LLM-as-classifier: 階層的テキスト分類器の構築方法

2010年代以降、膨大なテキストデータから深い意味的パターンを認識するニーズは、かつてないほど高まっています。これまでのテキスト分類は、大量のラベル付きデータを用いたファインチューニング(Fine-tuning)が主流でしたが、この手法は膨大な計算リソースが必要な上に、変化の速いビジネス環境においてアジリティを欠くという課題がありました。
そこで注目されているのが、大規模言語モデル(LLM)の高度な理解力を活用し、モデルをそのまま分類器として運用する「LLM-as-classifier」というアプローチです。
本記事では、人間のドメイン知識(Domain Knowledge)とLLMの能力を組み合わせ、高精度でメンテナンス性の高い「階層的テキスト分類システム」を構築するための実践的なフレームワークを解説します。単なる分類にとどまらず、運用後のデータの変化にも適応し続けるための、反復的なプロセスについて説明します。
1. LLMを分類器として採用する技術的利点
LLMを分類器として活用する最大の魅力は、タスク固有の追加学習を必要とせず、テキストの文脈やニュアンス、複雑な意味的関係を深く理解できる点にあります。従来の機械学習アプローチと比較して、具体的に以下の3つの利点が挙げられます。
- アジリティ(Agility)の向上: 特定の分類タスクに合わせてモデルを最適化する従来のファインチューニング(Fine-tuning)は、膨大なラベル付きデータと計算リソースを必要とし、変化の激しいビジネス環境では柔軟性に欠けるという課題がありました。一方、LLMはプロンプトに分類ロジックを記述する文脈内学習(In-context learning)を活用するため、データの分布やニーズが変化しても、プロンプトを調整するだけで迅速に対応可能です。
- ドメイン知識の直接的な統合: LLMを用いる手法では、専門家が持つ「ドメイン知識(Domain Knowledge)」を、自然言語による定義として直接プロンプトに組み込めます。単なる自動的なクラスタリングとは異なり、ビジネスの運用構造や既存の概念に沿った分類スキーマを明示的にコード化できるため、実務に即した精度の高い分類が可能になります。
- 解釈性(Interpretability)の向上: 思考の連鎖(Chain-of-Thought: CoT)という手法を実装することで、モデルに「なぜそのクラスに分類したのか」という推論プロセスを段階的に出力させることが可能です。この推論プロセスは、分類結果の妥当性を人間が検証したり、誤分類の原因を特定してプロンプトを改善したりするための強力な手がかりとなります。
以上、LLM-as-classifierは単なる自動化ツールではなく、人間の専門知識を柔軟に反映し、説明責任を果たせる堅牢な分類システムを構築する基盤となります。
2. 階層的分類構築の4つのフェーズ
効率的な分類システムを構築するために、以下の4段階のプロセスを実施します。
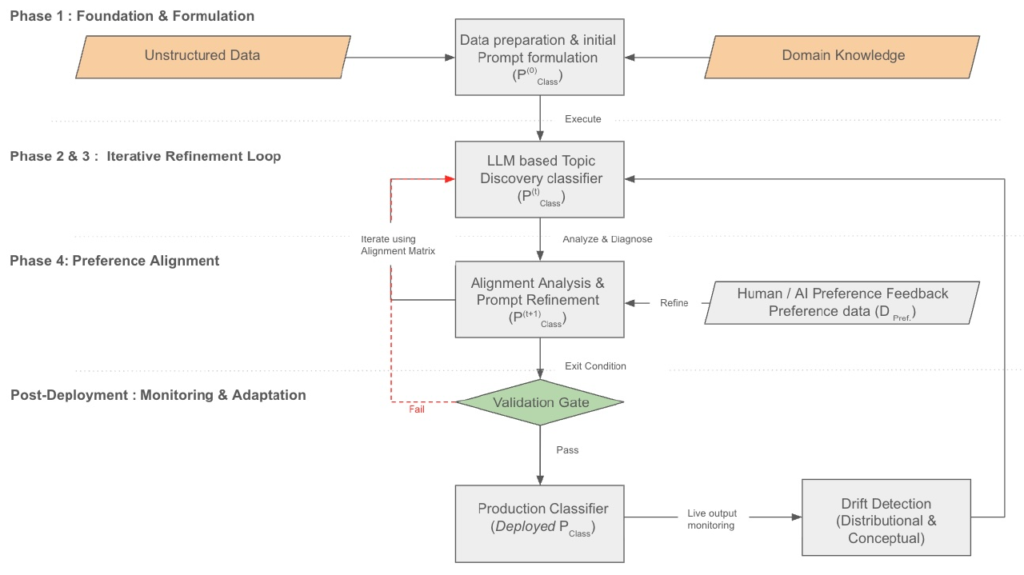
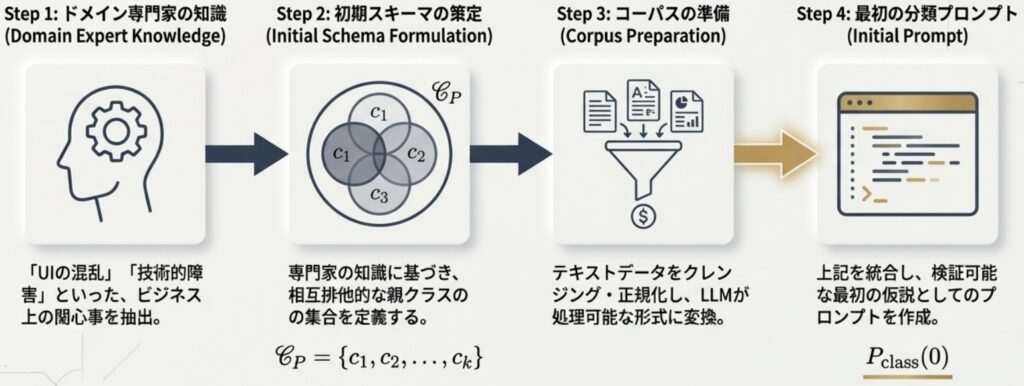
Phase 1: ドメイン知識の統合と初期スキーマ策定
最初のフェーズでは、人間の専門知識をモデルに明示的にコード化する作業から開始します。単なる自動的なクラスタリングとは異なり、ビジネスの目的や運用ルールに沿った分類を目指します。
- タスクの定義: 分類の目的や、既存システムでの課題を明確にします。
- 初期スキーマの策定: 専門家の知見に基づき、データの根本的な構造を示す「親クラス(Parent classes)」を仮説として定義します。
- コーパスの準備: 入力テキストのクリーニングや、モデルのコンテキストウィンドウに収めるためのセグメンテーション(分割)などの前処理を実施します。
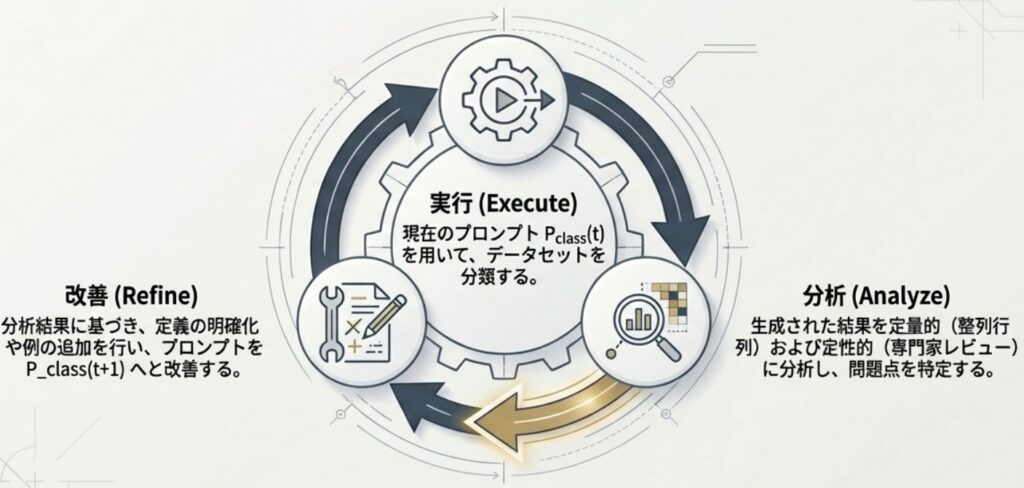
Phase 2: 反復的なトピック発見とクラスの洗練
次に、策定した初期スキーマが実際のデータ分布と一致しているかを、LLMによる「アライメント分析(Alignment Analysis)」で検証します。
- トピックモデリング: プロンプトによってLLMに制約のないトピック抽出を行わせ、データに潜む生のテーマを特定します。
- アライメント分析(ヒートマップの活用): 定義した親クラスと、LLMが抽出したトピックの共起関係をヒートマップ形式のマトリックスで可視化します。
- プロンプトの修正: ヒートマップの分析結果に基づき、定義が広すぎるクラスは「定義の鋭敏化」を行い、データが存在しないクラスは削除、曖昧なクラスは再定義や分割を実施することで、プロンプトを最適化します。
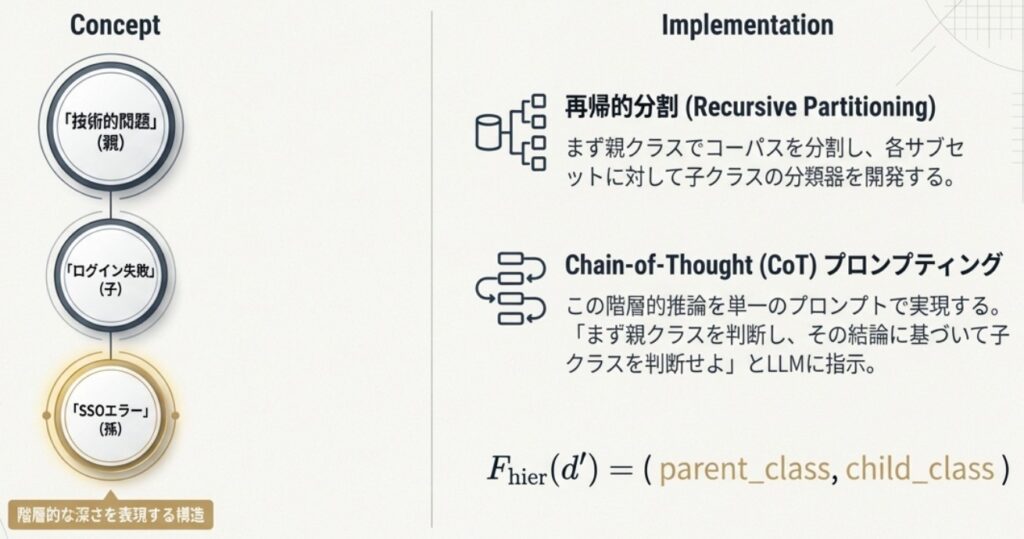
Phase 3: 階層の拡張とプロンプトの最適化
親クラスが安定した後は、より詳細な「子クラス(Child classes)」を定義し、階層構造へと拡張します。
- 再帰的パーティショニング: 親クラスごとにデータを分類し、それぞれのサブセットに対して専用の子クラスを定義します。
- Chain-of-Thought (CoT) の実装: 「まず親クラスを判断し、その結果に基づいて子クラスを推論する」というプロセスを1つのプロンプト内で指示することで、精度の向上を図ります。
- プロンプトの最適化と検証: 推論コストを抑えるために、精度を維持しつつプロンプトの長さを最小限に調整します。また、変更の影響を正確に把握するために、マクネマー検定(McNemar’s test)などの統計的手法を用いたA/Bテストを実施し、改善を科学的に検証します。
Phase 4: フィードバックによる強化
最終段階では、判断が難しいエッジケース(境界線上の事例)に対処するため、モデルの挙動を人間の意図に近づけます。
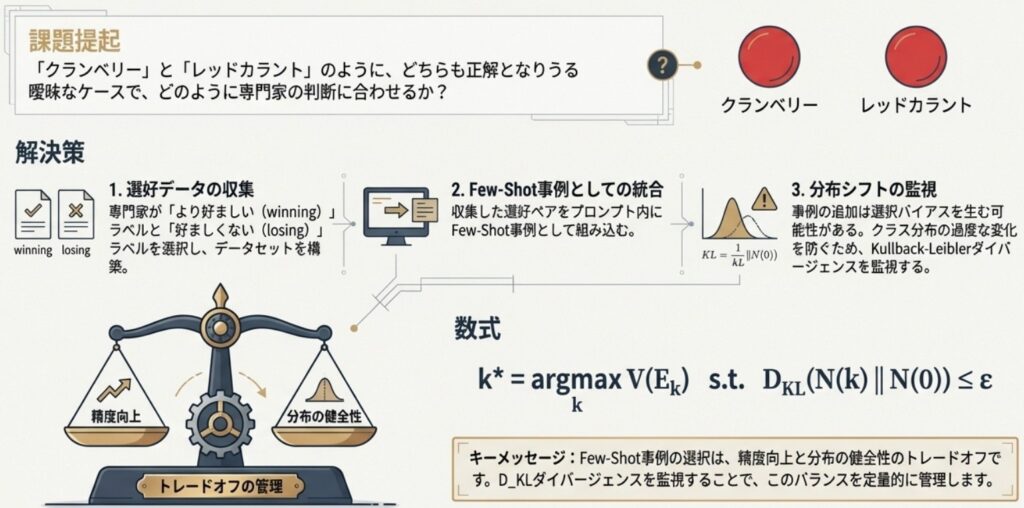
- Few-shotによるアライメント: 人間の専門家が選定した「好ましい分類例」をプロンプトに数件含めることで、モデルの判断基準を微調整します。
- AIフィードバックの活用: 強力なLLMを「裁判官」として用い、「憲法(Constitution)」と呼ばれる一連の原則に従って自動的にフィードバックを生成する手法も有効です。
- 分布の監視: 例示(Few-shot)を追加する際は、特定のクラスに偏り(Selection bias)が生じて全体の分布が歪まないよう、KLダイバージェンス(Kullback-Leibler divergence)などを用いて統計的な整合性を監視することが重要です。
3. 実運用に向けた検証と堅牢性のテスト
本番環境で信頼性の高い分類器を運用するためには、F1スコアや正解率といった一般的な指標だけでは不十分です。LLM特有の挙動から生じる様々なバイアスを特定し、構造的な堅牢性を検証するプロセスが不可欠となります。
- 順序不変性の検証(Statelessness): 本来、分類器は入力の順番に関わらず、同じデータに対しては常に同じ結果を出すべき「ステートレス(状態を持たない)」な関数として振る舞う必要があります。これを検証するために、固定されたデータセットの順番をランダムに入れ替えて繰り返し分類を実施する「シャッフルテスト」を取り入れます。もし実行順序によって結果が変動する場合、モデルが直前に処理した内容の影響を受けていることを意味し、本番での再現性に課題が残ります。
- ドキュメント内の位置バイアスの排除: LLMは、長いテキストの冒頭(Primacy:初頭効果)や末尾(Recency:親近効果)の情報を過重視し、中央付近の情報を軽視する「Lost in the middle」と呼ばれる現象に陥ることがあります。これを防ぐために、テキストの特定部分を意図的に除去して分類結果を比較する「切り出しテスト(Truncation test)」を進めます。これにより、モデルがドキュメント全体を包括的に理解しているか、あるいは特定の位置に引きずられていないかを定量的にはかることが可能です。
- プロンプト内例示の順序バイアス: Few-shotで提示する例示の順番も、モデルの判断を左右する大きな要因になります。特に、最後に提示された例に判断が引っ張られる「親近バイアス」が発生しやすいため、例示の並び順を入れ替えて一貫性を測定する「順列テスト」を実施します。例示の順番一つでロジックが揺らぐようでは、安定した運用は望めません。
これらの厳格な検証ゲート(Validation Gate)を設けることで、モデルの不安定な挙動を抑え、ミッションクリティカルな実務にも耐えうる信頼性の高いシステムを構築できます。

4. 運用後のモニタリングとデータドリフトへの対応
分類器は一度デプロイして完了ではなく、データの性質が変化する「ドリフト(Drift)」を監視し続ける必要があります。時間が経つにつれて、モデルと現実のデータにズレが生じるのは避けられないため、継続的なモニタリングが不可欠です。
- 分布ドリフト(Distributional Drift)の監視: 分類されるクラスの割合に、統計的に有意な変化がないかをチェックします。現在のクラス分布と過去の基準となる分布を比較し、カイ二乗検定などを用いて乖離を検知します。特定のトピックが急増した場合、それはビジネス環境の変化を知らせる重要なシグナルとなります。
- 概念ドリフト(Conceptual Drift)の検知: 単語の意味やユーザーの関心が変化し、定義した境界線が曖昧になる現象です。これには2つのアプローチで対応します。
- セマンティック凝集度の測定: 各クラスの「重心(セントロイド)」を算出し、新しいデータとの距離を監視します。平均距離が大きくなっている場合、そのクラスの定義が実態に合わなくなっている可能性があります。
- 未知トピックの発見: 定期的にPhase 2で実施した「制約なしのトピック抽出」を再度行い、既存のスキーマではカバーできない新しいテーマが出現していないかを確認します。
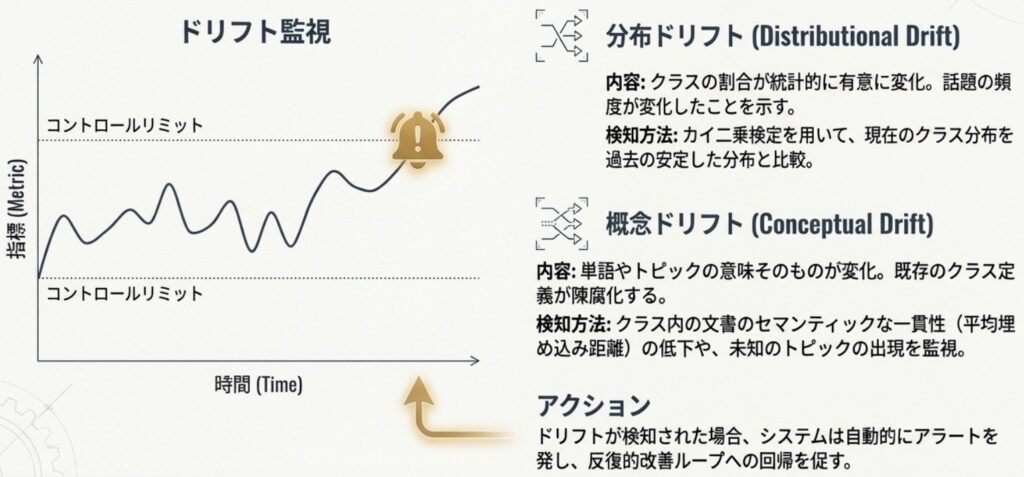
これらのドリフトが検知された場合は、自動的なアラートを通じて再度「Phase 2:反復的な洗練」のプロセスへと戻ります。プロンプトの定義を修正したり、最新の事例をFew-shotに追加したりすることで、分類器を常に最新の状態に保つ「ガードレール」として機能させることが重要です。この継続的なフィードバックループこそが、システムの長期的な信頼性を支える鍵となります。
おわりに
LLMを分類器として活用するフレームワークは、単なるラベル付けツールを超え、ユーザーの声を大規模に解析する「動的なセンシングシステム(Dynamic sensing system)」の構築を可能にします。
専門家のドメイン知識の統合、反復的なプロセスによる洗練、そしてバイアスを排除する厳格な検証を組み合わせることで、高精度な分類だけでなく、実運用に不可欠な信頼性と変化への適応力を両立できます。このアプローチにより、エンジニアリングチームは膨大な非構造化データの中から、バグの優先順位付けやUXの改善、戦略的なロードマップ策定に繋がる具体的なインサイトを導き出せるようになります。
本記事で解説した一連のプロセスは、プロダクトとユーザーの接点をより深く理解するための強力な武器となります。
More Informtaion
- arXiv:2508.16478, Doohee You et al., 「LLM-as-classifier: Semi-Supervised, Iterative Framework for Hierarchical Text Classification using Large Language Models」, https://arxiv.org/abs/2508.16478
関連記事

Stop Overthinking!- 大規模言語モデルの「考えすぎ」を解消する
近年、大規模言語モデル(LLM)は目覚ましい発展を遂げ、自然言語理解だけでなく、数学やプログラミングといった複雑な推論能力においても驚くべき成果を上げています。特に、Chain-of-Thought(CoT)と呼ばれる段 […]

「AI Agent vs. Agentic AI」: AIの進化形態を徹底解説
AI技術は目覚ましい進化を遂げ、今やビジネスに深く浸透しています。日々の定型業務の自動化から、データに基づいた戦略立案に至るまで、AIはもはや欠かすことのできないツールと言えるでしょう。 このような中、最近「AI Age […]

プロンプトエンジニアリングの奥義-「Meta Prompting」とは?
今日のAI、特に大規模言語モデル(LLM)は、私たちの仕事や日常に急速に浸透しつつあります。しかし、その能力を引き出すためには、AIに的確な指示を与える「プロンプト」が非常に重要な鍵を握ります。 とはいえ、本当に効果的な […]