RecursiveMAS: 潜在空間の再帰による次世代マルチエージェント協調

現在、マルチエージェントシステム(MAS)において、エージェント間で「テキスト」を介して情報をやり取りする手法が一般的ですが、これが推論レイテンシ(遅延)を増大させる主な要因となっています。他のエージェントのテキスト出力が完了するまで待機する必要があるため、システム全体の協調をEnd-to-Endで学習し、最適化することが非常に困難になっています。
この記事では、この課題を解決する新しいフレームワーク「RecursiveMAS」のアーキテクチャを紹介します。RecursiveMASは、テキストの代わりに「潜在空間(Latent Space)」を用いてエージェント間の連携を進めます。そして、再帰的なループ処理によってシステム全体をスケールさせるという斬新なアプローチをとっています。
今回は最新の論文「Recursive Multi-Agent Systems」をもとに、その学習プロセスや技術的な利点について詳しく解説します。
1. RecursiveMASのアプローチ
従来のマルチエージェントシステムの仕組みを見直し、RecursiveMASは計算効率と推論精度を両立するための新しいアーキテクチャを採用しています。その中核となるアプローチは、以下の3つのポイントに整理できます。
- テキスト媒介のボトルネックの解消: 従来のシステムでは、あるエージェントの出力を次のエージェントに渡す際、情報を都度テキストに変換(デコード)しています。このプロセスでは、モデルが持つ全語彙サイズ(\(|V|\))に対する確率計算をトークンごとに繰り返す必要があり、これが膨大な計算コストや推論レイテンシ(遅延)を発生させる原因となっていました。
- 潜在空間での再帰演算: RecursiveMASでは、各エージェントを「再帰的言語モデル(RLM: Recursive Language Model)」の1つのレイヤーのように扱います。エージェント間で情報を渡す際、テキストを生成せず、モデル内部の最終層の隠れ状態(潜在表現)をそのまま次のエージェントへ直接渡します。これにより、重い語彙サイズ(\(|V|\))に依存する計算を、より軽量な潜在空間の次元数(\(d_h\))での計算に置き換え、システム全体の計算複雑性を大幅に削減しています。
- 再帰による思考の深化: システムに配置された全てのエージェントの処理が完了したのち、最後のエージェントが出力した潜在表現を、再び最初のエージェントに戻してループさせます。この再帰的な循環によって、各エージェントは以前の推論結果を踏まえた修正を実施でき、より深い思考へと至ります。テキストへのデコードは、最終の再帰ラウンドにおける最後のエージェントのみが1回だけ実施します。これにより、途中経過の無駄なトークン消費を抑えつつ、全体の推論精度を効果的に向上させることが可能です。
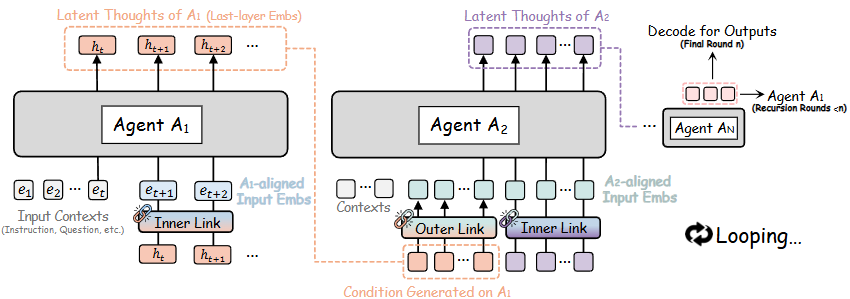
2. RecursiveLinkによる潜在空間の連結
前章で紹介した「潜在空間での再帰演算」を実現するコア技術が、「RecursiveLink」と呼ばれるモジュールです。このアプローチの最大の特徴は、LLM(ベースモデル)の膨大なパラメータを凍結したまま、この軽量なモジュールを追加・学習するだけでエージェント間の潜在表現を制御できる点にあります。
RecursiveLinkのネットワーク設計については様々な構造が検証されいます。例えば、1層のみの構造や、残差接続(Residual connection)を持たないネットワークと比較した結果、元の意味情報(セマンティクス)を保持しつつ分布のズレのみを学習する「残差接続を持つ2層のネットワーク」が最も高いパフォーマンスを示しました。
RecursiveLinkは、役割に応じて「Inner Link」と「Outer Link」の2つに分かれています。

Inner Link(内部リンク)
Inner Linkは、エージェント自身が自己回帰的に「潜在的な思考(Latent thoughts)」を生成し、次のステップへと伝達するためのモジュールです。
モデルの最終層から出力された埋め込みベクトル \(h\) を、以下の数式を用いて次のステップの入力空間へマッピングします:
$$ \mathcal{R}_{\text{in}}(h) = h + W_2\sigma(W_1h) $$
この式のポイントは、元のベクトル \(h\) をそのまま足し合わせる「残差接続」を採用している点です。これにより、元のセマンティクスを破壊することなく保持でき、ネットワークは分布の差分のみの学習に集中できるため、学習を安定させることが可能になります。
\(W_1, W_2\) は線形層、\(\sigma\) はGELU活性化関数を示します
Outer Link(外部リンク)
一方、Outer Linkは、アーキテクチャや隠れ層の次元数が異なる異種エージェント間で、潜在状態をスムーズに転送するためのモジュールです。
異なるモデル同士を繋ぐため、次元数の違いを吸収する必要があります。そこで、残差ブランチに追加の線形層 \(W_3\) を組み込み、次のように変換を実施します:
$$ \mathcal{R}_{\text{out}}(h) = W_3h + W_2\sigma(W_1h) $$
このように、Inner Linkでエージェント内部の思考を深め、Outer Linkで他のエージェントへ橋渡しをするという2段構えの仕組みにより、無駄なテキスト生成を省いた効率的な協調が実現されています。
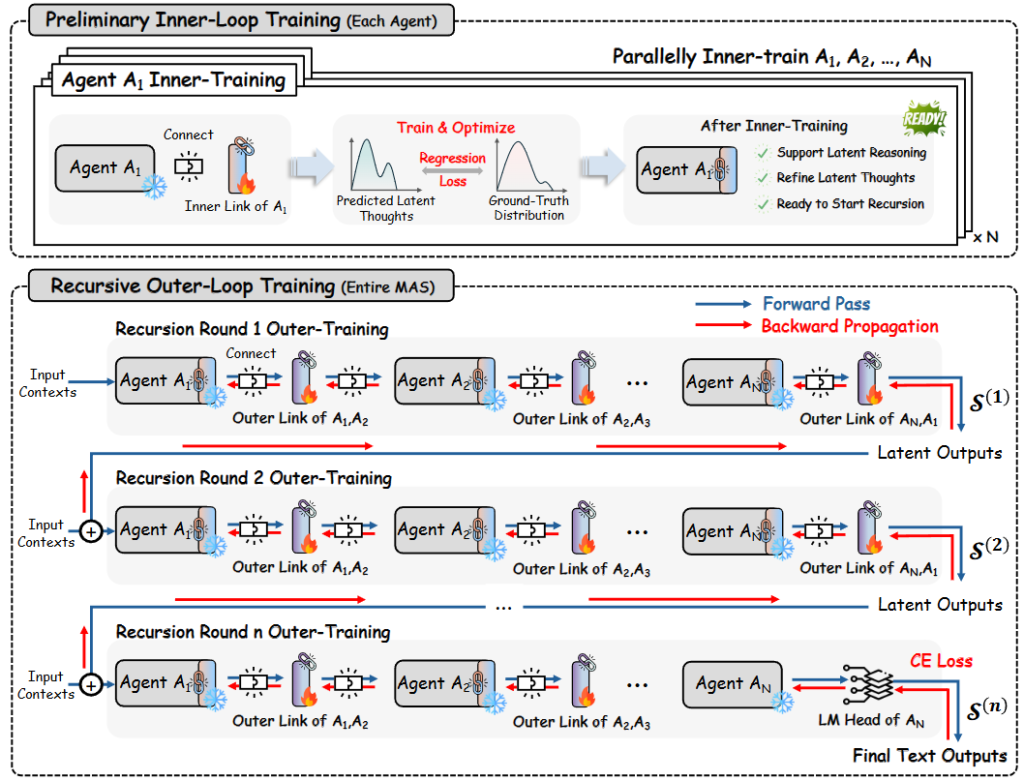
3. Inner-Outer Loop学習
RecursiveMASの強みは、個別のエージェントをバラバラに訓練するのではなく、システム全体を統合的に進化させる点にあります。この全体最適化を実現するために、「Inner-Outer Loop Training(内部・外部ループ学習)」という2段階の学習アルゴリズムを採用しています。
Inner-Outer Loop Training
具体的なプロセスは以下の2段階に分かれています。
- Inner Loop(内部ループ): 最初のステップでは、各エージェントに対して潜在思考の生成能力を「ウォームスタート(初期化)」させます。具体的には、エージェントが生成した潜在思考の分布を、正解テキストの「入力埋め込み層(Input Embedding)の分布」に近づけるよう、以下の数式で示される回帰目標を用いて最適化を実施します。
$$ \mathcal{L}_{\text{in}} = 1 – \cos(\mathcal{R}_{\text{in}}(H), \text{Emb}_{\theta_i}(y)) $$
ここで、\(H\) は生成された潜在思考、\(\text{Emb}_{\theta_i}(y)\) は正解テキスト \(y\) の埋め込み表現を示します。これにより、エージェントはテキストのデコード処理を挟むことなく、自分自身の内部で思考を深める準備が整います。 - Outer Loop(外部ループ): 次に、システム全体を一つの連続した処理として最適化します。システムが複数ラウンドの再帰ループを経て最終的なテキストを出力したのち、その最終出力の誤差から「ループの経路全体(Full Computation Trace)」をさかのぼって誤差を逆伝播させます。
$$ \mathcal{L}_{\text{out}} = \text{CE}(\mathcal{S}^{(n)}(\mathcal{S}^{(n-1)}(\cdots\mathcal{S}^{(1)}(x))), y) $$
ここで、\(\text{CE}\) は交差エントロピー誤差、\(\mathcal{S}^{(n)}\) は \(n\) 回目の再帰ラウンドにおけるシステムの状態を示します。この仕組みにより、エージェント同士を繋ぐすべてのOuter Linkが同時に調整され、システム全体としての協調が最適化されます。
学習の優位性と勾配の安定性
では、なぜテキストベースの学習ではなく、潜在空間を活用するのでしょうか?
従来のテキストベースのSFT(Supervised Fine-Tuning: 教師ありファインチューニング)を用いて再帰的な学習を進めた場合、トークン予測の確信度が高い(エントロピーが低い)場面において、「勾配消失(Gradient vanishing)」という現象が起こりやすくなるという理論的な課題があります。勾配が消失すると、ループを遡って正しく学習させることができません。
しかし、潜在空間で情報を直接やり取りするRecursiveMASでは、複数回の再帰ループを経ても勾配が安定して伝播し続けます。この勾配の安定性こそが、システム全体を効率的かつ効果的に最適化できる最大の理由となっています。
4. サポートされる様々な協調パターン
RecursiveMASのもう一つの大きな特徴は、特定のネットワーク構造やシステムアーキテクチャに依存しない柔軟性を持っている点です。実際、マルチエージェントシステムで一般的に採用される以下の4つの主要な協調パターンがRecursiveMASを適用され、その有効性が確認されています。
- Sequential Style(逐次型): 「Planner(計画役)」「Critic(評価役)」「Solver(解決役)」という役割の異なる3つのエージェントを直列に繋ぐパターンです。入力された問題をPlannerが段階的に分解し、Criticがその計画を評価・修正し、最後にSolverが具体的な解決策を導き出すというように、順を追って処理を進めます。
- Mixture Style(混合型): Math(数学)、Code(プログラミング)、Science(科学)といった特定の領域に特化した複数の専門エージェントを配置するパターンです。これらの専門エージェントが並行して推論を進め、最終的に「Summarizer(要約役)」エージェントがそれぞれの潜在的な推論結果を統合して、一つの最終回答を生成します。
- Distillation Style(蒸留型): パラメータサイズが大きく高度な推論能力を持つ「Expert(専門家)エージェント」と、サイズが小さく高速な「Learner(学習者)エージェント」をペアにするパターンです。この2つを再帰的に対話させることで、Learnerの高い推論スピード(効率)という強みを維持しつつ、Expertの持つ高度な知識をLearnerへと蒸留(移転)させ、システム全体のパフォーマンスを効果的に向上させます。
- Deliberation Style(熟考型): Web検索APIやPython実行環境などの外部ツールを操作できる「Tool-Caller(ツール呼び出し役)」と、その出力や解決策を評価して改善を促す「Reflector(内省役)」を相互に協調させるパターンです。両者が潜在空間で何度もやり取りと修正を重ねて合意を形成することで、ツールを用いた複雑な問題解決の精度を高めます。
このように、解決したい課題に合わせてエージェントの構成や役割を柔軟に組み替えることができるため、様々な実践的なユースケースに対して最適なAIチームを構築することが可能です。
| Collaboration Pattern | Role | Model Size & Version |
|---|---|---|
| Sequential Style (Light) | Planner | Qwen3-1.7B (Yang et al., 2025) |
| Critic | Llama3.2-1B-Instruct (Grattafiori et al., 2024) | |
| Solver | Qwen2.5-Math-1.5B-Instruct (Qwen et al., 2025) | |
| Sequential Style (Scaled) | Planner | Gemma3-4B-it (Team et al., 2025) |
| Critic | Llama3.2-3B-Instruct (Grattafiori et al., 2024) | |
| Solver | Qwen3.5-4B (Yang et al., 2025) | |
| Mixture Style | Code Specialist | Qwen2.5-Coder-3B-Instruct (Hui et al., 2024) |
| Science Specialist | BioMistral-7B (Labrak et al., 2024) | |
| Math Specialist | DeepSeek-R1-Distill-Qwen-1.5B (Qwen et al., 2025) | |
| Summarizer | Qwen3.5-2B (Yang et al., 2025) | |
| Distillation Style | Learner | Qwen3.5-4B (Yang et al., 2025) |
| Expert | Qwen3.5-9B (Yang et al., 2025) | |
| Deliberation Style | Reflector | Qwen3.5-4B (Yang et al., 2025) |
| Tool-Caller | Qwen3.5-4B (with Tool-Integration) (Yang et al., 2025) |
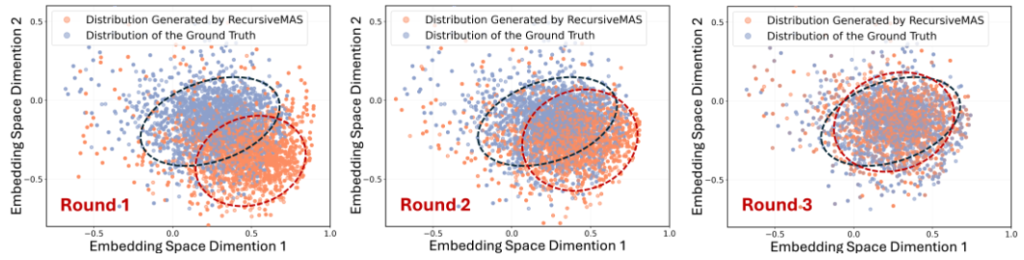
5. 潜在表現の推移と自己修正
潜在空間で思考をループさせることで、エージェントの出力はどのように変化するのでしょうか?論文では、再帰ラウンド(\(r\))を重ねるごとの「潜在表現の推移」と「自己修正(Refinement)」の挙動について、興味深い分析結果が示されています。
- 潜在表現の推移と正解への接近: 研究チームは、様々な分野から抽出した500件の質問に対するエージェントの最終出力の潜在表現を、PCA(主成分分析)を用いて可視化しました。その結果、初期ラウンド(\(r=1\))における出力の潜在表現の分布は、正解の分布から大きくズレていることが多いと分かりました。しかしながら、再帰ラウンドを(\(r=2, 3, \cdots\))と重ねて処理を進めるにつれて、その分布は徐々に正解の分布へと近づき、最終的にはほぼ一致することが確認されています。これは、再帰的なループが単なる計算の繰り返しではなく、意味的な表現を正解に向けて効果的に洗練させていることを示しています。
- 推論プロセスにおける自己修正の挙動: こうした分布の変化だけでなく、実際の推論プロセスでも「自己修正」が機能していることが、MATH500などのケーススタディから明らかになっています。たとえば、約数の個数を求める数学の問題において、初期ラウンド(\(r=1\))のエージェントはペアの数え上げで重複や抜け(ダブルカウントなどの推論ミス)を発生させ、誤った回答を出力しました。ですが、後続の再帰ラウンド(\(r=2, 3, \cdots\))を経ることで、エージェントは自らのアプローチの誤りに気づいて修正に取り組みます。最終的には、約数を正しく列挙するより短く洗練された推論へと自らを導き、正しい回答へと辿り着きました,。
このように、RecursiveMASはテキストの出力を間に挟むことなく、潜在空間の中だけで自らの思考の誤りを振り返り、正しい方向へと軌道修正する能力を備えているのです。
6. パフォーマンスと効率向上
新しいAIシステムを実運用に乗せる際、いくら精度が高くても、計算コストやレイテンシ(遅延)が大きすぎては困ります。ここでは、RecursiveMASがどのようにパフォーマンスと効率性を両立しているのかを、4つの観点から解説します。
- 推論速度とコストの削減: 推論時の再帰の深さ(ラウンド数 \(r\))が増えるにつれて、テキストベースのMASと比較したRecursiveMASの優位性はさらに際立ちます。検証によると、推論のスピードアップ率は \(r=1\) で1.2倍、\(r=3\) では最大2.4倍に達しました。また、トークン使用量についても、中間のテキスト出力を省略できるため、\(r=1\) で34.6%、\(r=3\) では最大75.6%もの大幅な削減を実現しています。
- 訓練と推論のスケーリング則: RecursiveMASでは、訓練時の再帰ラウンド数と推論時の再帰ラウンド数をともに増やすことで相乗効果が生まれます。少ないラウンド数で訓練したシステムでも推論時の再帰を深めることで性能は向上しますが、訓練時の再帰も深くすることで全体のパフォーマンス限界がさらに押し上げられ、右肩上がりにスケールする傾向が確認されています。
- 潜在思考長(ステップ長)の最適化: 各エージェント内部で生成する潜在思考の長さ(ステップ長 $m$)についての検証も進められました。ステップ長 \(m\) を増やしていくと、初期段階では全体のパフォーマンスが向上します。しかしながら、\(m=80\) 程度の長さで性能が安定(飽和)することが分かっています。つまり、テキストベースの推論で必要となる長大な思考プロセスとは異なり、過度な計算リソースを費やす必要はありません。
- 学習コストの低減: 最後に、学習にかかるリソースを比較した表を以下に示します。
| 学習手法 | GPUメモリ使用量 | 更新パラメータ数 | 平均精度 |
|---|---|---|---|
| Full-SFT (フルパラメータ) | 41.40 GB | 約 42.1億 (100%) | 68.6% |
| LoRA | 21.67 GB | 約 1,592万 (0.37%) | 66.9% |
| RecursiveMAS | 15.29 GB | 約 1,312万 (0.31%) | 74.9% |
このように、LoRAやフルパラメータのSFT(教師ありファインチューニング)と比較して、RecursiveMASは更新するパラメータがシステム全体のわずか約0.31%に抑えられています。そのため、GPUメモリの使用量や学習コストが最も少なく済むにもかかわらず、最も高いパフォーマンスを発揮しています。
少ないリソースで高い性能を引き出せるRecursiveMASは、非常に実用的なアーキテクチャだと言えます。
おわりに
この記事では、次世代のマルチエージェント協調を実現する新しいフレームワーク「RecursiveMAS」について紹介しました。
RecursiveMASは、エージェント間の協調プロセスをテキストから「潜在空間」へと移行させることで、推論速度の大幅な向上やトークンコストの削減、そして安定したシステム全体のEnd-to-End最適化を実現します。また、特定のネットワーク構造に依存せず、様々なコラボレーションパターンに柔軟に適応できる点も大きな魅力です。さらに、再帰的なループを活用した自己修正能力や明確なスケーリング則を備えており、限られた計算リソースであってもシステムから高い推論能力を引き出すことが可能です。
実用的なLLMベースのマルチエージェントアプリケーションを構築・運用していく上で、効率性と拡張性を兼ね備えたRecursiveMASは、間違いなく非常に有力なアプローチとなるでしょう。
More Information
- arXiv:2604.25917, Xiyuan Yang et al., 「Recursive Multi-Agent Systems」, https://arxiv.org/abs/2604.25917
関連記事

画像認識アーキテクチャの進化大全: CNN・ViT・Mamba・MLPの比較
AI技術の急速な進歩により、画像認識は私たちの生活に深く浸透し、顔認証、自動運転、医療画像診断など、多岐にわたる分野で革新をもたらしています。この画像認識技術の発展を支えているのが、ディープラーニングにおけるモデルアーキ […]

The Multimodal Universe: 天文学向け大規模機械学習用ビッグデータ
天文学は、その観測対象の広大さと複雑さから、常に膨大なデータを扱う分野です。近年、技術の進歩に伴い、画像、スペクトル、時系列データなど、多種多様な形式のデータが取得できるようになりました。これらのデータを統合的に解析する […]

Prompt Repetition: プロンプト反復によるLLMの改善
LLMの精度向上のために、日々プロンプトの試行錯誤を繰り返しているエンジニアは多いはずです。Google Researchの研究チームは、そのような課題に対し、非常にシンプルかつ強力な解決策である「Prompt Repe […]