ExecuTorch: モバイル・エッジデイバス向けAI推論の事始め
モバイル端末やエッジデバイス上でAIを動かす「オンデバイス推論」が近年注目を集めています。これまで、PyTorchで構築したモデルをエッジデバイスで展開する際は、主にTorchScriptベースの「PyTorch Mobile」が利用されてきました。しかし、エッジ環境には、限られたメモリや電力、計算リソース、そしてリアルタイム処理の要求など、特有の厳しい課題があります。
こうした課題を解決するために開発されたのが、新しいエンドツーエンドの推論ソリューションである「ExecuTorch」です。ExecuTorchは、PyTorch 2のコンパイラとエクスポート機能(torch.export)を最大限に活用することで、従来よりもさらに小さなメモリ使用量(メモリフットプリント)での推論を実現しています。スマートフォンから組み込み機器まで、様々なハードウェアに対応できる「高い移植性」と、デバイスの計算能力を引き出す「パフォーマンス」を両立している点が大きな特徴です。
今回は、このExecuTorchの全体像や最適化の仕組み、そして実際の実装例について解説し、エッジ向けAI開発の第一歩をサポートします。
1. ExecuTorch の概要
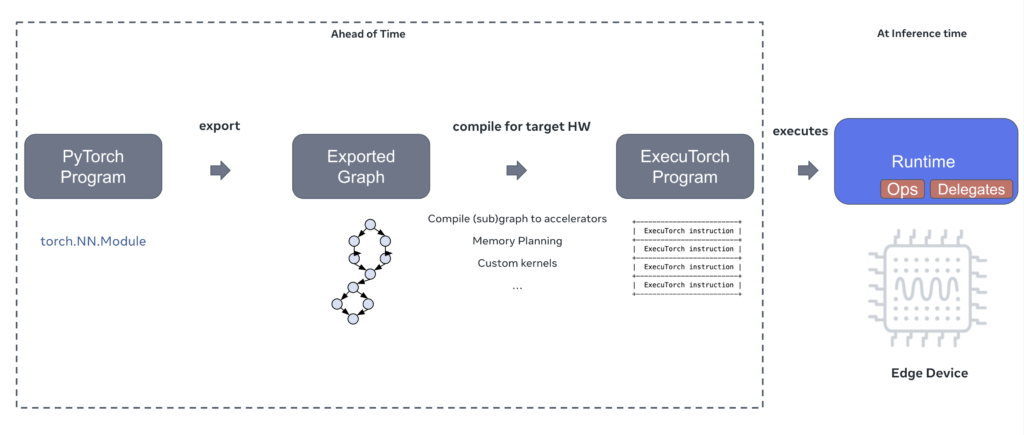
ExecuTorchの全体アーキテクチャは、PyTorchのモデルをエッジデバイスに展開するため、大きく分けて以下の3つのフェーズで構成されています。
- プログラムの準備(AOTコンパイル): PyTorchのコードをエクスポートし、ターゲット環境に依存しないグラフ表現から、デバイスに適した形式へと変換および最適化を進めます。この一連の処理はAOT(事前)コンパイルと呼ばれます。
- ランタイムの準備: 実際にプログラムを実行する環境向けに、必要なカーネルライブラリやバックエンドライブラリを選択・準備します。
- プログラムの実行: C++で記述されたランタイムがプログラムをロードし、デバイス上で推論を実施します。
エッジデバイスでの実行において特筆すべきは、ランタイムの圧倒的な軽量さです。カーネルやハードウェア固有のバックエンドを含まないコアとなるC++ランタイムライブラリ単体では、50kB未満というサイズに抑えられています。
さらに、リソース消費を抑えつつ厳密な動作を保証するため、コアランタイムは内部で malloc() や new といった動的メモリ割り当て(ヒープアロケーション)に一切依存しません。代わりに、実行時にユーザー側から提供されるメモリアロケータやメモリマネージャーを通じて、計画的にメモリを管理する仕組みを採用しています。
この設計により、ヒープ領域やOSを持たないベアメタル環境の組み込み機器から最新のスマートフォンまで、非常に幅広いハードウェア上で安定して動作させることが可能になっています。
2. 最適化の仕組み
限られたリソースしか持たないエッジデバイスでAIモデルを動かすためには、徹底した最適化が欠かせません。ExecuTorchでは、主に以下の4つのアプローチでこの課題に取り組んでいます。
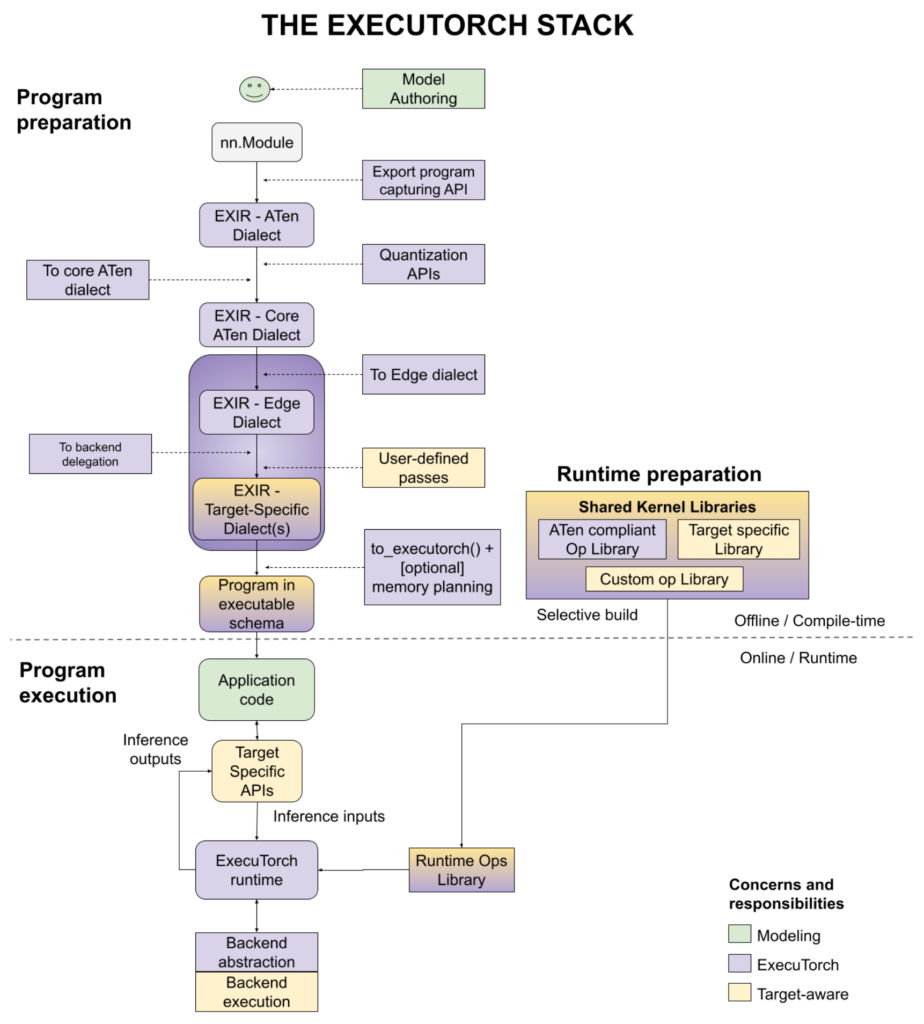
- グラフ変換(Dialectの活用) PyTorchのEager(実行時評価)モードで記述されたモデルは、まず
torch.exportを通じて ATen Dialect と呼ばれるハードウェアに依存しない中間表現として抽出されます。その後、データ型やメモリレイアウトといったエッジ環境向けの情報が付与された Edge Dialect、さらに特定のハードウェアの特性に合わせた Backend Dialect へと、段階的に変換(Lowering)を進めます。これにより、様々なデバイスに対して柔軟かつ効率的な実行コードを生成できます。 - メモリプランニング 実行時の動的なメモリ割り当ては、処理の遅延や電力消費の増加を招きます。そこでExecuTorchは、プログラムの実行前にすべてのテンソルのライフタイム(生存期間)とサイズを解析し、あらかじめメモリの割り当てを計画(メモリプランニング)します。テンソル同士のライフタイムが重ならない場合は、「Greedyアルゴリズム」などを利用してベストフィット基準でバッファを再利用します。この工夫により、メモリの断片化を防ぎつつ、ピーク時のメモリ使用量を大幅に抑えることが可能です。
- デリゲーション(処理の委譲) 計算グラフ全体を汎用的なCPUで処理するのではなく、適した一部の処理(サブグラフ)をNPUやDSPといった専用のアクセラレータに切り出して任せる仕組みがデリゲーションです。これにより、各ハードウェアに特化したコンパイラがもたらす高度な最適化と高速化の恩恵をフルに享受できます。
- 量子化(Quantization) エッジデバイスへの展開において欠かせないのが量子化です。ExecuTorchでは
torchaoライブラリやPT2E(PyTorch 2 Export)フローを活用して量子化を実施します。通常は32ビット浮動小数点(FP32)で扱われるパラメータや計算処理を、8ビット整数(INT8)などの低精度なデータ型に変換することで、モデルサイズを劇的に削減し、推論のレイテンシ(遅延)と消費電力を改善します。
このように、コンパイラによる事前準備からハードウェアの活用まで、多角的なアプローチを組み合わせることで、リソースの厳しい環境でも快適なAI推論を実現しているのがExecuTorchの強みです。
3. pteバイナリフォーマットの概要
ExecuTorchでエクスポートされたモデルは、最終的に.pteという拡張子のバイナリファイルとして保存(シリアライズ)されます。このファイルは、メモリ効率に優れたデータ構造である「フラットバッファ(FlatBuffer)」をベースに設計されています。
.pteファイルの構造は、主に以下の要素に分かれています。
- 標準ヘッダ: ファイルの基本情報を含みます。
- 拡張ヘッダ(オプション): ExecuTorch独自のヘッダであり、
ehというマジック文字列から始まります。ここには、プログラムデータや後続するセグメントデータへのオフセット(位置情報)などが記録されています。 - プログラムデータ: モデルの実行手順などを記述した、推論のライフサイクル全体で保持されるコアデータです。
- セグメントデータ(オプション): 実際のテンソルデータ(重みなど)を格納する領域です。
実際のファイル構造のイメージは以下の図の通りです。
┌───────────────────────────────────┐
│Standard flatbuffer header │
├───────────────────────────────────┤
Optional ─> │ExecuTorch extended header │
├───────────────────────────────────┤
│Flatbuffer-serialized program data │
│ │
│ │
┌ ├───────────────────────────────────┤
│ │Padding │
│ ├───────────────────────────────────┤
│ │Segment data │
│ │ │
│ │ │
│ ├───────────────────────────────────┤
│ │Padding │
Optional ┤ ├───────────────────────────────────┤
│ │Segment data │
│ │ │
│ │ │
│ ├───────────────────────────────────┤
│ │Padding │
│ ├───────────────────────────────────┤
│ │... │
└ └───────────────────────────────────┘このフォーマットの優れた点は、実行時のメモリ効率にあります。特にセグメントデータは、ターゲットシステムのメモリページサイズ(通常4096バイトなどの2の累乗)に合わせて、パディングによって開始位置が調整(アライメント)されています。
この工夫により、mmap()などのOSの機能を利用して、ファイルを直接メモリにマッピングする効率的な読み込みが可能になります。さらに、プログラムデータとセグメントデータが物理的に分離されているため、モデルの初期化が完了した後に不要となる巨大なテンソルデータを、メモリから早期に解放してリソースを節約できる設計となっています。これは、リソースが限られたエッジデバイスで巨大なモデルを動かすための重要な仕組みです。
4. サポートデバイス一覧
エッジデバイスと一口に言っても、搭載されているプロセッサや処理を高速化するアクセラレータは様々です。ExecuTorchでは、CPUや特定のアクセラレータが持つ性能を最大限に引き出すために、モデルはそれぞれの実行環境(バックエンド)に特化した.pteファイルとして生成およびデプロイされる仕組みになっています。
現在、ExecuTorchでは多様なハードウェア環境でのAI推論をサポートするため、以下のようなバックエンドが提供されています。
| カテゴリ | バックエンド名 | 概要 |
|---|---|---|
| モバイルCPU | XNNPACK | 幅広いArmおよびx86のCPUで動作し、モバイル端末でのCPU推論を最適化します。 |
| Appleデバイス | Core ML | iOSやmacOSにおいて、CPUだけでなくGPUや ANE (Apple Neural Engine) を統合的に活用します。 |
| MPS | MPS (Metal Performance Shaders) を利用し、iOSなどのGPU処理に特化した高速化を実施します。 | |
| Android GPU | Vulkan | クロスプラットフォームなGPU APIであるVulkanを活用し、主にAndroidデバイスのGPUで推論を進めます。 |
| NPU / DSP | Qualcomm AI Engine (QNN) | SnapdragonなどのQualcomm SoCに搭載された各種アクセラレータを制御します。 |
| MediaTek NPU | MediaTekのSoCに搭載された NPU (Neural Processing Unit) を活用します。 | |
| Arm Ethos-U | 組み込み機器向けのArm Ethos-U NPUシリーズ(U55、U65、U85など)での実行に対応します。 | |
| Cadence Xtensa DSP | 音声処理などに強みを持つCadenceの DSP (Digital Signal Processor) での推論に取り組みます。 | |
| その他 | OpenVINO | Intel環境のCPUやGPU、NPUなどに向けた最適化を提供します。 |
5. Python実装の例
ここでは、学習済みの ResNet-50 を ExecuTorch 形式にエクスポートし、推論を実行するサンプルを通じて、実際の開発フローを確認します。
5-1. モデルのエクスポート
エクスポートの流れは、「PyTorchモデルの静的グラフ化 → Edge dialectへの変換とバックエンド委譲 → .pteへのシリアライズ」の3段階です。
import torch
import torchvision
from executorch.backends.xnnpack.partition.xnnpack_partitioner import XnnpackPartitioner
from executorch.exir import EdgeCompileConfig, ExecutorchBackendConfig, to_edge_transform_and_lower
from torch.export import export
model = torchvision.models.resnet50(weights=torchvision.models.ResNet50_Weights.IMAGENET1K_V2)
model.eval()
# torch.export でモデルを静的グラフ(ExportedProgram)としてキャプチャする。
# 入力の shape・dtype を固定することで、ExecuTorch が AOT にメモリプランを確定できる。
example_input = (torch.randn(1, 3, 224, 224),)
exported_program = export(model, example_input)
# to_edge_transform_and_lower() は to_edge() と to_backend() を一括実行する推奨 API。
# XnnpackPartitioner が対応するオペレータを XNNPACK カーネルへ委譲(デリゲーション)し、
# 残りのオペレータはポータブルな Edge カーネルで実行される。
edge_manager = to_edge_transform_and_lower(
exported_program,
partitioner=[XnnpackPartitioner()],
compile_config=EdgeCompileConfig(_check_ir_validity=True),
)
# extract_delegate_segments=True でデリゲート(重みなど)を .pte 内の
# 別セグメントに分離し、mmap による効率的なロードを可能にする。
executorch_program = edge_manager.to_executorch(
ExecutorchBackendConfig(extract_delegate_segments=True)
)
with open("resnet50_xnnpack.pte", "wb") as f:
f.write(executorch_program.buffer)
ポイント:
torch.exportによる静的グラフのキャプチャが前提となる点がExecuTorchの大きな特徴です。入力 shape を固定することで、AOTコンパイル時にメモリプランニングを完結させ、実行時の動的アロケーションをゼロに近づけます。またto_edge_transform_and_lower()の一括 API により、Edge dialectへの変換とXNNPACKへのデリゲーションが効率よく行われます。
5-2. 推論とベンチマーク
エクスポートした .pte は ExecuTorch の Python ランタイム(executorch.runtime)で読み込み、method.execute() を呼び出すだけで推論できます。
import torch
import torchvision
from executorch.runtime import Program, Runtime
input_tensor = torch.randn(1, 3, 224, 224)
# Runtime はシングルトン。load_program() で .pte をロードし、
# load_method() で実行したいメソッド(ここでは "forward")を取得する。
et_runtime = Runtime.get()
program: Program = et_runtime.load_program("resnet50_xnnpack.pte")
method = program.load_method("forward")
et_logits = method.execute([input_tensor])[0] # 出力: Tensor[1, 1000]
実画像を使う場合は、学習時と同じ ImageNet 前処理パイプラインをテンソル変換前に適用します。
from torchvision import transforms
from PIL import Image
PREPROCESS = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
img = Image.open("cat.jpg").convert("RGB")
input_tensor = PREPROCESS(img).unsqueeze(0) # (1, 3, 224, 224)
et_logits = method.execute([input_tensor])[0]
ポイント: ExecuTorch ランタイムの推論出力は PyTorch eager モードと数値的にほぼ一致します(誤差は
1e-6オーダー)。一方、実行速度は対象デバイスのアーキテクチャに依存します。XNNPACK は ARM NEON や Intel AVX 向けに最適化されているため、一般のCPU 環境では PyTorch のネイティブカーネルを下回ることがありますが、Arm ベースのモバイル端末(Android / iOS / Raspberry Pi)では本領を発揮します。
おわりに
ExecuTorchが提供する標準化されたコンパイラインターフェースや軽量なランタイムを活用することで、PyTorchを用いたモデルの開発からエッジ環境へのデプロイまでをシームレスに進めることができます。
さらに現在では、Llama 3をはじめとする大規模言語モデル(LLM)のオンデバイス実行もサポートされています。このように、ExecuTorchは単なる軽量化ツールにとどまらず、メモリや電力といったリソース制約の厳しいエッジデバイスにおいて、高度なAI推論を実現するための強力な基盤となります。
今後のエッジAI開発において欠かせない選択肢となるExecuTorchに、ぜひ一度触れてみてください。
More Information
関連記事

YOLO26: 次世代のエッジAI物体検出
2026年1月、Ultralytics社はYOLOシリーズの最新版となる「YOLO26」をリリースしました。YOLOv8やYOLO11といった歴代モデルの正統進化でありながら、今回の設計思想は「エッジデバイスでの推論効率 […]

D-CLOSE - 物体検出モデルのためのXAI技術
近年の目覚ましいAI技術の発展に伴い、画像認識分野における物体検出モデルの活用が、医療や自動運転をはじめとする多岐にわたる分野で急速に拡大しています。しかしながら、これらの高性能な深層学習モデルが、どのように物体を検出し […]

LLM時代の自律型コーディング・エージェントはソフトウェア開発の在り方をどのように変えるか?
大規模言語モデル(LLM)の目覚ましい進化は、ソフトウェア開発(Software Development)の領域に根本的な変化をもたらしています。これまで、AIによるコーディング支援の多くは、自然言語の記述を静的なコード […]