XAI (説明可能なAI) の終焉と新たなパラダイム

近年、LLM(大規模言語モデル)やDNN(ディープニューラルネットワーク)などのAI技術が高度化する中で、モデルの「ブラックボックス化」がシステム構築における大きな課題となっています。この不透明性を解消し、AIへの信頼を構築するための手段として、「XAI(Explainable AI:説明可能なAI)」が長らく注目を集めてきました。
しかしながら、現在広く使われているXAIのアプローチには限界が見え始めています。特に、予測結果が出た後に理由を提示する「事後的な説明(Post-hoc explanation)」には、経験的・概念的、そして論理的な根本的欠陥があることが指摘されています。
この記事では、「Beyond Explainable AI (XAI): An Overdue Paradigm Shift and Post-XAI Research Directions」をもとに、現在のXAIが抱える構造的な限界やパラドックスを紐解きます。その上で、モデルの真の信頼性を担保するための新たなアプローチである「Post-XAI」に向けた4つのパラダイムシフトについて解説を進めます。
1. XAIの限界: 実運用で見えてきた課題
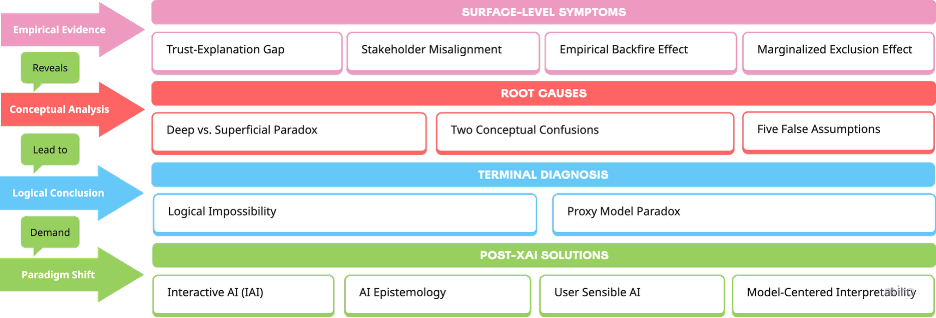
現在のXAIが実際のシステム運用において直面している表面的な症状と、その根底にある構造的な原因を整理します。
1-1. 信頼と説明のギャップ
XAIの主な目的は「エンドユーザーからの信頼を獲得すること」とされてきました。しかしながら、実際の研究では、モデルの透明性が必ずしも適切な信頼の構築に繋がらないことが示されています。
たとえば、不正確な予測を出すモデルに対して尤もらしい「説明」が付与されると、ユーザーの過剰な依存を引き起こし、かえってシステムのエラーを見逃すリスクが高まります。現場の実態としても、XAIは本来のターゲットであるエンドユーザーに向けて機能しているというよりも、MLエンジニアがモデルをデバッグするためのツールとして利用しているケースがほとんどです。
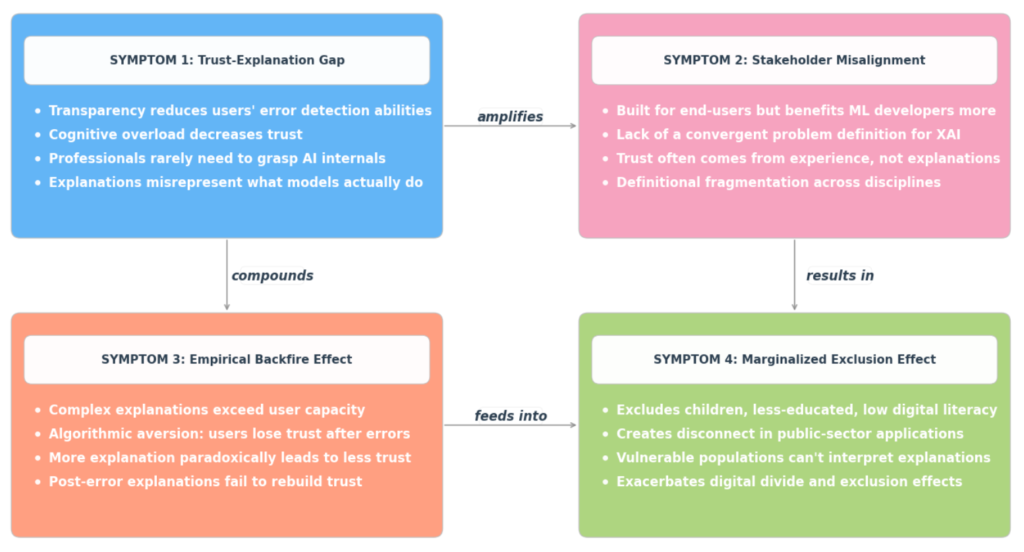
1-2. 「深い/浅い」のパラドックス
XAIには、モデルの複雑な内部プロセスを忠実に再現しようとする「深い説明」と、ユーザーに理解しやすく単純化する「浅い説明」の間に、避けられないジレンマが存在します。
- 深い説明: モデルの実際の推論プロセスを正確に反映しますが、認知的負荷が高すぎてエンドユーザーには理解されません。
- 浅い説明: ユーザーにとっては理解しやすいですが、モデルの真の複雑さを過度に単純化しているため、実際の推論プロセス(忠実性)を反映していないという問題があります。
結果として、現在のXAIは「正確だが理解不能」か、「理解できるが不正確」のどちらかに陥るパラドックスを抱えています。
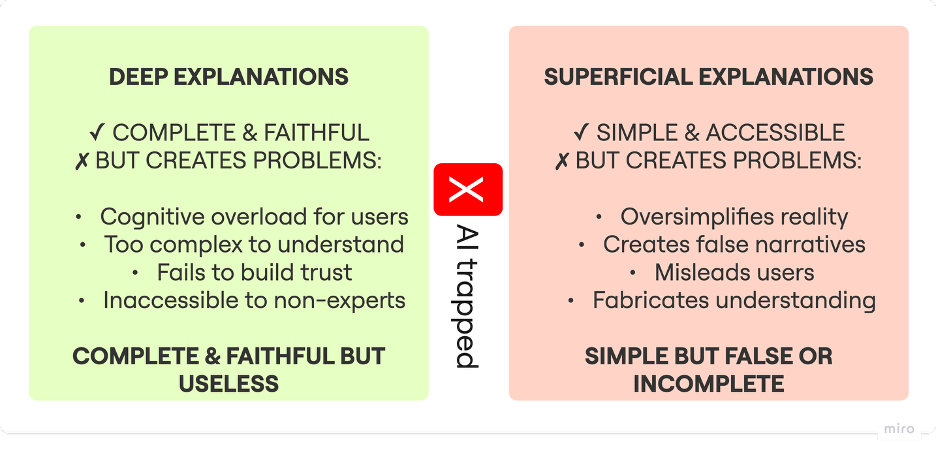
1-3. 相関と因果の混同
XAIツールは、しばしば統計的な「相関」と現実世界の「因果」を混同させます。
代表的な例として、LIMEやSHAPといったツールは、ターゲット予測とは直接的な関連性のない「サプレッサー変数(ノイズ除去のためにモデルが利用する変数)」を、予測に重要な特徴量として強調してしまうことがあります。
XAIが提示しているのは、あくまで「モデル内部でどの変数が統計的に寄与したか」というパターンに過ぎません。それにもかかわらず、「現実世界でその変数が結果を引き起こした(因果関係がある)」かのようにユーザーを誤認させる危険性が潜んでいます。
2. 論理的限界: 代理モデルのパラドックス
XAIが実運用で直面する課題の根底には、単なる精度の問題ではなく、XAIのアーキテクチャそのものが抱える論理的・数学的なパラドックスが存在します。
現在主流となっている事後的なXAIの多くは、ブラックボックスモデル(元のモデル)の挙動を近似するために、別のわかりやすいモデルである「プロキシモデル(代理モデル)」を構築して説明を生成します。しかし、この「元のモデルを別のモデルで説明する」という構造自体が、以下のような逃れられない論理的矛盾(ジレンマ)を引き起こすことが指摘されています。
- 完全な説明が可能な場合(自己消滅のジレンマ): もしプロキシモデルが、元のブラックボックスモデルの複雑な推論プロセスを「完全に忠実」に再現し、説明できると仮定しましょう。その場合、元のモデルの内部構造は完全に解明されていることになります。つまり、元のモデルは最初からブラックボックスではなく「透明なモデル」であり、わざわざXAIを用いて説明を付与する作業自体が不要になります。
- 不完全な説明しかできない場合(無限後退のジレンマ): 逆に、プロキシモデルが元のモデルを完全には再現できず「不完全な説明」しかできない場合を考えてみましょう。この場合、元のモデルとプロキシモデルの間に生じた「ズレ(ギャップ)」がなぜ発生したのかを説明するために、さらに第3のモデルが必要になります。そして第3のモデルも不完全であれば第4のモデルが……というように、説明のためのモデルが延々と必要になる「無限後退」に陥ってしまいます。
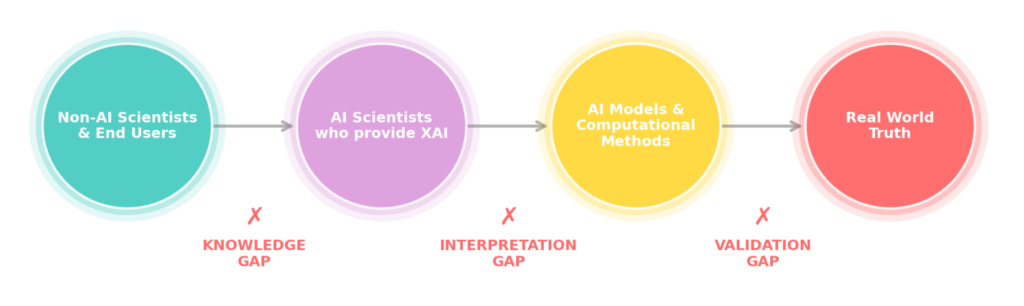
つまり、プロキシモデルを用いたXAIの仕組みは、「成功すれば自分自身の存在意義がなくなり、失敗すれば無限に説明を続けなければならない」という自己矛盾を抱えています。この論理的な限界により、予測結果が出た後に事後的なプロキシモデルを用いて、ブラックボックスの挙動を真の意味で説明することは構造的に不可能であると考えられています。

3. Post-XAIに向けた4つのパラダイムシフト
ここまで見てきたように、現在のXAIが抱える課題は実装レベルのものではなく、構造的なものです。そのため、ブラックボックスを無理に「説明」しようとするアプローチから脱却し、システムの信頼性と安全性を担保するための新たな方向性が求められています。ここでは、「Post-XAI」として提唱されている4つのパラダイムシフトを紹介します。

3-1. Interactive AI (IAI): 「説明」から「対話的検証」へ
Interactive AI (IAI) は、ブラックボックスモデルの不完全な説明をエンドユーザーに提示するのをやめ、ドメイン専門家との相互作用を通じた出力の「検証」に焦点を当てるアプローチです。
分かりやすい例として、医療現場を想像してみてください。患者は処方された薬の複雑な薬理学的メカニズム(いわばブラックボックス)を完全に理解していなくても、専門家である医師による診断と処方を信頼して薬を服用します。
AIシステムの実運用においても同様です。モデルの内部構造を無理に説明するのではなく、出力結果に対して専門家が体系的な検証プロセスを実施したり、対話型のインターフェースを組み込んだりすることで、システム全体としての信頼性を担保していくことに取り組みます。
3-2. AI Epistemology (AIの認識論)
AI Epistemology (AIの認識論) は、現在のAIが出力する結果(統計的なパターンや確率的な推論)が、どのような条件下で科学的に妥当な「知識」として扱えるのかを定義する基礎的なアプローチです。
現在、AIの評価は予測精度やベンチマークのスコアに偏りがちです。しかしながら、実運用においてAIが生成した仮説や知識を安全に利用するためには、それが単なる計算上の副産物なのか、それとも科学的に妥当な推論なのかを検証するための、新たな方法論的・科学的な基準を構築していく必要があります。
3-3. User-Sensible AI (ユーザー適応型AI)
現在のXAIは、すべてのユーザーに対して統一された「普遍的な説明」を提供しようとして失敗するケースが目立ちます。これに対してUser-Sensible AI (ユーザー適応型AI) は、普遍的な説明の提供を放棄し、ユーザーの属性やコンテキストに合わせた適応型のシステムを構築することを目指します。
- コンテキストへの適応: 対象ユーザーの認知レベルや専門知識に合わせて、コミュニケーションのスタイルやインターフェースを調整します。
- 専門家の介在: AIが直接ユーザーに説明するのではなく、小児科医や専門のコミュニケーターなど、適切な専門家を介在させる経路を設計します。
このように、様々なユーザーコミュニティに合わせて、専門家が仲介する実践的なアプローチを進めることが重要です。
3-4. Model-Centered Interpretability (モデル中心の解釈可能性)
最後に、これまでXAIが培ってきた技術をどう扱うかという視点です。Model-Centered Interpretability (モデル中心の解釈可能性) では、LIMEやSHAP、Attentionの可視化といった既存のXAIツールを「現実世界の因果関係を説明するツール」として扱うことをやめます。そして、MLエンジニア向けの「技術的なモデル解析ツール」として明確に再定義します。
具体的には、エンドユーザーへの説明責任を果たすためではなく、以下のような開発環境での用途に特化して活用を進めます。
- モデルのバグやエラーの特定
- トレーニング時の動態の理解
- セーフティガードレールの構築
- モデル挙動のリアルタイムな制御 (Steering)
XAIツールが持つ本来の技術的な価値を正しく評価し、ML開発者がモデルを改善・制御するためのツールとして割り切って利用することが推奨されています。
4. MLシステムの構築・運用においてのアプローチ
ここまでの解説を踏まえ、MLエンジニアが実際のシステム構築・運用において取り組むべき具体的なアプローチを3つの視点で提示します。
- XAIツールの用途を限定する: LIMEやSHAPといったXAIツールが算出する「特徴量重要度」などの出力を、ビジネスサイドやエンドユーザーに対して「AIの判断理由(現実世界の因果関係)」としてそのまま提示することは避けてください。これらはあくまでモデル内部の統計的な相関に過ぎません。XAIツールは、開発時のデバッグや異常検知、トレーニング動態の理解など、エンジニア向けの技術的な解析ツールに限定して活用を進めることが推奨されます。
- 「説明」よりも「検証プロセス」を設計する: システムの信頼性を高めるために、不完全な「事後的な説明」をエンドユーザーに提示するアプローチから脱却し、専門家が介在する「検証プロセス」の設計に注力してください。具体的には、システムアーキテクチャの中に、Human-in-the-Loopのようなドメイン専門家(医師や専門オペレーターなど)と連携する対話型インターフェースや、出力結果に対する体系的な監査証跡(監査トレール)の仕組みを組み込むことが有効です。
- 本質的に解釈可能なモデルの検討: 医療や金融、司法など、リスクの高い意思決定が求められる領域では、複雑なブラックボックスモデルを採用して後からXAIを付け足すという設計自体を見直す必要があります。このようなケースでは、決定木などの手法や、Concept Bottleneck Models (CBMs) といった、最初から内部構造が透明な「本質的に解釈可能なモデル(Intrinsic Interpretability)」の採用を優先的に検討してください。
おわりに
これまで見てきたように、予測が出た後に事後的な説明を付与することでブラックボックスの透明性を確保しようとする従来のXAIアプローチは、論理的・概念的な矛盾を抱えています。そのため、AIへの信頼構築に対する考え方は、根本的な見直しが必要な時期に来ていると言えます。
これからのMLエンジニアは、「AIがなぜその結論に至ったのかを、専門外のエンドユーザーに完璧に説明する」という、構造的に不可能なタスクから解放されるべきです。代わりに、ドメイン専門家による出力の対話的な検証プロセス(Interactive AI)をシステムに組み込むことや、開発者自身のデバッグに向けた精緻な内部解析(モデル中心の解釈可能性)を進めることへと、注力する領域をシフトしていくことが求められます。
より実務的で科学的なアプローチを取り入れることで、本当に信頼できるMLシステムの構築を進めていきましょう。
More Information
- arXiv:2602.24176, Saleh Afroogh et al., 「Beyond Explainable AI (XAI): An Overdue Paradigm Shift and Post-XAI Research Directions」, https://arxiv.org/abs/2602.24176
関連記事

GPyTorch ではじめる深層ガウス過程入門
ガウス過程(GP: Gaussian Process)は、関数そのものに確率分布を定義するノンパラメトリックなモデルです。このモデルの最大の強みは、単なる予測値だけでなく、その不確実性(信頼区間)を定量的に示せる点にあり […]

Code as Agent Harness: AIエージェントを自律駆動させるためのアーキテクチャ
LLM(大規模言語モデル)の進化により、AIエージェントの開発が急速に進んでいます。しかし、複雑なタスクを長期間にわたって自律的に実行させるには、自然言語による指示だけでは限界があります。 現在、LLMにとって「コード」 […]

LLMによるソフトウェアテストの現状とこれから
ソフトウェアテストは、ソフトウェアエンジニアリングにおける基本的な要素であり、プロジェクト予算の15~80%もの割合を占めることがあります。この数値が示す通り、テスト工程はソフトウェアの品質と信頼性を保証する上で極めて重 […]