機械学習モデルにおける不確実性

今日、機械学習モデルは、私たちの生活やビジネスのあらゆる側面に浸透しています。しかしながら、その高い予測精度とは裏腹に、モデルの信頼性や頑健性には依然として重大な課題が残されています。
実際、レベル5の自動運転車がカメラの照明不足やレーダーの解像度不足といったセンサーの限界に直面し、致命的な事故につながるケース や、医療分野で訓練データが少ないために、COVID-19の診断モデルが臨床的に使用できないと結論付けられた報告 があります。ビジネスにおいても、サプライチェーン計画における需要予測の過小評価による在庫切れ、正当な取引を誤って不正と見なすシステムなど、甚大なコストを伴う誤判断が発生しています。
こうした問題の原因は、ほとんどの機械学習モデルが、その予測に付随する不確実性(Uncertainty)を認識することなく、常に何らかの出力を出してしまう点にあります。モデルは、訓練データと大きく異なるケースやノイズの多いデータに遭遇しても、予測の信頼性が低い場合にそれを拒否するオプションを持たないのが一般的です。
不確実性を定量化し、自信がない場合には予測を見送る機能を持つこと は、機械学習モデルのビジネスへの広範な導入と、より情報に基づいた意思決定を可能にするために不可欠です。今回は、この「不確実性」をどのように捉え、定量化し、実際に活用していくのかを深く掘り下げていきます。
不確実性とは何か
機械学習モデルの予測に伴う「不確実性(Uncertainty)」は、その発生源によって大きく2つのカテゴリに分類されます。この分類は、現在も機械学習の分野で広く用いられているものです。予測がなぜ信頼できないのか、その根本的な原因を突き止めることは、モデルの性能改善に向けた適切なアプローチ(データの収集か、モデル構造の変更かなど)を選択する上で不可欠です。

認識論的不確実性(Epistemic Uncertainty)
認識論的不確実性とは、訓練データの不足に起因する不確実性のことを指します。これは「モデルの不確実性(Model Uncertainty)」とも呼ばれ、モデルが持つ知識や理解が不十分であるために生じます。
具体的には、訓練データに存在しない領域(ドメイン)での予測や、訓練データが極めてまばら(スパース)な領域で顕著に現れます。
- 実例:
- 訓練データには猫と犬の画像のみが含まれているモデルが、ラクダの画像を入力された場合、不確実性を示すことなく猫か犬として分類を試みてしまうケース。
- 自動運転車が、訓練時には想定されていなかった「極めて稀な状況」に直面するケース。
- 既存製品のデータで訓練された需要予測モデルが、新製品の需要を予測する際に、データ不足からくる不確実性の高まりによって、予測の信頼性が低下するケース。
- 医療研究において、特定の性別や人種がデータに不足しているために、そのグループに対する予測の不確実性が高まるケース。
この種の不確実性は、低減可能(Reducible)であるという重要な性質を持っています。不確実性の高い領域のデータを追加で収集し、モデルを再訓練することで、モデルの知識不足を解消し、不確実性を低減できます。
偶然的不確実性(Aleatoric Uncertainty)
偶然的不確実性とは、データ自体に内在するノイズやランダム性に起因する不確実性です。これは、たとえモデルが理想的な量の訓練データにアクセスできたとしても、入出力の関係が本質的にノイズを含んでいたり、ランダムであったりするために避けられないものです。
- 実例:
- 訓練データに含まれる誤ったラベル付け(例:センサーの不具合や人間によるラベリングミス)。
- 自動運転車のレーダーにおける、低解像度や干渉問題。
- 信用スコアリングモデルにおいて、申請者による所得報告のノイズや、地域の経済状況を示す重要な未観測の変数が欠落している場合。
- コイントスの結果など、本質的にランダムな現象の予測。
偶然的不確実性は、一般的に低減不可能(Irreducible)と見なされます。いくらデータを集めても、データ生成プロセスそのものにノイズが含まれている限り、不確実性は残ります。この不確実性に対処するには、より高精度で頑健なセンサーの導入など、ノイズの原因そのものを改善する必要があります。
ただし、ノイズに見えるものが、実はモデルが観測していない体系的な影響(例:特定の返品ポリシーや環境条件)に起因している場合もあります。このような未観測の関連変数をモデルに追加することで、見かけ上の偶然的不確実性を認識論的不確実性に変え、結果的に不確実性を緩和できるケースもあります。
両者の関係
実務においては、認識論的不確実性と偶然的不確実性を完全に分離することは難しい場合が多く、文脈に依存することもあります。しかし、自律走行車が予測の不確実性に直面した場合、その原因が予期せぬ物体(認識論的)であろうと、突然の降雪(偶然的)であろうと、最終的には運転手に制御を戻すなど、総不確実性(Total Uncertainty)が意思決定には最も重要になります。
この不確実性の2分類の理解は、モデルの信頼性を高めるためのデータ収集戦略や、ロバストなモデル設計に直結する基礎知識となります。

不確実性の定量化
前の章で不確実性を2つのタイプに分類しましたが、実務において重要なのは、これらの不確実性を具体的に定量化することです。モデルが自身の予測に対してどれだけの「自信」を持っているのかを数値で示すことで、初めて不確実性が意思決定に活用できるようになります。
ここでは、アンサンブル学習の代表例であるランダムフォレストと、現代の予測モデルの中核をなすニューラルネットワークにおける不確実性の定量化手法を見ていきます。
ランダムフォレストによる不確実性の分解
ランダムフォレスト(Random Forest)は、複数の決定木の結果を集計して最終予測を行うアンサンブル学習法です。このアンサンブル構造を利用し、情報理論の概念であるエントロピー(Entropy)を用いることで、分類タスクにおける不確実性を認識論的と偶然的なものに分解できます。
ランダムフォレストは、アンサンブルを構成する個々のモデルの予測のばらつきを捉えることで、モデルが持つ知識の不足(認識論的不確実性)を浮き彫りにします。
不確実性の分解の概念
- 総不確実性 (\(H_h\)): モデルの最終的な予測確率分布に対するシャノンエントロピー(Shannon Entropy)として定義されます。予測の全体の不確実性、すなわち、分類結果がどれだけ曖昧かを示します。
- 偶然的不確実性 (\(C_h\)): アンサンブルを構成する個々のモデルが予測する確率ベクトルのエントロピーを平均したものとして計算されます(条件付きエントロピー)。個々のモデルがどれだけデータ内在のノイズ(ランダム性)に苦しんでいるかを捉える尺度です。
- 認識論的不確実性 (\(I_h\)): 認識論的不確実性は、総不確実性から偶然的不確実性を引いた差として定義されます (\(I_h = H_h – C_h\))。これは情報理論における相互情報量(Mutual Information)に対応します。この値は、アンサンブル内の個々のモデルの予測がどの程度乖離しているか、すなわち、モデルの知識不足を定量化します。
この手法の大きな利点は、不確実性を原因別に分解できる点です。認識論的不確実性が高ければ、データを追加収集すべきという判断につながり、偶然的不確実性が高ければ、データ品質の問題(ノイズ)や、重要な変数の欠落を調査すべきという指針が得られます。
ニューラルネットワークにおける不確実性推定
古典的な決定論的ニューラルネットワークは、訓練データ外の観測に対してであっても、単一の予測値を出力してしまい、自身の知識不足(認識論的不確実性)を認識できません。この課題を克服するために、重み(パラメータ)を単一点ではなく分布として捉えるベイズ的アプローチが導入されます。
認識論的不確実性の近似
ベイジアンニューラルネットワーク(Bayesian Neural Networks: BNNs)の厳密な解法は計算が困難なため、近年ではその近似手法が用いられます。その1つが、正則化手法であるドロップアウト(Dropout)を推論時(Inference)にも有効なままにしておくアプローチです。
- 手法: 推論時にドロップアウトを有効にしたまま、\(T\)回(例: \(T=50\)回)の確率的な順伝搬パス(Forward Pass)を実行します。
- ロジック: ドロップアウトが有効な状態では、順伝搬パスごとに異なるノードが無効化され、結果として異なるモデル(重み分布のサンプリング)が使用されたと見なせます。
- 定量化: この\(T\)回の予測結果から得られた標本分散が、認識論的不確実性を定量化する尺度となります。分散が大きいほど、モデルの知識不足が大きいことを意味します。
偶然的不確実性の学習
偶然的不確実性 (\(\sigma^2_h\)) は、ニューラルネットワークの学習プロセス自体を通じて捉えることができます。
- 手法: ネットワークの最終層の出力を2重にし、通常の予測値 (\(y_h\)) と同時に、不確実性の推定値 (\(\sigma^2_h\)) の両方を予測するようにモデルを設計します。
- 実装: この推定値を、特殊な損失関数に組み込みます。特に、ノイズの大きいデータ点に対してモデルが高い \(\sigma^2_h\) を予測すると、そのデータ点からの損失への寄与が低減される仕組み(損失の減衰/Loss Attenuation)を利用します。
この手法により、ニューラルネットワークはノイズが大きいデータ(偶然的不確実性が高い)に対しては自信がないことを学習し、予測の信頼度を単一の出力値だけでなく、認識論的および偶然的不確実性の両方の尺度で提供できるようになります。

コンフォーマル予測とは?
線形回帰モデルは、その予測に対して信頼区間を構築できますが、均一分散性(Homoscedasticity)や残差項の正規分布など、比較的に強い統計的仮定を満たしている必要があります。これらの仮定が現実世界のデータで破られてしまうと、計算された信頼区間はもはや真の不確実性を反映しなくなり、信頼性が低下してしまいます。
また、前章で紹介したように、ニューラルネットワークやランダムフォレストといった最新のモデルでも、不確実性の定量化は可能ですが、その手法は複雑であり、信頼区間や予測セットの導出は煩雑になりがちです。
こうした課題を克服し、モデルの予測に統計的に有効な信頼保証を与えるための強力なフレームワークが、コンフォーマル予測(Conformal Prediction: CF)です。
モデルに依存しない予測保証
コンフォーマル予測の最大の特徴は、そのモデル非依存性(Model-agnostic)にあります。コンフォーマル予測は、線形回帰、ランダムフォレスト、ニューラルネットワークなど、あらゆる予測モデルと組み合わせて使用することが可能です。さらに、特定のデータ分布について一切の仮定を必要としません。
コンフォーマル予測は、既に訓練された予測モデルと、訓練データからホールドアウトされたキャリブレーションセット(Calibration Set)を用いるだけで適用できます。モデルの再訓練は不要であり、計算効率が高い点も大きな利点です。
統計的保証を備えた予測セットの生成
コンフォーマル予測の主な機能は、任意の信頼確率(\(1-\alpha\))を満たすように、統計的に保証された予測セット(分類タスクの場合)または予測区間(回帰タスクの場合)を生成することです。
たとえば、信頼確率を \(90%\)(\(\alpha=0.1\))と設定した場合、コンフォーマル予測によって生成された予測セット \(C(x_h)\) は、平均して \(90%$\) の確率で真のターゲット \(y_h\) を含みます。この保証は、データ量が有限であっても統計的に厳密なものとなります。
理想的には、予測セットと区間は狭い方が好ましいですが、予測セットのサイズと、真のターゲットが含まれる確率の間にはトレードオフが存在します。信頼レベルを高く設定する(\(1-\alpha\) を大きくする)ほど、セットや区間は広くなります。
分類タスクにおけるロジック
分類タスクにおいて、コンフォーマル予測は以下のロジックで予測セットを構築します。
- コンフォーマルスコアの計算: 訓練済みのモデルを用いて、キャリブレーションセット内の各観測 \(x_i\) について、真のクラスラベル \(y_i\) に対する予測確率 \(\hat{f}(x_i)_{(y_i)}\)(ソフトマックス出力)を計算します。この真の確率を用いて、コンフォーマルスコア \(s_i = 1 – \hat{f}(x_i)_{(y_i)}\) を定義します。予測の信頼性が低いほど、スコア \(s_i\) は高くなります。
- 閾値 (\(\hat{q}\)) の決定: 計算されたすべてのスコア \(s_i\) を昇順にソートし、所望の信頼レベル \(1-\alpha\) に基づいて閾値 \(\hat{q}\) を決定します。
- 予測セットの構築: 新しいテスト観測 \(x_h\) に対してモデルが出力するソフトマックス確率のうち、\(1 – \hat{q}\) 以上となるクラス \(y\) をすべて選び出します。これらが最終的な予測セット \(C(x_h)\) を構成します。
活用事例
この手法は、曖昧さを含む意思決定が必要なビジネスシーンで特に有用です。例えば、カスタマーインテント(顧客の意図)のタグ付けを行う分類タスクで有効です。
従来のモデルが単一の意図(例:「支払い問題」)を予測するのに対し、CFは \(90%\) の確率で真の意図を含む可能性のある意図のセットを出力できます。
曖昧な問い合わせ「アプリがクラッシュしてチェックアウトできません」に対して、単一の予測に固執するのではなく、「{技術サポート, 製品バグ}」のように複数の可能性を示すことで、顧客対応の信頼性が向上します。これにより、問い合わせを関連する複数のチームに確実にルーティングしたり、複雑なリクエストの潜在的な側面をすべて網羅したりすることが可能になり、顧客満足度の維持に貢献します。
不確実性を実務に活用する
機械学習モデルが不確実性を定量化できるようになったことで、その活用範囲は単に予測値を出すだけに留まらず、予測システムの全体的なパフォーマンス向上と、実務における意思決定の効率化にまで拡大します。
予測システムの改善
不確実性に関する理解は、予測システムの設計や改善フェーズにおいて、データとモデルの品質を評価するための枠組みを提供します。
データの質の向上と収集の指針
- 偶然的不確実性の活用: 高い偶然的不確実性は、データ品質の問題を指し示します。これは、センサーのエラー、人間のラベリングにおけるエラーやバイアス、あるいはモデルにとって不可欠な説明変数の欠落を示唆している可能性があります。例えば、ある特定の地域で特有の返品ポリシー(例:送料無料や延長された返品期間)がデータセットに含まれていない場合、その地域の顧客返品はモデルから見ると予測不能なノイズに見えるため、偶然的不確実性が高まります。このような欠落変数をモデルに組み込むことで、偶然的不確実性を低減できます。
- 認識論的不確実性の活用: 認識論的不確実性が高い場合は、ドメインの特定の領域でデータが不足していることを示しています。認識論的不確実性は削減可能であり、データを追加することで低減できますが、データの収集にはコストが伴います。この不確実性を活用し、費用対効果を考慮しながら、次にどのデータを取得すべきかを決定するのに役立てる手法が、アクティブラーニング(Active Learning)です。
システム監視とドリフトの検出
運用中のシステムにおいて不確実性が上昇することは、入力データの分布が変化するデータドリフトや、入力と出力の関係性が時間とともに変化するコンセプトドリフトを早期に検出するシグナルとなり得ます。不確実性を継続的に監視することで、パフォーマンスがさらに低下する前に、モデルの再訓練やデータの更新を促すことができます。
実務における意思決定の自動化と支援
不確実性の推定値は、予測の解釈を助け、実務における自動化を促進します。
閾値の設定による自動化
精度-拒否曲線(Accuracy-rejection curves)を使用することで、組織が目標とする予測精度(例:97%)を達成するために必要な不確実性の閾値を設定できます。この閾値より不確実性の低い予測のみを保持し、その他の予測を拒否することで、自動化された処理システムの信頼性を保証できます。
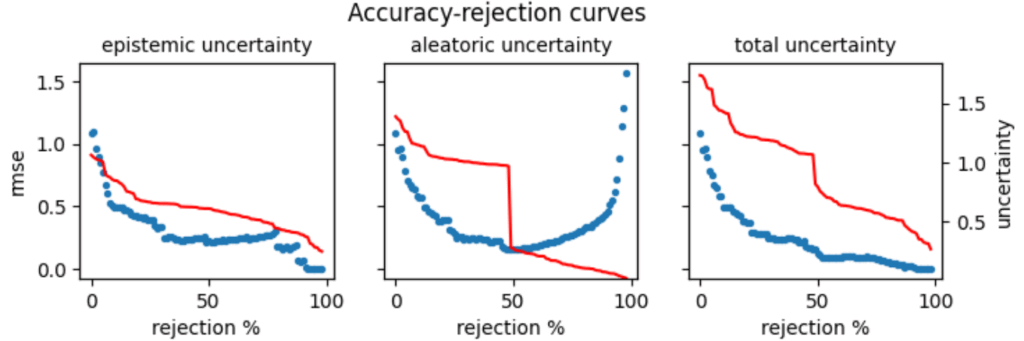
ヒューマン・イン・ザ・ループの実現
不確実性の認識は、ヒューマン・イン・ザ・ループの設計を可能にします。不確実性の閾値を超える予測、すなわち信頼度が低いケースは、自動処理から除外され、人間の専門家にルーティングされます。これらの曖昧で複雑なケースは、人間の判断により適しているため、人間はより価値の高いタスクに集中でき、システム全体の自動化の恩恵を最大限に享受できます。これはデュアルトラックシステムの設計を可能にします。
早期導入の促進
認識論的不確実性がデータ不足に起因することから、組織はデータが十分に集まるまで予測システムの導入を見送りがちです。しかし、適切な不確実性の閾値を設定することで、初期のデータセットが不足していても、信頼できる少数の予測からシステムの運用を開始できます。データの収集が進むにつれて、閾値以下の予測の割合が増加し、システムの許容範囲が拡大していくため、迅速なイノベーションと継続的な学習をサポートします。
おわりに
本記事を通じて、機械学習モデルの予測における「不確実性(Uncertainty)」が、単なる学術的な関心事ではなく、現代のAI駆動型システムを構築し運用する上での実用的な要件であることが理解できたかと思います。モデル予測に付随する不確実性を定量化し、自信がない場合に予測を拒否するオプションを持つことは、ビジネスにおける機械学習モデルの導入と、よりよい情報に基づいた意思決定を可能にするために不可欠です。
偶然的不確実性(Aleatoric Uncertainty)と認識論的不確実性(Epistemic Uncertainty)という2つの不確実性の概念は、エンジニアリング上の意思決定を改善するための明確なフレームワークを提供します。偶然的不確実性が高ければデータの品質や特徴量の欠落、認識論的不確実性が高ければデータの不足 と、それぞれ適切な改善策を導き出すことができます。
さらに、不確実性を定量化する具体的な手法も見てきました。アンサンブル学習におけるエントロピーを用いた不確実性の分解 や、ニューラルネットワークにおけるドロップアウト(Dropout)を推論時に有効にする近似ベイズ的手法 は、モデルの予測をより透明で、信頼性の高いものにします。
そして、コンフォーマル予測(Conformal Prediction: CF)は、特定のモデルやデータ分布に依存せず、統計的に有効な予測セットや区間を生成する強力なフレームワークです。これにより、組織が要求する目標精度を満たす不確実性の閾値を設定し、低信頼度ケースを人間の専門家(ヒューマンエキスパート)に委ねるヒューマン・イン・ザ・ループのシステム設計 が可能になります。
不確実性への適切な対応は、AIをビジネスの現場でより広く、安全に、そして効果的に活用するための鍵となります。不確実性の定量化は、予測モデルの早期導入を促進し、継続的な学習と改善をサポートする羅針盤となります。
More Information
- arXiv:2510.06007, Hans Weytjens, Wouter Verbeke, 「Uncertainty in Machine Learning」, https://arxiv.org/abs/2510.06007
関連記事

組込みシステムと量子化ニューラルネットワーク
深層ニューラルネットワーク(DNN)は、画像分類、音声認識、物体検出といった分野で優れた性能を発揮しますが、その実現には膨大な計算資源とメモリを要求します。一方で、モノのインターネット(IoT)の急速な普及に伴い、マイク […]

The Dead Salmons: 統計的・因果的推論によるAI解釈性の再構築
2009年、神経科学の世界に衝撃的な報告がなされました。MRI装置の中に入れられた「死んだ鮭」が、人間の写真に対して感情反応を示す脳活動を見せたのです。もちろん、鮭に意識があったわけではありません。これは多重比較の補正を […]

Data-centric AI: データ中心のAIとは何か?
近年のAI(人工知能)の発展は目覚ましく、我々の生活や社会のあらゆる領域に大きな影響を与えています。その躍進を支える重要な要素の一つが、機械学習モデル構築のための豊富で高品質なデータです。 これまでのAI開発では、アルゴ […]