2010年代以降、膨大なテキストデータから深い意味的パターンを認識するニーズは、かつてないほど高まっています。これまでのテキスト分類は、大量のラベル付きデータを用いたファインチューニング(Fine-tuning)が主流で […]

MetaGPT: マルチLLMエージェントフレームワークを使ってみる
近年、AI技術は目覚ましい進化を遂げており、特に大規模言語モデル(LLM)の発展がソフトウェア開発の分野に革新をもたらしています。その中でも、MetaGPTは、マルチエージェントシステムを活用してソフトウェア開発の自動化 […]

進化する知能: LLMエージェントの最新動向とエンジニアが知るべき技術的視点
近年、LLM(Large Language Model)エージェントがAI分野において急速に注目を集めています。LLMエージェントは、単にユーザーの入力に応答する従来のAIシステムとは異なり、大規模言語モデルを基盤とし、 […]