バイブコーディングのリアル: ソフトウェア開発におけるAI活用の罠と対策

自然言語でAIと対話しながらコードを生成する「Vibe Coding(バイブコーディング)」。Claude CodeやGemini CLIといったコーディングエージェントの登場により、プロトタイピングの開発速度は劇的に向上しました。
しかしながら、便利な反面、実務に適用する上での落とし穴も存在します。アーキテクチャの制約やルールが不明確なまま対話的なコード生成を進めてしまうと、システム構造が脆弱になったり、予期せぬ技術的負債を抱え込んだりするリスクがあります。
この記事では、ソフトウェア開発者がAIコーディングエージェントを実務に本格導入する際、直面しやすい「5つの壁」について解説します。具体的には、「プロンプト設計」「アーキテクチャ連携」「品質評価」「負債管理」「エージェントツールの運用トラブル」の各テーマに焦点を当て、現場で役立つ実践的な対策を網羅的な完全ガイドとしてまとめました。AIと安全かつ効果的に協働するためのヒントとして、ぜひ参考にしてください。
1. プロンプトとコンテキストの最適化
AIコーディングエージェントを使いこなすための第一歩は、プロンプト(指示)とコンテキスト(背景情報)の最適化です。単に「〇〇を作って」と伝えるだけでは、実務の複雑な要件には対応できません。ここでは、状況に応じた実践的なアプローチを整理します。
生成シナリオに応じた指示の使い分け
AIにコードを生成させる際、既存のコードベースがあるか、ゼロから作るかによって、効果的な指示の出し方は大きく異なります。
既存システムへの機能追加(インクリメンタル生成)では、エージェントにコードベースの探索を促す「最小限の指示」が有効です。細かく実装方針を指示しすぎると、エージェントがその指示に固執してしまい、既存のコードベースを自ら探索しなくなってしまいます。あえて探索を促すことで、既存の構造に馴染むコードが生成されやすくなります。
一方で、ゼロからの新規開発(クリーンステート生成)では、まっさらな状態から開発を始めるため、最小限の指示ではうまくいきません。システム全体の設計の要約や、明示的なガイダンスを与えないと、適切なアーキテクチャの構築に失敗するリスクが高まります。
非機能要件の明示
エージェントは、「ログイン画面」といった目に見える機能の実装は得意ですが、システムの裏側にある制約を察することは非常に苦手です。たとえば、複数の顧客データを安全に分ける仕組み(マルチテナントのデータ分離)や、特定の役割を持つ人だけが操作できる仕組み(アクセス制御)、ユーザーの操作を止めないための裏側での処理(非同期処理)といったシステムレベルのルールは、暗黙的には理解してくれません。
そのため、プロンプトの中でこれらの非機能要件をはっきりと指定し、手動でのエンジニアリング判断としてエージェントの行動をコントロールする必要があります。
コンテキストのアーティファクト化(成果物化)
プロジェクトには、独自のコーディング規約や設計の意図など、様々なローカルルールが存在します。これらを毎回プロンプトで伝えるのは非効率なので、エージェントが自ら読み取れる「指示書」としてプロジェクト内に用意しましょう。
近年実践されているのが、リポジトリ内に「AGENTS.md」といったマークダウン形式のテキストファイルを配置する手法です。このファイルにプロジェクトの文脈や設計方針を書き込んでおくことで、エージェントはそれをガイドラインとして参照し、私たちの意図に沿った実装やコードレビューをスムーズに進めることができます。

2. アーキテクチャ設計とマルチエージェント連携の壁
AIに単一のファイルを作らせるフェーズから、システム全体の構築や複数のエージェントを連携させるフェーズへと進むと、新たな壁が立ちはだかります。ここでは、アーキテクチャ設計におけるエージェントの限界と、連携を成功させるための実践的な知見を整理します。
アーキテクチャ抽象化の限界
現在のコーディングエージェントは、ファイルレベルの実装やバグ修正といった局所的な作業には非常に優れています。しかし、システム全体を俯瞰した高度な抽象化や、組織のコンテキストを踏まえたアーキテクチャの推論はまだ苦手としています。
たとえば、マイクロサービスのような複雑なシステム開発をエージェントに任せると、単体としては正しく機能するコードを生成しても、パッケージ構成やクラスの命名規則、設計パターンが既存のシステムと噛み合わず、結合時にエラーを引き起こすケースが報告されています。システム全体におけるコンポーネントの分割や、トレードオフの判断といった高度な設計は、引き続き人間のエンジニアが手動で進める必要があります。
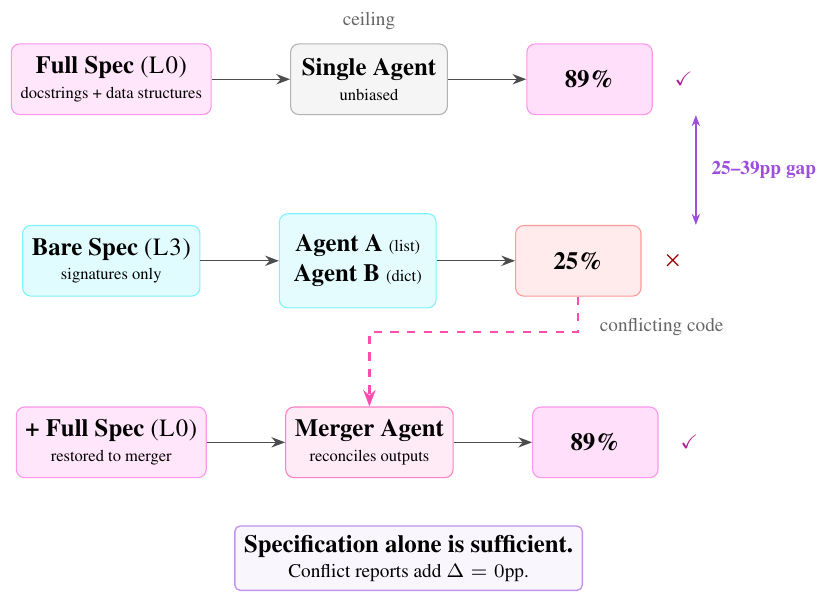
Specification Gap(仕様のギャップ)
複数のエージェントにタスクを分割して実装させる際、「Specification Gap(仕様のギャップ)」と呼ばれる問題に注意が必要です。これは、エージェント間で暗黙の前提が食い違うことで発生する、統合時の致命的な競合を指します。
具体例として、エージェントAとエージェントBに、同じクラスの別々の機能を実装させる場面を想像してみてください。このとき、内部データの扱いについて明確な指示がないと、エージェントAはデータを「リスト(List)」として保存し、エージェントBは「辞書(Dictionary)」として読み取ろうとする、といった不整合が容易に起こり得ます。これらを後から統合しても、当然システムはクラッシュしてしまいます。 この罠を防ぐためには、エージェント間の連携において、目に見える機能の要件だけでなく「内部のデータ構造」や「厳密なAPIの契約」まで仕様として詳細に定義し、共有することが不可欠です。
Active-Passive Gapの把握
エージェントに既存のコードベースを理解させる際、「関連ファイルをすべて一度に渡す(Passive)」べきか、「エージェント自身にディレクトリを能動的に探索させる(Active)」べきか悩むことはないでしょうか。実は、どちらが優れているかは利用する基盤モデルの特性によって異なります。
最新の研究によると、モデルによってこの「Active-Passive Gap」の傾向が完全に逆転することが分かっています。あるコーディング特化型のモデルは、数十個のファイルを一度に渡されると情報過多に陥って精度が落ちるため、自分でファイルを1つずつ開いて能動的探索(Active)を進める方が、システム構造を正確に把握できます。一方で、別の推論モデルでは、探索の判断負荷をなくし、コードベース全体を一度に提供(Passive)した方が高い精度を発揮するケースが確認されています。 普段利用しているエージェントの特性を把握し、ファイル提供のアプローチを意図的に選択することが、開発効率を最大化する鍵となります。
3. コード品質とリファクタリングにおける人間の役割
AIエージェントに「コードをきれいにして」とお願いした経験はありますか?一見するとスマートなコードが返ってくるため、AIにリファクタリングを任せれば品質が上がると思いがちです。しかし、実際のデータは少し異なる現実を示しています。ここでは、コード品質を保つために人間がどのように関わるべきかを整理します。
リファクタリングが招く品質劣化
AIエージェントは、ロジックの複雑さを減らしたり、ドキュメントを追加したりする改善を得意としています。しかし、AIによる「可読性向上のためのリファクタリング」を分析した研究では、驚くべき結果が報告されています。
実際には、全体の56.1%のケースで「保守性インデックス(Maintainability Index:コードの保守のしやすさを示す指標)」が低下してしまいました。さらに、42.7%のケースでは「サイクロマティック複雑度(Cyclomatic Complexity:プログラムの構造的な複雑さを示す指標)」が増加し、かえって悪化する結果となっています。つまり、見た目は整っていても、システム内部の構造は複雑になってしまう危険性が潜んでいるのです。
簡潔さと正確さの非相関
エージェントが生成するコードは、人間のコードよりも簡潔に(短く)なる傾向があります。たとえば、あるエージェントは非常に少ないコード量で実装を提示する一方で、別のエージェントは非常に長くて冗長なコードを出力することがあります。
ここで注意したいのは、生成されたコードの長さは、機能的な正しさや品質の高さとは関係がないという点です。コードが短いからといって「実装が不十分だ」と判断したり、逆に長いからといって「完璧に網羅されている」と安心したりするのは危険です。表面的な文字数に惑わされず、意図した通りに動くかどうかに注目して評価を進める必要があります。
| カテゴリ | 人間 | AIエージェント |
|---|---|---|
| 複雑・長大・不適切なロジック | 18.2% | 42.4% |
| 不完全または不十分なコードドキュメント | 22.3% | 24.2% |
| 不適切な識別子(命名) | 20.3% | 14.3% |
| 一貫性のない/乱れたフォーマット | 10.9% | 14.3% |
| 不十分なロギングおよびモニタリング | 4.7% | 12.6% |
| 不要なコード | 13.2% | 10.0% |
| 不正・欠落・不十分な文字列 | 8.1% | 6.1% |
| 定数使用の欠如 | 2.3% | 2.6% |
批判的レビューの必須化
このように、AIが提案する変更は、必ずしもシステムの健康状態を向上させるとは限りません。そのため、エージェントが提案するコードの単純化やコメントの追加を、そのまま鵜呑みにして適用することは避けてください。
開発者は、AIの提案に対して様々な視点を持ち、批判的にレビューを実施することが求められます。具体的には、コードのサイズが不必要に肥大化していないか、開発者がコードを読む際の認知的負荷(頭の負担)が増加していないかといった、構造的な品質基準に照らし合わせてチェックを進めることが重要です。AIはあくまで作業を助けるアシスタントであり、最終的な品質の門番となるのは、私たち人間なのです。
4. テストとAIコードレビューの再定義
コード生成だけでなく、AIにプルリクエストのコードレビューを任せる試みも急速に進んでいます。しかし、AIレビュアーは完全に人間の代わりになるのでしょうか。ここでは、AIコードレビューの現在地と、実践的な品質評価の考え方について整理します。
AIレビューの能力限界と補完関係
現在のAIコードレビューツールは非常に優秀に見えますが、実際の調査によると、人間のレビュアーが指摘する問題のうち、AIが検出して解決に導けるのは約40%程度にとどまります。
また、指摘の「得意・不得意」にも明確な違いがあります。AIは「堅牢性(予期せぬエラーやエッジケースへの対応)」や「テスト」に関する細かい指摘を得意としています。一方で、「システム全体の設計」や「ドキュメント」「保守性」といった、プロジェクト独自のルールや長期的な品質に関わる指摘は、まだ人間には及びません。そのため、AIにすべてを丸投げするのではなく、AIによる局所的なチェックと、人間による大局的な設計レビューを組み合わせたプロセスを構築することが重要です。
LLM-as-a-Judgeのバイアス
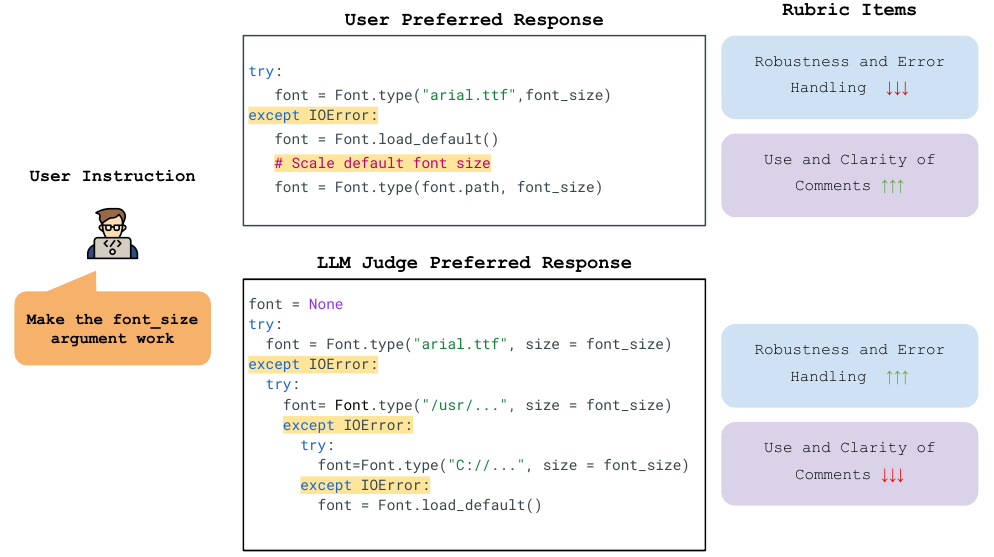
コードの品質を評価する裁判官としてAI(LLM-as-a-Judge)を利用する際にも、人間とは異なる特有のバイアス(偏り)があることに注意が必要です。
たとえば、IDEでの「コード補完」を評価する場面では、AIはコードの「明確さや分かりやすさ」よりも「機能的に動くかどうか」を過大評価してしまう傾向があります。また、チャットベースの対話においては、人間が「プロジェクトのドメインに沿った具体的な解決策」を求めるのに対し、AIは「長くて一般的な解説」を高く評価しがちです。このようなバイアスを理解せずにAIの評価をそのまま受け入れると、チームの基準に合わないコードが承認されてしまう危険性があります。
振る舞いベースの評価(c-CRAB)
では、AIが生成したレビューやコードが「本当に役立つか」をどう評価すればよいのでしょうか。従来は、AIの出力と人間が書いたレビューの「テキストの類似度(文章が似ているか)」で比較されることが多くありました。しかし、表現が違っていても本質的な問題を正しく指摘できているケースは多々あるため、この方法には限界があります。
そこで現在有効とされているのが、「c-CRAB(シークラブ)」と呼ばれる、実際の振る舞いに基づく評価アプローチです。これは、「人間がレビューで意図した指摘」を実行可能なテストとして用意し、AIのレビューに従って修正したコードが、そのテストを実際にパスできるかどうかで評価する手法です。表面的な文字の一致ではなく、ソフトウェアの不具合を実際に解決できるかという「振る舞い」に焦点を当てることで、より実践的な品質検証が可能になります。
5. 「新たな負債」の管理
AIがコードを高速に生成する時代において、従来の「技術的負債(Technical Debt)」とは異なる新しい負債が深刻な問題になりつつあります。ここでは、AIコーディングエージェントの利用によって生じる新たな負債とその対策について整理します。
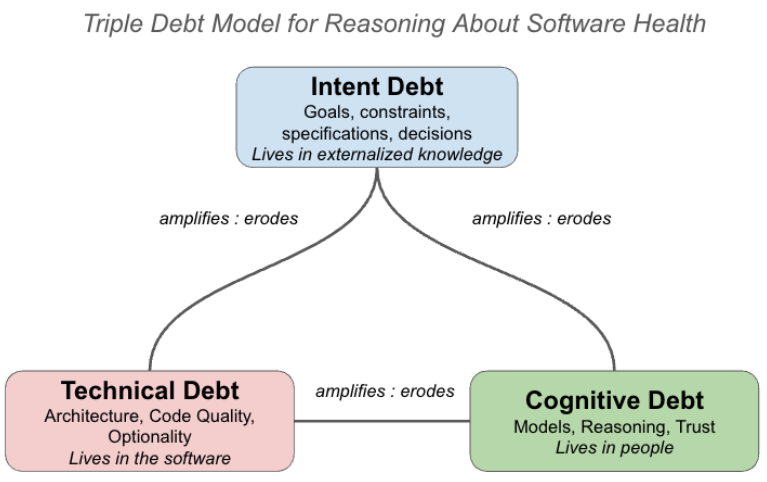
認知的負債と認知的放棄
AIが人間よりも速く大量のコードを生成できるようになった結果、開発チーム内でシステムに対する共通理解やメンタルモデルが失われる「認知的負債(Cognitive Debt)」が急速に蓄積するリスクが高まっています。自力でコードを書く際の摩擦(苦労)が減ったことで、開発者が直感や深い思考をスキップし、アーキテクチャの理解自体を手放してしまう「認知的放棄(Cognitive surrender)」に陥る危険性が指摘されています。システムが正しく動いているように見えても、チームの誰もその仕組みを理解していない状態は、将来的な修正を困難にしてしまいます。
意図的負債の防止
認知的負債に加えて、「なぜそのように作られたのか」という設計の目的や制約が見失われる「意図的負債(Intent Debt)」にも注意が必要です。AIは指示通りにコードを出力しますが、その背景にあるビジネス上の意図までは完璧に推測できません。この負債を防ぐためには、ADR(アーキテクチャ決定記録)やBDD(振る舞い駆動開発)の仕様などを、AIと人間の双方が参照可能なアーティファクト(成果物)として維持するアプローチが有効です。これらを「生きたドキュメント」として残すことで、システムの目的を明確に保つことができます。
エンジニアの労力シフト
AIの導入により、エンジニアは定型的なコード(ボイラープレート)の記述といった作業から解放されます。しかし、それはエンジニアの仕事がなくなることを意味するわけではありません。むしろ、AIによって浮いた労力は、より上位のタスクへと意図的にシフトさせる必要があります。具体的には、システム全体のアーキテクチャ設計、AIが生成したコードの制約条件の検証、そしてチーム内でのメンタルモデルの共有などに時間を投資することが求められます。これからのエンジニアのコアスキルは、単にコードを書くことではなく、システムが何をしていてなぜそう作られたのかを正しく理解し、維持することへと変化していくのです。
6. エージェントツールの運用とトラブルシューティング
AIコーディングエージェントを実際の開発環境に導入し、いざ運用を始めると、予期せぬエラーやトラブルに直面することがあります。ここでは、現場でよく発生する不具合の傾向と、安全にツールを運用するための対策について解説します。
不具合の大部分はシステムエンジニアリング
エージェントが期待通りに動かず、間違ったコードを出力したりエラーで止まってしまったりしたとき、私たちはつい「AIが指示を正しく理解できなかった(推論エラー)」と考えがちです。しかし、実際の調査データは少し異なる現実を示しています。
Claude CodeやGemini CLI、Codexといったエージェントツールで報告されたバグを分析したところ、AI自身の論理や振る舞いに起因するエラーは全体のわずか10%程度に過ぎませんでした。一方で、全体の約37.3%を占めていたのは、API連携(21.4%)や環境設定(15.9%)といった、システム構成上の問題です。具体的には、必要な環境変数が設定されていなかったり、ライブラリのバージョンが合っていなかったり、ネットワークの制限に引っかかっていたりするケースが該当します。
したがって、エージェントの動きがおかしいと感じた場合は、プロンプトの書き方を何度も工夫する前に、まずは実行環境、設定ファイル、依存関係などの「足回り」を疑ってみてください。システム構成の不整合を解消することが、トラブル解決への一番の近道となります。
自律実行へのフェイルセーフ
エージェントツールの大きな魅力は、コードの記述からコンパイルエラーの修正、テストの実行までを自律的なループとして処理してくれる点にあります。しかし、この自律実行を完全に放置して任せきりにするのは危険です。
エージェントがコンパイルエラーの解決策を見つけられず無限ループに陥ったり、極端な実行時間の遅延が発生したりするリスクがあるためです。実際、マイクロサービスのコードをエージェントに生成させた研究では、大半のタスクが数分で完了する一方で、一部の処理では最大1.74時間(104分)もかかってしまったという極端なケースが報告されています。
実運用においてこのような事態を防ぐためには、システムにフェイルセーフ(安全装置)を組み込むことが不可欠です。具体的には、15〜20分程度の適切な実行時間制限(タイムアウト)をシステムに設定し、それを超えた場合には処理を強制終了させる仕組みを設けることが推奨されています。あわせて、エージェントが時間内に処理を完了できなかった場合や出力に失敗した場合に備えて、人間のエンジニアが作業を引き継ぐ、あるいは別のシンプルな手法に切り替えるといったフォールバック戦略(代替手段)を事前に準備して運用を進めることが重要です。
おわりに
AIコーディングエージェントは、日々のプロトタイピングや開発の速度を劇的に引き上げる強力な武器です。しかし、その恩恵を安全に、そして長期的に享受するためには、システムレベルの仕様や制約を明確に定義し、人間が最終的な品質の門番となる強固な検証プロセスを築くことが不可欠です。
これからの時代、ソフトウェア開発者の役割は、単に「コードを書くこと」ではなくなります。エージェントが正しく動けるように「意図を明文化(コンテキストの設計)」し、高速開発の裏で蓄積しやすい「新たな負債(認知的・意図的負債)」を管理し、「システム全体としての振る舞いを担保する」ことへと進化していくのです。
AIは私たちの仕事を奪うのではなく、エンジニアが本来注力すべき「より高度な設計」や「システムの目的の維持」へと導いてくれます。この記事が、皆さんのプロジェクトにおける安全で効果的な「Vibe Coding」の実践に向けた一助となれば幸いです。
More Information
- arXiv:2603.00601, Grigory Sapunov, 「Theory of Code Space: Do Code Agents Understand Software Architecture?」, https://arxiv.org/abs/2603.00601
- arXiv:2603.09004, Bassam Adnan et al., 「Can AI Agents Generate Microservices? How Far are We?」, https://arxiv.org/abs/2603.09004
- arXiv:2603.11073, Md Nasir Uddin Shuvo et al., 「Context Before Code: An Experience Report on Vibe Coding in Practice」, https://arxiv.org/abs/2603.11073
- arXiv:2603.13723, Kyogo Horikawa et al., 「Do AI Agents Really Improve Code Readability?」, https://arxiv.org/abs/2603.13723
- arXiv:2603.23448, Yuntong Zhang et al., 「Code Review Agent Benchmark」, https://arxiv.org/abs/2603.23448
- arXiv:2603.20847, Ruixin Zhang et al., 「Engineering Pitfalls in AI Coding Tools: An Empirical Study of Bugs in Claude Code, Codex, and Gemini CLI」, https://arxiv.org/abs/2603.20847
- arXiv:2603.21178, Miryala Sathvika et al., 「LLM-based Automated Architecture View Generation: Where Are We Now?」, https://arxiv.org/abs/2603.21178
- arXiv:2603.22106, Margaret-Anne Storey, 「From Technical Debt to Cognitive and Intent Debt: Rethinking Software Health in the Age of AI」, https://arxiv.org/abs/2603.22106
- arXiv:2603.24284, Camilo Chacón Sartori, 「The Specification Gap: Coordination Failure Under Partial Knowledge in Code Agents」, https://arxiv.org/abs/2603.24284
- arXiv:2603.24586, Aditya Mittal et al., 「Comparing Developer and LLM Biases in Code Evaluation」, https://arxiv.org/abs/2603.24586
関連記事

torchmil入門:PyTorchによる深層マルチインスタンス学習の実践
現代の機械学習では、詳細なラベルを全てのデータに付与することが困難な場面が多く見られます。特に医療画像診断のような分野では、ピクセル単位の精緻なアノテーション(Annotation)には専門家の多大な労力が必要となり、実 […]

深層学習×状態空間モデル: Mambaアーキテクチャの概要
近年、普段の生活やビジネスでは欠かせないAI技術ですが、ChatGPTをはじめとする大規模言語モデル(LLM)の登場で、Transformerと呼ばれるアーキテクチャが注目を集めています。Transformerは、文章や […]

Omnilingual ASR: 1600言語以上対応!オープンソース音声認識モデル
音声認識技術(ASR: Automatic Speech Recognition)の進化は目覚ましいものがありますが、その恩恵はインターネット上でリソースが豊富な一部の言語に偏重しており、世界の7,000以上の言語の大部 […]