大規模言語モデルのためのエージェント推論
従来の大規模言語モデル(LLM)は、入力に対して静的にテキストを予測・生成するシステムとして機能してきましたが、情報が絶えず変化する動的な環境下では、その対応力に限界がありました。現在、この課題を突破する鍵として「エージェント推論(Agentic Reasoning)」が注目されています。
これは、LLMを受動的なテキスト生成器ではなく、自律的に計画を立て、ツールを駆使し、環境との相互作用を通じて学習する「エージェント」として再定義するパラダイムシフトです。単なる出力の生成から、行動とフィードバックを伴うプロセスへと推論の定義を拡張することで、システムの信頼性やタスク遂行能力は飛躍的に向上します。
本記事では、このエージェント推論を支える技術的構成要素から、自己進化のメカニズム、そして実装に向けた戦略までを体系的に解説します。
1. エージェント推論の基礎:思考と行動の統合
エージェントが単独でタスクを完遂するためには、抽象的な思考を具体的な行動へと変換する基盤が必要です。ここでは、その核となる3つの主要機能について解説します。
- 計画(Planning): 複雑なタスクを管理可能なサブタスクに分解し、実行順序を決定するプロセスです。推論時に「思考の連鎖(Chain of Thought)」や「ReAct」のようにプロンプトで制御する手法と、事後学習によって計画能力自体をモデルに内包させる手法が存在します。これにより、モデルは長期的なゴールを見失うことなく、必要に応じて以前のステップに戻って再考するなど、柔軟にタスクを進行できます。
- ツール利用(Tool Use): 外部APIや計算機を呼び出し、モデル内部の知識不足や計算能力の限界を補完する機能です。単にツールを呼び出すだけでなく、「いつ」「どの」ツールを選択すべきか、適切なパラメータは何か、そして実行結果は妥当かを推論ループの中で検証します。外部環境からのフィードバックを推論に統合することで、ハルシネーションを低減し、事実に基づいた信頼性の高い回答生成を実現します。
- エージェント検索(Agentic Search): 従来のRAG(検索拡張生成)が一回限りの検索で回答を生成するのに対し、エージェント検索ではモデル自身が「いつ」「何を」検索すべきかを自律的に判断します。検索結果が不十分であればクエリを修正して再検索を行うなど、動的な情報収集プロセスを通じて、静的な検索では得られない精度の高い回答を導き出します。
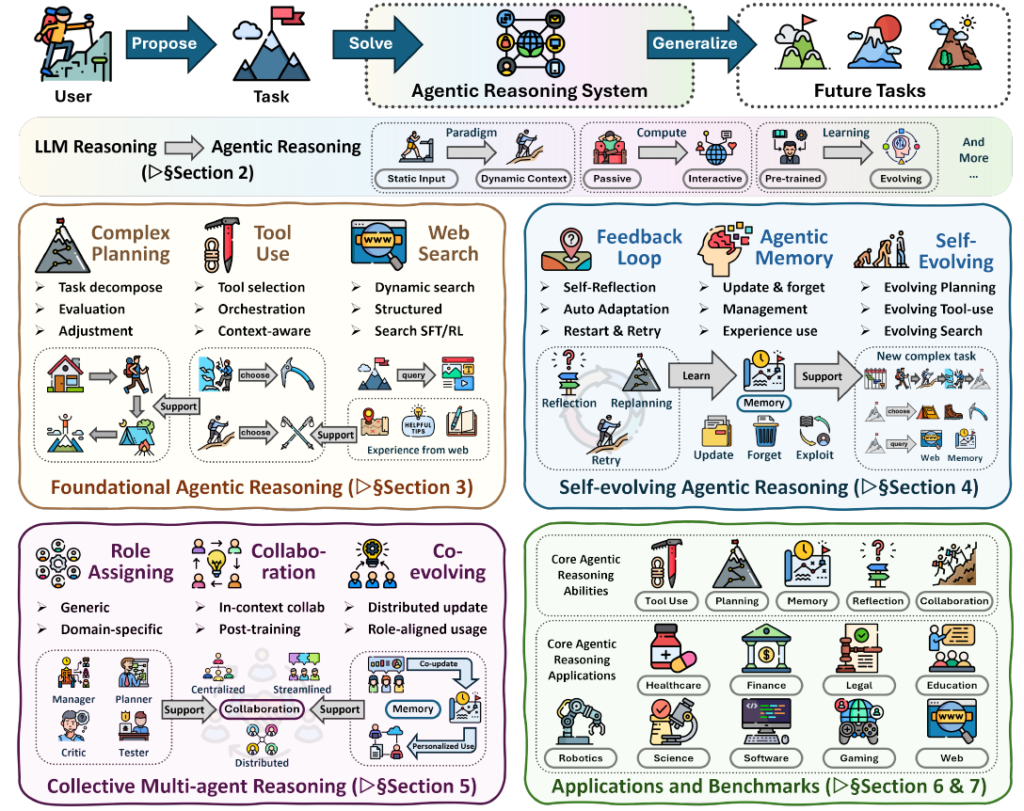
2. 自己進化するエージェント:フィードバックとメモリ
基礎的な能力(計画・ツール・検索)を備えたエージェントが、環境からのフィードバックと過去の経験(メモリ)を活用することで、どのように適応・進化するのかを解説します。静的な推論から、経験を通じて継続的に改善するシステムへの転換点となります。
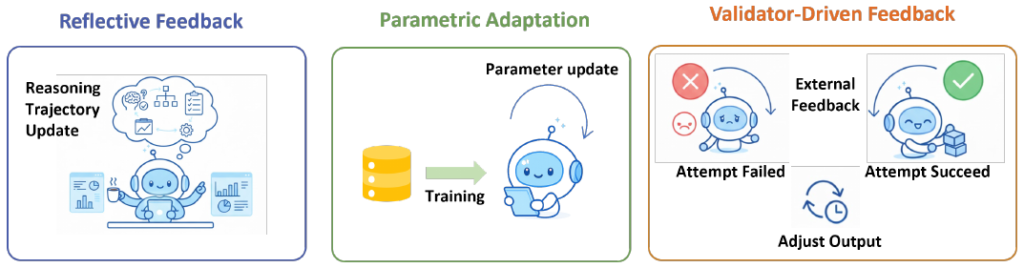
- フィードバック機構(Feedback Mechanisms): 単発の出力で終わらせず、結果を評価して修正するループを構築します。
- 反省的フィードバック(Reflective Feedback): 推論時に「自己批判(Self-Critique)」や検証を行い、動的に軌跡を修正する手法です。パラメータ更新を伴わずに、即座に推論精度を高められます。
- パラメータ適応(Parametric Adaptation): 成功した推論プロセスやツール利用のパターンを、強化学習(RL)や微調整(SFT)を通じてモデルの重みに反映させ、恒久的な能力向上を図ります。
- 検証駆動(Validator-Driven): コード実行時の単体テストやシミュレータからの成否判定(バイナリ信号)に基づき、成功するまで再試行(Retry)を行う実用的なアプローチです。
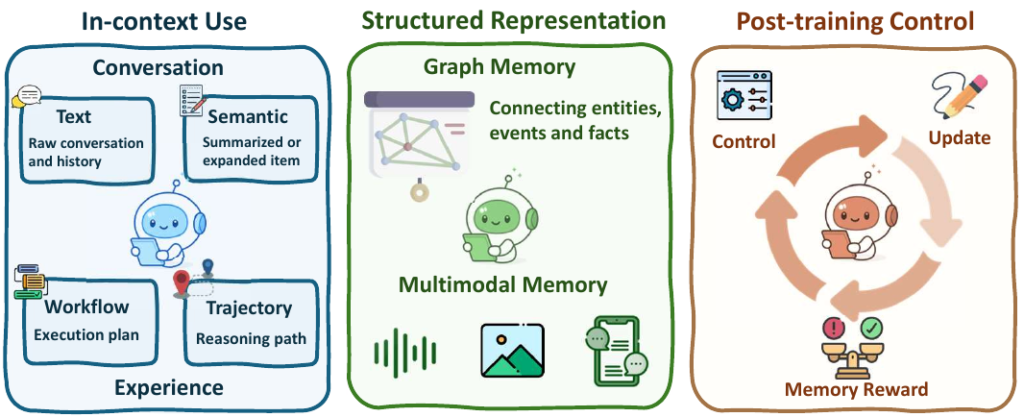
- エージェントメモリ(Agentic Memory): 単なるコンテキストウィンドウの拡張やログの保存ではなく、推論を支援するための能動的な記憶システムです。
- 構造化と検索: 過去の対話や成功体験を、単なるテキスト(Flat Memory)としてだけでなく、ナレッジグラフや階層構造(Structured Memory)として保存し、タスクの文脈に合わせて動的に検索・活用します。
- 能動的な管理: エージェント自身が「何を記憶し、何を忘れるか」を判断する制御機能(Memory Control)を持たせることで、情報の取捨選択を行い、長期的なタスクでも一貫性を維持します。
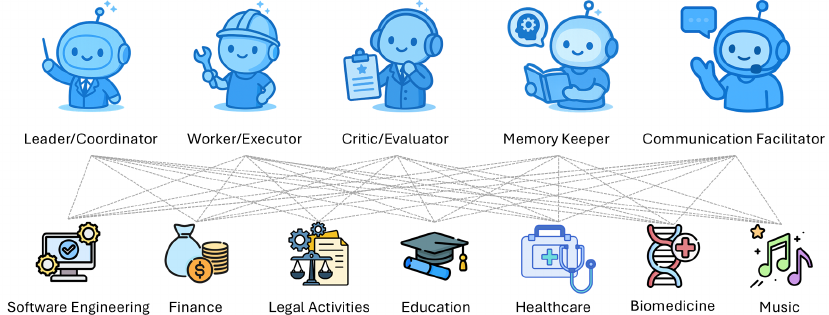
3. マルチエージェントシステム:役割分担と協調
単一のエージェントでは対応しきれない複雑なタスクにおいて、複数のエージェントが連携して解を導く「集合的な推論(Collective Reasoning)」が新たな標準となりつつあります。ここでは、個々のLLMを組織の一員として機能させ、相乗効果を生み出すための仕組みについて解説します。
- 役割の専門化(Role Specialization): タスクを遂行するために、各エージェントに明確な役割と権限を与え、分業体制を構築します。
- リーダー/コーディネーター: 全体目標を管理可能なサブタスクに分解し、適切な作業者に割り振る司令塔の役割です。
- 作業者(Executor): コード生成、文書作成、ツール利用など、具体的な実務を担当します。
- 批評家(Critic/Evaluator): 作業者の出力に対して検証を行い、論理エラーや安全性の問題を指摘します。生成と評価を分離することで、ハルシネーションのリスクを大幅に低減できます。
- メモリ管理者(Memory Keeper): チーム全体の長期的なコンテキストやナレッジを維持し、エージェント間の情報共有を支援します。
- 協調と議論(Collaboration & Discussion): 単なる作業のリレーではなく、エージェント間の相互作用を通じて推論の質を高めます。
- 動的な議論: エージェント同士が推論結果を提示し合い、議論や交渉(Debate)を行うことで、単独の視点では気づけない誤りを修正し、合意形成を図ります。
- ワークフローの制御: 事前に定義されたパイプラインに従って順次処理する手法(Cascading)に加え、タスクの状況に応じて動的に次のエージェントを選定・ルーティングする柔軟なオーケストレーションも可能です。
4. 実装戦略:インコンテキストと事後学習
システム構築の観点から、エージェントの推論能力を実現するためのアプローチは、大きく「推論時のオーケストレーション」と「モデル自体の学習」の2つに大別されます。これらは相互排他的なものではなく、補完的な関係にあります。
- インコンテキスト推論(推論時のオーケストレーション): モデルのパラメータを凍結したまま、プロンプトエンジニアリングや検索メカニズムを用いて推論プロセスを制御するアプローチです。具体的には、ReActのように思考と行動を交互に生成させたり、Tree of Thoughts (ToT) のように探索アルゴリズムを用いて最適な推論パスを選択させたりします。 この手法は実装コストが低く、プロンプトの調整のみで柔軟に挙動を変更できるため、迅速なプロトタイピングや、ルールが頻繁に変わる動的な環境に適しています。
- 事後学習(Post-training): 強化学習(RL)やファインチューニング(SFT)を用いて、エージェント特有の思考パターンやツール利用能力をモデルの重み自体に内包させるアプローチです。成功した推論の軌跡を教師データとしたSFTや、GRPO(Group Relative Policy Optimization)などの強化学習アルゴリズムを用いて、長期的な報酬を最大化するようにモデルを最適化します。 この手法は、特定のタスクにおける性能を大幅に向上させるだけでなく、推論時のトークン消費を抑えた効率的な動作が可能となるため、実運用において高い信頼性とコスト効率が求められる場合に有効です。

おわりに
エージェント推論は、LLMを受動的なテキスト生成から、環境と相互作用する能動的な問題解決へと進化させるパラダイムシフトです。計画、ツール利用、フィードバックによる自己進化、そしてマルチエージェント協調を統合することで、従来のモデルでは困難だった長期的かつ複雑なタスクの遂行が可能になります。
技術の実装が進む一方で、今後はユーザーごとの文脈に適応するパーソナライゼーションや、数日以上にわたる長期的なインタラクションへの対応、そして実世界での安全な運用のためのガバナンス構築が重要な課題となります。静的な推論から、行動と適応を伴う動的な推論への転換は、AIシステムの実用性を次の段階へと引き上げる核心となります。
More Information
- arXiv:2601.12538, Tianxin Wei et al., 「Agentic Reasoning for Large Language Models」, https://arxiv.org/abs/2601.12538
関連記事

TabNet: 表形式データ向け深層学習モデル
ディープラーニングは画像やテキストなどの分野で大きな成功を収めていますが、表形式データにおいては未だに決定木をベースにしたブースティング手法が主流です。しかし、表形式データは実世界において最も一般的なデータであり、ディー […]

進化する機械学習とは?
従来の機械学習モデルは、データの特徴が時間の経過とともに変化しないという前提で動いています。しかし、現実の世界ではそうはいきません。データは常に変化し、ユーザーの行動も、周りの環境も移り変わっていくからです。進化する機械 […]

Lightlyで実践 - 自己教師あり学習入門
近年、機械学習プロジェクトで扱うデータ量は増大し続けています。しかし、その膨大なデータすべてに手作業でアノテーション(教師ラベル付け)を行うのは、コストと時間の面で大きな課題です。この「アノテーションの壁」を乗り越える技 […]