scikit-upliftで始めるアップリフトモデリング入門

データ駆動型の意思決定において、機械学習モデルは「どの顧客が商品を購入する可能性が高いか」という相関関係の予測に広く活用されています。しかし、マーケティング施策や介入の予算を真に最適化するためには、「我々の施策(介入)によって、どの個体の行動が変化するか」という因果関係を推定する必要があります。
従来の予測モデルでは、施策の有無にかかわらず購入する「確実層」と、施策によって初めて行動が変化する「説得可能者」を区別することができません。このため、施策が不要な顧客にまでコストを費やしてしまい、リソースの非効率な配分を招く可能性があります。
アップリフトモデリング(Uplift Modeling)の核となる目的は、この非効率性を解消し、施策による真の増分効果(Incremental Impact / インクリメンタリティ)を個人レベルで捉えることにあります。この手法を用いることで、限られたリソースを、最も反応が増大すると予測される「説得可能者」に集中させ、投資収益率(ROI)を最大化できます。
今回は、因果推論に基づくこの強力な手法の基礎概念と、その実践的な実装に焦点を当てます。Pythonの scikit-uplift (sklift) という、使いやすさとscikit-learnエコシステムとの互換性に優れたライブラリ を利用し、アップリフトモデリングの基本的な考え方と実装手順を解説していきます。
アップリフトモデリングの基礎概念
アップリフトモデリング(Uplift Modeling, UM)は、単なる予測分析ではなく、処方的分析(prescriptive analytics)を実現するための因果推論に基づく枠組みです。その理論的根幹は、ルービン因果モデル(Rubin Causal Model)の潜在的結果フレームワーク(Potential Outcomes Framework)にあります。
因果推論の核心:反事実とITE
潜在的結果フレームワークでは、個体 \(i\) が持つ潜在的な結果として、次の2つを考えます。
- \(Y_i(1)\): 個体 \(i\) が処置(Treatment, 例:施策)を受けた場合の潜在結果。
- \(Y_i(0)\): 個体 \(i\) が処置を受けなかった(Control, 例:施策なし)場合の潜在結果。
この2つの結果の差、\(\tau_i = Y_i(1) – Y_i(0)\) は、個体 \(i\) に対する処置の真の因果効果であり、個別処置効果(Individual Treatment Effect, ITE)と呼ばれます。
しかし、現実世界において、ある一個体に対して「Eメールを送った場合の購入有無」と「Eメールを送らなかった場合の購入有無」を同時に観測することはできません。観測できない方の結果は反事実(Counterfactual)と呼ばれ、この観測不可能性こそが「因果推論の根本問題(The Fundamental Problem of Causal Inference)」となります。
推定目標としてのCATE
ITEを直接推定することが不可能であるため、アップリフトモデリングが実務的な推定目標とするのが、条件付き平均処置効果(Conditional Average Treatment Effect, CATE)です。
CATEは、観測可能な共変量(特徴量)\(X=x\) を持つ個体の集団において、処置効果 \(\tau\) の期待値を推定するものであり、\(\tau(x) := E[Y(1) – Y(0) | X=x]\) と定義されます。アップリフト(Uplift)という用語は、このCATEの推定値を指します。
CATEを偏りなく推定するためには、以下の2つの重要な仮定が必要です。
- Unconfoundedness(非交絡性): 特徴量 \(X\) が与えられた場合、処置の割り当てがポテンシャルアウトカムと独立である、という仮定です。これは、同じ \(X\) を持つ個体間では、処置群とコントロール群への割り当てがランダムであることを意味します。
- Overlap(オーバーラップ): 任意の \(X=x\) を持つ個体について、処置を受ける確率と受けない確率がともにゼロより大きい、という仮定です。
これらの仮定を満たすためには、処置の割り当てがランダムに行われた実験、すなわちランダム化比較試験(RCT、A/Bテスト)から得られたデータセットが必須となります。
ビジネス上の顧客タイプ:4象限
アップリフトモデリングの最大のビジネス的価値は、施策に対する個人の反応の異質性を捉え、顧客を施策への増分効果に基づいて分類することにあります。
UMが識別を目指す4つの主要な顧客セグメントは以下の通りです。
| セグメント名 (英語) | セグメント名 (日本語) | 定義(施策効果 \(\tau_i\)) | 戦略的示唆 |
|---|---|---|---|
| Persuadables | 説得可能者 | \(\tau_i > 0\)(施策で行動変化) | 最重要ターゲット。限られたリソースを集中すべき層。 |
| Sure Things | 確実層 | \(\tau_i \approx 0\)(施策の有無によらず行動) | 施策コストが無駄になるため、ターゲティングを避けるべき層。 |
| Lost Causes | 損失者(不応層) | \(\tau_i \approx 0\)(施策の有無によらず非行動) | 施策コストが無駄になるため、ターゲティングを避けるべき層。 |
| Do-Not-Disturbs (Sleeping Dogs) | 天邪鬼層 | \(\tau_i < 0\)(施策で行動が阻害される) | 施策が害を及ぼすため、絶対に避けるべき層。 |
アップリフトモデリングの究極の目的は、ポジティブな増分効果をもたらす「説得可能者」に焦点を当て、真のROIを最大化するための施策配分を決定することにあります。
因果推論の基礎については、以前執筆したPythonで始める因果推論入門を合わせてご確認ください。
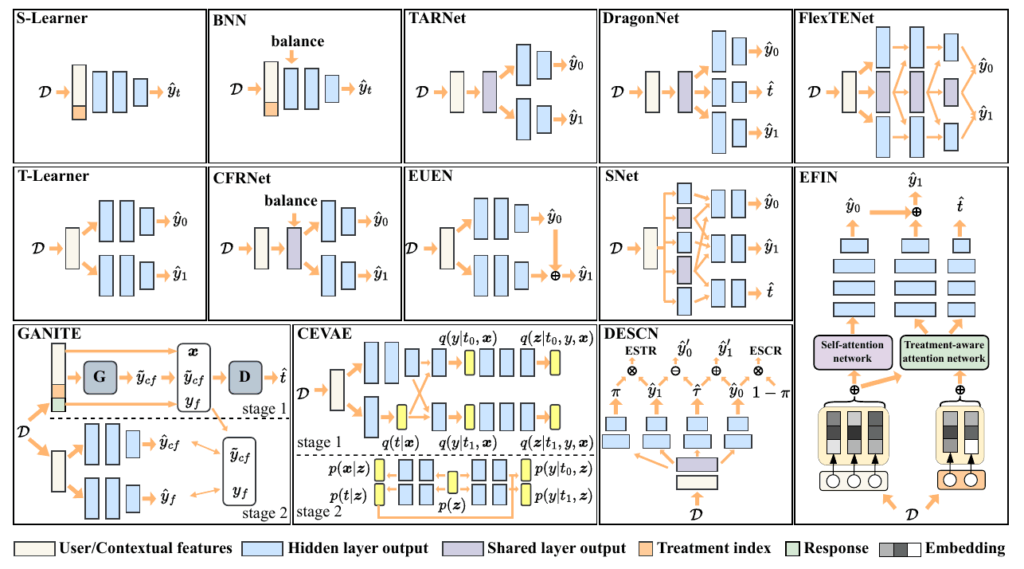
scikit-upliftの主要なアルゴリズム
Pythonのアップリフトモデリングライブラリである scikit-uplift (sklift) は、使い慣れたscikit-learnライクなAPIを通じて、因果効果を推定するための様々なアプローチを提供しています。これらのアルゴリズムは、主に既存の予測モデルを利用する「Meta Learner」と、問題を再定式化する「Class Transformation」に大別されます。
ここでは、sklift.models モジュールに実装されている代表的な手法を、そのロジックと特性とともに解説します。
Meta-Learners アプローチ
Meta Learner は、標準的な教師あり学習アルゴリズムをベースの学習器として活用し、その出力を組み合わせてCATE(条件付き平均処置効果)を導出するフレームワークです。
S-Learner(sklift.models.SoloModel)
S-Learner(Single-model approach、単一モデルアプローチ)は、最も直感的で実装が容易な手法です。
- ロジック: 処置フラグ \(T\) (Treatment) を、個体の特徴量 \(X\) とともに単一のモデルに入力します。モデルの訓練が完了した後、アップリフトを推定したい個体に対して、処置フラグを \(1\) に設定した予測値 \(\hat{Y}(T=1, X)\) と、 \(0\) に設定した予測値 \(\hat{Y}(T=0, X)\) の2回予測を実行します。この予測値の差が、アップリフト \(\hat{\tau}(X) = \hat{Y}(T=1, X) – \hat{Y}(T=0, X)\) となります。
- 実装: scikit-uplift では SoloModel クラスに対応します。
- 注意点: 処置効果のシグナルが他の特徴量に比べて弱い場合、学習プロセスにおいてモデルが処置フラグを軽視してしまい、真の因果効果を捉えられないリスクが指摘されています。
T-Learner(sklift.models.TwoModels)
T-Learner(Two-model approach、ダブル分類器アプローチ)は、処置群とコントロール群のデータを完全に分離して学習するアプローチです。
- ロジック: 処置群のデータのみを用いてモデル \(f_1\) を、コントロール群のデータのみを用いてモデル \(f_0\) を、それぞれ独立して訓練します。アップリフトは、これら2つのモデルの予測差 \(\hat{\tau}(X) = f_1(X) – f_0(X)\) として計算されます。
- 実装: scikit-uplift では TwoModels クラスとして提供されています。
- 注意点: この手法の主要な欠点は、各モデルがアウトカムそのものの予測精度を高めることに注力しすぎるため、もしアップリフトのシグナルが微弱であった場合、その差分シグナルがノイズに埋もれ、結果的にアップリフトの推定精度が低下する可能性があることです。
Class Transformation
Class Transformation は、アップリフト推定という因果推論の問題を、既存の標準的な教師あり学習アルゴリズムで解けるように、目的変数(ターゲット)を変換するアプローチです。
ClassTransformation(sklift.models.ClassTransformation)
この手法は、2値結果(分類問題)に特化した変換アプローチです。
- ロジック: 新しい目的変数 \(Z\) を、元の目的変数 \(Y\) と処置フラグ \(W\) を用いて、\(Z = YW + (1-Y)(1-W)\) と定義します。これは、「処置群で反応あり」または「コントロール群で反応なし」の場合に \(Z=1\) となるようにラベルを変換します。
- 推定: 処置群とコントロール群のサンプル数が均等である (\(P(W=1)=0.5\)) という強い仮定 の下で、アップリフト \(\tau(X)\) は標準的な分類器が予測する \(P(Z=1|X)\) から \(\hat{\tau}(X) = 2 \cdot P(Z=1|X) – 1\) として導出されます。
- 実装: sklift.models.ClassTransformation クラスに対応します。
Transformed Outcome(sklift.models.ClassTransformationReg)
これは、CATE推定を回帰問題に変換する、より柔軟で頑健な手法です。
- ロジック: 観測されたアウトカム \(Y\) を、傾向スコア \(p\) (処置群に割り当てられる確率)を用いて \(Z = Y(W-p) / (p(1-p))\) と変換します。この変換されたアウトカム \(Z\) の条件付き期待値 \(E[Z|X=x]\) は、CATE \(\tau(x)\) そのものに等しくなるため、標準的な回帰モデルを訓練することでアップリフトを推定できます。
- 実装: sklift.models.ClassTransformationReg クラスで提供されます。傾向スコア \(p\) は、定数(例: \(0.5\))を設定するか、
propensity_estimatorを使って学習させることも可能です。この手法は、2値の結果だけでなく、連続的な結果(例:売上高)を持つ収益アップリフトモデリングなど、より汎用的な問題にも応用が可能です。
Pythonによる実践
ここでは、これまでに解説したアップリフトモデリングの理論を、Pythonのscikit-upliftを用いて実際にどのように実装するかを見ていきます。データ準備からモデル学習、評価、そして結果の可視化までの一連のワークフローを、S-Learner (SoloModel) を使って解説します。
インストールとライブラリのインポート
まず、必要なライブラリをインストールします。scikit-upliftは比較的新しいバージョンのscikit-learnと互換性の問題が発生することがあるため、バージョンを指定します。なお、ここではPython v3.11系を使用しています。
$ pip install scikit-uplift scikit-learn==1.3.2 lightgbmインストール後、今回の実装で利用するライブラリをインポートします。pandasによるデータ操作、scikit-learn によるデータ分割、そして scikit-uplift からはモデル (SoloModel)、評価指標(uplift_at_k, qini_auc_score)、可視化ツール(plot_qini_curve)をインポートします。ベースの学習器としてはLightGBMを使用します。
# -*- coding: utf-8 -*- import pandas as pd import numpy as np from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt # Import necessary modules from the scikit-uplift library from sklift.metrics import uplift_at_k, qini_auc_score from sklift.viz import plot_qini_curve from sklift.models import SoloModel # Import the LightGBM classifier from lightgbm import LGBMClassifier
サンプルデータの生成と分割
アップリフトモデリングには、個体の特徴量(\(X\))、処置(介入)の有無を示すフラグ(\(T\))、そして結果(コンバージョンなど)を示す目的変数(\(Y\))が含まれるデータセットが必要です。今回は、create_sample_data 関数を用いて、特定の条件下で介入効果が高まるように設計されたシミュレーションデータを生成します。
データ生成後、機械学習の標準的な手順に従い、train_test_split を用いてデータを学習用と評価用に分割します。
def create_sample_data(size=10000, random_state=None):
"""
Function to generate sample data for uplift modeling.
Args:
size (int): Number of data points to generate.
random_state (int): Seed for the random number generator.
Returns:
pd.DataFrame: The generated sample data.
"""
if random_state:
np.random.seed(random_state)
# Generate 12 random features
X = pd.DataFrame({f'feature_{i}': np.random.rand(size) for i in range(12)})
# Randomly generate the treatment flag (0: control, 1: treatment)
treatment = np.random.randint(0, 2, size=size)
# Generate the target variable
# The effect of the treatment is designed to appear only for users with specific features.
# The uplift effect is higher when feature_1 > 0.5 and feature_2 > 0.5.
# This represents the "Persuadables" or "treatment responders".
y_propensity = 0.4 + 0.1 * X['feature_1'] - 0.2 * X['feature_2']
# Define the uplift effect from the treatment
# Give a higher uplift only to users who meet a specific condition.
uplift_effect = np.where((X['feature_1'] > 0.5) & (X['feature_2'] > 0.5), 0.15, 0.02)
# Calculate the conversion probability for treatment and control groups
conversion_prob = y_propensity + treatment * uplift_effect
# Generate the target variable based on the probability above
target = np.random.binomial(1, conversion_prob, size=size)
# Combine into a single DataFrame
df = X.copy()
df['treatment'] = treatment
df['target'] = target
return df
# --- Main execution flow ---
# 1. Generate sample data
print("1. Generating sample data...")
df = create_sample_data(size=10000, random_state=42)
# Split data into features (X), treatment flag (treat), and target (y)
X = df.drop(columns=['treatment', 'target'])
y = df['target']
treat = df['treatment']
print(f"Data size: {len(df)}")
print(f"Number of features: {X.shape[1]}")
print("\nData sample:")
print(df.head())
# 2. Split the data
# Split into training and validation sets
print("\n2. Splitting data into training and validation sets...")
X_train, X_test, y_train, y_test, treat_train, treat_test = train_test_split(
X, y, treat, test_size=0.3, random_state=42
)
print(f"Training data size: {len(X_train)}")
print(f"Validation data size: {len(X_test)}")
S-Learnerによるモデル学習とアップリフト予測
S-Learner(SoloModel)は、処置フラグを他の特徴量と同様に扱い、単一のモデルで学習を行う最もシンプルなアプローチです。
ここでは、ベースの学習器として LGBMClassifier を指定し、SoloModel を初期化します。その後、fitメソッドに学習用の特徴量、目的変数、処置フラグを渡してモデルを学習させます。学習後、predictメソッドを用いて評価データに対するアップリフトスコアを計算します。このスコアは、各個体における「処置があった場合の予測確率」と「処置がなかった場合の予測確率」の差分として計算されます。
# 3. Train the Uplift Model
# Predict uplift using the SoloModel.
# The SoloModel uses a single model to learn from both the treatment and control groups' data.
# Internally, it uses the treatment flag as one of the features.
print("\n3. Training the Uplift Model...")
# Specify LightGBM as the base machine learning model
# n_estimators: Number of decision trees
# max_depth: Maximum depth of the decision trees
lgbm = LGBMClassifier(n_estimators=100, max_depth=5, random_state=42, force_col_wise=True)
# Initialize the SoloModel
# estimator: The base model
sm = SoloModel(estimator=lgbm)
# Train the model
# Pass features, target, and treatment flag to the fit method
sm.fit(X_train, y_train, treat_train)
# Predict uplift scores on the validation data
# Uplift score = P(target=1 | treatment=1) - P(target=1 | treatment=0)
uplift_sm = sm.predict(X_test)
print("Model training and prediction completed.")
モデルの評価
個々の真のアップリフト(ITE)は観測できないため、モデルの評価には専用の指標が必要です。ここでは代表的な2つの指標を用います。
- Qini AUCスコア: Qini曲線の下の面積で、モデルがランダムなターゲティングと比較してどれだけ効率的にアップリフトを生み出しているかを示します。値が大きいほど性能が良いとされます。
- uplift_at_k: アップリフトスコアが高い上位k%のユーザーに介入した場合の平均アップリフトを計算します。ビジネス上の意思決定(例:「上位30%の顧客にクーポンを送る」)における効果を直接的に評価できます。
# 4. Evaluate the model's performance
# Use the Qini coefficient to evaluate the model.
# The Qini coefficient is a leading metric for measuring the performance of uplift models.
# It shows how effectively the model identifies individuals to target compared to random targeting.
print("\n4. Evaluating the model's performance...")
# Calculate the Area Under the Qini Curve
qini_score = qini_auc_score(y_true=y_test, uplift=uplift_sm, treatment=treat_test)
print(f"Qini AUC Score: {qini_score:.4f}")
# Calculate the uplift value for the top 30% of users
uplift_30 = uplift_at_k(y_true=y_test, uplift=uplift_sm, treatment=treat_test, strategy='overall', k=0.3)
print(f"Uplift at top 30%: {uplift_30:.4f}")
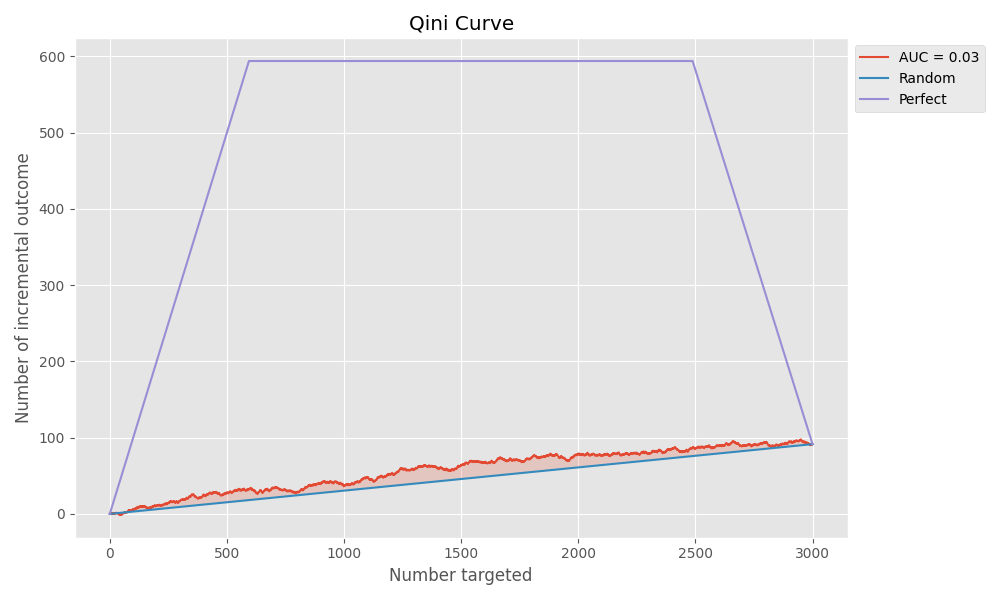
結果の可視化
最後に、評価結果をQini曲線で可視化します。このグラフは、モデルの性能を直感的に理解するのに非常に役立ちます。
- 横軸: 介入対象者の割合(アップリフトスコアが高い順)
- 縦軸: 累積的なアップリフト(純増コンバージョン数)
性能の良いモデルは左上に凸の曲線を描き、対角線(Random)からの乖離が大きいほど、効率的に「説得可能者」を特定できていることを意味します。
# 5. Visualize the results
# Plot the Qini curve.
# x-axis: Percentage of the population targeted (ordered by uplift score).
# y-axis: Cumulative uplift.
# An ideal model will draw a curve that is convex towards the top-left,
# while a random model will be close to the diagonal line.
print("\n5. Visualizing the evaluation results...")
fig, ax = plt.subplots(figsize=(10, 6))
plot_qini_curve(y_true=y_test, uplift=uplift_sm, treatment=treat_test, ax=ax, perfect=False)
ax.set_title('Qini Curve')
plt.savefig("qini_curve.png")
print("Qini curve graph saved as 'qini_curve.png'.")
print("\nProcessing completed.")
おわりに
今回は、アップリフトモデリングの基礎から、Pythonライブラリ scikit-uplift を用いた実践的なアプローチまでを概説いたしました。
アップリフトモデリングは、単に「何が起こるか」を予測する従来の分析手法とは本質的に異なります。施策がもたらす増分効果(Incremental Impact)を個人レベルで捉え、「誰に施策を適用すべきか」という処方的な意思決定を支援する強力な枠組みです。従来のモデルでは見過ごされていた「説得可能者」をピンポイントで識別し、リソースの非効率な配分を解消することで、マーケティングやビジネス戦略のROIを最適化させることが可能となります。
そして、Python環境でこの因果推論に基づくアプローチを実務に導入するための最適なスタート地点となるのが、今回紹介した scikit-uplift です。 scikit-learn 互換のAPI と、S-Learner や T-Learnerといった堅牢なMeta Learnerの実装により、データサイエンティストはアルゴリズムの選択や評価をスムーズに進めることができます。
本記事で基本的な実装を理解した後は、さらに複雑で現実的な課題に挑戦することで、アップリフトモデリングの応用範囲を広げることができます。今後の主要な探求領域として、以下の発展的なテーマが挙げられます。
- 収益アップリフトモデリング (Revenue Uplift Modeling): コンバージョン(2値の結果)ではなく、施策による売上高や利益といった連続値(裾の重い分布を持つことが多い)の増加を直接最適化するモデルです。
- 連続値処置 (Continuous Treatments): 割引率や広告の表示頻度など、2値ではない連続的な処置量(Dose)を扱うため、条件付き平均用量反応(CADR)を推定し、予算制約の下で最適な施策配分を決定する制約付き最適化(ILP)との統合が研究されています。
- 深層アップリフトモデリング (DUM): 大規模かつ高次元なデータに対して、DragonNetのような深層学習をベースとしたアーキテクチャを活用し、複雑な因果効果の異質性を高精度に捉える試みです。
More Information
- arXiv:2007.12769, Weijia Zhang et al., 「A unified survey of treatment effect heterogeneity modeling and uplift modeling」, https://arxiv.org/abs/2007.12769
- arXiv:2308.09066, Felipe Moraes et al., 「Uplift Modeling: from Causal Inference to Personalization」, https://arxiv.org/abs/2308.09066
- arXiv:2312.07206, Théo Verhelst et al., 「A churn prediction dataset from the telecom sector: a new benchmark for uplift modeling」, https://arxiv.org/abs/2312.07206
- arXiv:2403.19289, George Panagopoulos et al., 「Uplift Modeling Under Limited Supervision」, https://arxiv.org/abs/2403.19289
- arXiv:2405.15301, Bowei He et al., 「Rankability-enhanced Revenue Uplift Modeling Framework for Online Marketing」, https://arxiv.org/abs/2405.15301
- arXiv:2406.00335, Dugang Liu et al., 「Benchmarking for Deep Uplift Modeling in Online Marketing」, https://arxiv.org/abs/2406.00335
- arXiv:2412.09232, Simon De Vos et al., 「Uplift modeling with continuous treatments: A predict-then-optimize approach」, https://arxiv.org/abs/2412.09232
関連記事

画像認識アーキテクチャの進化大全: CNN・ViT・Mamba・MLPの比較
AI技術の急速な進歩により、画像認識は私たちの生活に深く浸透し、顔認証、自動運転、医療画像診断など、多岐にわたる分野で革新をもたらしています。この画像認識技術の発展を支えているのが、ディープラーニングにおけるモデルアーキ […]

AIコーディングエージェントの限界と課題:3万件のプルリクエスト分析から見る現実
GitHub CopilotやDevinといったAIツールは、今や単なるコード補完のアシスタントではなく、自律的にコードを書き、プルリクエスト(PR)まで作成する「エージェント」へと進化を遂げています。しかし、彼らは実際 […]

Neuro-Symbolic AI: ブラックボックス時代における信頼性と論理の融合
現在の自然言語処理(NLP)やコンピュータビジョン(CV)の分野では、深層学習モデルが目覚ましい成果を上げています。しかし、これらのモデルはデータ効率の悪さや予測の根拠(説明性)が不透明であるという根本的な課題を抱えてい […]