Deep Research 完全ガイド: 自律型LLMエージェントとアーキテクチャ

近年、大規模言語モデル(LLM)は、単にテキストを生成するだけでなく、複雑な問題解決を可能にする強力なエージェントへと急速に進化しています。しかし、現実世界の多くのオープンエンドなタスクは、単一のプロンプトや標準的なRAG(検索拡張生成)では対応できない、批判的思考や複数ソースの検証可能な出力を要求します。
この課題に応えるのが、Deep Research (DR)という新たなパラダイムです。DRは、LLMの推論能力と検索エンジンなどの外部ツールを組み合わせることで、LLMを複雑なタスクを完了できる「リサーチエージェント」として機能させることを目指します。従来のRAGが静的な検索拡張に留まるのに対し、DRはより柔軟で自律的なワークフローを採用し、証拠に基づいた一貫性のあるレポートの生成を目指します。
今回は、このDeep Researchシステムの全体像を徹底解説します。具体的には、システムの鍵となる4つの主要な構成要素(クエリ計画、情報取得、メモリ管理、回答生成)、実務的な最適化技術(プロンプティング、教師ありファインチューニング、エージェント的強化学習)、そして実務における応用例について掘り下げていきます。
1. Deep Research の基礎概念
1.1 Deep Researchの定義と3つの進化フェーズ
Deep Research (DR)とは、LLM(大規模言語モデル)にプランニング、エビデンス収集、分析、レポート作成を含むエンドツーエンドのリサーチワークフローを組み込むことを目指すパラダイムです。これにより、最小限の人間による監視で、一貫性があり、根拠に基づいたレポートを生成することが可能になります。
DRシステムは、以下に示す4つの主要な構成要素を反復的に実行するエージェントとして機能します。
- クエリの計画(Query Planning)
- 様々なソースからの証拠取得とフィルタリング(Information Acquisition)
- 作業メモリの維持・改訂(Memory Management)
- 検証可能な回答の統合(Answer Generation)
DRの能力は、その進化の度合いに応じて、以下の3つのフェーズ(段階的なロードマップ)で捉えられています。
- フェーズ I: エージェント的検索 (Agentic Search)
- この段階では、正確な情報源を見つけ、引用付きの簡潔な回答を抽出することに特化します。評価の焦点は、リコール率(recall@k)や正確なマッチングといった、情報の正確性と効率性です。
- フェーズ II: 統合リサーチ (Integrated Research)
- 隔離された事実の抽出を超越し、様々なエビデンスを統合し、不確実性に対応しながら、一貫性のある構造化された長文レポート(例:市場分析、政策概要)を生成します。評価は、長文の品質、ファクト検証、構造的な一貫性へと移行します。
- フェーズ III: フルスタックAIサイエンティスト (Full-stack AI Scientist)
- 単なる情報集約を超えて、仮説生成、実験的検証の実施、既存の主張への批判、そして斬新な視点の提案といった、科学的な創造性を目指す、最も野心的な段階です。このフェーズの評価は、発見の新規性と洞察力に重点が置かれます。
1.2 従来型RAGとの決定的な違い
Deep Researchは、従来のRAG (Retrieval-Augmented Generation) の抱える根本的な限界を克服するために設計されました。
- 柔軟なワークフローとツールの利用
- 従来のRAGシステムが静的な検索ループで動作し、事前インデックス化されたコーパスにのみ依存するのに対し、DRは、検索エンジンやWeb API、コード実行環境といった動的な環境と、マルチステップでツール拡張された相互作用を実行できます。これにより、最新情報へのアクセスや仮説の検証が可能になります。
- 長期的な計画と自律性
- 複雑なリサーチ課題は、複数のサブタスクの調整や、長期的なコンテキスト(文脈)管理を必要とします。DRは、閉ループ制御とマルチターン推論を通じて、長期的な目標に向けてワークフローを自律的に計画・最適化することで、このRAGの限界に対処します。
- 検証可能な信頼性
- オープンエンドな設定では、LLMはハルシネーション(誤情報生成)を起こしやすいですが、DRシステムは、自然言語の出力を根拠のある証拠と整合させる検証可能なメカニズムを導入し、より信頼性の高いインターフェースを確立します。
| 能力(主要機能)(Capability / Key Feature) | 標準RAG(Standard RAG) | エージェント型検索(Agentic Search) | 統合型リサーチ(Integrated Research) | フルスタックAIサイエンティスト(Full-stack AI Scientist) |
|---|---|---|---|---|
| 検索エンジンへのアクセス(Search Engine Access) | ✓ | ✓ | ✓ | ✓ |
| 各種ツールの利用(例:Web API)(Use of Various Tools) | ✗ | ✓ | ✓ | ✓ |
| 実験のためのコード実行(Code Execution for Experiment) | ✗ | ✗ | ✗ | ✓ |
| 行動修正のための内省(Reflection for Action Correction) | ✗ | ✓ | ✓ | ✓ |
| タスク解決のためのメモリ管理(Task-solving Memory Management) | ✗ | ✓ | ✓ | ✓ |
| イノベーションおよび仮説提案(Innovation and Hypothesis Proposal) | ✗ | ✗ | ✗ | ✓ |
| 長文回答の生成と検証(Long-form Answer Generation & Validation) | ✓ | ✗ | ✓ | ✓ |
| 行動空間(Action Space) | 狭い(Narrow) | 広い(Broad) | 広い(Broad) | 広い(Broad) |
| 推論の時間的スコープ(Reasoning Horizon) | 単一ステップ(Single) | 長期(Long-horizon) | 長期(Long-horizon) | 長期(Long-horizon) |
| ワークフロー構成(Workflow Organization) | 固定(Fixed) | 柔軟(Flexible) | 柔軟(Flexible) | 柔軟(Flexible) |
| 出力形式・用途(Output Form and Application) | 短文応答(Short Span) | 短文応答(Short Span) | レポート(Report) | 学術論文(Academic Paper) |
2. Deep Research システムのコアアーキテクチャ
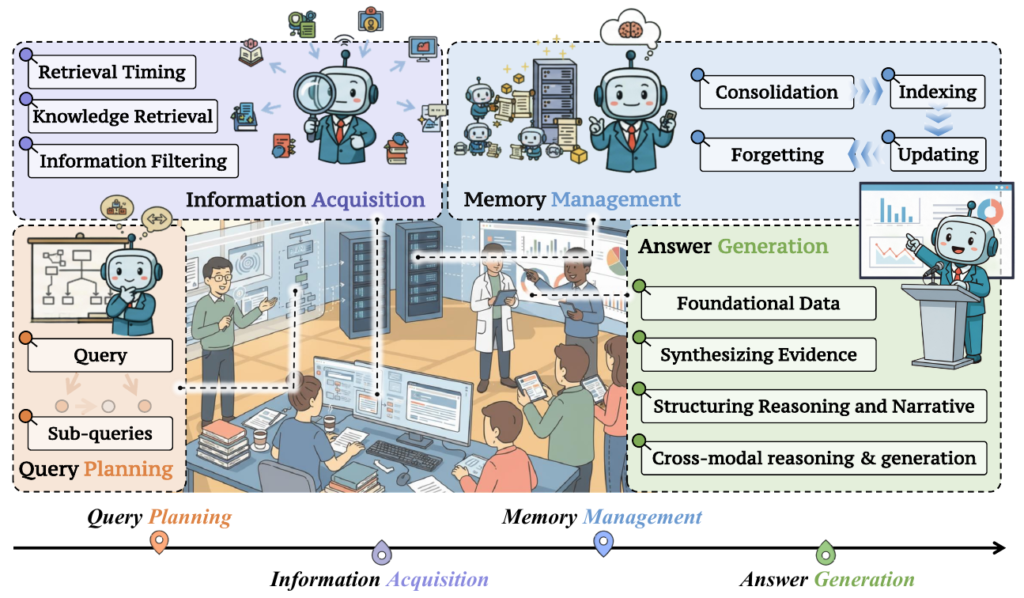
Deep Research (DR) システムは、複雑なリサーチ課題を解決するために、(i) クエリ計画、(ii) 情報取得、(iii) メモリ管理、(iv) 回答生成という4つの相互接続されたコンポーネントを反復的に循環する閉ループワークフローとして構築されます。これにより、システムは自律的に動作し、リサーチを深めることができます。
2.1 クエリ計画 (Query Planning): 複雑なタスクの分解
クエリ計画は、複雑で論理的に入り組んだ質問を、段階的に処理できる実行可能なサブクエリ(サブタスク)の構造化されたシーケンスに変換するプロセスです。この分解戦略を採用することで、ステップワイズの推論と必要な知識の取得が可能になり、最終的な出力の信頼性と正確性が向上します。
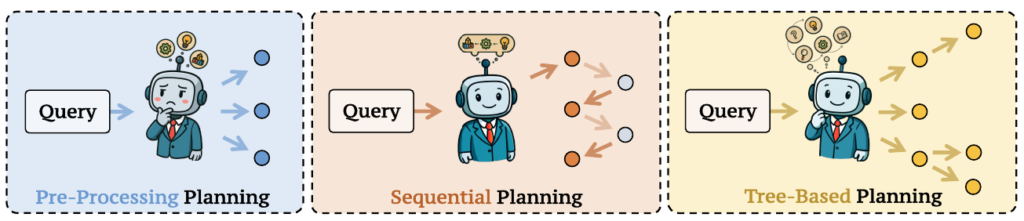
主な実装パターンは以下の3つに大別されます。
- 並列計画 (Parallel Planning): 元のクエリを複数の独立したサブクエリに一度に分解し、同時処理することで効率性を追求します。しかし、サブクエリ間に論理的な依存関係がある場合、対応が難しいという課題があります。
- 逐次計画 (Sequential Planning): 各分解ステップが、以前のラウンドで得られた中間出力やエビデンスに基づいて構築される反復的なプロセスです。これにより、複雑な推論を必要とするタスクにおいて、クエリ経路を動的に適応させることができます。
- ツリーベース計画 (Tree-based Planning): 各サブクエリを構造化された探索空間(木やDAG)内のノードとして扱い、並列と逐次の利点を統合します。MCTS(モンテカルロ木探索)などの高度な探索アルゴリズムを活用することで、柔軟かつ包括的な知識取得を促進します。
2.2 情報取得 (Information Acquisition): タイミングとフィルタリングの最適化
DRにおける情報取得は、単なる静的なテキスト検索(語彙的検索、意味的検索)を超え、リアルタイム情報アクセスを可能にする商用ウェブ検索の利用へと進化しています。
また、マルチモーダル検索の活用も進んでいます。これは、テキストベースの手法が見逃しがちな、図表、テーブル、レイアウトといった視覚的に符号化された情報を取得するものです。これにより、テーブルセルやグラフの座標などの特定のデータポイントにリンクされた、根拠に基づく検証可能な引用が可能になります。
さらに、無駄な検索を防ぐために適応的検索タイミング (Adaptive Retrieval Timing)が導入されています。モデルが知識不足を認識した場合にのみ検索ツールを起動する機能で、モデルの確信度(確率的、一貫性ベース、内部状態のプローブなど)を推定することで実現されます。
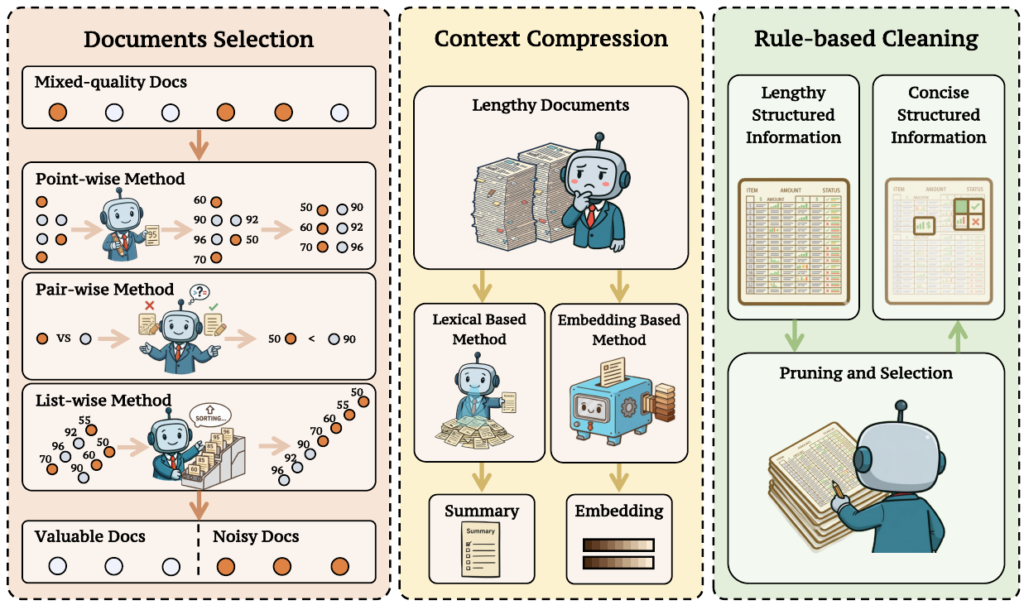
取得した情報にはノイズが含まれることが多いため、情報フィルタリング (Information Filtering)によって、無関係なコンテンツやノイズを除去し、有用なコンテンツの密度を高めることが重要です。主な手法として、ドキュメントの関連性で順位付けするドキュメント選択、冗長な情報を要約するコンテキスト圧縮、HTMLなどの構造化情報から不要な要素を取り除くルールベースのクリーニングが用いられます。
2.3 メモリ管理 (Memory Management): 長期的な文脈維持の鍵
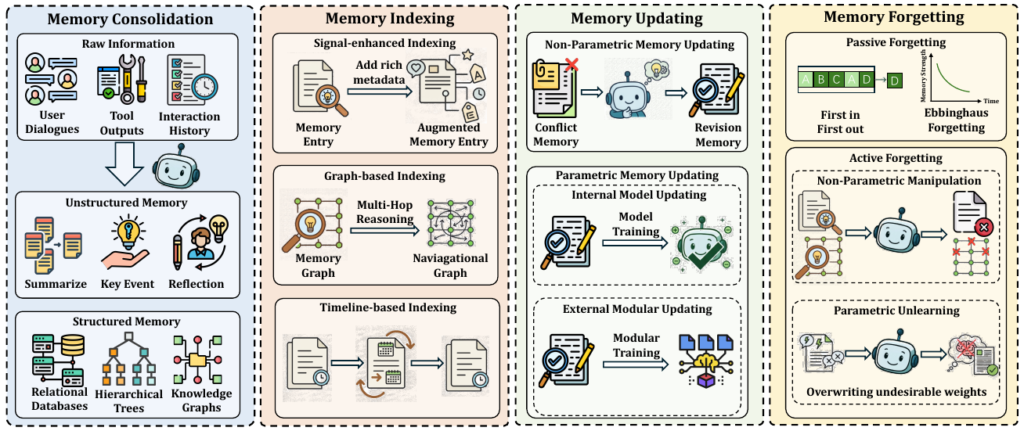
Deep Research (DR) エージェントにとって、メモリ管理は複雑で長期にわたるタスクにおいて、使用するコンテキストの一貫性と関連性を維持するために不可欠な機能です。この機能こそが、DRエージェントを単純なRAGシステムから根本的に区別する要素となっています。メモリ管理は主に、統合、インデックス作成、更新、忘却という4つのコアな運用で成り立っています。
- メモリ統合 (Memory Consolidation): 短期的な対話履歴やツールの出力を、要約、キーイベントログ、または知識グラフのような構造化された表現に変換し、耐久性のある長期メモリ表現を作成します。
- メモリインデックス作成 (Memory Indexing): 統合されたメモリの上に、効率的な情報検索をサポートするための検索経路(例:グラフベース、タイムラインベース)を構築します。
- メモリ更新 (Memory Updating): 新しい情報や環境からのフィードバックに応答して、モデルの外部(非パラメトリック)または内部(パラメトリック)で既存の知識を修正し、正確性を維持します。
- メモリ忘却 (Memory Forgetting): 古い、無関係な、または誤っている可能性のあるコンテンツを選択的に除去または抑制する機能的なプロセスであり、ノイズのフィルタリングに貢献します。
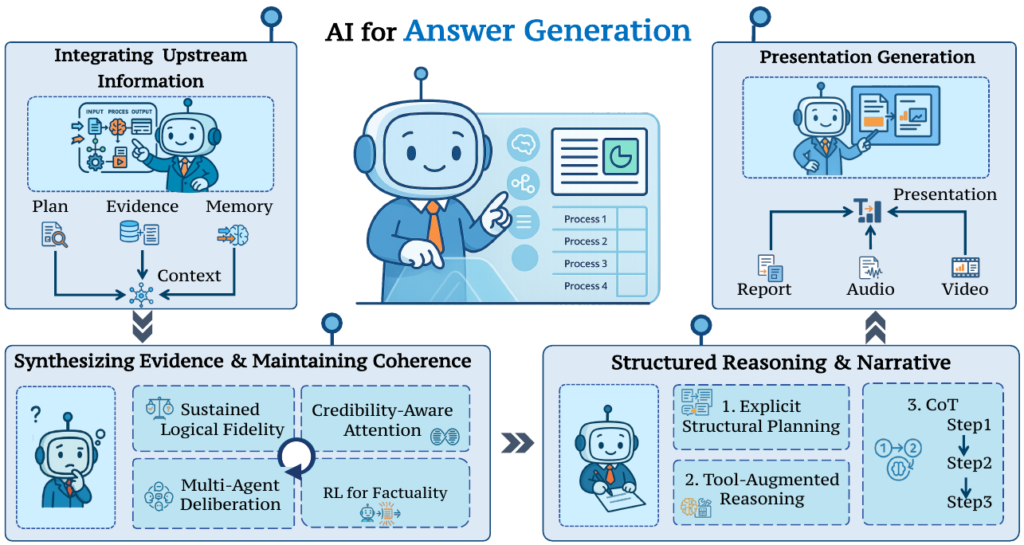
2.4 回答生成 (Answer Generation): 証拠の統合と構造化
回答生成は、DRシステムにおける最終段階です。ここでは、上流のクエリ計画、取得情報、メモリシステムからの情報を統合し、首尾一貫した、裏付けのある包括的な回答が生成されます,。
特にリサーチレベルの質問では、相反する情報源が出現することが多いため、高度なエビデンス合成が求められます。これに対処するため、信頼性に基づいて証拠に重み付けをする信頼性認識アテンション、複数のエージェントが証拠を議論するマルチエージェント審議、または事実の正確さを報酬とする強化学習が採用されています。
また、単なる事実の正確さだけでなく、説明可能性と論理的厳密性を確保するため、思考の連鎖 (Chain-of-Thought, CoT) プロンプティングや、アウトライン生成を伴う明示的な構造化計画(例:RAPID)が用いられます。
さらに、回答生成の最前線はテキストを超え、テキスト、図、表、音声などの情報を統合したマルチモーダルなプレゼンテーション生成(例:スライドデッキ、動画)へと進化している点も注目されています。
3. 実装を加速する最適化戦略
Deep Researchシステムの機能性と自律的な性能を向上させるため、実装においては主に以下の3つのパラダイムが用いられます。これらは、システム内の主要なコンポーネントを効果的に連携させ、全体としてより信頼性の高いタスク完了を目指すものです。
3.1 ワークフロー・プロンプト・エンジニアリング
これは、複雑なワークフローを構築し、複数の専門エージェント間で協調作業を行う方法です。AnthropicのDRシステムを例にとると、まずオーケストレーターエージェントが入力クエリの難易度を分析し、リサーチ戦略と、エージェント数やツール使用回数などの予算を割り当てます。メインクエリはモジュール式のサブタスクに分解され、各ワーカーエージェントには、明確な目的、出力スキーマ、引用ポリシーが指定された構造化プロンプトとして委任されます。ワーカーエージェントは並行して作業を進め、オーケストレーターが結果を監視し、競合を解決しながら、検証済みの調査結果を首尾一貫したレポートに統合します。このアプローチは、モジュール化された委任と明示的な予算管理により、スケーラブルで信頼性の高いリサーチを実現します。
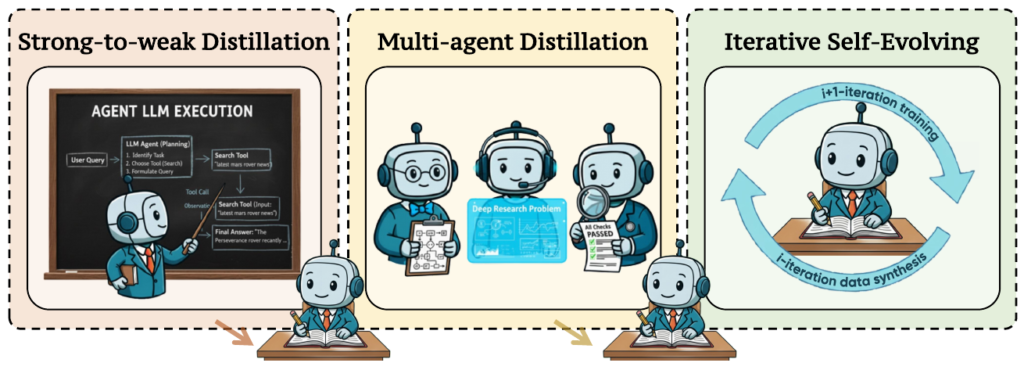
3.2 教師ありファインチューニング (SFT) を用いた技術
SFTは、オンラインの強化学習(RL)を開始する前の「コールドスタート」として、エージェントに基本的なタスク解決スキルを持たせるために利用されます。熟練した動作を収集する手間を省くため、高品質なトレーニングデータ合成が鍵となります。
- Strong-to-weak Distillation(強力モデルからの蒸留): GPT-4のような強力なティーチャーシステムから、高品質なタスク解決の軌跡を抽出し、より小さなスチューデントモデルに転送する手法です。マルチエージェントシステムをティーチャーとして活用することで、より多様で高度な推論軌跡を生成し、スチューデントモデルの汎化能力を強化できます。
- Iterative Self-Evolving(反復的な自己進化): モデルが継続的に新しいトレーニングデータを生成し、それを用いて自身をファインチューニングする自律的なサイクルプロセスです。これにより、外部モデルや人間によるアノテーションへの依存を減らし、スケーラブルなトレーニングが可能になります。ただし、反復が進むにつれてデータの質の低下や自己強化学習エラーが蓄積するリスクも伴います。
3.3 エンドツーエンドのエージェント的強化学習 (RL)
RLは、PPO(Proximal Policy Optimization)やGRPO(Group Relative Policy Optimization)などのアルゴリズムを用いてDRエージェントを訓練し、計画、行動、最終回答生成を一貫して柔軟に行えるようインセンティブを与える手法です。
エージェントの出力品質を評価する報酬設計は非常に重要です。報酬としては、Exact Match (EM) やF1スコアなどのルールベースの報酬、あるいは、正確性、完全性、引用品質などの事前に定義された評価基準に基づき外部LLMがスコアを割り当てるLLM-as-judge報酬が一般的に使用されます。
最適化のスコープは、以下の2つに分かれます。
- 特定モジュールの最適化: クエリプランナーなど、DRシステム内の単一のコアコンポーネントにRLを適用します。これにより、より正確な信用割当が可能になり、コストを抑えつつ性能を向上できます。
- パイプライン全体の最適化: クエリ分解、検索、推論、回答生成など、インプットからアウトプットまでの全プロセスを共同で最適化します。全体的な性能向上につながりますが、報酬のスパース性やトレーニングの不安定性といった課題に直面することがあります。
4. Deep Researchシステムの応用例と今後の展望
Deep Research (DR) システムは、その自律性と検証可能性から、多岐にわたる複雑なタスクに応用されており、AIの能力を次の段階へと押し上げています。
4.1 実用的な応用分野
DRシステムの応用は、主に以下の3つのシナリオに分類されます,。
- エージェント的情報探索 (Agentic Information Seeking):
DRエージェントは、単一の質問回答(QA)タスクではなく、マルチステージで反復的なプロセスとして情報探索を行います。具体的には、HotpotQA のようなマルチホップQAや、GAIA、GPQA のような複雑な推論を要求する質問に対応します。評価は、従来の静的なコーパスではなく、BrowseComp や Mind2Web のようなリアルタイムのWeb環境での動的な情報収集能力に焦点を移しています。 - 包括的レポート生成 (Comprehensive Report Generation):
システムは、複数の情報源やモダリティ(テキスト、図、表など)を統合し、構造化された論理的に一貫性のある長文レポートを生成します。応用例には、サーベイ論文(AutoSurvey 、ReportBench)、長期レポート、そしてコンテンツとビジュアルを統合したポスター やスライド の生成が含まれます。 - AI for Research (科学的発見):
これは、単なる情報集約を超えて、科学的発見を加速させることを目指す、最も野心的な段階(フェーズIII: フルスタックAIサイエンティスト)です。応用には、アイデア生成、実験実行、学術論文の査読(Peer Review)、ソフトウェアエンジニアリング などが含まれ、新しい知識や視点の創出を目指します。
4.2 実装者が直面する主要な課題
DRシステムのさらなる普及に向けて、いくつかの技術的な課題に直面しています。
- RLトレーニングの不安定性:
マルチターン設定におけるPPOやGRPOといった強化学習(RL)アルゴリズムは、不安定性を抱えています。これは、報酬の急激な低下や、タスクを進行させない無効な応答の生成(ボイドターン、エコー・トラップ など)として現れます。解決策としては、無効なターンを含む軌跡をフィルタリングすること や、初期の探索行動を維持するためのコールドスタート手法を設計すること が挙げられます。 - メモリの長期的な進化:
既存のメモリシステムは、過去のイベントを記録する受動的な知識バッファとして機能することが多く、ゴール駆動型の適応性に欠けています。今後は、人間の認知に着想を得た構造化メモリ(知識グラフなど)を導入すること、そして最終タスクの成果によって記憶の操作を最適化するRLパラダイムへ移行することが重要視されています。 - 新規性とハルシネーションの境界線:
DRの目標は斬新な仮説を生成することですが、表面上は独創的に見える出力が、検証不可能な主張や根拠のない推論(ハルシネーション)と区別することが困難です。この課題を区別するためには、新規性のスコアリングと、主張が検証可能な外部証拠に基づいているかをチェックする検証機構を組み合わせる必要があります。
おわりに
Deep Research(DR)パラダイムは、LLM(大規模言語モデル)を単なる応答者から、反復的な推論、証拠の統合、検証可能な知識創造が可能な自律的な調査者へと変革する最前線に位置しています,。
DRシステムは、複雑な問題を分解するクエリ計画、リアルタイム情報を含む多様な情報を扱う情報取得、そして長期的な文脈を維持するメモリ管理といった洗練されたアーキテクチャを通じて、従来のRAGモデルの限界を超越します,,。特にメモリ管理は、DRエージェントを単純なRAGシステムから根本的に区別する要素です。
これらのアーキテクチャの理解は、単にテキストを生成するだけでなく、信頼性が高く、説明可能で、実世界の課題を解決できるエージェントを構築するための強固な基盤となります,。今後の進展は、マルチモーダル推論や人間の認知に着想を得た構造化メモリ,、そして強化学習の安定化 といった分野を通じて、より汎用的で信頼性の高いインテリジェンスへの進化が期待されています。
More Information
- arXiv:2512.02038, Zhengliang Shi et al., 「Deep Research: A Systematic Survey」, https://arxiv.org/abs/2512.02038
関連記事

Prompt Repetition: プロンプト反復によるLLMの改善
LLMの精度向上のために、日々プロンプトの試行錯誤を繰り返しているエンジニアは多いはずです。Google Researchの研究チームは、そのような課題に対し、非常にシンプルかつ強力な解決策である「Prompt Repe […]

Mixture of Experts (MoE) - 混合専門家モデルとは何か?
大規模言語モデル(LLM)は、自然言語処理からコンピュータビジョン、さらにそれ以上の領域に至るまで、様々な分野で大きな進歩を遂げています。LLMの驚異的な能力は、そのモデルサイズ、多様なデータセット、そしてトレーニング中 […]

画像認識アーキテクチャの進化大全: CNN・ViT・Mamba・MLPの比較
AI技術の急速な進歩により、画像認識は私たちの生活に深く浸透し、顔認証、自動運転、医療画像診断など、多岐にわたる分野で革新をもたらしています。この画像認識技術の発展を支えているのが、ディープラーニングにおけるモデルアーキ […]