Prompt Repetition: プロンプト反復によるLLMの改善

LLMの精度向上のために、日々プロンプトの試行錯誤を繰り返しているエンジニアは多いはずです。Google Researchの研究チームは、そのような課題に対し、非常にシンプルかつ強力な解決策である「Prompt Repetition(プロンプト反復)」を提案しました。
この手法の基本は、入力プロンプトを単に繰り返して「<QUERY><QUERY>」の形で入力することです。これだけで、GPT-4oやGemini 2.0、Claude 3.7 Sonnet、Deepseek V3といった様々な主要モデルにおいて、精度が改善することが実証されました。
最大の利点は、生成トークン数や遅延(Latency:レイテンシ)を増大させずに性能を底上げできる点にあります。これは、反復の処理が並列計算可能な「プリフィル(Prefill:推論前の読み込み)」段階で完結するためです。既存システムへも即座に導入(Drop-in)可能なこの手法について、その仕組みと活用法を詳しく解説します。
1. Prompt Repetitionの概要と基本的な仕組み
Prompt Repetitionとは、その名の通り、ユーザーが入力するプロンプト <QUERY> をそのまま複製し、<QUERY><QUERY> という形式でモデルに与える非常にシンプルな手法です。この単純な変更をプロンプトに加えるだけで、様々な主要モデルにおいて応答精度が向上することが実証されています。
なぜ性能が上がるのか
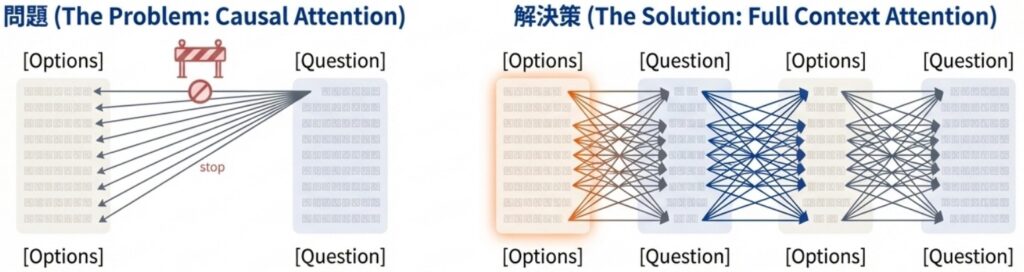
その理由は、現在のLLMの多くが「因果的言語モデル(Causal Language Model)」として設計されている点にあります。この設計では、あるトークンは自分より「過去」にあるトークンしか参照(アテンション:Attend)できず、未来のトークンを見ることはできません。
そのため、プロンプト内の情報の並び順(例:質問が先か、選択肢が先か)が性能に影響を及ぼすことが多々あります。しかし、プロンプトを2回繰り返すことで、各プロンプトトークンが、もう一方のプロンプトに含まれるすべてのトークンに対してアテンションを向けられる状態が作り出されます。これにより、情報の順序依存による性能のばらつきを抑え、モデルの理解を深めることが可能になります。
効率性と導入のメリット
この手法は、実務者にとって極めて実用的な効率性を備えています。
- 生成コストが不変: 生成される回答(生成トークン数)の長さは増えません。
- 遅延(レイテンシ)の最小化: プロンプトの反復処理は、並列計算が可能なプリフィル(Prefill:推論前の読み込み)段階で実施されます。そのため、生成時の遅延はほとんど増加しません。
- ドロップインな導入: 出力のフォーマット自体は変わらないため、既存のシステムにそのまま組み込める(Drop-in)解決策となります。
例えるなら、この手法は「難しい指示を2回読み返してから作業を始める」ようなものです。2回目を読むときには既に全体像が頭に入っているため、1回目よりも各情報のつながりを正しく把握して実行に移せる、というわけです。
2. 実証データに見る技術的な利点
Prompt Repetitionの有効性は、理論上の推測ではなく、最新の主要モデルを用いた厳密なテストによって裏付けられています。Google Researchは、Gemini 2.0、GPT-4o、Claude 3.7 Sonnet、DeepSeek V3といった様々な最新モデルを用いて、その効果が検証されています。
広範なモデルとタスクでの検証結果
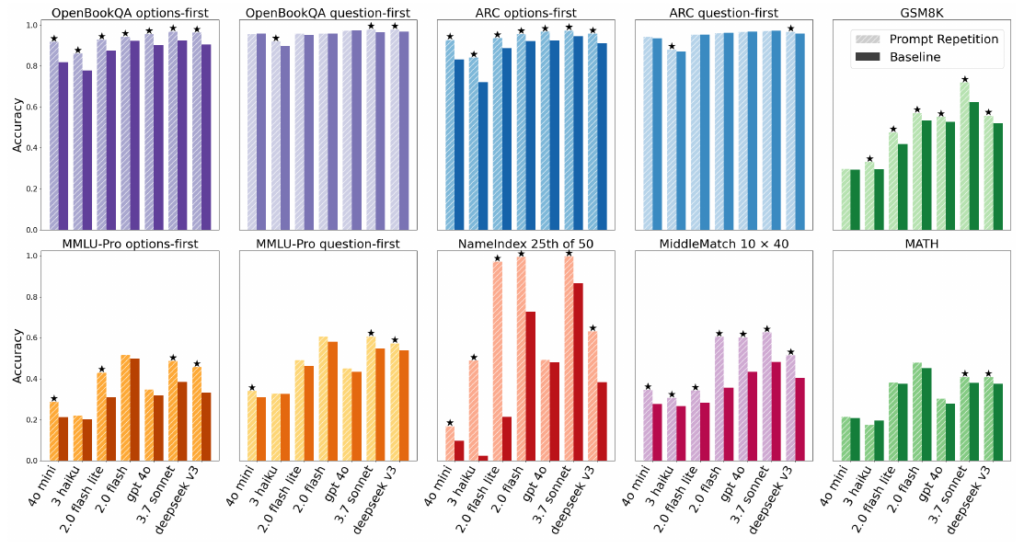
7つの主要モデルと7つのベンチマークを組み合わせた計70項目のテスト結果は、実務者にとって非常に示唆に富むものです。
- 圧倒的な勝率: 全テスト中、47のケースで統計的に有意な精度向上が確認され、性能が低下したケースはゼロでした。
- 非推論タスクでの強み: 「一歩ずつ考えて(Think step by step)」といった明示的な推論(Reasoning)指示を行わない設定において、特に顕著な改善が見られます。
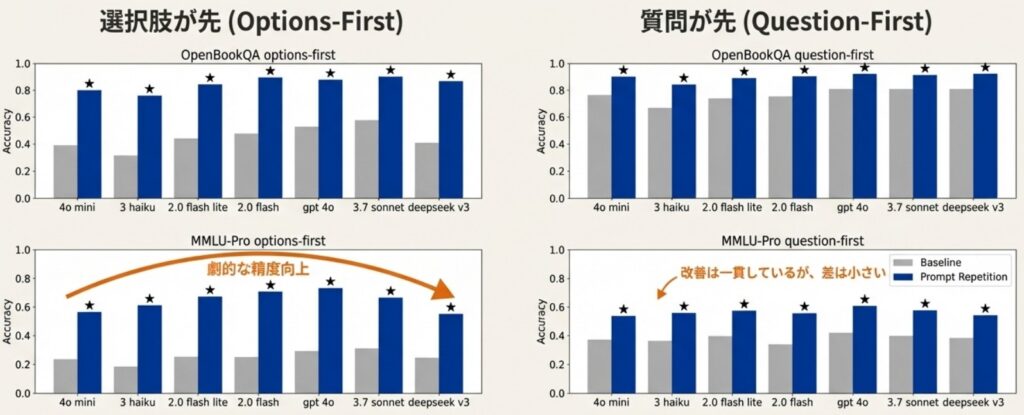
- 順序依存の解消: 質問より先に選択肢を提示する「Options-first」形式など、通常の入力順序ではモデルが苦手にしがちな構成で、より大きな効果を発揮します。
劇的な精度向上の事例
特定のタスクにおいては、プロンプトを反復するだけで驚異的な改善が見られます。たとえば、長いリストの中から特定の位置にある情報を抽出する「NameIndex」というタスクでは、Gemini 2.0 Flash-Liteの精度が21.33%から97.33%へと劇的に向上しました。
「単に長くすれば良い」わけではない
重要なのは、この性能向上が「入力トークンが増えたこと」そのものによる結果ではないという点です。研究チームは比較実験として、プロンプトを繰り返す代わりに、同じ長さになるようドット(.)で埋める「パディング(Padding)」を施したテストも実施しました。その結果、パディングでは精度向上が見られなかったため、「同じ情報を再度読み込ませる(反復する)」プロセス自体に価値があることが証明されています。
以上のように、Prompt Repetitionはコストを抑えつつ、確実に応答の質を底上げできる実用性の高い手法と言えます。
3. 推論(Reasoning)モデルとの関係
最新のLLM開発では、「Chain of Thought(CoT:思考の連鎖)」などの推論手法が一般的です。では、Prompt Repetitionはこれらの推論指示とどのような関係にあるのでしょうか。
推論指示との併用効果
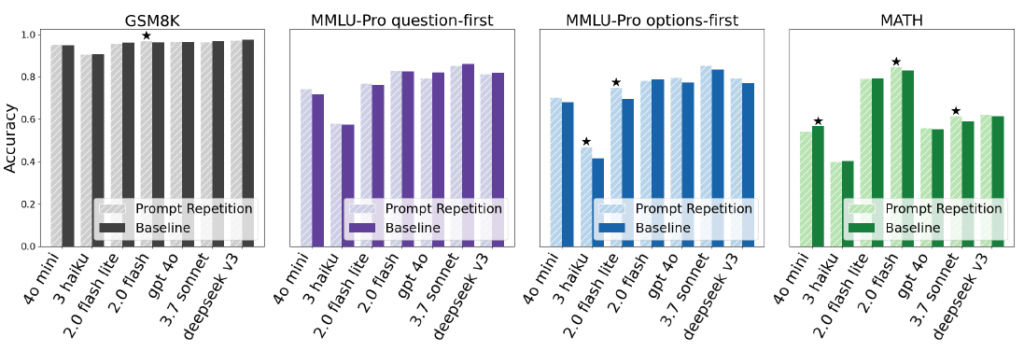
調査結果によると、モデルに明示的な推論(Reasoning)を行わせる場合、Prompt Repetitionによる精度向上は「中立(変化なし)からわずかにプラス」という結果に留まっています。具体的には、28件のテスト中、有意な改善が見られたのは5件で、22件は性能に変化がありませんでした。
この理由について、ソース資料では「推論モデルの挙動」が鍵であると指摘されています。強化学習(RL)で訓練された推論モデルは、自らの思考プロセスの中でユーザーのリクエストを部分的に繰り返す傾向があります。つまり、モデルが内部的に「反復」に近い処理を既に行っているため、事前に入力を繰り返すメリットが相対的に小さくなるのです。
実装における使い分けのヒント
実務者がこの手法を導入する際は、「効率性」と「タスクの性質」に基づいて判断するのが得策です。
- 推論指示(Step-by-step): 複雑な論理問題に強いですが、回答が長くなるため生成トークン数が増え、遅延(Latency:レイテンシ)と計算コストが大幅に増加します。
- Prompt Repetition: 生成トークンの長さや形式を変えません。反復処理は並列計算が可能なプリフィル(Prefill)段階で行われるため、コストや遅延を抑えつつ精度を底上げできます。
結論として、高度な論理推論を必要とせず、「直接的な回答」を求める様々なタスクにおいては、Prompt Repetitionをデフォルトの設定として採用するのが非常に効率的です。
たとえるなら、Prompt Repetitionは「作業前に一回、仕様書を読み直して内容を定着させる」ようなものです。一方で推論モデルは「作業の工程を一つずつ声に出しながら進める」ようなもので、後者は丁寧ですがその分だけ時間がかかります。
4. 実装のバリエーションと具体的なヒント
Prompt Repetitionには、単なる繰り返し以外にもいくつかのバリエーションが存在します。タスクの難易度やモデルの特性に合わせてこれらを使い分けることが、精度を最大化する鍵となります。
主な実装のバリエーション
研究チームは、単純な反復以外に以下の2つの効果的なパターンを提示しています。
- 単純反復(Simple Repetition):
<QUERY><QUERY>と、プロンプトをそのまま2回並べる最も基本的な形です。 - 丁寧な反復(Verbose Repetition): 「Let me repeat that:(もう一度繰り返します:)」といった接続語をプロンプトの間に挟むバリエーションです。タスクによっては、この形式が単純な反復を凌駕するパフォーマンスを示すことがあります。
- 3回反復(Prompt Repetition ×3): プロンプトを計3回繰り返す手法です。特に、大量の情報から特定の要素を探し出す「NameIndex」や「MiddleMatch」のような複雑な検索タスクにおいて、2回反復をさらに上回る劇的な精度向上が確認されています。
# Verbose形式のサンプル
Which of the following combinations is a mixture rather
than a compound?
A. oxygen and nitrogen in air
B. sodium and chlorine in salt
C. hydrogen and oxygen in water
D. nitrogen and hydrogen in ammonia
Reply with one letter (’A’, ’B’, ’C’, ’D’) in the format:
The answer is <ANSWER>.
Let me repeat that:
Which of the following combinations is a mixture rather
than a compound?
A. oxygen and nitrogen in air
B. sodium and chlorine in salt
C. hydrogen and oxygen in water
D. nitrogen and hydrogen in ammonia
Reply with one letter (’A’, ’B’, ’C’, ’D’) in the format:
The answer is <ANSWER>.実装時に意識すべき技術的注意点
様々なモデルにおいて「ドロップイン(Drop-in)」で導入できる本手法ですが、実用化にあたっては以下の点に留意してください。
- コンテキスト制限(Context Window): プロンプトを複製するため、消費する入力トークン数も2倍(または3倍)に増加します。極めて長い入力ドキュメントを扱う場合、モデルの最大コンテキスト制限に抵触する可能性があるため、入力サイズの管理が重要です。
- レイテンシ(Latency:遅延)の変化: 生成トークン数は変わらないため、多くの場合で遅延は増大しません。ただし、非常に長いプロンプトを反復させた場合、プリフィル(Prefill:推論前の読み込み)段階の処理時間が延びることがあります。実際にClaude 3 HaikuやSonnetでは、非常に長いリクエストにおいて遅延が増加する傾向が観測されています。
- 比較の基準: 精度向上が「単に入力長が増えたから」ではないことを確認するため、研究ではドット(.)で入力を埋める「パディング(Padding)」との比較も行われました。その結果、パディングでは改善が見られなかったことから、「同じ情報を再度読み込ませる」というプロセス自体が重要であることが分かっています。
まずは最もシンプルな2回反復から試し、検索性の高いタスクなどでは3回反復やVerbose形式を検討するのが、実務者にとって効率的なアプローチと言えるでしょう。
おわりに
Prompt Repetitionは、モデルの重みの更新や複雑なパイプラインの構築を必要とせず、プロンプトを繰り返すだけでLLMの性能を最適化できる「ドロップイン(Drop-in)」な解決策です。特に非推論タスクにおいて、生成トークン数や遅延(Latency:レイテンシ)を増大させずに精度を底上げできる点は、実務上のコストパフォーマンスにおいて大きな利点となります。
この手法は、GeminiやGPT、Claude、Deepseekといった様々な主要モデルでその有効性が実証されており、多くのタスクで「デフォルトの設定」として検討する価値があります。今後は、第2の反復のみをKVキャッシュに保持する効率化や、マルチターン対話への適用、画像などの非テキスト・モダリティへの拡張など、さらなる応用が期待されています。
More Information
- arXiv:2512.14982, Yaniv Leviathan, Matan Kalman, Yossi Matias, 「Prompt Repetition Improves Non-Reasoning LLMs」, https://arxiv.org/abs/2512.14982
関連記事

LLMエージェントの最前線 ~最新動向と今後の展望~
LLM(大規模言語モデル)エージェントは、人工知能研究の最前線に位置づけられ、目覚ましい進化を遂げています。本稿では、LLMエージェントの基本的な概念から最新の研究動向、技術応用、さらには今後の展望について解説していきま […]

QueryGym: LLMベースの Query Reformulation フレームワーク
検索システムの改善において、ユーザーの曖昧な入力意図を補完する「クエリ拡張(Query Reformulation)」は、LLMの登場により劇的な進化を遂げています。しかし、論文で提案される有望な手法も、実装コードが散逸 […]

音声ディープフェイク検出の最前線
深層学習の目覚ましい進化は、音声合成技術に革命をもたらしました。これは、パーソナライズされた仮想アシスタントの実現や、発話能力を失った方々が再び「声」を取り戻す手助けをするなど、計り知れない利益をもたらす可能性を秘めてい […]