Omnilingual ASR: 1600言語以上対応!オープンソース音声認識モデル

音声認識技術(ASR: Automatic Speech Recognition)の進化は目覚ましいものがありますが、その恩恵はインターネット上でリソースが豊富な一部の言語に偏重しており、世界の7,000以上の言語の大部分は未サポートという課題を抱えています。特に「ロングテール」と呼ばれる低リソース言語のコミュニティは、データの不足により技術的な恩恵から疎外されがちです。
この課題を克服し、言語のデジタルデバイドを解消するために、MetaのFundamental AI Research (FAIR) チームはオープンソースの多言語音声認識システム、Omnilingual ASRを発表しました。
Omnilingual ASRは、1,600以上の言語をサポートしており、これまでにASR技術でカバーされたことのない500以上の低リソース言語を含んでいる点が画期的です。このシステムは「広範なアクセシビリティ」のために設計されており、専門的な知識や大規模なデータセットを必要とせず、ごくわずかな音声とテキストのペア(インコンテキストなサンプル)を用いるだけで、新しい言語を追加できるゼロショット拡張性を備えています。
この記事では、この圧倒的なスケールと様々な言語への拡張性を実現した技術的基盤と、それが今後の機械学習システムにどのような影響をもたらすのかを、具体的な情報に基づいて解説していきます。
1,600言語超を実現した技術基盤
Omnilingual ASRの圧倒的な対応言語数と性能を支えるのは、「大規模化」と「アーキテクチャの革新」を組み合わせた技術基盤です。
大規模クロスリンガル音声エンコーダの役割
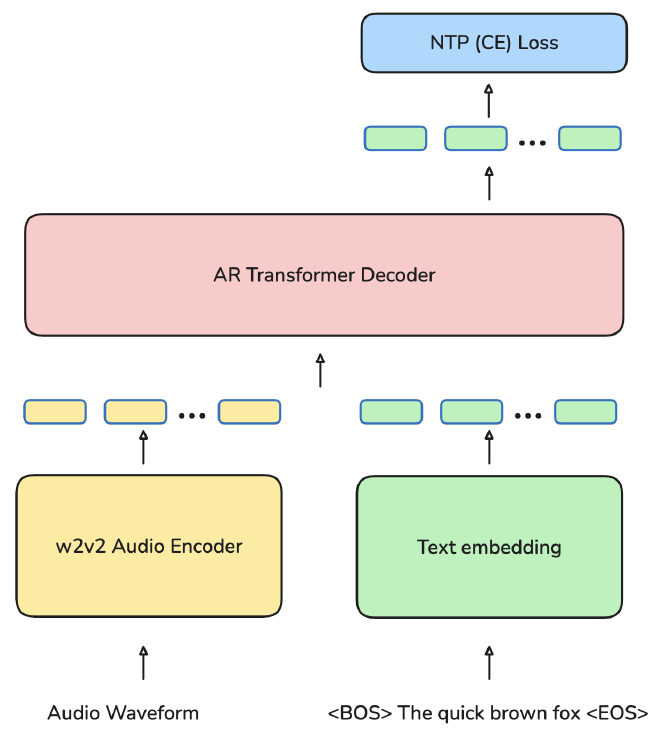
Omnilingual ASRの中核を担うのは、入力された音声から、言語横断的に利用可能な強力な表現を抽出するスピーチエンコーダです。Meta AI Research (FAIR) チームは、このエンコーダの基盤として、自己教師あり学習(SSL: Self-Supervised Learning)の代表的なモデルであるwav2vec 2.0を採用し、その容量を大幅にスケールアップしました。
具体的には、モデル容量をこれまでの最大規模となる70億(7B)パラメーターにまで拡張しています。この巨大なエンコーダは、その事前学習のスケールが画期的です。1,600以上の様々な言語をカバーする、合計430万時間もの膨大な量のラベルなし音声データを用いてSSLによって事前学習されました。この学習規模により、エンコーダは、特定の言語に偏らず、高レベルでロバストな音声表現を抽出する能力を獲得しました。
LLMに着想を得たデコーダ:LLM-ASR
エンコーダから得られた表現をテキストに変換するデコーダ部分には、2種類の手法が用意されています。
1つは、高速な処理に適した従来のCTC (Connectionist Temporal Classification) に基づくデコーダです。そしてもう1つが、大規模言語モデル(LLM) で一般的に用いられるTransformerデコーダを組み込んだ「LLM-ASR」と呼ばれアプローチです。
このLLM-ASR、特に7B-LLM-ASRシステムは、性能面で大きな優位性を示しています。1,600以上の言語全体で最先端の性能を達成し、特にデータが極端に少ないロングテール言語(低リソース言語)の認識精度において、画期的な「ステップチェンジ」をもたらすと評価されています。全体として、評価対象言語の78%で、文字誤り率(CER: Character Error Rate)が10未満という高い精度を実現しました。
このアーキテクチャの選択が、以下で詳しく述べる「ゼロショット拡張性」の鍵を握っています。LLM-ASRが、LLMに見られるインコンテキスト学習能力をASRにもたらすことで、限られたデータしかない言語にも対応可能となったのです。
ゼロショット拡張性と応用
Omnilingual ASRの真に画期的な点は、対応言語の数だけにとどまりません。それは、新しい言語を追加するためのパラダイムシフトを実現した点にあります。
ゼロショットによる新しい言語への対応
多くの既存のASRシステムでは、リリース時に含まれない言語をサポートするために、専門家主導による大規模なファインチューニングが必須でした。これは、データの収集や高度な計算資源、専門知識を必要とするため、ほとんどの話者コミュニティにとって実現不可能な道筋でした。
これに対し、Omnilingual ASRは、**LLM(大規模言語モデル)にヒントを得たインコンテキスト学習(In-Context Learning)の能力をASRにもたらしました。この機能により、推論時にわずかな音声とテキストのペア(インコンテキストな例)**を提供するだけで、トレーニングデータに一度も登場していない言語であっても、実用的な転写品質を得ることが可能になります。
ゼロショット性能は、完全に訓練されたシステムにはまだ及びませんが、この機能は、大規模な訓練データや、手の届かない専門知識、高度な計算リソースへのアクセスを必要とせずに、話者コミュニティが自らの言語をデジタル利用可能にするスケーラブルな道筋を提供します。ASRのカバレッジを静的な在庫リストから、コミュニティ主導で拡張可能なオープンエンドなフレームワークへと変えることを目指しています。
その他の柔軟な応用
音声-テキスト翻訳(S2TT)への応用
Omnilingual ASRのLLM-ASRバリアントは、音声認識の枠を超え、**音声-テキスト翻訳(S2TT: Speech-to-Text Translation)**タスクにも柔軟に適用できる点が注目されています。
必要な修正は最小限です。ソース言語とターゲット言語のIDトークンをインプットシーケンスに挿入するだけで、S2TTモデルとして機能します。このアプローチにより、既存の最先端システムであるWhisperを大きく上回り、S2TTのために設計されたSeamlessM4Tにも匹敵する、あるいはそれを上回る強力な性能を発揮しています。
デプロイの柔軟性
本システムは、特定のユースケースやインフラストラクチャの制約に対応できるよう、単一のモデルではなく、様々なサイズのモデルスイートとしてリリースされています。
提供されるモデルは、低電力デバイス向けに設計された軽量な300Mバージョンから、最高精度を提供するための強力な7Bモデルまで含まれており、クラウドインフラストラクチャから現場の低電力デバイスまで、多様な環境でのデプロイメントが可能です。これにより、研究者が追求できる研究課題の幅だけでなく、ASRを適用できるコンテキストも広がります。
実装ガイド
Omnilingual ASRは、オープンソースとして提供されており、導入は非常にシンプルです。ここでは、モデルの選択基準から、実際の推論実行、そして高度なカスタマイズ方法までを解説します。
モデルの選択とインストール
Omnilingual ASRは、性能と速度のトレードオフに応じて、様々なサイズのモデルスイートとして提供されています。まずは、自身のユースケースに最適なモデルを選択することが重要です。
| 特徴 | 最高精度重視(LLM-ASR) | 低遅延/低リソース重視(CTC) |
|---|---|---|
| モデル例 | 7B-LLM-ASR (omniASR_LLM_7B) | 300M-CTC (omniASR_CTC_300MASR) |
| 目標 | 最高精度の達成 | 低電力デバイスへのデプロイ |
| 推論速度 | 基準速度 | 非常に高速(7B-LLMの約16倍速い) |
最高精度の文字誤り率(CER: Character Error Rate)を追求し、モデルの持つ言語知識を最大限に活用したい場合は、7B-LLM-ASRモデルの利用が推奨されます。一方で、レイテンシ(遅延)が許容できないリアルタイムアプリケーションや、計算資源が限られた環境では、CTC(Connectionist Temporal Classification)に基づくモデルが理想的です。同じ7Bスケールで比較すると、7B-CTCモデルは7B-LLM-ASRモデルと比べて推論が約16倍高速であることが示されています。
| Model Name | Features | Parameters | Download Size (FP32) | Inference VRAM¹ | Real-Time Factor¹ (relative speed)² |
|---|---|---|---|---|---|
omniASR_W2V_300M | SSL | 317_390_592 | 1.2 GiB | ||
omniASR_W2V_1B | SSL | 965_514_752 | 3.6 GiB | ||
omniASR_W2V_3B | SSL | 3_064_124_672 | 12.0 GiB | ||
omniASR_W2V_7B | SSL | 6_488_487_168 | 25.0 GiB | ||
omniASR_CTC_300M | ASR | 325_494_996 | 1.3 GiB | ~2 GiB | 0.001 (96x) |
omniASR_CTC_1B | ASR | 975_065_300 | 3.7 GiB | ~3 GiB | 0.002 (48x) |
omniASR_CTC_3B | ASR | 3_080_423_636 | 12.0 GiB | ~8 GiB | 0.003 (32x) |
omniASR_CTC_7B | ASR | 6_504_786_132 | 25.0 GiB | ~15 GiB | 0.006 (16x) |
omniASR_LLM_300M | ASR with optional language conditioning | 1_627_603_584 | 6.1 GiB | ~5 GiB | 0.090 (~1x) |
omniASR_LLM_1B | ASR with optional language conditioning | 2_275_710_592 | 8.5 GiB | ~6 GiB | 0.091 (~1x) |
omniASR_LLM_3B | ASR with optional language conditioning | 4_376_679_040 | 17.0 GiB | ~10 GiB | 0.093 (~1x) |
omniASR_LLM_7B | ASR with optional language conditioning | 7_801_041_536 | 30.0 GiB | ~17 GiB | 0.092 (~1x) |
omniASR_LLM_7B_ZS | Zero-Shot ASR | 7_810_900_608 | 30.0 GiB | ~20 GiB | 0.194 (~0.5x) |
omniASR_tokenizer | Tokenizer for most of architectures (except omniASR_LLM_7B) | – | 100 KiB | – | |
omniASR_tokenizer_v7 | Tokenizer for omniASR_LLM_7B model | – | 100 KiB | – |
クイックスタート
Omnilingual ASRは、pipやuvといった標準的なパッケージマネージャーを通じてインストールが可能です。
# pip を使用したインストール pip install omnilingual-asr # uv を使用したインストール uv add omnilingual-asr
推論は、提供されているASRInferencePipelineクラスを利用して実行できます。推論時には、モデルカード名(例:"omniASR_LLM_7B")と、音声ファイル、そして対応する言語コードのリストを渡します。
言語コードは、{language_code}_{script}の形式(例: eng_Latn はラテン文字の英語)に従う必要があります。
from omnilingual_asr.models.inference.pipeline import ASRInferencePipeline # 7B-LLM-ASRモデルを指定 pipeline = ASRInferencePipeline(model_card="omniASR_LLM_7B") audio_files = ["/path/to/eng_audio1.flac", "/path/to/deu_audio2.wav"] lang = ["eng_Latn", "deu_Latn"] # 言語コードとスクリプトを指定 transcriptions = pipeline.transcribe(audio_files, lang=lang, batch_size=2)
(ただし、現時点では推論で受け付けられる音声ファイルは40秒未満に制限されています。無制限長の音声ファイルへの対応も計画されているので、今後のアップデートをお待ちください。)
高度なカスタマイズとファインチューニング
言語条件付けによる精度向上
LLM-ASRモデルを使用する場合、推論時に言語コードとスクリプトを明示的に提供する「言語条件付け」のメカニズムを活用することで、認識精度を大きく改善できます。特に、ウルドゥー語のように複数の表記(スクリプト)を持つ言語では、この条件付けによってモデルがスクリプトを誤認識する問題を防げるため、精度の大幅な向上に繋がります。これは、CTCモデルではスクリプトの誤認識が原因でエラーが発生しやすいという弱点に対する、LLM-ASRモデルの大きな優位点の一つです。
低リソース言語の性能最適化
Omnilingual ASRは、訓練済みチェックポイントを独自のデータセットでファインチューニングできるため、特定の言語に対して最大限の性能を引き出すことが可能です。
特に、10時間未満の訓練データしかない低リソース言語を対象とする場合、単一言語に特化してファインチューニングを行うことで、大規模な計算資源がなくても高い精度を実現できます。例えば、軽量な300Mスケールのモデルであっても、この単一言語ファインチューニングにより、Omnilingual ASRのベースライン(1,600言語全てで訓練されたモデル)を上回り、非常に低いCERを達成できます。このアプローチは、計算資源が限られた環境でのデプロイメントに役立つため、ローカルコミュニティ主導の言語支援に最適です。
ファインチューニングを行う際は、公開されているデータ準備ガイドやトレーニングレシピガイドが利用でき、プロセスを効率的に進めることができます。
評価とテストのためのリソース
大規模な多言語音声データセットであるOmnilingual ASR Corpusも、HuggingFace上でCC-BY-4.0ライセンスのもとオープンに公開されています。このデータセットには、ASRシステムがこれまでカバーしていなかった数百の言語の音声が含まれており、ご自身のモデルの評価やテストに直接利用することが可能です。
おわりに
Omnilingual ASRは、ASR(音声認識技術)のカバレッジに対するアプローチを根本から変える画期的なシステムです。これは、言語のカバー範囲を固定された静的な在庫リストとしてではなく、コミュニティ主導で拡張可能なオープンエンドなフレームワークとして再定義しました。
本システムの最大の貢献は、1,600以上の言語(これまでASRでカバーされたことのない500以上の低リソース言語を含む)をサポートしつつ、モデルとツールをオープンソース(Apache 2.0ライセンス)として提供した点にあります。これにより、大規模なデータや専門知識を必要とせず、わずかな例を用いて新しい言語を追加できる「ゼロショット拡張性」が、コミュニティ主導のイノベーションを可能にしました。
提供されるモデルスイートは、最高精度の強力な7Bモデルから低電力デバイス向けの軽量な300Mバージョンまで多岐にわたり、デジタルアクセスの改善や口頭アーカイブの検索可能化など、広範な社会的影響が期待されます。この技術は、今後のマルチモーダルAIや言語保存プロジェクトの基盤として、AI技術の構築と共有のあり方を再構築しようとしています。
More Information
- arXiv:2511.09690, Omnilingual ASR team, 「Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages」, https://arxiv.org/abs/2511.09690
関連記事
PyTorch Metric Learningではじめる深層距離学習
近年のAI技術の発展において、画像認識、自然言語処理、推薦システムなど、様々なタスクでデータ間の「類似性」を理解し、活用することが重要となっています。このような背景から、入力データを効果的な特徴空間にマッピングし、類似す […]

ハーネス・エンジニアリング: 次世代エージェントの設計指針
近年、LLMベースのエージェントは単なる受動的な質問応答から、自律的に環境を認識し、長期的なタスクを完遂するシステムへと移行しています。このような機能的要件を満たすため、現在のエージェントは「認知エンジン」である基盤モデ […]

Lightlyで実践 - 自己教師あり学習入門
近年、機械学習プロジェクトで扱うデータ量は増大し続けています。しかし、その膨大なデータすべてに手作業でアノテーション(教師ラベル付け)を行うのは、コストと時間の面で大きな課題です。この「アノテーションの壁」を乗り越える技 […]