Efficient-SAM2: セグメンテーションの高速化と効率化

Segment Anything Model 2 (SAM2) は、画像や動画のセグメンテーションにおいて非常に強力な性能を発揮する基盤モデルです。すでに実務でMLシステムへ組み込もうと検討された方も多いのではないでしょうか。
しかし、実際の運用を想定すると「計算コストの高さ」という大きな壁にぶつかります。SAM2は大規模な画像エンコーダや、過去のフレーム情報を保持するメモリ機構に強く依存しています。そのため、推論にかかるレイテンシが大きく、リアルタイムの動画処理などへ適用するのは容易ではありません。
今回解説する「Efficient-SAM2」は、この課題を解決するための新しい手法です。人間の視覚が重要な部分にだけ注意を向けるように、モデル内部の「疎な(Sparse)知覚パターン」に着目し、計算の冗長性を排除しています。
これにより、精度をほとんど落とさずに推論の大幅な高速化を実現しました。今回は、専門外のエンジニアの方にも直感的に理解いただけるよう、Efficient-SAM2のアーキテクチャの仕組みから、Pythonを用いた具体的な実装例までを解説します。
1. SAM2のアーキテクチャと計算上の課題
SAM2の推論パイプラインは、主に以下の3つのモジュールから構成されています。
- 画像エンコーダ: 入力された画像や動画フレームから、様々なスケールで特徴を抽出します。
- メモリ注意(Memory Attention): 過去のフレーム情報を保持する「メモリバンク」を参照し、時間的なつながりを加味した特徴へと変換します。
- マスクデコーダ: ユーザーからのプロンプト(クリックや枠指定など)と上記の特徴を掛け合わせ、最終的なセグメンテーションマスクを生成します。
動画セグメンテーションにおいて非常に強力な仕組みですが、処理を追っていくと、2つの大きな「計算の無駄」が潜んでいることが分かります。
① 画像エンコーダにおける「背景計算」の無駄: 後段のマスクデコーダは、ユーザーが指定した対象オブジェクトにしっかりと注意(Attention)を向けています。しかし、前段にある画像エンコーダは、「これから何に注目すべきか」をまだ知らされていません。そのため、対象外である背景領域に対しても全力で特徴抽出を実施してしまい、膨大な計算リソースを消費しています。例えるなら、被写体が決まっているのに、常に風景の隅々まで細かく分析し続けているような状態です。
② メモリ注意における「全トークン参照」の無駄: 動画には時間的な連続性があるため、メモリバンク内で本当に役立つ情報(顕著性: Saliency)は、ごく一部のトークンに偏って分布しています。さらに、どのトークンが重要かというパターンは、数フレームにわたって一貫していることがほとんどです。それにもかかわらず、SAM2は新しいフレームが来るたびに、毎回メモリ内のすべてのトークンに対して計算を繰り返しています。これは、すでに重要なページに付箋を貼ったノートを、毎回1ページ目から隅々まで読み直しているような非効率さを生んでいます。
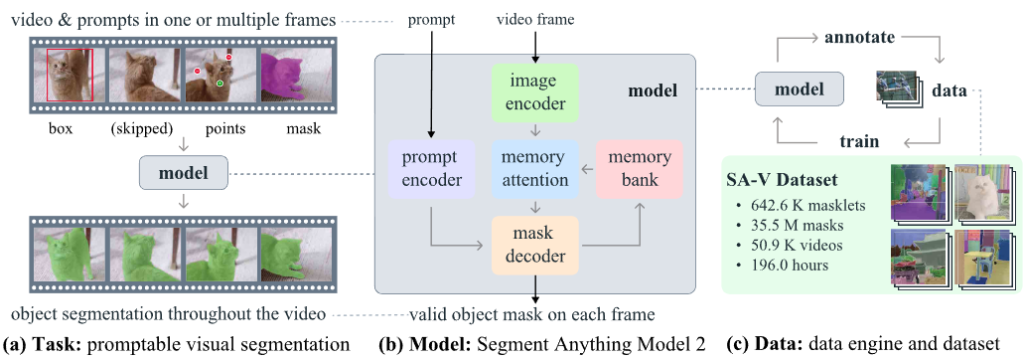
2. Efficient-SAM2のアーキテクチャ
前章で触れた2つの「計算の無駄」を解消するために、Efficient-SAM2は元のアーキテクチャを大きく変えることなく、事後学習(Post-training)によって推論を最適化するフレームワークを採用しています。大規模な再学習を必要としないため、実運用への導入ハードルが低いのもエンジニアにとって嬉しいポイントです。
具体的には、主に以下の2つのモジュールを導入して計算を効率化しています。
- Sparse Window Routing (SWR) ‐ 画像エンコーダの最適化: SWRは、画像エンコーダの処理をウィンドウ(領域)単位で割り振る仕組みです。1つ前のフレームで対象オブジェクトがどこにあったかという予測や、どこに注意が向いていたかという情報(空間的・時間的な一貫性と顕著性の手がかり)を活用します。そして、オブジェクトに無関係な「背景」と判断されたウィンドウは、通常よりパラメータ数の少ない軽量な「ショートカットブランチ」へとルーティングします。真面目に計算しなくてもよい背景領域を簡単な処理で済ませることで、エンコーダの冗長性を大幅に削減します。
- Sparse Memory Retrieval (SMR) ‐ メモリアテンションの最適化: SMRは、メモリ内の重要な情報(顕著性パターン)だけを抽出して計算を効率化する機構です。あるメモリフレームが初めて参照されたタイミングで、「どのトークンが重要か」を計算してキャッシュしておきます。動画において重要な領域は急には変わらないため、次のフレーム以降はそのキャッシュしたパターンを再利用し、本当に必要なトークンのみを計算に参加させます。毎回1から探し直す手間を省くことで、メモリ処理の計算負荷を大きく引き下げます。
以上の工夫により、Efficient-SAM2はモデルの精度をほとんど犠牲にしません。実際に、様々な評価データセットにおいて優れた結果を残しており、SA-Vデータセットでは約1%のわずかな精度低下に抑えながら、SAM2.1-Lモデルで約1.68倍〜1.80倍の推論高速化を実現しています。
Efficient-SAM2は人間の視覚のように「対象にフォーカスし、背景は流し見する」といったメリハリをつけて情報を処理することで、システムとしての効率を飛躍的に高めています。

3. Efficient-SAM2のユースケース
Efficient-SAM2の高速化技術は、実際のMLシステムにおける様々な課題解決に直結します。ここでは、代表的なユースケースを3つご紹介します。
- リアルタイム動画トラッキング: 動画内の特定オブジェクトを継続して追跡するタスクにおいて、SMRによるメモリ処理の効率化が大きく貢献します。これまでは新しいフレームが追加されるたびに全トークンに対する重い計算が必要でしたが、有用な情報(トークン)だけを抽出して使い回すことで、計算リソースが限られた環境でも低レイテンシで滑らかなトラッキングを実現できます。
- インタラクティブな画像セグメンテーション: ユーザーが対象物をクリックしたり(ポイントプロンプト)、枠で囲んだり(ボックスプロンプト)して指定するUIツールにも最適です。SWRによって対象外となる背景領域の処理を軽量なネットワークに迂回させるため、画像エンコーダ全体の処理が最適化されます。結果として、ユーザーの操作に対するマスク予測の応答速度が飛躍的に向上し、ストレスのない体験を提供できます。
- 自動マスク生成への応用: SAM2には、画像全体に大量のプロンプトをサンプリングして自動的にマスクを一括生成する強力な機能があります。非常に便利ですが計算負荷が高い点がネックでした。ここにEfficient-SAM2を適用して計算の冗長性を排除することで、大規模な画像データセットに対するバッチ処理のインフラコスト削減や、処理時間の大幅な短縮が期待できます。
4. Pythonによる実装例と実行方法
本章では、手元の環境でEfficient-SAM2を実際に動かすための手順と、代表的なユースケースに対応するPythonコードを紹介します。
セットアップ方法
まずはGitHubリポジトリからコードを取得し、必要なライブラリをインストールします。PyTorch(2.5.1以上)およびTorchVision(0.20.1以上)がインストールされた環境を準備します。
# リポジトリのクローン git clone https://github.com/jingjing0419/Efficient-SAM2.git cd Efficient-SAM2 # 依存関係のインストール(Jupyter等を利用する場合はオプションも追加) pip install -e . pip install -e ".[notebooks]" # 事前学習済みチェックポイントのダウンロード cd checkpoints ./download_ckpts.sh cd ..
画像からのオブジェクト選択
1枚の画像に対して、指定したポイント(座標)からオブジェクトのマスクを予測する例です。SAM2ImagePredictorクラスを使用することで、画像エンコーディングの計算とプロンプトに基づくマスク予測をスムーズに実行できます。
import torch
import numpy as np
from PIL import Image
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
# 1. モデルと予測器の初期化
# 環境に合わせてチェックポイントと設定ファイルのパスを指定してください
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
# CUDA環境を推奨します
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = build_sam2(model_cfg, checkpoint, device=device)
predictor = SAM2ImagePredictor(model)
# 2. 画像の読み込みとエンコーディング
image_path = "path/to/your/image.jpg"
image = Image.open(image_path).convert("RGB")
image_np = np.array(image)
# ここで画像エンコーダが走り、特徴量が計算・保持されます
predictor.set_image(image_np)
# 3. プロンプトの指定と推論
# 対象オブジェクト上の座標 (x, y) と、ポジティブクリック(1)のラベルを指定します
input_point = np.array([])
input_label = np.array()
# predictメソッドにプロンプトを渡して推論を実行します
# デフォルトでは3つのマスク候補とその品質スコアが返されます
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True # 曖昧なプロンプトに対して複数のマスク候補を出力
)
# 最もスコアの高いマスクを選択するなどの後処理をここに追加します
print(f"Predicted {len(masks)} masks. Scores: {scores}")
動画のトラッキングと伝播 (SAM2VideoPredictor)
動画内の特定オブジェクトを追跡する例です。動画はあらかじめフレームごとのJPEG画像(00000.jpgなど)としてディレクトリに保存されている前提となります。最初のフレームでオブジェクトを指定し、動画全体へマスク(masklet)を伝播させます。
import torch
import numpy as np
from sam2.build_sam import build_sam2_video_predictor
# 1. モデルと動画予測器の初期化
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
predictor = build_sam2_video_predictor(model_cfg, checkpoint, device=device)
# 2. 推論状態 (inference state) の初期化
# 指定したディレクトリ内のJPEGフレーム群が読み込まれます
video_dir = "path/to/your/video_frames_directory"
inference_state = predictor.init_state(video_path=video_dir)
# 3. 初期フレームへのプロンプト追加
# フレーム0に対して、追跡したいオブジェクトの座標を指定します
points = np.array([], dtype=np.float32)
labels = np.array(, dtype=np.int32)
# add_new_points_or_box APIを使用してターゲットを指定し、初期マスクを取得します
frame_idx, object_ids, mask_logits = predictor.add_new_points_or_box(
inference_state=inference_state,
frame_idx=0,
obj_id=1, # オブジェクトの識別ID
points=points,
labels=labels
)
# 4. 動画全体へのマスク伝播
# propagate_in_video APIを呼び出し、動画全体のフレームにマスクを伝播させます
# SMRによる効率的なメモリ処理により、低レイテンシでのトラッキングが実現されます
video_segments = {}
for out_frame_idx, out_obj_ids, out_mask_logits in predictor.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {
out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
for i, out_obj_id in enumerate(out_obj_ids)
}
print("Video tracking completed.")
半教師ありビデオオブジェクトセグメンテーション (VOS) 推論
リポジトリには、DAVIS 2017やMOSEといった標準的なVOSデータセットに対して、効率的にバッチ処理で推論を進めるためのスクリプトが用意されています。これを利用することで、複数動画に対する推論結果をまとめて出力可能です。
以下のコマンドは、DAVIS 2017データセットに対して推論を実施する例です。結果のマスク画像は指定した出力ディレクトリに保存されます。
# 評価用スクリプトを利用したVOS推論の実行
python tools/vos_inference_main.py \
--model_cfg configs/sam2.1/sam2.1_hiera_l.yaml \
--checkpoint checkpoints/sam2.1_hiera_large.pt \
--dataset_path path/to/DAVIS_2017 \
--dataset_name davis \
--output_mask_dir output_masks/davis_predictions
このように、Efficient-SAM2は元のSAM2とほとんど変わらない直感的なインターフェースを保ちつつ、内部で計算の冗長性を排除しているため、既存のコード資産からの移行や新規開発の負担を小さく抑えながら高速化の恩恵を受けることができます。
おわりに
今回は、SAM2の推論を高速化する「Efficient-SAM2」について解説しました。この手法の最大の魅力は、モデルが本来持っている「疎な(Sparse)知覚パターン」をうまく活用し、精度をほとんど犠牲にすることなく、画像エンコーダやメモリ機構の計算の無駄を大幅に削減できる点にあります。
SWRによる背景処理の軽量なショートカット化や、SMRによる重要な情報のキャッシュといった工夫は、大規模な再学習を必要としません。そのため、現在構築されている既存のパイプラインへも容易に組み込むことが可能です。
計算リソースが限られたエッジデバイスでの推論や、リアルタイム性が強く求められる動画解析、さらには大規模なアノテーションシステムにおいて、システム全体のレイテンシ改善と運用コストの低減に大きく貢献するはずです。
More Information
- arXiv:2602.08224, Jing Zhang, Zhikai Li, Xuewen Liu, Qingyi Gu, 「Efficient-SAM2: Accelerating SAM2 with Object-Aware Visual Encoding and Memory Retrieval」, https://arxiv.org/abs/2602.08224
関連記事

DSPy入門: LLMパイプライン構築の効率化
LLM(大規模言語モデル)を活用したアプリケーション開発が盛んになる中、LangChainやLlamaIndexといった優れたフレームワークが注目されています。これらのツールは、LLMの活用を容易にする様々な機能を提供し […]

UnslothではじめるLLMのFine-tuning
大規模言語モデル(LLM)を特定のタスクやドメインに特化させる「ファインチューニング」。その可能性に多くの開発者が惹きつけられる一方で、「膨大な計算コストがかかる」「高性能なGPUがなければ手も足も出ない」といった高いハ […]

機械学習における敵対的攻撃とは何か?
AI、特に深層学習モデルが社会に急速に浸透し、画像認識から自動運転まで、その能力は目覚ましい進化を遂げています。しかし、その成果の裏で、モデルが抱える深刻な脆弱性については、まだ広く知られていません。実は、現在のAIモデ […]