大規模言語モデルは知性か?現代AIの能力と限界

近年、大規模言語モデル(LLM)が示す驚異的なテキスト生成能力は、我々に「これは真の知性なのか?」という根源的な問いを投げかけています。その流暢さの裏で、LLMが膨大なテキストの統計的パターンを模倣しているだけの「確率的オウム(Stochastic Parrots)」に過ぎないのではないか、という懐疑論も、長年の議論を再燃させています。
この問いは、単なる哲学的な学術論争で終わりません。私たちビジネスパーソンにとって、LLMの能力の本質を理解することは、信頼性、拡張性、そして根本的な限界を把握し、LLMを事業に組み込む際の基盤戦略を定める上で不可欠です。例えば、LLMが頻繁に引き起こす誤情報(ハルシネーション)への対策は、「接地(Grounding)」の欠如という理論的課題に直結します。
本記事では、現代AIをめぐる3つの主要な懐疑論——テキストの限界、スケールの限界、計算基盤の限界——に対し、最新の研究が示した具体的な「反論」と、それが実現する技術的な利点について解説いたします。
テキストの限界を越える:LLMに「世界知識」と「信頼性」をどう注入するか(接地論争)
LLMがもっともらしい文章を流暢に生成する一方で、事実と異なる虚偽の情報、すなわちハルシネーション(もっともらしい嘘)を混ぜ込むことは、ビジネス活用の大きな障壁となっています。この現象の根本的な原因として指摘されているのが、「接地(Grounding)」の欠如です。
LLMは、膨大なテキストデータに含まれる単語の統計的共起パターン、つまり「文字列の確率分布」のみを学習しています。批判者たちは、LLMを「確率的オウム(Stochastic Parrots)」と呼び、現実世界や物理的な体験との繋がり(接地)がないため、生成するテキストが真の「意味」や「事実」を理解しているとは言えない、と主張します。この接地の欠如こそが、LLMがもっともらしい虚偽情報(ハルシネーション)を生成してしまう直接的な原因であるという見解です。
反論の核心:「抽象的な意味ハブ」と「世界知識」の獲得
一方で、テキストの統計的な学習が知性へ通じる道筋を示す反論も多く提示されています。LLMの技術的な基盤である「分布仮説(Distributional Hypothesis)」は、「類似した文脈で現れる単語は類似した意味を持つ」という定義に基づいています。LLMはこのパターンを学習することで「意味」を計算的に表現したネットワークを獲得していると考えられており、一部の理論家は、意味そのものが、ある文に続く全てのトークン系列の確率分布であると定義し、批判をリフレーミングしています。
経験的な証拠も得られています。最新モデルは、テキスト学習のみにもかかわらず、常識推論能力を問う様々なベンチマークにおいて、人間の平均正答率を凌駕する性能を達成しました。
この能力の獲得を裏付けるのが、LLMの内部構造に関する研究です。MITなどの研究では、LLMの内部表現が、人間の脳の「意味的ハブ(semantic hub)」に類似した機能を持つ可能性が示唆されました。この中間層では、入力された言語(モダリティ)から切り離された、抽象的かつ汎用的な内部言語で情報が処理され、推論が進められていることが示唆されています。これは、単なる文字列の模倣ではなく、「理解」に近い質的な現象が内部で起きていることを強く示唆しています。
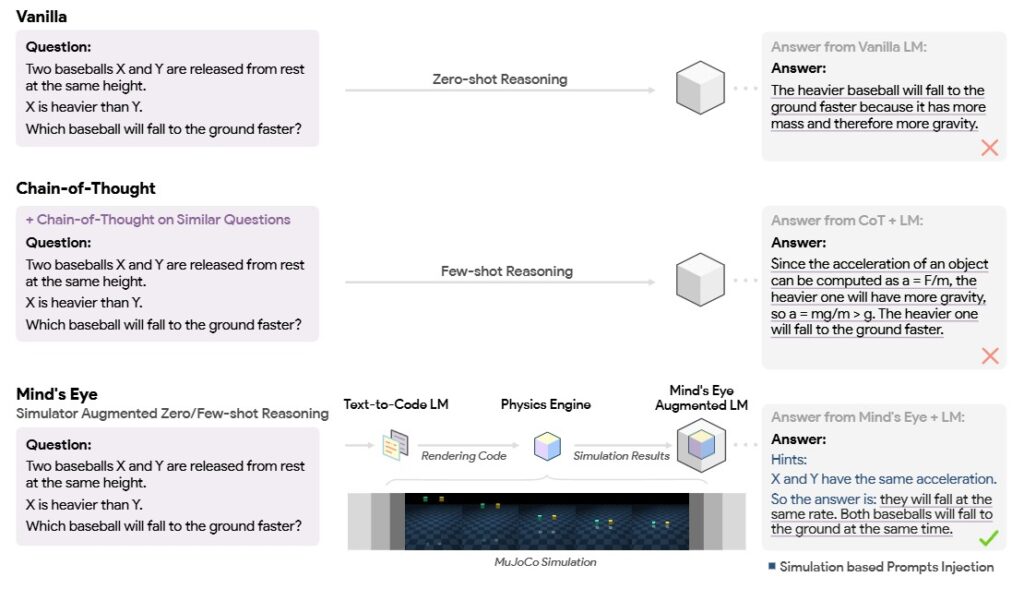
実装のヒント:信頼性を高める「外部連携」戦略
とはいえ、「テキストのみ」では物理法則や因果関係の直感的な理解には限界があることも認識されています。この限界を工学的に克服し、LLMの信頼性を劇的に向上させる最も重要な戦略が、外部システムとの連携による「接地」です。
LLMの応答の事実的信頼性を高めるため、最も普及している手法の一つが、RAG (Retrieval-Augmented Generation) です。これは、応答生成時に外部の検証済みデータベースや文書を参照させることで、LLMの回答を事実に基づいた情報に強制的に接続させ、ハルシネーションを防ぐことができます。
さらに高度な応用例として、Google ResearchによるMind’s Eyeフレームワークがあります。複雑な物流シミュレーションなど、物理的な因果推論が必要なタスクに対し、LLMが推論エンジンとして働き、自ら外部の物理エンジンを呼び出し、そのシミュレーション結果を文脈情報として取り込んで回答を生成するという実装が可能になっています。
これらの外部連携戦略は、LLMを単体の知識ベースではなく、現実世界や事実と協調しながらタスクに取り組む「信頼性の高い推論エンジン」として活用する道を開くものです。
スケールは「質」に転化するか?:非線形な能力飛躍の利用法(拡張性論争)
LLMの進化は、モデルサイズ、データ、計算リソースを増大させる「スケーリング(規模拡大)」によって支えられてきました。しかし、この拡張性が本当に「知性」という質的な飛躍をもたらすのか、それとも単なる「量的改善」で終わるのか、という議論が、拡張性論争の核心です。
課題:スケールは単なる「量的改善」で終わるのか
懐疑論者、あるいはスケーリング批判論者は、モデル、データ、計算資源を仮に1兆倍に増やしたとしても、それは単なる性能改善に過ぎず、「エラー(ハルシネーション)の頻度が軽減する」といった量的改善に留まり、真の知性という質的な飛躍は起こらないのではないか、と指摘します。
さらに、実際のスケーリングは深刻な収穫逓減(Diminishing Returns)に直面しています。LLMのエラー減少は極めて遅い指数で進むことが示唆されており、例えばエラー率を10分の1に減らすだけでも、天文学的な量のデータが必要になるという分析もあります。これは、ハルシネーションの完全な除去が、現在のスケーリング則では物理的に不可能であることを示唆しています。
反論の核心:「創発」とプロンプトによる推論能力の獲得
この懐疑論に対し、現代AI研究は「創発的能力(Emergent Abilities)」という概念を提示し、「量」は「質」に転化し得ると反論しています。
創発的能力とは、小規模なモデルには存在しないが、大規模なモデルに突如としてジャンプ(非線形的に獲得)する能力を指します。これは、小規模モデルの性能曲線から単純に予測(外挿)することができない「相転移」的な振る舞いであり、単なる量的改善ではない、質的な転化が起きている証拠とされます。
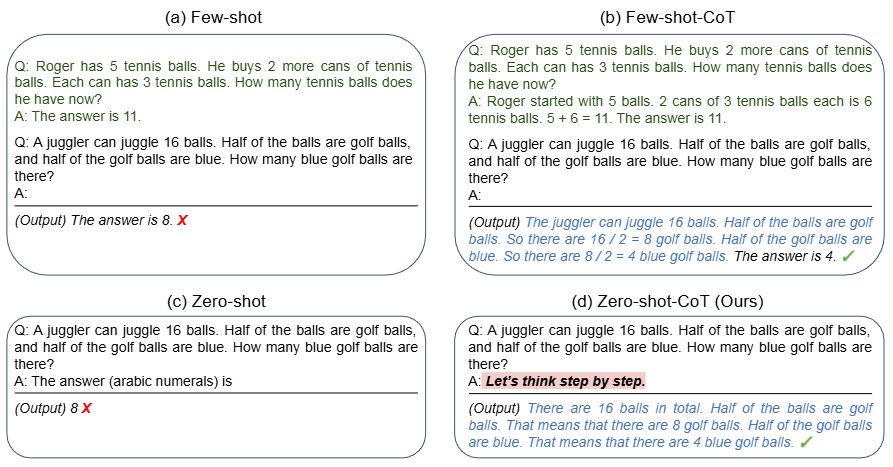
この創発の具体的な証拠の一つが、「Zero-shot Chain-of-Thought (Zero-shot-CoT)」と呼ばれる現象です。
2022年に発見されたこの手法は、大規模なLLM(例:GPT-3 175B)に対し、何の例示も与えずに、ただ「Let’s think step by step (ステップ・バイ・ステップで考えよう)」という簡単な指示(プロンプト)を追加するだけで、複雑な多段階推論タスクの正答率が劇的に向上することを示しました。例えば、算術タスクにおいて、この一文だけで正答率が急上昇した例が報告されています。
この現象は、高度な推論能力が、人間が明示的にプログラミングしたものではなく、大規模なスケールにおいて副産物として「創発」し、モデル内に潜在的に存在していたことを強く示唆しています。これは、「大規模モデルは、単にエラーを減らすだけでなく、小規模モデルが原理的に解けなかった質的に新しいタスクを解く能力を獲得する」という、質的転化の強力な証拠となります。
実装のヒント:低コストで潜在能力を引き出す「推論最適化」
Zero-shot-CoTの発見がビジネスにもたらす最大の利点は、大規模なインフラ投資を伴わずに、既存のLLMの複雑な推論能力を最大限に引き出すための戦略を提供することです。これは推論最適化のための強力な実装戦略です。
技術的利点(効率的な利用):
プロンプティング技術、特にCoTの適用は、LLMが潜在的に持っている多段階のロジック構築能力を顕在化させます。これを応用することで、複雑な法規制のチェック、財務分析における多段階ロジックの適用、あるいはコード生成の事前プランニングなど、逐次的な推論を必要とする業務の自動化がより高い信頼性で可能になります。
戦略的な投資判断:
ただし、学術界では、この「創発」が、研究者が選んだ評価指標が生み出す「幻想」であるという反論も存在します。真の能力は滑らかに向上しているものの、評価指標が不連続であるために急激にジャンプしたように見えるだけではないか、という論争です。
そのため、闇雲にモデルを大型化するスケーリング戦略に巨額のリソースを投じるのではなく、Zero-shot-CoTやそれを応用したアーキテクチャ設計、すなわちプロンプティング技術による「推論最適化」にリソースを集中投下することが、より効率的で戦略的な投資判断となり得ます。
| No. | プロンプトテクニック | 概要 |
|---|---|---|
| 1 | Basic/Standard/Vanilla Prompting | LLMに直接クエリを投げかける最も基本的な方法。特別なエンジニアリングは行わない。 |
| 2 | Chain-of-Thought (CoT) | 複雑な問題を小さな中間ステップに分解し、順を追って解決する方法。人間の思考プロセスを模倣している。 |
| 3 | Self-Consistency | 複数の推論パスを生成し、最も一貫性のある答えを選択する手法。複雑な推論問題に有効。 |
| 4 | Ensemble Refinement (ER) | CoTとSelf-Consistencyを組み合わせ、複数の生成を行い、それらを基に改善された説明と回答を生成する。 |
| 5 | Automatic Chain-of-Thought (Auto-CoT) | クエリをクラスタリングし、各クラスタから代表的なクエリを選んでゼロショットCoTで推論チェーンを生成する自動化手法。 |
| 6 | Complex CoT | 複雑なデータポイントを訓練例として使用し、デコード時に最も複雑な推論チェーンから多数決で回答を選択する手法。 |
| 7 | Program-of-Thoughts (PoT) | CoTを拡張し、Pythonプログラムを生成して計算部分をPythonインタプリタに委ねる手法。数値推論に特に有効。 |
| 8 | Least-to-Most | 問題を部分問題に分解し、順次解決していく2段階の手法。例示よりも難しい問題にも対応可能。 |
| 9 | Chain-of-Symbol (CoS) | 自然言語の代わりに記号を使用して空間的関係を表現する手法。空間に関する質問応答タスクに特に有効。 |
| 10 | Structured Chain-of-Thought (SCoT) | プログラム構造(シーケンス、分岐、ループ)を使用して中間推論ステップを構造化し、より正確なコード生成を行う手法。 |
| 11 | Plan-and-Solve (PS) | 問題を小さな部分問題に分割する計画を立て、その計画に従って解決する2段階の手法。CoTの短所を改善している。 |
| 12 | MathPrompter | 数学的問題解決のための4段階の手法。代数式の生成、解析的解決、変数の値の代入、最終的な計算を行う。 |
| 13 | Contrastive CoT/ Contrastive Self-Consistency | 正例と負例の両方を提示することで、LLMの推論能力を向上させる手法。CoTとSelf-Consistencyの拡張版。 |
| 14 | Federated Same/Different Parameter Self-Consistency/CoT (Fed-SP/DP-SC/CoT) | クラウドソーシングされた類似クエリを使用してLLMの推論能力を向上させる手法。パラメータの同一性に基づいて2つの変種がある。 |
| 15 | Analogical Reasoning | 人間の類推的推論を模倣し、元の問題に類似した例を生成して解決し、その後元の問題に適用する手法。 |
| 16 | Synthetic Prompting | LLMを使用して合成例を生成し、既存の手作りの例に追加する手法。2段階のプロセスで生成と推論を行う。 |
| 17 | Tree-of-Thoughts (ToT) | 問題解決を木構造で表現し、各ノードを部分解とする探索手法。LLMに思考の生成と評価を行わせ、最適な解を探索する。 |
| 18 | Logical Thoughts (LoT) | 論理的等価性を利用してLLMのゼロショット推論能力を向上させる手法。推論チェーンの検証と修正を行う。 |
| 19 | Maieutic Prompting | 深い再帰的推論を用いて、様々な仮説に対する帰納的説明を引き出す手法。矛盾する選択肢を協調的に排除する。 |
| 20 | Verify-and-Edit (VE) | CoTで生成された推論チェーンを事後編集し、より事実に即した出力を得る3段階の手法。 |
| 21 | Reason + Act (ReAct) | 推論と行動を組み合わせ、言語推論と意思決定タスクを解決する手法。言語的推論トレースと行動を交互に生成する。 |
| 22 | Active-Prompt | タスク固有の例を識別し、フューショット設定でLLMをプロンプトする際に最も関連性の高いデータポイントを使用する4段階の手法。 |
| 23 | Thread-of-Thought (ThoT) | 長い混沌としたコンテキストを扱うための2段階の手法。文書の各セクションを分析・要約し、その出力に基づいてクエリに回答する。 |
| 24 | Implicit Retrieval Augmented Generation (Implicit RAG) | LLM自体に与えられたコンテキストから重要な部分を抽出させ、それに基づいてクエリに回答させる手法。 |
| 25 | System 2 Attention (S2A) | 不適切なコンテキストによる誤判断を防ぐ2段階の手法。コンテキストを再生成して不要な部分を除去し、その結果を使用して回答を生成する。 |
| 26 | Instructed Prompting | 問題記述の無関係な情報を無視するようLLMに明示的に指示する1段階の手法。 |
| 27 | Chain-of-Verification (CoVe) | 幻覚を防ぎ、性能を向上させるための4段階の手法。基準回答の生成、検証クエリの生成、検証、修正を行う。 |
| 28 | Chain-of-Knowledge (CoK) | 幻覚に対処するための3段階の手法。予備的な根拠と回答の準備、動的な知識適応、回答の統合を行う。 |
| 29 | Chain-of-Code (CoC) | LLMのコード指向の推論を改善する拡張手法。コードの記述だけでなく、特定の行の期待される出力を選択的にシミュレートする。 |
| 30 | Program-aided Language Models (PAL) | 自然言語とプログラミング言語の文を交互に生成し、最終的にPythonインタプリタを使用して回答を得る手法。 |
| 31 | Binder | LLMの機能を1つのAPIとしてプログラミング言語にバインドし、より広範なクエリに対応する2段階のニューラル記号的手法。 |
| 32 | Dater | 大きなテーブルを関連する小さなサブテーブルに分解し、複雑な自然言語クエリを論理的・数値的計算に分解する3段階の手法。 |
| 33 | Chain-of-Table | CoTを表形式データに適用した3段階の手法。テーブル操作の動的計画、引数生成、最終回答生成を行う。 |
| 34 | Decomposed Prompting (DecomP) | 複雑な問題をより単純な部分問題に分解し、それぞれを専用のLLMに委ねる手法。階層的、再帰的、または外部API呼び出しによる分解が可能。 |
| 35 | Three-Hop Reasoning (THOR) | 感情/感情理解タスクのための3段階の手法。アスペクトの特定、詳細な意見の抽出、感情極性の推論を行う。 |
| 36 | Metacognitive Prompting (MP) | 認知心理学の概念に基づく5段階の手法。テキストの理解、予備的判断、批判的評価、最終決定、自信度評価を行う。 |
| 37 | Chain-of-Event (CoE) | 要約タスクのための4段階の手法。イベントの抽出、分析・一般化、フィルタリング、統合を行う。 |
| 38 | Basic with Term Definitions | 基本的なプロンプト指示に医学用語の定義を追加する手法。しかし、固定の定義がLLMを混乱させる可能性がある。 |
| 39 | Basic + Annotation Guideline-Based Prompting + Error Analysis-Based Prompting | 臨床固有表現認識タスクのための3つのコンポーネントを組み合わせた手法。基本情報、アノテーションガイドライン、エラー分析に基づく指示を含む。 |
計算の基盤:知性は「1/0」のデジタルシステムで実現できるのか(計算主義論争)
LLMがどれほど複雑な推論をしても、その基礎が「1」か「0」のビットで動く古典的なチューリングマシン(現在のデジタルコンピュータ)である限り、真の知性は生まれないのではないか、という根源的な問いがあります。これは計算主義論争の核心です。
課題:「非計算的」プロセスへの哲学的異議
この懐疑論の代表格が、ノーベル物理学賞受賞者であるロジャー・ペンローズ氏です。彼は、人間の意識や数学的真理を「ひらめく」能力には、現在のアルゴリズム(計算)では再現不可能な「非計算的」なプロセスが含まれると主張しました。
ペンローズ氏が提唱した量子脳理論(Orch-OR)が正しければ、意識は脳内の微小管における量子効果によって生じるため、シリコンチップに基づく「1/0」のデジタル基盤をいくらスケーリングしても、意識や真の理解という質的な現象には原理的に到達できないことになります。
この議論は、哲学者ジョン・サール氏が提起した「中国語の部屋(Chinese Room)」の思考実験にも直結します。サール氏は、プログラム(構文)に従って記号を操作するコンピュータは、その記号が何を意味するのか(意味論)を理解していないため、知性を実現したとは言えない、と批判しました。
反論の核心:「物質」ではなく「機能」が知性を定義する
AI研究の理論的支柱となっているのは、この懐疑論とは正反対の機能主義(Functionalism)という哲学的立場です。機能主義によれば、精神状態や知性は、それを構成する物質(生物学的ニューロンやシリコン)ではなく、その機能、すなわち「入力に対する出力」という因果的役割の連鎖によって定義されます。
この考え方から、基盤独立性(Substrate Independence)という重要な帰結が導かれます。知性を定義するものが「計算」であるならば、その計算を実行する基盤は本質的な問題ではない、ということです 。シリコンチップであろうと、生物学的ニューロンであろうと、同じ計算が実装されている限り、知性は宿るという主張です。
サールの「中国語の部屋」批判に対しても、機能主義からは反論が可能です。最も標準的な反論は、「システム応答」と呼ばれ、部屋の中の人間(CPU)ではなく、人間+ルールブック+記号全体からなる「システム全体」が中国語を理解していると見なします。また、LLMの徹底的な学習プロセス(最適化)こそが、意味(理解)を生み出すという目的論的意味論による反駁も提示されています 。
実装のヒント:未来のハードウェア戦略と「異質な知性」
機能主義と計算主義の立場は、現在のデジタル基盤(1/0)上でAIの開発を進めることに対し、哲学的・理論的な正当性を与えます。
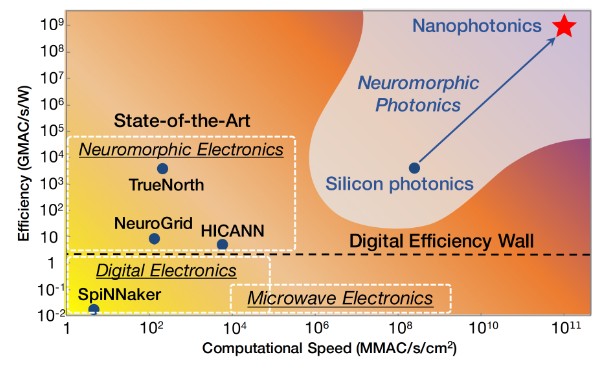
しかし、現行のデジタルシステムは、消費電力やメモリと計算の分離といった点で限界を抱えています。将来的にAIをより効率的に運用するため、脳の構造と動作原理を模倣し、計算と記憶を統合するニューロモーフィック・コンピューティング(Neuromorphic Computing)など、次世代アーキテクチャの研究開発が進められています。これは、「1/0」の限界を工学的に克服しようとする試みです。
また、デジタル基盤で実現される知性は、生物の知性が持つエネルギー制約とは根本的に異なる環境で動作するため、「異質な知性(Alien Intelligence)」となる可能性が高いと指摘されています。この異なる特性(例:超人的な計算速度と、体験的理解の欠如)を理解することが、将来的なAIの活用範囲を見極める上での鍵となります。
おわりに
本記事で言及したように、大規模言語モデル(LLM)が人間と同じ意味での「知性」や「意識」を持っているかという問いには、依然として結論が出ていません。しかし、LLMが単なる確率的オウムによる表層的な模倣を超え、抽象的で汎用的な推論エンジンとして機能し始めていることは確かです。
興味深いことに、LLMの「限界」に対する懐疑論こそが、AI研究全体を前進させる最も重要な駆動力となっています。
- 「接地(Grounding)の欠如」という批判(接地論争)は、RAG (Retrieval-Augmented Generation) や Mind’s Eye のような外部シミュレーションとの連携戦略を生み出し、信頼性の向上を可能にしました。
- 「確率的オウム」という批判は、Zero-shot CoT (Chain-of-Thought) の発見を促し、プロンプトによる潜在的な推論能力の解明と活用(効率性の向上)を促しました。
我々AI利用者にとって重要なのは、この理論的両輪を理解し、単純なスケーリング競争に巻き込まれないことです。RAGによる事実的信頼性の担保、CoTによる複雑な推論の最適化、そしてニューロモーフィック・コンピューティングのような次世代計算基盤への戦略的な視点を持つことが、LLMの能力を最大限に引き出し、競争優位性を確立するための鍵となります。
More Information
- arXiv:2205.11916, Takeshi Kojima et al., 「Large Language Models are Zero-Shot Reasoners」, https://arxiv.org/abs/2205.11916
- arXiv:2206.07682, Jason Wei et al., 「Emergent Abilities of Large Language Models」, https://arxiv.org/abs/2206.07682
- arXiv:2210.05359, Ruibo Liu et al., 「Mind’s Eye: Grounded Language Model Reasoning through Simulation」, https://arxiv.org/abs/2210.05359
- arXiv:2304.15004, Rylan Schaeffer et al., 「Are Emergent Abilities of Large Language Models a Mirage?」, https://arxiv.org/abs/2304.15004
- arXiv:2311.09533, Xi Ye et al., 「Effective Large Language Model Adaptation for Improved Grounding and Citation Generation」, https://arxiv.org/abs/2311.09533
- arXiv:2405.05741, Jinyang Wu et al., 「Can large language models understand uncommon meanings of common words?」, https://arxiv.org/abs/2405.05741
- arXiv:2406.06485, Ruoyao Wang et al., 「Can Language Models Serve as Text-Based World Simulators?」, https://arxiv.org/abs/2406.06485
- arXiv:2407.00118, Xinji Mai et al., 「From Efficient Multimodal Models to World Models: A Survey」, https://arxiv.org/abs/2407.00118
- arXiv:2407.03778, Stefanie Krause et al., 「From Data to Commonsense Reasoning: The Use of Large Language Models for Explainable AI」, https://arxiv.org/abs/2407.03778
- arXiv:2410.19923, John Gkountouras et al., 「Language Agents Meet Causality — Bridging LLMs and Causal World Models」, https://arxiv.org/abs/2410.19923
- arXiv:2411.08794, Chang Yang et al., 「Evaluating World Models with LLM for Decision Making」, https://arxiv.org/abs/2411.08794
- arXiv:2412.16443, Charles Luo, 「Has LLM Reached the Scaling Ceiling Yet? Unified Insights into LLM Regularities and Constraints」, https://arxiv.org/abs/2412.16443
- arXiv:2504.07440, Yixin Cao et al., 「Model Utility Law: Evaluating LLMs beyond Performance through Mechanism Interpretable Metric」, https://arxiv.org/abs/2504.07440
- arXiv:2505.00985, Yash Goel et al., 「Position: Enough of Scaling LLMs! Lets Focus on Downscaling」, https://arxiv.org/abs/2505.00985
- arXiv:2505.03368, Stef De Sabbata et al., 「Geospatial Mechanistic Interpretability of Large Language Models」, https://arxiv.org/abs/2505.03368
- arXiv:2506.06725, Guillaume Levy et al., 「WorldLLM: Improving LLMs’ world modeling using curiosity-driven theory-making」, https://arxiv.org/abs/2506.06725
- arXiv:2507.00885, Nicholas Lourie et al., 「Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check」, https://arxiv.org/abs/2507.00885
- arXiv:2507.19703, Peter V. Coveney et al., 「The wall confronting large language models」, https://arxiv.org/abs/2507.19703
- arXiv:2507.22928, Xi Chen et al., 「How does Chain of Thought Think? Mechanistic Interpretability of Chain-of-Thought Reasoning with Sparse Autoencoding」, https://arxiv.org/abs/2507.22928
- arXiv:2509.09677, Akshit Sinha et al., 「The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs」, https://arxiv.org/abs/2509.09677
関連記事

LangFair: LLMアプリケーションのバイアスと公平性を評価する
近年、大規模言語モデル(LLM) は、テキスト生成、分類、推薦など、様々な分野で活用されています。しかし、LLMにはバイアスが存在することが指摘されており、特定のグループに対して不公平な結果を生み出す可能性があります。こ […]

マルチモーダル推論の最前線と技術的ブレークスルー
AIが高度化する現代において、推論能力は人間知能の中核をなす重要な要素です。近年、大規模言語モデル(LLM)は、算術、常識推論、記号推論といった分野で目覚ましい進歩を遂げ、その推論能力を大きく向上させてきました。しかし、 […]

Few-Shot Learning 入門: 少ないデータで機械学習モデルを構築する
私たちの周りでは、日々新しい技術やサービスが登場し、機械学習(ML)はそれらを支える中心的な役割を担っています。しかし、従来の機械学習モデルを訓練するには、大量のデータが必要となるのが一般的です。 新しい感染症が突如とし […]