AstroAlertBench: マルチモーダルLLMによる天体分類の現在地

現在の天文学の最前線では、ZTF (Zwicky Transient Facility) などの大規模な観測プロジェクトによって、毎晩数百万件もの天文アラート(突発天体などの観測通知)が生成されています。しかし、データ量が膨大すぎるため、専門家による手動の確認作業はすでに限界を迎えています。
この課題に対処するため、ALeRCEやBTSbotといった既存の機械学習システムが活用されていますが、これらには大きな弱点があります。それは、分類精度は高いものの、なぜその分類に至ったのかという「解釈可能な科学的根拠」を出力できない「ブラックボックス」であるという点です。
そこで新たな解決策として、画像とテキストを同時に処理できるマルチモーダルLLM (MLLMs: Multimodal Large Language Models) に期待が集まっています。しかしながら、実運用に向けては、商用APIの高コストと、オープンモデルにおける専門知識の不足という2つの大きな壁が存在します。
この記事では、実際の天文データを用いてLLMの推論能力とAIの「正直さ」を測る新たな評価フレームワーク「AstroAlertBench」を取り上げ、天体分類におけるAIの現在地と最新の知見を解説します。
1. AstroAlertBenchの概要
AstroAlertBenchは、実際の天体観測データを用いて、マルチモーダルLLMが天文学の「科学的アシスタント」としてどの程度実用できるかを測るために構築された包括的なベンチマークです。この評価フレームワークでは、ZTF (Zwicky Transient Facility) の観測ストリームから取得した1,500件の初回検出アラートの実データを使用し、GPTやClaude、Qwenなど13種類の最先端モデルをテストします。
AIに精度の高い天体分類を促すため、AstroAlertBenchでは画像とテキストを組み合わせた「マルチモーダル」な情報をモデルに入力します。具体的には、以下の2つのデータがセットで提示されます。
- 3つの画像ストリップ (Image Triplet): 天体の状態を視覚的に捉えるため、以下の3種類の画像を1つの画像ストリップとして水平にタイリング(結合)して入力します。
- Science (最新画像): 今回新たに観測された天体の画像
- Reference (参照画像): 過去の観測に基づく、その場所のベースラインとなる画像
- Difference (差分画像): 最新画像から参照画像を差し引き、変化した部分だけを抽出した画像
- 19項目のアラートメタデータ: 画像に加えて、ZTFのアラートパケットに含まれる19項目の数値やテキストデータが併用されます。これには、天体の明るさを示す測光属性や、過去にその場所で何回検出されたかを示す履歴情報が含まれます。画像単体からは読み取れない空間的・履歴的なコンテキストを補完することで、より専門的な判断を可能にしています。
さらに、このベンチマークでは実データ特有のノイズに対する対策も徹底しています。実際の観測データには、有効な測定値が得られなかったことを示す「センチネル値(-999などの欠損値)」が含まれることがあります。汎用的なLLMがこの「-999」を、物理的なマイナスの数値として誤って解釈しないように、プロンプト(AIへの指示文)内で厳密なルールを設けています。
このように、単に画像を読み込ませるだけでなく、様々な観測データと厳格なルールを組み合わせることで、実際の天文学者が日々の研究で直面する状況に近い評価環境を実現しています。

2. 3段階の論理チェーンによる評価プロセス
AIを科学的な問題解決に活用する際には、単に最終的な正解ラベルを当てる「結果ベースの指標」だけでは不十分です。仮にAIが間違えた場合、どこで思考を誤ったのかというエラーの原因を特定できるよう、「段階的な評価論理」への移行が不可欠になります。
そこでAstroAlertBenchでは、AIの思考プロセスを以下の3段階の論理チェーンに分解して評価を実施します。
第1段階: メタデータの認識 (Metadata Grounding)
最初のステップでは、AIが測光フィルターやマグニチュードといった観測パラメータの数値を正確に読み取れるかをテストします。
この段階の真の目的は、単なる文字認識の精度を測ることではありません。ここで確実にデータを認識させることで、後続の推論でエラーが起きた際、その原因を「データ認識(Perception)の失敗」から完全に切り離すことを狙いとしています。実際に今回のベンチマークテストでは、評価対象となった13種類のAIモデルすべてが100%の認識精度を達成しています。
第2段階: 科学的根拠の構築 (Scientific Rationale)
次に、AIが提示した分類の「根拠」を評価します。モデルは単に答えを出すだけでなく、以下の3要素を言語化して出力する必要があります。
- 重要な証拠 (Key Evidence): 画像やデータから読み取れる事実
- 主要な解釈 (Leading Interpretation): 証拠から導かれる最も有力な仮説
- 代替の分析 (Alternative Analysis): 他の可能性についての考察
さらにAIは、自分が記述したこれら3要素の質を0〜5のスケールで自己採点します。この自己評価は、「平均自己推論スコア (MSRS: Mean Self-Reasoning Score)」として以下の数式で定量化されます。
$$\text{MSRS} = \frac{1}{n} \sum_{i=1}^n \bar{s}_i$$
ここで \(n\) は評価したデータの総数、\(\bar{s}_i\) は各データに対してAIがつけた自己評価スコアの平均値を指します。 この数式により、AIが自身の推論に対してどの程度自信を持っているか(あるいは謙虚であるか)を、客観的な数値として比較できるようになります。
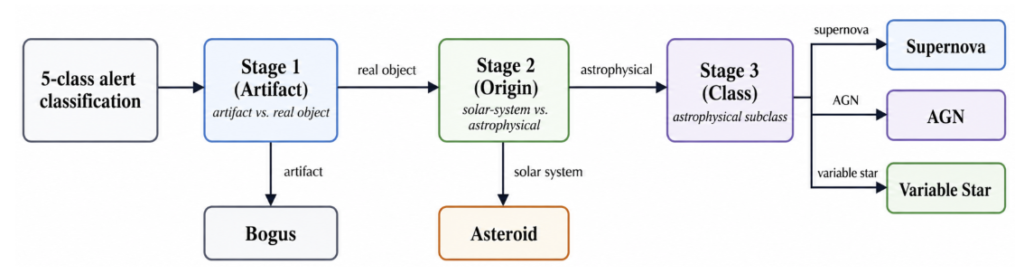
第3段階: 階層的分類 (Staged Classification)
最後のステップとして、AIは最終的な天体の分類に挑みます。いきなり具体的な天体名を当てるのではなく、以下の3ステップの決定ツリーに沿って段階的に分類を進めます。
- 実態の判定: 観測機器のエラーなどの「人工物 (Artifact)」か、実際の「実天体 (Real Object)」かを区別する。
- 起源の特定: 実天体の場合、それが小惑星のような「太陽系内の天体 (Solar System)」か、より遠くの「宇宙物理学的な天体 (Astrophysical)」かを見分ける。
- サブクラスの分類: 宇宙物理学的な天体であれば、さらに「超新星 (Supernova)」「変光星 (Variable Star)」「活動銀河核 (AGN)」のいずれに該当するかを特定する。
このように思考プロセスを細分化することで、AIが単純な認識タスクで失敗したのか、それとも高度な宇宙物理学の知識でつまづいたのかを、詳細に分析することが可能になります。
3. LLMの分類精度と推論モード
AstroAlertBenchを用いた評価から、最新のLLMが天体分類において人間の専門家にどこまで迫れるのか、そしてどのような限界があるのかが明らかになってきました。
大規模モデルによる「人間超え」と前提条件の違い
テストの結果、Claude Opus 4.7などの一部の大規模モデルは、最終的な分類精度(約60.6%)において、人間の専門家チームによるアンサンブル(多数決)精度(約26.7%)や、最も成績の良かった個人の専門家(約46.7%)を上回る成績を残しました。
ただし、この結果を解釈する際には、人間とAIの「前提条件の違い」に留意する必要があります。人間の専門家は、データが不十分な場合に「判断保留(Don’t Know: DK)」を選択できます。つまり、専門家は曖昧なデータに対して「わからない」と正直に認める(Calibrated refusal)ことができるのに対し、今回のベンチマークにおいてAIモデルは強制的にいずれかのクラスを選択させられているという点です。
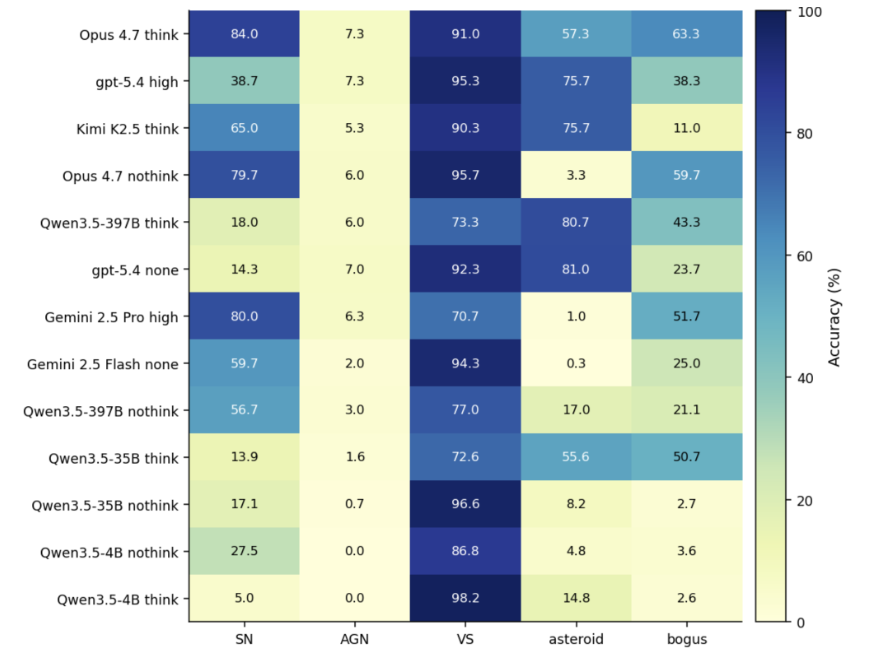
AIの共通の弱点:AGNと変光星の混同
詳細な分類結果を見ると、全モデルに共通する弱点も浮き彫りになりました。それは、活動銀河核(AGN)と変光星の混同です。実際のAGNデータのうち、およそ91〜93%が変光星として誤分類され、AGNの正答率は全モデルで8%未満にとどまりました。
これはAIの純粋な知識不足というよりも、入力データの制約が主な原因だと考えられます。数週間から数ヶ月にわたる「光度曲線」のような時間的な変化の文脈が不足している状態では、単発の画像やわずかなメタデータだけで両者を区別することは非常に困難です。
「思考の連鎖(Chain-of-Thought)」とモデル規模の相性
モデルが最終的な答えを出す前に段階的な推論を挟む、「思考の連鎖(Chain-of-Thought)」と呼ばれる推論モードの効果についても重要な発見がありました。モデル内部でこの推論プロセスを有効にした場合、分類精度の向上幅は「モデルのパラメータ規模(基礎的な推論能力)」に大きく依存します。
- 超大規模モデル: Claude Opus 4.7やGPT-5.4などでは、推論モードによって精度が7〜11%以上も有意に向上しました。
- 中規模モデル: 精度はほぼ変わらず、推論にかかるコストとメリットが相殺される結果となりました。
- 小規模モデル: 逆に精度が大幅に悪化(約14%低下)するケースが確認されました。
つまり、「じっくり考えさせる」アプローチは万能な魔法ではなく、基礎的な能力が十分に高いモデルに適用して初めて、大きな精度向上に貢献すると言えます。
4. AIの「正直さ」
AIを天文学の科学アシスタントとして現場で活用する上で、分類の精度と同じくらい重要なのが「正直さ (Honesty)」です。ここでいう正直さとは、AI自身の「自信(自己評価スコア)」と「実際のパフォーマンス」がどれだけ一致しているかを指します。日々の膨大な観測データに対処する実運用においては、AIが自信満々に間違った答えを出してしまうのが最も危険なためです。
AstroAlertBenchでは、このAIの正直さを以下の3つの観点から検証しています。
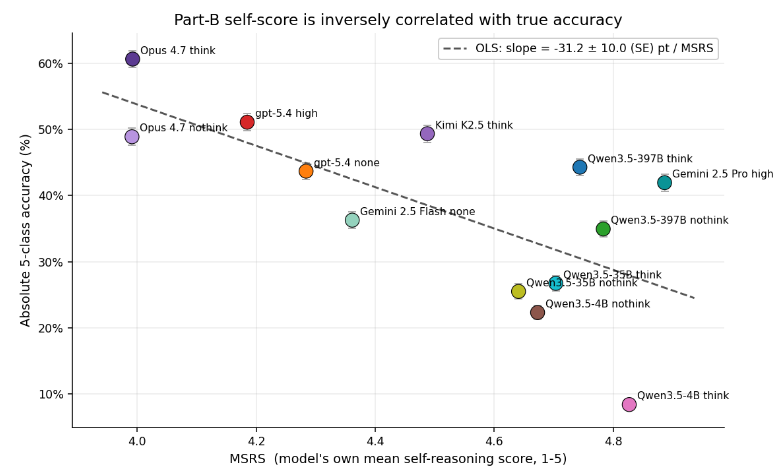
- マクロな傾向と「謙虚さ」 (Modesty): AIが自ら算出した平均自己推論スコア (MSRS) を分析した結果、非常に興味深い傾向が見えてきました。それは、分類精度の高い優秀なモデルほど、集団レベルでは自己評価を低く(謙虚に)つけるという逆相関の関係です。逆に、精度がそれほど高くない小規模なモデルほど、自身の推論に対して満点に近いスコアをつけて過信してしまう傾向がありました。
- 自己修正挙動の違い: AI自身が「自信がない」と低く評価したデータに対して、あえてもう一度推論をやり直させる(再試行)実験を実施しました。その結果、モデルによって自己修正のプロセスに大きな違いが出ることが確認されています。
- Claude Opus 4.7: 最初の正解を維持したまま、間違っていた分類だけを正しく修正するという、非常に有効なリカバリー能力を発揮しました。
- Gemini 2.5 Flash: 出力する分類の答え自体は一切変えないまま、「自信(自己スコア)だけをインフレさせる」という実用上リスクのある特異な挙動を示しました。
- 代替仮説の有用性 (Alternative-reasoning advantage): モデルに対して、一番有力な解釈だけでなく「別の視点からの代替仮説」もあわせて記述させたところ、推論の質そのものが大きく向上することがわかりました。人間の専門家がAIの記述を評価した際、「完全に正しい推論」と判定された割合が、約23%から約44%へと劇的に増加したのです。これは、AIに対して強制的に様々な視点から考えさせることが、結果的に推論の質を引き上げる強力なアプローチになることを示唆しています。
おわりに
今回のAstroAlertBenchによる評価から、マルチモーダルLLMはメタデータを正確に読み取り、一部で専門家を上回る分類精度を示すなど、天文学における日々のトリアージ(優先順位付け)を革新する大きなポテンシャルを持つことがわかりました。
しかし一方で、AIが自身の誤りを認識できず「自信満々に間違えるモデル」をそのまま実運用に組み込むことは非常に危険です。これは、天文学者にとって貴重で限られた追観測 (Follow-up) リソースの無駄遣いにつながる重大なリスクとなるためです。
今後の研究では、光度曲線のような時系列データを統合して分類精度をさらに高めることが求められます。それに加えて、LLMを単なる情報抽出器として扱うのではなく、外部のカタログを自律的に照会して仮説検証を進める「自律型エージェント (Autonomous Agents)」へと進化させていくことが、次なる重要なステップとなります。
More Information
- arXiv:2605.05573, Claire Chen et al., 「AstroAlertBench: Evaluating the Accuracy, Reasoning, and Honesty of Multimodal LLMs in Astronomical Classification」, https://arxiv.org/abs/2605.05573
関連記事

The Multimodal Universe: 天文学向け大規模機械学習用ビッグデータ
天文学は、その観測対象の広大さと複雑さから、常に膨大なデータを扱う分野です。近年、技術の進歩に伴い、画像、スペクトル、時系列データなど、多種多様な形式のデータが取得できるようになりました。これらのデータを統合的に解析する […]

反証可能性の壁:LLMは科学的研究を促進させるのか?
近年、GPT-5などの最先端モデルが、数学や物理、生物学といった様々な分野で新たな知見を生み出し、人間レベルの知能を示しているという報告が相次いでいます。モデルが複雑な課題を解き、科学の研究プロセスを大幅に加速させる様子 […]

宇宙物理学×深層学習:基礎アーキテクチャからAIエージェントまでを概観する
現代の天文学は、Vera C. Rubin天文台やRoman宇宙望遠鏡などに代表される次世代の観測サーベイの稼働により、かつてない規模のデータ主導型科学へと急激に移行しています。こうした膨大なデータを前にして、従来の解析 […]