データエージェントの自律性レベルとロードマップ

「データエージェント」という言葉、最近よく耳にしますよね。ですが、単にSQLを回答するだけのチャットボットから、複雑な分析ワークフローを自律的に回す高度なシステムまで、その定義は非常に曖昧です。この曖昧さは、開発者とユーザーの間で期待値のズレを生み、実装の現場に混乱を招く原因にもなっています。
そこで本記事では、データベース分野のトップ会議であるSIGMOD ’26のチュートリアル資料で提案された「データエージェントの自律性レベル(L0〜L5)」というフレームワークをもとに、この概念を整理します。なぜ汎用的なLLMエージェントと区別して考える必要があるのか、そして現在主流の「ツール利用(Tool Use)」を行うシステムはどのレベルに位置づけられるのか。
現在の技術的な到達点と、これから実務でデータエージェントを構築する際の指針について、エンジニア視点で具体的に解説していきます。
1. データエージェントとは何か: 汎用LLMエージェントとの違い
「エージェント」と聞くと、Web検索をして旅行プランを立ててくれるような汎用的なアシスタントを思い浮かべる方が多いかもしれません。しかし、企業のデータ基盤を扱うデータエージェントは、それらとは全く異なる過酷な環境で戦う必要があります。
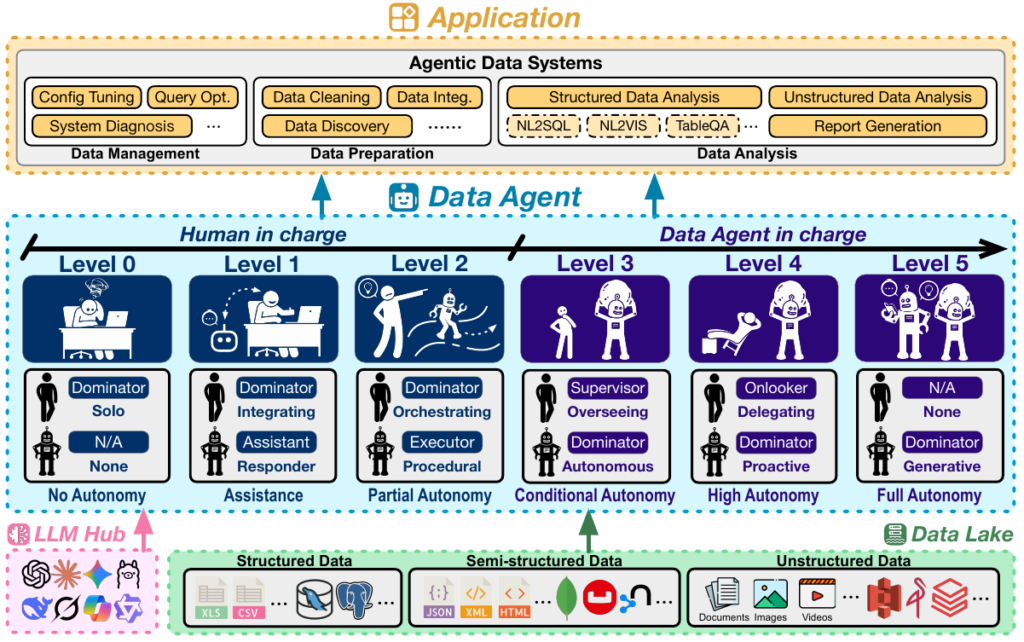
SIGMODの資料では、データエージェントを汎用LLMエージェントと明確に区別しています。システム設計者が意識すべき決定的な違いは、以下の3点に集約されます。
①「おしゃべり」ではなく「データライフサイクル」全体を扱う
汎用エージェントの主な目的は、ユーザーとの対話やコンテンツ生成です。一方、データエージェントの守備範囲はデータライフサイクル(管理・準備・分析)の全工程に及びます。
具体的には、単に「売上を教えて」という質問にSQLで答える(分析)だけではありません。その前段階であるデータのクリーニングや統合(準備)、さらにはデータベースのインデックス設定やクエリ最適化(管理)といった、従来はデータベース管理者やデータエンジニアが行っていた裏方の作業までもが対象となります。
➁ エラーが連鎖し、静かに全体を汚染する(Cascading Errors)
ここがエンジニアにとって最も恐ろしい点です。 チャットボットが事実と異なる回答(ハルシネーション)をした場合、ユーザーは比較的気づきやすく、影響はその回答単体にとどまることが多くあります(Localized Error)。
しかし、データエージェントがパイプラインの途中でミスを犯すと、事態は深刻になります。たとえば、データクリーニングの段階で特定のレコードを誤って削除してしまったとしましょう。そのエラーは下流の集計処理、レポート作成、そして最終的な経営判断に至るまで、誰にも気づかれないまま静かに伝播します。そのため、データエージェントには汎用モデル以上の堅牢性と、各工程での検証メカニズムが求められます。
③「きれいな箱庭」ではなく「泥臭い現場」で動く
汎用エージェントは、ある程度整理されたテキストや明確な指示を入力とすることが多いです。対してデータエージェントが相手にするのは、ノイズだらけの巨大なデータレイクや、予告なくスキーマ(構造)が変更されるデータベースです。
「先週まで動いていたクエリが、カラム名変更で突然動かなくなった」「CSVのフォーマットが微妙に壊れている」——そんな大規模かつ動的で、不確実性の高い環境を自律的に探索し、問題を解決しながらタスクを完遂する能力が必要とされます。
このように、データエージェントは単なる「SQL生成Bot」ではありません。複雑なデータ基盤の中で、責任ある行動が求められるシステムです。
| 観点 | 汎用LLMエージェント | データエージェント |
|---|---|---|
| 主な焦点 | タスクおよびコンテンツ中心 定義されたタスクの遂行やコンテンツ生成を行う。 | データライフサイクル中心 データの管理、前処理、分析を担う。 |
| 問題のスコープ | 自己完結的かつ静的 明示的な指示および有限のプロンプトに基づいて動作する。 | 探索的かつ動的 広大で動的なデータレイクを積極的に探索・走査する。 |
| 入力データ | 小規模かつ即利用可能 整理された扱いやすいクリーンな入力を受け取ることが一般的。 | 大規模かつ“生データ” 異種混在・動的・ノイズを含む生データの処理を前提とする。 |
| ツール活用 | 汎用ツールキット Web検索、電卓、OCR、画像生成など。 | 専門的データツールキット DBローダー、SQL同値性検証、可視化ライブラリなど。 |
| 主な出力 | 生成成果物 対話、推論結果、画像など人間が直接利用可能な成果物。 | データ成果物および洞察 設定情報、加工済みデータ、分析結果、可視化、分析レポートなど。 |
| エラーの影響 | 局所的 通常は直接的な出力のみに影響が限定される。 | 連鎖的 エラーが下流工程へ波及し、後続の洞察に影響を及ぼす可能性がある。 |
2. 自律性の6段階レベル(L0〜L5)の定義
自動運転技術に「レベル分け(SAE J3016)」が存在するように、データエージェントにもその自律性に応じた6段階の分類が提唱されています。
エンジニアとしてシステムを設計する際、まずは「自分が作ろうとしているものがどのレベルなのか」を正しく認識することが重要です。ここでは、SIGMODのチュートリアルで定義されたL0からL5までの各レベルを、技術的な実装要件と合わせて解説します。
L0: No Autonomy(自動化なし)
すべてを人間が手動で行う段階です。
データベース管理者が手動でコンフィグを調整したり、データアナリストがExcelやPythonスクリプトを自ら書いて実行したりする状態を指します。ここにエージェントの介入はありません。
L1: Assistance(対話型アシスタント)
現在多くの開発者が利用している「Copilot」的な立ち位置です。このレベルのエージェントはステートレス(状態を持たない)であり、「プロンプト・レスポンス」形式で動作します。
- 何をするか: ユーザーの質問に対してSQLクエリを提案したり、Pythonのデータ分析コードを生成したりします。
- 何ができないか: 生成されたコードの実行(Execution)や、データベースへの直接アクセスは行いません。あくまで「提案」にとどまり、それをコピー&ペーストして実行し、エラーが出たら修正するのは人間の役割です。
L2: Partial Autonomy(部分的自律)
ここからが「エージェント」らしい挙動になります。L2の最大の特徴は、環境(Environment)へのアクセス権とツール実行能力を持つことです。
- ツールの利用: データベースに接続してスキーマを取得したり、Pythonインタプリタでコードを実行してグラフを描画したりできます。
- フィードバックループ: 実行結果(エラーメッセージやクエリ結果)を「知覚」し、自動でリトライや修正を行うループ処理が可能です。
- 限界: ただし、エージェントはあくまで「実行者(Executor)」です。ワークフロー全体(どの順番でどのツールを使うか)の設計は人間が行う必要があり、エージェントは決められた手続きの中で自律的に動くだけに留まります。
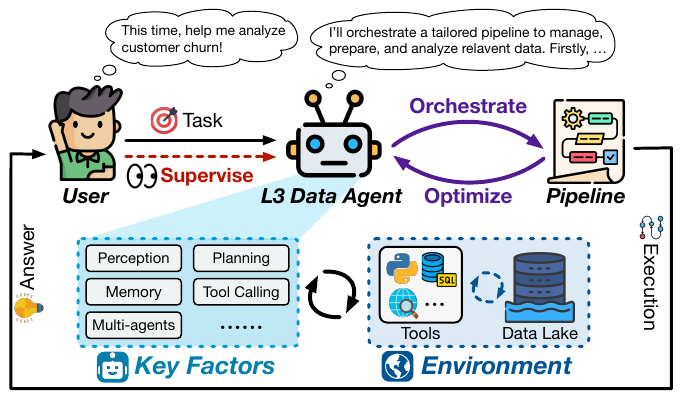
L3: Conditional Autonomy(条件付き自律)
現在、研究開発の最前線となっているのがこのL3です。L2との決定的な違いは、エージェントが「オーケストレーター(指揮者)」になる点です。
- 高レベルな指示: ユーザーは「今期の顧客解約(Churn)の要因を分析して」といった抽象的なゴールだけを与えます。
- プランニング: エージェントは自らタスクを分解し、必要なパイプライン(データの抽出→クリーニング→分析→可視化)を設計・構築します。
- 役割の変化: 人間は作業者から「監督者(Supervisor)」へと退き、エージェントが提案したプランの承認や、最終結果の確認に注力します。
L4: High Autonomy(高度な自律)
L3までは「ユーザーからの指示」がトリガーでしたが、L4ではエージェントがプロアクティブ(能動的)になります。
- 常時監視と提案: エージェントはデータレイクやシステムの状態を常に監視(Monitor)します。「データの分布が変わったので再学習が必要かもしれません」や「このインデックスを追加するとパフォーマンスが改善します」といった提案を、人間が聞く前に自ら行います。
- 自己管理: エージェントは長期間にわたって稼働し続け、自律的にシステムの健全性を維持します。
L5: Full Autonomy(完全自律)
これは未来のビジョンです。L5のエージェントは、既存の手法を適用するだけでなく、新たなアルゴリズムや解決策を発明できる「AIデータサイエンティスト」となります。人間の関与は完全に不要となります。
現在の技術トレンドとしては、L1(コード生成)からL2(ツール実行)への移行が進んでおり、一部の先進的なシステムがL3(自律的なワークフロー設計)に挑戦しているという状況です。
3. 実装の壁: L1からL2、そしてL3へ
定義上のレベル分けを理解したところで、エンジニアとして最も気になるのは「どうやって実装するか」、そして「どこに技術的な壁があるか」でしょう。実務的な開発において重要となる、各レベル間の技術的な飛躍と実装のポイントを解説します。
L1(Co-pilot)からL2(Executor)への進化
現在、多くの企業で導入されている「社内版ChatGPT」や「SQL生成ボット」の多くはL1(Assistance)に留まっています。これらをL2(Partial Autonomy)へと進化させるためには、単なる「回答の生成」から「環境との相互作用」へのシフトが不可欠です。
実装において乗り越えるべき壁は、主に以下の2点です。
- フィードバックループの自動化(Closing the Loop): L1では、エージェントが生成したSQLやPythonコードを人間がコピーし、実行し、エラーが出ればその内容を再度エージェントに伝えて修正させる必要がありました。 L2システムでは、この「試行錯誤」のプロセス自体を自動化するロジックが求められます。具体的には、DBMSやコードインタプリタからの実行結果(成功時のデータプレビューや、失敗時のスタックトレース)をエージェントが「知覚」し、自律的にリトライや修正を行うループ処理を実装する必要があります,。
- ステートフルな設計への転換: L1は基本的にステートレス(一問一答)ですが、L2はタスク完了まで中間データを保持し続ける必要があります。たとえば、データ分析において「データのロード→クリーニング→可視化」という手順を踏む際、各ステップの実行状態や中間変数をコンテキストとして維持し、ツール間で受け渡す設計が求められます。
実用例: DBチューニングにおける進化 データベース管理の領域で例えると、L1は「現在のワークロードに対して、どのようなインデックスを貼るべきか」を提案するだけです。対してL2のエージェントは、実際にテスト環境でベンチマークを実行し、そのパフォーマンス結果(フィードバック)を見てパラメータを再調整するところまでを担当します。
L3(Orchestrator)への挑戦
L2が「決められた手順の中でツールをうまく使う(Executor)」レベルだとすれば、L3(Conditional Autonomy)は「手順そのものを設計する(Orchestrator)」レベルです。ここは現在のアカデミアと産業界における最前線(Proto-L3)であり、実装難易度は飛躍的に高まります。
- ワークフローの動的生成(Dynamic Planning): L2までのシステムは、人間が設計した固定のパイプライン(例:前処理→分析→レポート)の中で動作していました。しかしL3では、ユーザーの「今期の解約率の要因を知りたい」といった抽象的な意図から、必要なツールやステップを自律的に組み合わせ、実行計画(DAG: 有向非巡回グラフ)を動的に生成する能力が必要となります。
- 技術的なボトルネック: 現在の研究では、L3の実現に向けていくつかの課題が浮き彫りになっています。
- 既存オペレーターへの依存: 多くのシステムは、あらかじめ定義されたツール(Predefined Operators)の組み合わせしかできず、想定外のデータ形式やタスクに対応する柔軟性が不足しています。
- コンテキストと記憶の維持: 複数の工程にまたがる長期間のタスクにおいて、初期の指示や途中で判明した重要な制約条件を「忘れずに」保持し続けるメモリ管理が課題となっています。
- リカバリ戦略: L3では人間が「監督者(Supervisor)」に退くため、エージェントが間違った計画を立てた際、それが致命的なエラー(Cascading Errors)になる前に検知・修正する高度なメタ認知能力が求められます。
L1からL2への進化は「自動化範囲の拡大」ですが、L2からL3への進化は「意思決定権の委譲」を意味します。エンジニアは、エージェントが生成したプランを人間が検証しやすいUI/UXとセットで設計することが、L3実装の鍵となります。
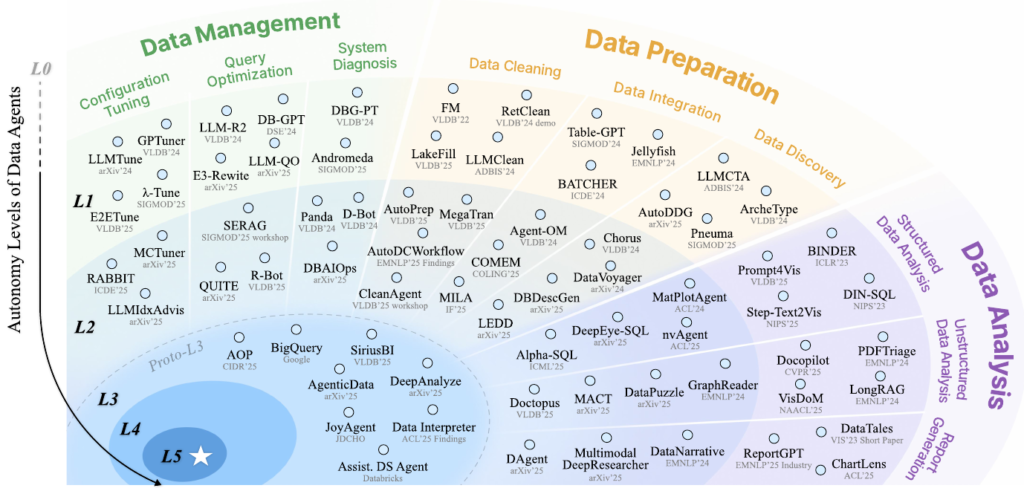
4. 具体的なユースケースと技術適用
これまで定義した自律性レベルが、実際の開発現場でどのように適用されているかを見ていきます。SIGMODのチュートリアル資料では、データライフサイクルを「管理」「準備」「分析」の3つに分け、それぞれのフェーズにおけるL1(アシスタント)とL2(実行者)の実装例を紹介しています。
データ管理(Data Management)
データベース管理者の業務を支援、あるいは代行する領域です。
- L1(提案レベル): クエリのパフォーマンスが悪い時、LLMにSQLを貼り付けて「もっと速くして」と頼むのがこのレベルです。システムはクエリの書き換え案や、データベースの設定値(Knob)の調整案を提示します。
- L2(実行・実験レベル): エージェントはDBMSに直接アクセスする権限を持ちます。 例えば、インデックス作成の提案だけでなく、実際にテスト環境で作成し、ベンチマークを実行して効果を測定します。パフォーマンスが低下すればロールバックし、改善すれば適用するといった「実験と検証のループ」を自律的に回します。
- 技術例: D-Bot(診断)や Rabbit(チューニング)などが該当し、これらはデータベース内部の統計情報を監視(Monitor)しながら作業を進めます。
データ準備(Data Preparation)
いわゆる「データの前処理」です。データサイエンティストが最も時間を費やす工程と言われています。
- L1(ルール生成レベル): 「このカラムの表記ゆれを直す正規表現を書いて」といった指示に対し、Pythonコードやクリーニングルールを生成します。
- 技術例: LLMClean はデータの汚染を検知して修正ルールを提案しますが、そのルールが正しいかどうかは人間がコードを見て判断する必要があります。
- L2(クリーニング実行レベル): エージェントは外部ツール(PythonインタプリタやAPI)を呼び出し、実際にデータを加工します。重要なのは、実行時にエラー(例:型不一致)が出た場合、エージェントがエラーメッセージを読み取ってコードを修正し、成功するまでリトライする点です。
- 技術例:
CleanAgentや MegaTran は、データの変換を実行し、その結果を検証して反復的に精度を高めることができます。
- 技術例:
データ分析(Data Analysis)
ビジネスインサイトを導き出す、花形の工程です。
- L1(コード生成レベル): ユーザーの質問をSQLに変換する Text-to-SQL や、グラフ描画コードを書く Text-to-Vis が主流です。これらは「一問一答」形式であり、生成されたSQLが実行不可能だったり、空の結果を返したりしても、システム側はそれを知りません。
- 技術例: 一般的な Table QA システムや、初期の
Copilotツールがここに分類されます。
- 技術例: 一般的な Table QA システムや、初期の
- L2(探索的分析レベル): エージェントはSQLエンジンやPythonの可視化ライブラリ(Matplotlib等)と連携します。クエリを実行してデータの中身を確認し、「この集計結果は異常値っぽいな」と判断すれば、自ら別の角度でクエリを投げ直すといった多段階の推論(Multi-step Reasoning)を行います。
- 技術例: Data Interpreter や MatPlotAgent は、エラー修正だけでなく、中間データを確認しながら動的に分析プロセスを修正し、最終的なレポートまで作成します。
このように、L1からL2への進化は、単に「AIが賢くなる」ことではなく、「AIが実行環境(Environment)とフィードバックループを持つこと」を意味します。現状の多くのプロダクトはL2の実装を急ピッチで進めており、一部の先進的な研究は、これら全ての工程を統合して指揮するL3(オーケストレーター)へと向かっています。
| Years | Data Agent | Open-source | Undef Ops. | Multis. | Hete. | Multim. | Config Tun. | Query Opt. | Sys. Diag. | Data Clean. | Data Integ. | Data Disc. | Struct. | Unstruct. | Report Gen. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2025 | AgenticData | – | ❌ | ✅ | ✅ | – | – | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | – |
| 2025 | DeepAnalyze | ✅ | – | ✅ | ✅ | – | – | – | – | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 2025 | AOP | – | – | ✅ | ✅ | ✅ | – | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | – |
| 2025 | iDataLake | ✅ | – | ✅ | ✅ | ✅ | – | ✅ | – | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 2024 | Data Interpreter | ✅ | – | – | ✅ | ✅ | – | – | – | ✅ | – | ✅ | ✅ | ✅ | ✅ |
| 2025 | JoyAgent | ❌ | ❌ | ✅ | ✅ | – | – | – | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 2025 | Assist. DS Agent | – | – | ✅ | ✅ | – | – | ✅ | – | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 2025 | TabTab | – | – | ✅ | ✅ | – | – | – | – | ✅ | ✅ | – | ✅ | ✅ | ✅ |
| 2025 | ByteDance Data Agent | – | – | ✅ | ✅ | – | – | – | – | – | ✅ | – | ✅ | ✅ | ✅ |
| 2025 | BigQuery | – | – | ✅ | ✅ | – | – | ✅ | – | ✅ | ✅ | ✅ | ✅ | – | – |
| 2025 | Cortex | – | – | ✅ | ✅ | ✅ | – | – | – | ✅ | ✅ | ✅ | ✅ | ✅ | – |
| 2025 | Xata Agent | – | – | ✅ | ✅ | – | ✅ | ✅ | ✅ | – | – | ✅ | – | – | – |
| 2025 | SiriusBI | – | – | – | – | – | – | – | – | ✅ | – | ✅ | ✅ | – | ✅ |
おわりに
データエージェントの開発は、単なる「対話型AI」から、環境を知覚し行動する「自律型システム」へと急速に進化しています。本記事で解説した通り、現在の実用的なシステムの多くはL1(支援)からL2(部分的自律)への移行期にあります。
エンジニアにとって、L2実現の鍵は「ツール実行結果をフィードバックループに取り入れる設計」にあります。SQLやPythonコードを生成するだけでなく、その実行エラーや中間データをエージェント自身に「見せ」、自律的な修正を促す仕組みが不可欠です。
将来的にはL3(オーケストレーション)以上の高度な自律性が目指されていますが、まずはL2システムの堅牢性を高め、データパイプライン特有の「エラー伝播(Cascading Errors)」を防ぐ信頼性の高い基盤を構築すること。それが、システム開発者がいま取り組むべき最大の課題であり、大きなチャンスでもあります。
More Information
- arXiv:2602.04261, Yuyu Luo, Guoliang Li, Ju Fan, Nan Tang, 「Data Agents: Levels, State of the Art, and Open Problems」, https://arxiv.org/abs/2602.04261
関連記事

プロンプト圧縮技術の比較と最新動向
近年、大規模言語モデル(LLM)は、その高度な自然言語処理能力により、様々な分野で注目を集めています。しかし、LLMの能力を最大限に引き出すためには、詳細な指示や情報を盛り込んだ、長文のプロンプトが必要となるケースが少な […]

2024年、LLM研究の最前線:必読論文総まとめ
大規模言語モデル(LLM)は、もはや一部の研究者や開発者にとどまらず、私たちの生活に身近な存在となっています。文章生成、翻訳、情報検索など、その応用の場は多岐にわたります。 しかし、LLMの進化はそれだけにとどまりません […]

LLMのハルシネーション検出のための不確実性定量化
近年、大規模言語モデル(LLM)は、文章作成、翻訳、質疑応答など、私たちの生活や仕事における様々なタスクでその能力を発揮し、急速に普及しています。その利便性の一方で、LLMには「ハルシネーション(幻覚)」と呼ばれる、事実 […]