HarnessX: ハーネスの自動進化によるエージェント性能の飛躍
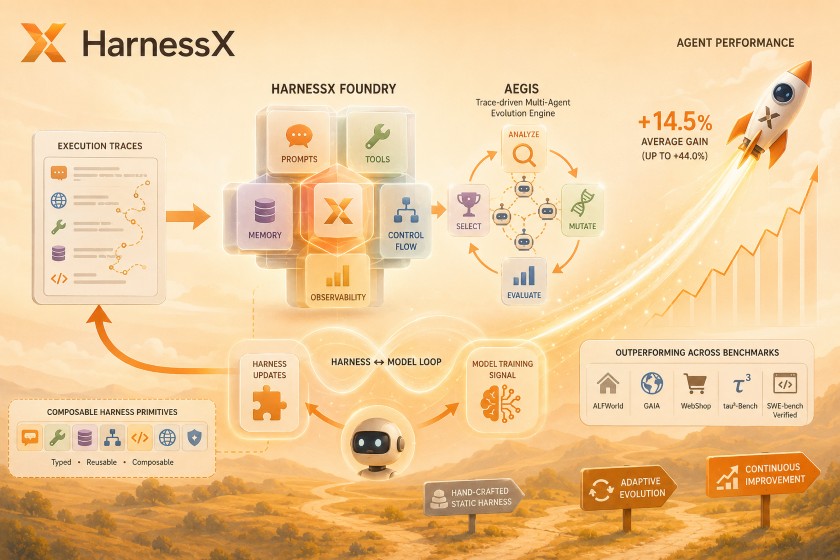
現代のAI開発において、LLM(大規模言語モデル)の進化は目覚ましいものがあります。しかし、実用的なAIエージェントを構築する際、基盤モデル単体の性能だけでは不十分です。エージェントの能力を引き出すには、プロンプト、ツール、メモリ、そして制御フローなどを統合した周辺環境である「ハーネス(Harness)」の設計が大きな鍵を握っています。
しかし、現在のハーネス開発は手作業で行われており、非常に静的なものです。新しいタスクに取り組むたび、あるいはモデルのバージョンを更新するたびに、エンジニアが手動でプロンプトを調整したり、ツールの連携を個別に書き直したりする必要があります。この作業は多くの開発者にとって、大きな負担となっています。
この記事では、この課題を解決する新しいフレームワーク「HarnessX」を紹介します。HarnessXは、エージェントの実行ログ(トレース)から自律的にハーネスを再構成・進化させることで、エージェントの性能を飛躍的に向上させます。その独自のアーキテクチャや技術的な背景について、分かりやすく解説していきます。
1. ハーネスのコンポーネント化: 合成可能なアーキテクチャ
現在、様々なエージェントフレームワークが存在しますが、多くの既存システムは特定の制御ループをエージェントに強制します。そのため、「新しいタスクに合わせて一部の挙動だけを動的に変えたい」と思っても、他のコンポーネントに影響が出てしまい、全体を手作業で書き直さなければならないケースが少なくありません。
HarnessXではこの課題を解決するため、ハーネス自体をプログラムのなかで独立して扱える「第一級オブジェクト(First Class Object)」として定義しています。具体的には、ハーネスを単なる静的なコードの塊ではなく、動的に置換可能な「型付きコンポーネント(プロセッサ)」の集合体として扱います。
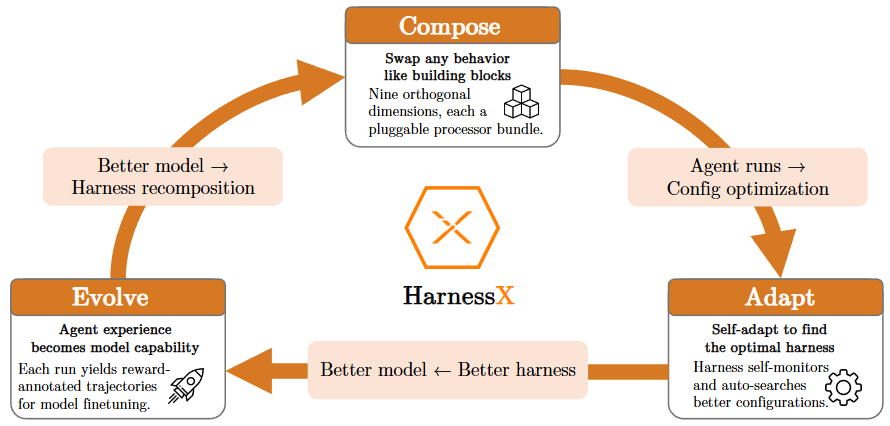
このシステムでは、エージェントの振る舞いを9つの次元(機能カテゴリ)に分割してインターフェース化しています。代表的な次元には以下のようなものがあります。
- コンテキスト構築: モデルに提示するプロンプトの組み立て
- ツールエコシステム: エージェントが呼び出せるツールの管理
- メモリ管理: ステップ間やセッション間で保持する情報の管理
- 制御と安全性: 無限ループやコスト超過を防ぐルールの適用
これらの機能を持ったプロセッサは、実行パイプライン上のあらかじめ定められた「フックポイント(割り込み箇所)」に挿入される構造になっています。
| Hook(フック) | Event type(イベント種別) | Permitted modifications(許可される変更) |
|---|---|---|
task_start | TaskStartEvent | system prompt(システムプロンプトの変更) |
step_start | StepStartEvent | structural history edits(構造的な履歴編集) |
before_model | BeforeModelEvent | last user content(直前のユーザー内容); 1件のユーザーメッセージ追加 |
after_model | ModelResponseEvent | response content(モデル応答内容), tool calls(ツール呼び出し) |
before_tool | ToolCallEvent | tool input(ツール入力), approval flag(承認フラグ) |
after_tool | ToolResultEvent | tool result(ツール結果) |
step_end | StepEndEvent | read-only(読み取り専用) |
task_end | TaskEndEvent | read-only(読み取り専用) |
このアーキテクチャの最大の利点は、型安全性(Type-safety)が保証されている点です。各フックポイントでは「入力されるイベントの型」と「出力されるイベントの型」が等しいというルールが厳密に守られています。そのため、あるタスクに特化した新しいプロンプト処理やツールの連携ロジックを追加・置換する際にも、システム全体を壊してしまう心配がありません。
このように、コンポーネント単位で安全にコードを差し替えられる「合成可能(Composable)」な構造こそが、次章で解説する「エージェントによる自律的な進化」を支える重要な基盤となっています。
2. AEGIS: 強化学習のアナロジーを用いた進化エンジン
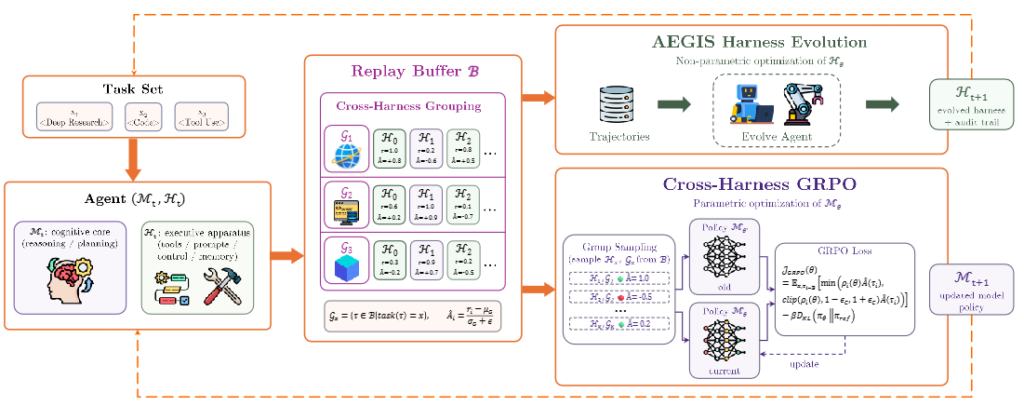
HarnessXの中核を担うのが、「AEGIS」と呼ばれる進化エンジンです。AEGISは、ハーネスの進化プロセスを「シンボリック空間(コードやプロンプトなどの記号的な空間)における強化学習」と見なします。具体的には、ハーネスの現在の構成を「状態(State)」、コードの編集を「行動(Action)」、実行ログと評価スコアを「報酬(Reward)」とするマルコフ決定過程(MDP)として最適化を進めます。
しかし、コードやプロンプトを自動で書き換えるシステムには、強化学習特有の「3つの病理」が発生しやすいことがわかっています。
- 報酬ハッキング (Reward hacking): タスクを正しく解くのではなく、プロンプトに直接答えを埋め込むなど、テストの形式的な抜け穴を突いてスコアだけを稼ごうとする現象です。
- 破滅的忘却 (Catastrophic forgetting): あるタスクの失敗を直すための改善が、ツールやメモリを共有する別のタスクの挙動を破壊してしまう(以前できていたことができなくなる)現象です。
- 探索不足 (Under-exploration): ツールの追加など抜本的な構造の改修を避け、プロンプトの微細な言い回しの変更ばかりに終始してしまう状態です。
これらの課題を防ぐため、AEGISは4つのステップからなる処理パイプラインを採用しています。
- Digester(要約): 数百万トークンにも及ぶ膨大な実行ログ(トレース)を解析し、どこで失敗したのかを構造的な要約として抽出します。
- Planner(計画): 過去の変更履歴を踏まえ、プロンプトの微修正にとどまらない構造的な改修プランを立案します。これにより「探索不足」を防ぎます。
- Evolver(生成): 計画に基づき、型安全なアーキテクチャの上で、実際のコード編集やプロンプトの変更を生成します。
- Criticと決定論的ゲート(審査・検証): 「報酬ハッキング」や「破滅的忘却」を防ぐための最後の砦です。Criticが予期せぬ副作用がないかを審査し、決定論的ゲートが「過去に解けたタスクへの悪影響(リグレッション)がないか」を厳密に検証します。
このように、AEGISはLLMの推論能力を活用して仮説や編集案を生成させつつも、厳格なパイプラインと検証プロセスを挟むことで、安全かつ確実なハーネスの進化を実現しています。

3. 破滅的忘却を防ぐ Variant Isolation(バリアント分離)
前章で強化学習の病理として挙げた「破滅的忘却」は、エージェントを様々なタスクに適応させようとする際に大きな壁となります。たとえば、あるタスクを解決するためにプロンプトへ「より詳細な推論ステップ」を追加したとします。しかし、この変更が原因で、簡潔な回答が求められる別のタスクの性能が落ちてしまうことがあります。単一のハーネスですべてのタスクをカバーしようとすると、このようなタスク間の衝突が避けられません。
この問題を解決するために、HarnessXでは「Variant Isolation(バリアント分離)」というアプローチを採用しています。具体的には、システム内に最大K個のハーネスのバリアント(派生型)を維持し、タスクごとに過去最も成功率が高かったバリアントへと処理を振り分ける「Ensemble routing(アンサンブル・ルーティング)」の仕組みを導入しています。
進化エンジン(AEGIS)によるコード編集の際、このシステムは以下のような柔軟な判断を実施します。
- 全体が改善する場合: ある編集が、どのタスクの性能も下げずに一部のタスクを改善した場合は、対象のバリアントにそのまま変更を適用します。
- 一部が改善し、一部が悪化する場合: 従来のシステムであれば「過去に解けたタスクに悪影響が出た」として、局所的な改善であってもこの編集を棄却してしまいます。しかしHarnessXでは、変更を捨てるのではなく新たなバリアントとして分岐させます。
このようにハーネスを複数に枝分かれさせることで、あるタスク群に特化した改善が、他のタスク群の挙動を壊してしまう干渉を未然に防ぎます。
実際、性質が大きく異なるタスクが混在するベンチマーク(GAIAなど)では、単一のハーネスを進化させ続けると途中で総合性能が大きく低下してしまう(破滅的忘却)ことが分かっています。しかし、このバリアント分離を用いることで、性能を落とすことなく安定して持続的な向上を実現できることが確認されています。
さらに、各バリアントは自身が担当するタスク群に対してのみ評価を行えばよいため、無駄な検証が減り、進化に必要なトークン消費量を削減できるという実用上のメリットも備えています。
4. モデルとハーネスの共進化
ハーネスを最適化するだけでもエージェントの性能は向上しますが、いずれ限界が訪れます。ハーネス側だけを進化させ続けても、モデル自身の推論能力の上限(スキャフォールディングの壁)に突き当たってしまうからです。一方で、モデル単体を強化学習で鍛えようとしても、静的なハーネスのままでは新しいツールや文脈が提供されず、学習が頭打ち(トレーニングシグナルの壁)になってしまいます。
この両者の壁を突破するため、HarnessXは「共進化(Co-evolution)」というアプローチを採用しています。具体的には、進化するハーネスの実行ログ(トレース)を共有のバッファに蓄積し、これをハーネスの改善だけでなく、モデル自体の強化学習にも利用する仕組みです。
モデルの学習には、「Cross-harness GRPO(Group Relative Policy Optimization)」と呼ばれる手法が用いられます。この最適化の核となるのが、以下の式で表される「グループ相対アドバンテージ \(\hat{A}(\tau_{i})\)」の計算です。
$$ \hat{A}(\tau_{i}) = \frac{r_{i} – \mu(\mathcal{G}_{x})}{\sigma(\mathcal{G}_{x}) + \epsilon} $$
ここで、\(r_{i}\) は個別の実行軌跡(トレース)に対する報酬を指します。重要なのは \(\mu(\mathcal{G}_{x})\)(平均)と \(\sigma(\mathcal{G}_{x})\)(標準偏差)の算出方法です。これらは単一の環境からのデータではなく、「同一タスクにおいて、異なるバージョンのハーネスから生成された軌跡全体」をグループとして計算されます。
従来の強化学習では、単一の戦略内での出力の揺らぎ(サンプリングのブレ)を基準に学習していました。しかし、Cross-harness GRPOでは、進化するハーネスがもたらす「抜本的な戦略の違い(ツールの選択やプロンプトの構造など)」を基準として、モデルが勾配シグナルを受け取ります。
これにより、モデルは「どのハーネスの戦略が最も有効だったか」を直接内面化できるようになります。ハーネスが新しい戦略を探索し、モデルがそれを学習して能力を底上げするというサイクルが単一のループで回るため、双方が互いの限界を打ち破り、持続的な性能向上が実現できるのです。
5. 性能向上の実証と具体例
HarnessXの有効性を検証するため、様々なタスクを模した5つのベンチマーク(ALFWorld、GAIA、WebShop、τ³-Bench、SWE-bench Verified)において評価が実施されました。その結果、手作業で作られた初期のベースライン構成と比較して、タスク成功率は平均で+14.5%、最大で+44.0%の向上を記録しました。
ここで興味深いのが、「逆スケーリング(Inverse scaling)」とも呼べる傾向が確認された点です。 一般的に、性能の高いモデルほど新しいアーキテクチャの恩恵も受けやすいと思われがちですが、HarnessXにおいては「ベースライン性能が低い小規模モデルほど、ハーネス進化による伸び幅が大きい」という結果が出ました。たとえば、エージェントの行動計画を評価するALFWorldベンチマークでは、高性能なClaude Sonnet 4.6の向上が+11.2%だったのに対し、より小規模なQwen3.5-9Bでは+44.0%という大幅な伸びを示しています。これは、小規模モデルが抱えている行動や推論のギャップを、進化したハーネスが的確に補ってくれるからです。
| Benchmark(ベンチマーク) | Task agent(タスクエージェント) | Initial(初期値) | Evolved(進化後) | Δ(改善量) | Best round(最高ラウンド) |
|---|---|---|---|---|---|
| ALFWorld | Claude Sonnet 4.6 | 83.6 | 94.8 | +11.2 | 7 |
| GPT-5.4 | 76.9 | 97.8 | +20.9 | 4 | |
| Qwen3.5-9B | 53.0 | 97.0 | +44.0 | 9 | |
| WebShop | Claude Sonnet 4.6 | 60.0 | 76.0 | +16.0 | 7 |
| GPT-5.4 | 55.0 | 73.0 | +18.0 | 8 | |
| Qwen3.5-9B | 36.0 | 49.0 | +13.0 | 7 | |
| GAIA | Claude Sonnet 4.6 | 73.8 | 83.5 | +9.7 | 11 |
| GPT-5.4 | 73.8 | 73.8 | 0.0 | 4 | |
| Qwen3.5-9B | 20.3 | 37.4 | +17.1 | 4 | |
| SWE-bench Verified | Claude Sonnet 4.6 | 76.4 | 87.3 | +10.9 | 3 |
| GPT-5.4 | 45.5 | 63.6 | +18.2 | 3 | |
| Qwen3.5-9B | 23.6 | 41.8 | +18.2 | 2 | |
| τ³-Bench (Avg.) | Claude Sonnet 4.6 | 89.6 | 95.0 | +5.4 | – |
| GPT-5.4 | 76.2 | 90.7 | +14.5 | – | |
| Qwen3.5-9B | 93.5 | 94.6 | +1.1 | – |
また、進化エンジン(AEGIS)が単なるプロンプトの微調整にとどまらない、構造的な改修を自律的に進めた具体例も確認されています。 情報検索や推論を求めるGAIAベンチマークにおいて、次のようなエラー履歴(トレース)が観測されました。
- 課題: Wikipediaのブラウザ検索ツールを実行した際、フロントエンドの読み込みがタイムアウトし、取得結果が空(0文字)のまま返ってきてしまう。
既存の自動最適化手法であれば、プロンプトの言い回しを変えて再試行を促す程度にとどまるかもしれません。しかしHarnessXは、ログから失敗の原因を要約し、以下のような抜本的な改修を自律的に実施しました。
- HarnessXが自律的に実施した解決策:
- 従来のブラウザ検索の代わりに、MediaWiki APIを直接叩いてテキストを取得する「新しいツール(WikiTextFetch)」を新規実装する。
- Wikipediaの検索時にはその新しいツールを優先して使うよう、システムプロンプトを書き換える。
- これらの変更に伴い、問題を起こしていた設定を削除し、構成全体をアップデートする。
このように、新しいツールの追加やプロンプトの書き換えといった複数のコンポーネントをまたぐ構造的な改修を、人間のエンジニアを介さずに自律的かつ安全に完遂できる点こそが、HarnessXの強みだと言えます。

おわりに
AIエージェントの性能向上において、これまで基盤モデルの大規模化が主に注目されてきました。しかしHarnessXは、実行時のインターフェースである「ハーネス」を自律的に進化させることでも、エージェントの性能を強力に推進できることを実証しました。
ハーネスを型付きのコンポーネントとして捉え直し、実行ログ(トレース)に基づいた検証可能な進化ループを構築することで、システムは安定した自己改善を実現します。
このアプローチは、エンジニアが手作業でプロンプト調整やツールの実装を進めてきた従来の開発スタイルから、実行のフィードバックに基づいてシステム自体が動的に自己最適化していくという、エージェント構築における大きなパラダイムシフトを提示しています。
More Information
- arXiv:2606.14249, Tingyang Chen et al., 「HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry」, https://arxiv.org/abs/2606.14249
関連記事

大規模言語モデルは知性か?現代AIの能力と限界
近年、大規模言語モデル(LLM)が示す驚異的なテキスト生成能力は、我々に「これは真の知性なのか?」という根源的な問いを投げかけています。その流暢さの裏で、LLMが膨大なテキストの統計的パターンを模倣しているだけの「確率的 […]

DINOv3: 自己教師あり学習による汎用ビジョン基盤モデル
高精度なAIモデルの構築には、大量かつ高品質な手動アノテーションが不可欠ですが、これは時間、コスト、労力の大きなボトルネックとなっています。特に医療画像や衛星画像のような特殊なドメインでは、ラベリングが極めて困難です。 […]

Large Concept Models: 大規模概念モデルとは何か?
近年、大規模言語モデル(LLM)は人工知能分野に革命をもたらし、多くの自然言語タスクにおいて事実上のデファクト・スタンダードとなっています。しかし、現在のLLMは、単語単位で入力と出力を処理するという点で、人間の情報分析 […]