World Model: 世界モデルの最前線

私たちは普段、ボールを投げたらどう落ちるか、この角を曲がったら何があるかを無意識に予測して行動しています。AI研究の最前線にある「World Model(世界モデル)」は、まさにこの人間の「メンタルモデル」をAIに持たせようとする試みです。
従来の強化学習(DQNやPPOなど)は、膨大な試行錯誤を繰り返す「モデルフリー」なアプローチが主流でしたが、現実世界での学習には時間とコストがかかりすぎるという課題がありました。これに対し、世界モデルは環境の法則(ダイナミクス)を学習し、未知の状況でも脳内シミュレーション(Imagination)を通じて解を導き出す「モデルベース強化学習(MBRL)」の中核を担う技術です。
本記事では、DreamerやJEPAといった主要アーキテクチャの進化から、自動運転やロボティクスにおける具体的な活用事例、さらにはエッジデバイスでの動作を見据えた最新の軽量化実装まで、エンジニアが知るべき世界モデルの最前線を概観します。
1. 世界モデルのアーキテクチャと進化
AIが複雑な環境で自律的に行動するためには、外界の情報を効率的に処理し、未来を予測する仕組みが必要です。ここでは、世界モデルがいかにしてこの能力を獲得してきたか、その技術的な進化を解説します。
潜在空間でのダイナミクス学習: 情報の「要約」
初期の研究における最大の壁は、カメラ画像のような高次元の入力データ(ピクセル)をそのまま予測しようとすることにありました。ピクセル単位の予測は計算コストが膨大であるだけでなく、わずかな予測誤差が積み重なることで、長期的なシミュレーションが破綻してしまう「誤差の蓄積」という問題を引き起こします。 この課題に対し、David Ha & Jürgen Schmidhuber(2018)は、観測データをVAE(変分オートエンコーダ)を用いて低次元の「潜在空間(Latent Space)」へと圧縮し、その圧縮された空間内で状態の変化(ダイナミクス)を学習するアプローチを提唱しました。これは、人間が視覚情報のすべてを記憶するのではなく、「車が近づいている」といった抽象的な概念(要約)として処理するプロセスに似ており、これによりAIは本質的な情報のみを用いて効率的に未来を予測できるようになりました。
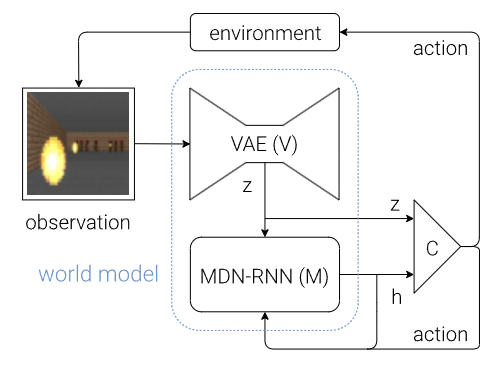
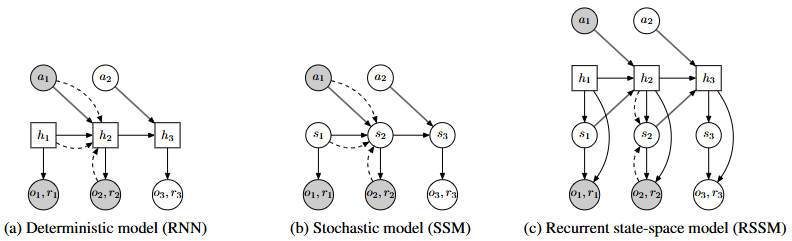
DreamerとRSSM: 記憶と想像の融合
潜在空間での学習をさらに推し進め、現在の標準的な手法となっているのが「Dreamer」シリーズです。その中核を成すのが「RSSM(Recurrent State-Space Model)」と呼ばれる技術です。 RSSMの革新性は、環境のモデル化において「過去の記憶」と「未来の不確実性」を巧みに統合した点にあります。具体的には、RNN(再帰型ニューラルネットワーク)を用いて過去の履歴情報を集約する「決定論的パス」と、そこから分岐する未来の可能性を表現する「確率的パス(状態空間モデル)」を組み合わせています。これにより、エージェントは過去の文脈を維持しながら、不確実な未来の展開を安定してシミュレーション(想像)することが可能になりました。最新のDreamerV3では、潜在変数を離散化することで、さらにロバストな学習を実現しています。
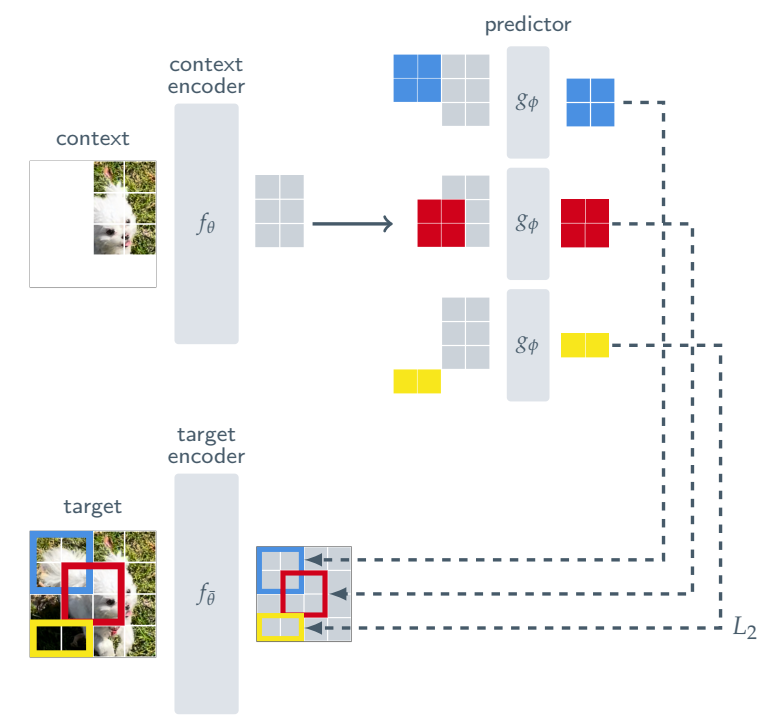
生成から予測へ: JEPAによる抽象化
一方で、MetaのYann LeCunは、「画像を再構成(生成)すること」自体が、世界を理解する上で必ずしも必要ではないと提唱しています。例えば、複雑な模様の絨毯の上を歩く際、絨毯の柄をピクセル単位で予測できなくても、歩行には支障がありません。 この考えに基づき開発されたのが「JEPA(Joint-Embedding Predictive Architecture)」です。JEPAは、入力データの一部を隠し、その欠損部分の「抽象的な特徴表現」のみを予測するように学習します。ピクセルレベルの生成を行わないため計算コストが低く、タスクに不要な詳細情報(ノイズ)を捨て去ることで、より汎用的で意味のある表現を獲得できる点が大きな利点です。
生成AIと世界シミュレータの可能性
近年、SoraやGenieといった高度な動画生成モデルが登場し、これらが「創発的な世界シミュレーター」になり得るのではないかという議論が活発化しています。これらのモデルは、大量の動画データから物理法則を近似的に学習し、一貫性のある3D構造や物体の永続性を表現する能力を見せています。 しかし、これらが真に物理世界を理解しているかについては慎重な見方もあります。「Gen-ViRe」のようなベンチマークによる評価では、動画生成モデルは視覚的なリアリティは高いものの、物理的な因果関係の推論や、長期的な計画が必要なタスクにおいては依然として限界があることが示されています。現状では、生成AIは強力な「視覚エンジン」ですが、完全な「物理エンジン」への進化は途上にあります。
2. 技術的な利点と課題解決
世界モデルをシステムに組み込むことは、単なる性能向上だけでなく、実世界での運用における本質的な課題を解決する鍵となります。ここでは、世界モデルを採用すべき理由と、実環境特有のノイズに対する最新の解決策を解説します。
なぜ世界モデルを使うのか?
世界モデルの導入には、主に「学習効率」と「安全性」の観点から明確なメリットがあります。
- サンプル効率の劇的な向上: 従来のモデルフリー強化学習では、実環境での膨大な試行錯誤が必要でした。一方、世界モデルを用いたモデルベース強化学習(MBRL)では、エージェントが内部モデルの中で「夢(Latent Imagination)」を見るようにシミュレーションを繰り返します。これにより、実世界での試行回数を最小限に抑えながら、高精度な方策を学習することが可能になります。例えば、ロボットアームの制御学習において、実機を動かす時間を大幅に短縮できる点は、ハードウェアの摩耗を防ぐ意味でも大きな利点です。
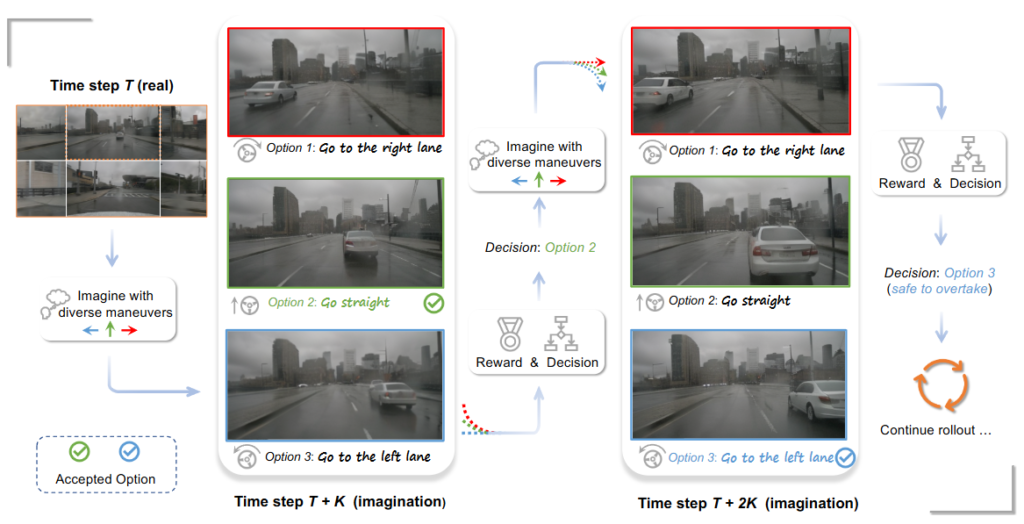
- 反実仮想(Counterfactual Reasoning)による安全性検証: 「もし交差点で対向車が車線を逸脱してきたら?」といった、現実世界ではテストが困難な危険なシナリオ(エッジケース)への対応は、自動運転や産業ロボットにおける重要課題です。世界モデルは、過去の経験に基づいて「あり得たかもしれない未来」を脳内で生成し、その結果を予測することができます。これにより、物理的なリスクを負うことなく、危険な状況下での意思決定プロセスを検証・強化することが可能になります。
ノイズとロバスト性への対応
実世界の映像データは、常にクリーンであるとは限りません。背景の動き、照明の変化、カメラのブレといった「視覚的なノイズ」は、AIの学習を阻害する大きな要因です。
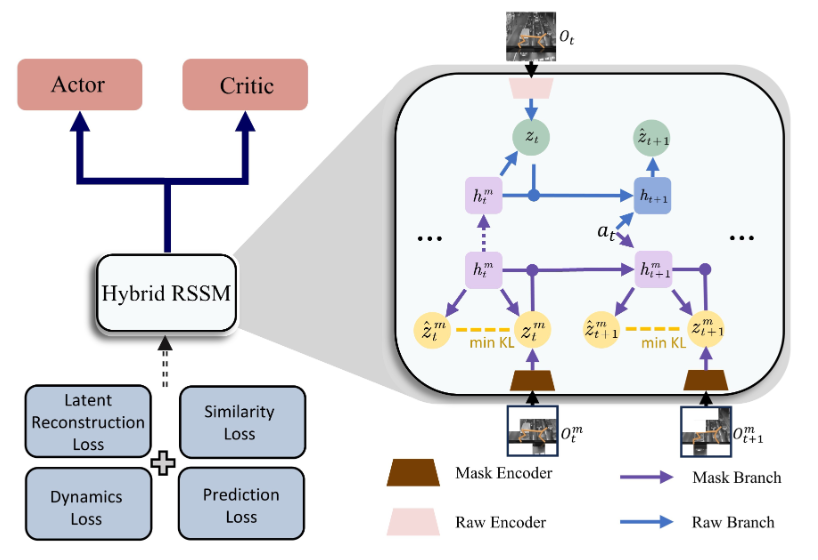
- ピクセル再構成の限界と「内生的なダイナミクス」: 初期のDreamerのようなモデルは、入力画像の全ピクセルを再構成しようとするため、タスクに関係のない背景の揺らぎなどの予測に計算リソースを浪費してしまう傾向がありました。実用的なシステム構築においては、制御に必要な「内生的な(Endogenous)情報」と、無視すべき「外生的な(Exogenous)ノイズ」を区別する必要があります。
- Hybrid-RSSMとフィルタリング技術: この課題に対し、最新の研究では「Hybrid-RSSM」のような堅牢なアーキテクチャが提案されています。これは、以下の二つの技術を組み合わせることで、ノイズに強い表現学習を実現しています。
- マスキング戦略: 画像の一部をランダムに隠すことで、時空間的な冗長性を削減し、モデルが意味のある特徴量だけに注目するように促します。
- Bi-simulation(双模倣)原理: ピクセルの見た目が異なっていても、期待される報酬や次の状態への遷移が同じであれば、それらを「等価な状態」として扱います。
これらの技術的アプローチにより、複雑な視覚ノイズが存在する環境下でも、タスクに本質的なダイナミクスのみを抽出し、安定した制御を行うことが可能になりつつあります。
3. 具体的な実用例と応用分野
世界モデルは理論的な探求の段階を終え、産業界における「予測エンジン」としての地位を確立しつつあります。ここでは、自動運転、ロボティクス、デジタルツインの3大領域における具体的な実装事例と、技術的な進化の方向性を解説します。
自動運転におけるシナリオ生成と計画
自動運転開発における最大のボトルネックは、事故寸前の状況や極端な悪天候など、現実世界でのデータ収集が困難かつ危険な「エッジケース」への対応です。世界モデルは、これらの希少なシナリオを生成(シミュレーション)することで、AIの安全性検証に革命をもたらしています。
- 生成AIによるシナリオ拡張: 例えば、英国Wayve社の「GAIA-1」は、ビデオ、テキスト、アクション入力を組み合わせて将来の運転シーンを生成します。学習データには含まれない「歩道への強引な進入」のような危険な状況さえも物理的に矛盾なく生成し、AIドライバーのトレーニングデータとして活用することを可能にしました。また、「Drive-WM」はマルチビュー映像の一貫性を保ちながら未来を予測し、安全な経路計画を支援します。
- 物理的整合性の追求: 初期のモデルは視覚的な予測(RGB画像)に留まっていましたが、最新のトレンドは「物理的な空間理解」へとシフトしています。「MUVO」や「OccWorld」といったモデルは、LiDAR点群や3D占有グリッド(Occupancy Grid:空間を格子状に区切り、物体の有無を表現したマップ)を直接予測します。これにより、単なる映像の生成ではなく、幾何学的に正確な衝突判定や経路計画が可能となり、実用性が飛躍的に向上しています。
ロボティクスとHumanoid World Models
人型ロボット(ヒューマノイド)の制御においても、世界モデルは重要な役割を果たしています。特に注目すべきは、計算リソースの制約が厳しい環境でも動作する「軽量化」への取り組みです。
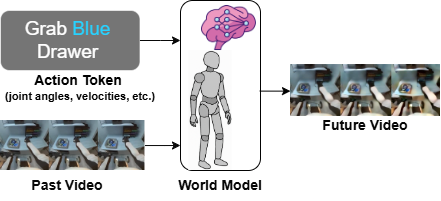
- Humanoid World Models (HWM): 2025年に発表された「HWM」は、ヒューマノイドロボット向けに特化したオープンソースの世界モデルです。このモデルは、100時間に及ぶデモデータから学習され、ロボットの視覚情報と行動入力から未来の視覚的結果を予測します。
- 民主化される世界モデル: HWMの特筆すべき点はその効率性です。パラメータ共有(Parameter Sharing)という技術を用いることで、モデルサイズを33〜53%削減しつつ、高い予測精度を維持しています。これにより、従来は巨大なデータセンターを必要とした学習や推論が、一般的なコンシューマ向けGPU(1〜2台)で実行可能になりました。これは、大学の研究室や中小規模のスタートアップでも、高度な世界モデルを用いたロボット制御開発が可能になることを意味します。
デジタルツインの高度化(自律管理)
デジタルツインは、物理空間を単にコピーして監視するフェーズから、世界モデルを組み込んで未来を予測し、自律的に介入するフェーズへと進化しています。
- Agentic AIへの進化: 従来、異常検知後の判断は人間に委ねられていました。しかし、最新のデジタルツインは、大規模言語モデル(LLM)と世界モデルを統合することで「自律エージェント(Agentic AI)」として機能します。LLMが人間の指示(「エネルギー効率を最大化せよ」など)を解釈し、世界モデルが「空調を下げた場合の室温変化」や「ライン速度を上げた場合の故障リスク」をシミュレーションします。
- 自律的な介入: この予測に基づき、システムは最適なパラメータを自律的に決定し、物理側の機器を制御します。製造業における予知保全や、スマートシティにおける交通流の最適化など、人間が常時監視しきれない複雑なシステムの運用を、AIが能動的に代行する未来が現実のものとなりつつあります。
4. 実装へのヒントとエコシステム (Implementation)
理論や応用事例を理解したところで、実際にエンジニアが世界モデルを構築・検証するための具体的なツールや、実システムへの組み込みに向けた技術的アプローチについて解説します。
開発ライブラリとツール
世界モデルの実装は、画像圧縮(VAE)、時系列予測(RNN/SSM)、強化学習(Actor-Critic)が複雑に絡み合うため、ゼロからの構築は容易ではありません。幸い、信頼性の高いオープンソース・ライブラリが登場しており、これらを活用することで開発を加速できます。
- DreamerV3 (JAX): 著者による公式実装です。最新のアルゴリズム(Symlog変換や離散潜在表現)を網羅しており、研究の再現性を重視する場合に最適です。
- PyDreamer (PyTorch): 多くのエンジニアにとって馴染み深いPyTorchベースの実装です。DeepMind LabやMineRLといった複雑な環境へのラッパーも含まれており、既存のPyTorchエコシステムとの統合が容易です。
- mbrl-lib (Meta AI): Meta社(Facebook Research)が開発した、モデルベース強化学習のための包括的ツールキットです。ダイナミクスモデルやプランナーがモジュール化されており、これらを自由に組み合わせて実験できるため、独自の改良を加えたい場合に適しています。
エッジデバイスへの展開と軽量化
世界モデルをロボットやドローンなどのエッジデバイスで動作させる場合、計算リソースの制約が大きな課題となります。これに対し、ハードウェアの進化に頼るだけでなく、モデル自体の軽量化技術が重要視されています。
- 量子化と蒸留: モデルの重みを32ビット浮動小数点から8ビット整数(INT8)などに変換する「量子化」や、巨大なモデルの知識を軽量なモデルに継承させる「蒸留」は、推論速度を向上させる有効な手段です。
- アーキテクチャによる効率化: 例えば「Humanoid World Models (HWM)」は、パラメータ共有(Parameter Sharing)という手法を用いることで、モデルサイズを約33〜53%削減しつつ、高い予測精度を維持することに成功しています,。これにより、大規模な計算クラスタではなく、一般的なGPU(1〜2台)でも学習・運用が可能になりつつあります。
評価指標の考え方
世界モデルの性能を測る際、単に「生成された映像が綺麗か」という画質の良さ(FIDなど)だけに注目するのは危険です。自動運転やロボット制御においては、物理的な整合性や因果関係の正しさが生死を分けます。
- 物理的・論理的整合性の評価: 最新の研究では、ピクセルの美しさではなく、モデルが物理法則や因果関係を正しく推論できているかを測るベンチマークが登場しています。「Gen-ViRe」はその一例で、視覚的な生成プロセスが論理的な推論(Chain-of-Frames)に基づいているかを定量的に評価します。
- モデル選定の指針: エンジニアは、単に高解像度な映像を生成できるモデルではなく、長期的な計画や物理的な一貫性を保てるモデルを選定する必要があります。目的に応じて、画質よりも推論能力を重視した評価指標を設定することが、実用的なシステム構築への第一歩です。
おわりに
世界モデルは、単なる環境シミュレータという枠を超え、AIが物理世界を「理解」し、複雑な状況下で「推論」するための基盤アーキテクチャへと進化しています。
これまでの研究により、直感的な物理挙動の予測(System 1)においては目覚ましい成果が得られました。しかし、数分先を見据えた長期的な計画や、論理的な判断(System 2)には依然として課題が残されています。今後の展望として最も期待されるのは、大規模言語モデル(LLM)が持つ意味論的な推論能力と、世界モデルの物理的な接地(Grounding)能力の統合です。
この「System 1」と「System 2」の融合が、より汎用的で説明可能な自律システム(Embodied AI)を実現するブレイクスルーと期待されています。
More Information
- Learning and Leveraging World Models in Visual Representation Learning
- World Models for Autonomous Driving: An Initial Survey
- Learning Latent Dynamic Robust Representations for World Models
- Humanoid World Models : Open World Foundation Models for Humanoid Robotics
- A Comprehensive Survey on World Models for Embodied AI
- Can World Simulators Reason? Gen-ViRe: A Generative Visual Reasoning Benchmark
- Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
関連記事

KAN: Kolmogorov–Arnold Networks
ディープラーニングモデルの多くは、多層パーセプトロン(MLP)に大きく依存していますが、MLPには、解釈が難しさや、Transformerなどのモデルでは埋め込みパラメータ以外のほぼすべてのパラメータを消費してしまうとい […]

Agent-as-a-Judge: 次世代の自律的評価システムに向けたロードマップ
AI評価の分野では、LLM自身の高度な理解力を活用して他のモデルを評価する「LLM-as-a-Judge」が広く普及しています。しかし、AIが生成する回答が高度化し、専門領域における多段階のタスクへと進化するにつれ、単一 […]

ベイジアンネットワーク入門:pgmpyによる因果探索と因果推論の実践
近年の機械学習(ML)モデルは、ビッグデータ解析において非常に高い予測精度を達成しています。しかし、その意思決定に至るプロセスが不透明な「ブラックボックス」となってしまう課題が指摘されています。データから相関関係を発見す […]