AI学習データの品質管理 - 有害データ検出の最新手法

AI開発の潮流は、近年、「モデル中心AI(Model-Centric AI)」から、訓練データの品質向上に焦点を当てる「データ中心AI(Data-Centric AI)」へと大きく転換しました。AIシステムの最終的な精度は、モデルのアルゴリズムだけでなく、その学習源となるデータの品質に深く依存するためです。
ビジネスの現場では、データ品質の低さが直接的な経済的損失に繋がり、ある調査によれば、企業は質の悪いデータのために収益の15%から25%を失うと推定されています。このような背景から、AIモデルの性能、頑健性、そして公平性を保証するためには、データセット内に潜む有害なデータポイントを特定し、修正・除去する「データセットデバッグ」の技術が不可欠です。
本記事では、このデータセットデバッグを実現するための手法について、その分類から先進的なアプローチまでを解説いたします。
有害なデータの種類と定義
データ中心AI(Data-Centric AI)の時代において、AIモデルの性能を最大限に引き出すためには、訓練データセットの品質が極めて重要となります。この品質を損なう要因となるのが「有害なデータポイント」です。効果的なデータセットデバッグを実践するためには、まず、これらの有害なデータポイントがどのような種類に分類されるのかを深く理解することが不可欠です。なぜなら、これらのデータポイントはモデルの学習プロセスを妨げ、結果として最終的な推論性能に悪影響を及ぼす可能性があるからです。
ここでは、主な有害データの種類とそれぞれの特徴について解説します。
外れ値(Outliers)
外れ値(Outliers) とは、目的変数(Y)または説明変数(X)の空間において、データの大部分が従う一般的な傾向から大きく逸脱した観測点を指します。例えば、住宅価格の予測モデルを構築する際に、周囲の物件と比べて異常に高額または低額な取引価格を持つ物件は外れ値として検出される可能性があります。
ただし、外れ値が必ずしもモデルにとって有害であるとは限りません。その点がデータの真の変動性、例えば非常に稀な、しかし正当な事象を表している場合、モデルの汎化能力を高める上で貴重な情報を含んでいる可能性もあります。そのため、外れ値の特定には慎重な分析が求められます。

高レバレッジ点(High-Leverage Points)
高レバレッジ点(High-Leverage Points) は、説明変数空間(X空間)において、他のデータ点の分布の中心から遠く離れた位置にある観測点です。これらの点は、その特異なX値のために、回帰直線や決定境界を自身の方へ強く「引き寄せる」潜在的な力を持っています。
「レバレッジ」とは、そのデータ点がモデルに与える「潜在的な」影響力を示すものです。レバレッジ値は説明変数Xの値のみに依存し、目的変数Yの値には依存しません。高レバレッジ点は、モデルの係数推定を不安定にしたり、実際には存在しない関係性を表面上作り出したり、あるいは既存の関係性を隠蔽したりするリスクをはらんでいます。
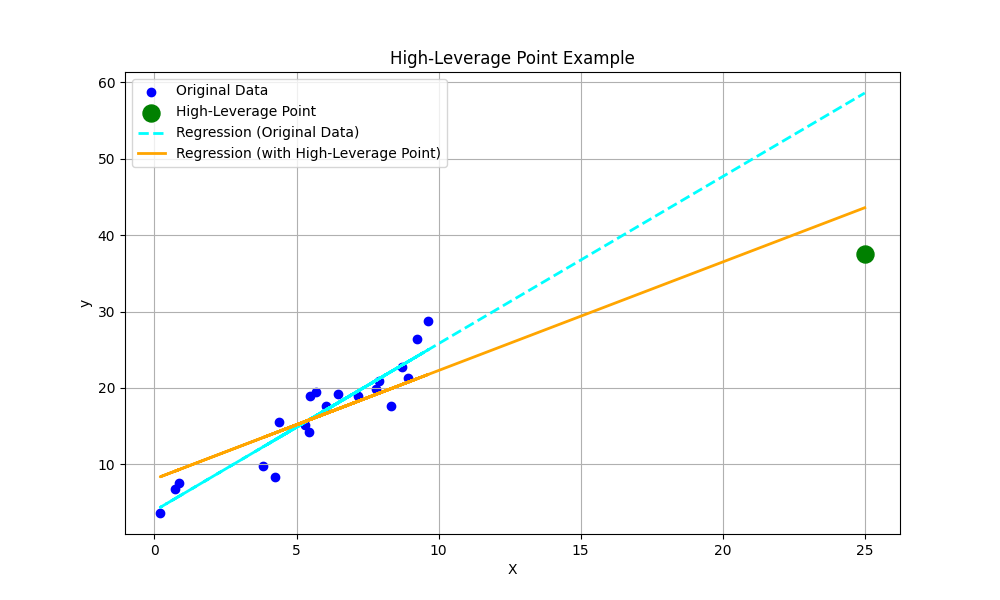
影響点が大きい点(Influential Points)
影響点が大きい点(Influential Points) とは、そのデータ点の有無によって、学習済みモデルのパラメータや予測値が著しく変化する観測点のことです。これらの点は、モデルの安定性を損ない、汎化性能を低下させる直接的な原因となる可能性が高いです。
多くの場合、影響点が大きい点は、大きな残差(予測誤差)を持つ外れ値であり、同時に高レバレッジ点であるという特性を兼ね備えています。しかし、必ずしも両方の条件を満たすわけではありません。例えば、高レバレッジ点であってもデータ全体のトレンドに沿っていればモデルへの影響は小さく、逆にレバレッジが低くても目的変数の値がトレンドから大きく外れていれば、モデルに大きな影響を与えることがあります。
誤ラベルデータ(Mislabeled Data)
誤ラベルデータ(Mislabeled Data) は、その名の通り、割り当てられたラベルが不正確なデータです。例えば、猫の画像に誤って「犬」というラベルが付与されているようなケースがこれに当たります。
このようなデータは、モデルに誤った特徴とクラスの関係性を学習させてしまうため、決定境界を歪め、汎化性能に対して最も深刻な悪影響を及ぼす要因の一つと考えられています。AIシステムが学習する基盤を根本から誤らせるため、その検出と修正はデータセットデバッグの最重要課題の一つです。
学習困難なデータ(Hard Examples)
学習困難なデータ(Hard Examples) は、ノイズや誤りではないものの、モデルがそのパターンを学習するのが本質的に難しいデータ点を指します。例えば、異なるクラス間の境界領域に位置するサンプルや、非常に希少な特徴を持つサンプルなどが該当します。
これらのデータは、モデルの訓練中に誤分類されやすい傾向がありますが、必ずしも有害であるとは限りません。むしろ、モデルの頑健性(Robustness)を試す上で重要な役割を果たし、適切に学習させることで、より精度(Accuracy)の高い決定境界の獲得に寄与する可能性もあります。したがって、有害なデータと混同せず、慎重に扱う必要があります。

総合的な判断の重要性
これら「有害なデータ」の分類は相互に排他的ではなく、一つのデータポイントが複数のカテゴリに属することもあります。また、「有害なデータ」の定義は、分析の文脈や目的に大きく依存するため、単一の指標で機械的に判断を下すことは危険です。レバレッジ(潜在的影響力)、残差(予測誤差)、そして影響度(実質的影響)といった異なる側面を捉える指標を多角的に用い、最終的にはドメイン知識を基に総合的な判断を下すアプローチが求められます。
古典的な影響度診断手法
機械学習における影響度分析の概念は、その多くが古典的な統計学、特に線形回帰モデルの診断手法にルーツを持っています。これらの手法は、モデルの仮定が満たされているか、特定の観測値がモデルの推定結果に不当な影響を及ぼしていないかを確認するために開発されました。計算コストが比較的低く、基本的な問題点を迅速に把握できるため、現代の複雑なモデルを理解するための基盤としても極めて重要です。
ここでは、影響度診断における主要な古典的指標について詳述します。
レバレッジ値(Leverage Value)
レバレッジ値は、ある観測値の説明変数(X)が、データセット全体の平均的な説明変数のパターンからどれだけ離れているかを測る指標です。これは、説明変数空間における「外れ値」の度合いを示し、その点が回帰モデルに与える「潜在的な」影響力を定量化します。レバレッジ値は説明変数Xの値のみに依存し、目的変数Yの値には依存しません。そのため、モデルを当てはめる前に、潜在的に影響の大きいデータ点を特定できる「早期警告システム」として機能します。高レバレッジ点は、回帰直線や決定境界を自身の方へ強く「引き寄せる」力を持つため、モデルの係数を不安定にしたり、本来存在しない関係性を表面上作り出したりする可能性があります。ただし、レバレッジが高いことは「影響を与える可能性がある」ことを示すだけであり、その点が必ずしもモデルにとって「有害な影響を与えている」ことを意味するわけではありません。
import statsmodels.api as sm
import numpy as np
# サンプルデータの作成
# 説明変数Xを100行2列のランダムな値で作成
X = np.random.rand(100, 2)
# 高レバレッジ点を意図的に追加
# 99番目のデータポイントのX値を他のデータから大きく離れた値に設定
X[99, :] = [2, 3]
# 目的変数yを作成
# Xに基づいて線形関係を作り、ノイズを印加
y = X[:, 0] * 2 + X[:, 1] * 3 + np.random.randn(100)
# 切片項(定数項)を追加
# statsmodelsのOLSモデルには通常必要
X = sm.add_constant(X)
# モデルのフィット
# 最小二乗法(OLS)モデルをデータXとyで学習
model = sm.OLS(y, X).fit()
# 影響度分析オブジェクトの取得
# モデルの診断情報にアクセスするためのinfluenceオブジェクトを取得
influence = model.get_influence()
# レバレッジ値(hat_matrix_diag)の取得
# influenceオブジェクトからレバレッジ値(ハット行列の対角要素)を取得
leverage = influence.hat_matrix_diag
# パラメータ数とサンプルサイズ
# モデルのパラメータ数(切片を含む説明変数の数)pとサンプルサイズnを取得
p = X.shape[1]
n = len(y)
# 閾値の設定
# 一般的なレバレッジ値の閾値として、平均レバレッジ値 (p/n) の2倍を使用
threshold = 2 * p / n
# 高レバレッジ点の特定
# 計算されたレバレッジ値が閾値を超えるデータポイントのインデックスを特定
high_leverage_points = np.where(leverage > threshold)
# 結果の出力
print(f"パラメータ数 (p): {p}")
print(f"サンプルサイズ (n): {n}")
print(f"閾値 (2*p/n): {threshold:.4f}")
print(f"高レバレッジ点 (インデックス): {high_leverage_points}")
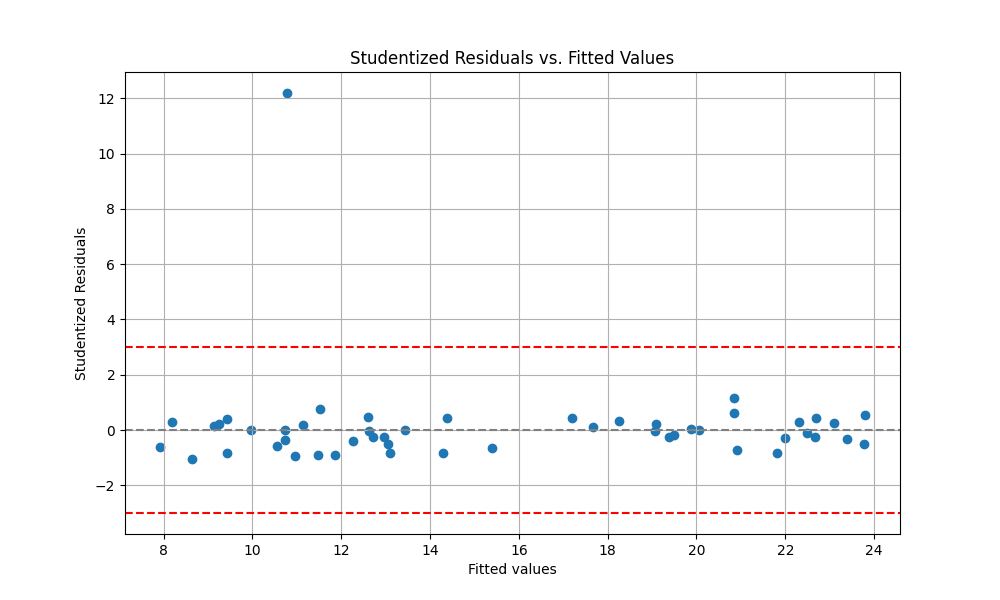
スチューデント化残差(Studentized Residuals)
スチューデント化残差は、観測値とモデルによる予測値の差である残差を標準化する指標です。通常の残差では、外れ値自身がモデルの平均二乗誤差(MSE)の推定値を膨らませてしまい、その外れ値の残差を過小評価してしまう問題があります。この問題を解決するため、スチューデント化残差では、i番目の観測値の影響を評価する際に、その観測値自身をモデルのパラメータ推定から除外して計算した「一つ抜き残差」と、それから導かれる標準誤差を用いて残差を標準化します。これにより、外れ値自身が残差の分散推定に与える影響を排除し、目的変数(Y)方向の外れ値をより感度良く検出できるようになります。スチューデント化残差の絶対値が2や3を超える観測値は、外れ値の候補として詳細な調査が推奨されます。
import statsmodels.api as sm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの作成
X = np.random.rand(50, 1) * 10
y = 2 * X.flatten() + 5 + np.random.randn(50) * 2
# Y方向の外れ値を意図的に追加します。
# 3番目のデータポイントのy値を外れ値に設定
y[2] = 40
# 切片項(定数項)を追加
X_sm = sm.add_constant(X)
# モデルのフィット
# 最小二乗法(OLS)モデルをデータX_smとyで学習
model = sm.OLS(y, X_sm).fit()
# スチューデント化残差の計算
# outlier_test() メソッドはスチューデント化残差、p値、ボンフェローニ補正されたp値を計算
outlier_info = model.outlier_test()
studentized_residuals = outlier_info[:, 0]
# 可視化
plt.figure(figsize=(10, 6))
plt.scatter(model.fittedvalues, studentized_residuals)
plt.axhline(y=0, color='grey', linestyle='--')
plt.axhline(y=3, color='red', linestyle='--')
plt.axhline(y=-3, color='red', linestyle='--')
plt.xlabel('Fitted values')
plt.ylabel('Studentized Residuals')
plt.title('Studentized Residuals vs. Fitted Values')
plt.grid(True)
plt.savefig("studentized_residuals.png")
# 外れ値の特定(絶対値が3を超えるもの)
# スチューデント化残差の絶対値が3を超える観測値は、外れ値の候補として詳細な調査が推奨される
outliers = outlier_info[np.abs(studentized_residuals) > 3]
print("外れ値として検出されたデータポイント:")
print(outliers)
Cookの距離(Cook’s Distance)
Cookの距離は、単一のデータポイントがモデルの予測全体に与える影響の大きさを測るための統合的な指標です。これは、レバレッジが説明変数空間(X空間)での特異性を、スチューデント化残差が目的変数空間(Y空間)での逸脱をそれぞれ捉えるのに対し、これら両方の情報を組み合わせて評価します。具体的には、あるデータ点をデータセットから除外したときに、モデルの予測値が全体としてどれだけ変化するかを定量化します。この指標は、残差の大きさ(予測誤差)とレバレッジの大きさ(潜在的影響力)の両方に比例して大きくなるため、モデルの安定性や信頼性に大きな影響を及ぼす可能性のある「影響点が大きい点」を特定するための、第一選択となる診断ツールとして非常に有効です。
import statsmodels.api as sm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from yellowbrick.regressor import CooksDistance
# サンプルデータの作成
X_base = np.random.rand(99, 1) * 10
y_base = 2 * X_base.flatten() + 5 + np.random.randn(99) * 2
# 意図的に影響度が大きいデータポイントを定義
influential_x_val = 20.0
influential_y_val = 5.0
# 異常点を挿入する位置
insert_index = 40
# 全データセットを構築(np.insertを使用して指定した位置に異常点を挿入)
# X_baseは(99, 1)の2次元配列なので、一度1次元にしてから挿入し、再度2次元に戻す
X_data = np.insert(X_base.flatten(), insert_index, influential_x_val).reshape(-1, 1)
y_data = np.insert(y_base, insert_index, influential_y_val)
# statsmodelsのOLSモデルにフィットするために切片項(定数項)を追加
X_sm_data = sm.add_constant(X_data)
# モデルのフィット
model = sm.OLS(y_data, X_sm_data).fit()
# 影響度分析オブジェクトの取得
# モデルの診断情報にアクセスするためのinfluenceオブジェクトを取得
influence = model.get_influence()
# Cookの距離の計算
# influence.cooks_distanceはタプル (Cookの距離の配列, p値の配列) を返すので、0番目の要素を取得
cooks_d_values = influence.cooks_distance[0]
# 閾値の計算
# 一般的な経験的閾値として、4/n を使用
n = len(y_data)
threshold = 4 / n
# 影響度が大きいデータポイントの特定
# Cookの距離が閾値を超えるデータポイントのインデックスを特定
influential_indices = np.where(cooks_d_values > threshold)
# 結果の出力
print(f"データポイント数 (n): {n}")
print(f"閾値 (4/n): {threshold:.4f}")
print(f"Cookの距離が閾値を超える影響度が大きい点 (インデックス): {influential_indices}")
print(f"追加した影響点(X={influential_x_val}, Y={influential_y_val})のインデックス: {insert_index}")
print(f"追加した影響点のCookの距離: {cooks_d_values[insert_index]:.4f}")
# Yellowbrickによる可視化
plt.figure(figsize=(12, 7))
visualizer = CooksDistance(threshold=threshold)
visualizer.fit(X_data, y_data)
visualizer.show()

DFBETAS
DFBETASは、Cookの距離がデータ点除去の「全体的な」影響を評価するのに対し、その影響をモデルの「個々のパラメータ」レベルに分解して分析するための指標です。これにより、どのデータ点がどの特定の回帰係数の推定に影響を与えているかを詳細に把握できます。DFBETASは、i番目の観測値を除外した場合の、j番目の回帰係数推定値の変化量を、i番目の観測値を除外して計算した標準誤差で割ることによって標準化されます。この標準化により、異なる係数間での影響度の比較が可能となります。特定の係数の符号が予期しないものであったり、値が不安定であったりする場合に、その原因となっているデータ点を特定するのに特に有効です。
import statsmodels.api as sm
import numpy as np
import pandas as pd
from rich import print
from rich.table import Table
def print_table(df: pd.DataFrame) -> None:
table = Table(title="DFBETAS", show_header=True, header_style="bold magenta")
# DataFrameの列をTableの列として追加
for col in df.columns:
table.add_column(col, justify="right", style="cyan", no_wrap=True)
# DataFrameの各行をTableの行として追加
for index, row in df.iterrows():
table.add_row(*[str(item) for item in row])
# テーブルを出力
print(table)
# mtcarsデータセットのロード(statsmodelsに付属)
mtcars = sm.datasets.get_rdataset("mtcars", "datasets").data
# モデルの定義とフィット
y = mtcars['mpg']
X = mtcars[['wt', 'hp']]
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
# DFBETASの計算
influence = model.get_influence()
dfbetas = influence.dfbetas
# DFBETASをデータフレームに変換
dfbetas_df = pd.DataFrame(dfbetas, index=mtcars.index, columns=X.columns)
# 閾値の計算
# 一般的に、DFBETASの絶対値が 2/√n を超える観測値は、対応する係数に対して影響が大きいと見なされる。
# 文献によっては、3/√n というより厳しい基準が用いられることもある。
n = len(y)
threshold = 2 / np.sqrt(n)
print(f"閾値 (2/sqrt(n)): {threshold:.4f}\n")
# 閾値を超えるデータポイントを特定
influential_points_dfbetas = dfbetas_df[np.abs(dfbetas_df) > threshold].dropna(how='all')
print("DFBETASで影響が大きいとされたデータポイント:")
print_table(influential_points_dfbetas)
一般化線形モデル(GLM)への応用
これらの古典的診断手法は、その多くが誤差項が正規分布に従う線形モデルを前提としていますが、ロジスティック回帰やポアソン回帰といった一般化線形モデル(GLM)にも拡張して適用することが可能です。GLMのパラメータ推定に用いられる反復重み付き最小二乗法(IRWLS)の最終ステップを重み付き最小二乗法(WLS)と見なすことで、線形モデルの診断指標をGLM向けに再定義できます。例えば、GLMでは生の残差の代わりにピアソン残差や逸脱度残差が用いられ、ハット行列やCookの距離も重み行列を含んだ形で拡張されます。
これらの古典的手法は、計算効率が高く、モデルの基本的な問題点を迅速に把握するための強力なツールであり、より複雑なモデルのデバッグを理解するための基礎となります。
近代的な影響度推定アプローチ
深層学習モデルがもたらす高次元性、非線形性、そして非凸な損失関数といった特性は、古典的な線形モデルの診断手法の直接的な適用を困難にします。これに対応するため、より高度で、深層学習の特性に合わせた先進的な影響度推定アプローチが開発されています。これらの手法は、モデルのデバッグ、解釈、そして有害なデータポイントの特定において、強力な手法となります。
影響関数(Influence Functions)
影響関数は、統計学に起源を持つ概念であり、深層学習の文脈で再評価されました。その核心は、再学習を行うことなく、ある訓練データがテストデータへの予測に与える影響を近似的に計算する点にあります。具体的には、訓練データセットのある一点の重みを微小量だけ増やしたときに、モデルのパラメータやテストデータの損失がどのように変化するかを評価します。この変化は、モデルの損失関数のヘッセ行列の逆行列と勾配の積として数学的に定式化されます。
影響関数は、モデルのデバッグや解釈、そして誤ラベルデータの特定に利用できます。スコアが正であれば、その訓練データはテスト予測に悪影響を与える「反対者」であり、負であれば「支持者」であると解釈できます。しかし、大規模な深層学習モデルでは、ヘッセ行列の逆行列(iHVP)を直接計算することが計算上のボトルネックとなり、近似アルゴリズムが必要となります。また、深層学習の非凸な損失関数は、凸性を前提とする影響関数の理論的前提を崩す「脆弱性」が課題として指摘されており、その解釈についても研究が進んでいます。pyDVLやkronfluenceなどのライブラリが、その実装をサポートしています。
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
# pyDVLから影響関数を計算するためのクラスをインポート
from pydvl.influence import SequentialInfluenceCalculator
from pydvl.influence.torch import DirectInfluence
from pydvl.influence.torch.util import (
NestedTorchCatAggregator, # 結果をTorchテンソルとして結合するツール
TorchNumpyConverter, # 結果をNumPy配列に変換して保存するツール
)
# ------------------------------------------------
# 1. 準備 (データ、モデル、損失関数)
# ------------------------------------------------
# モデルが受け取る入力データの次元を定義 (チャンネル数, 高さ, 幅)
# この例では5x5で5チャンネルのダミーデータを使用
input_dimensions = (5, 5, 5)
# モデルの最終的な出力の次元を定義
output_dimension = 3
# ダミーの訓練データとテストデータを作成
# 実際の利用シーンでは、画像データやテキストデータなどを読み込む
training_inputs, training_targets = torch.rand((10, *input_dimensions)), torch.rand((10, output_dimension))
test_inputs, test_targets = torch.rand((5, *input_dimensions)), torch.rand((5, output_dimension))
# データセットをバッチ処理するためのDataLoaderを作成
training_dataloader = DataLoader(TensorDataset(training_inputs, training_targets), batch_size=2)
test_dataloader = DataLoader(TensorDataset(test_inputs, test_targets), batch_size=1)
# 学習対象のモデルを定義 (シンプルな畳み込みニューラルネットワーク)
convolutional_model = nn.Sequential(
nn.Conv2d(in_channels=5, out_channels=3, kernel_size=3),
nn.Flatten(), # 畳み込み層の出力を1次元に変換
nn.Linear(27, 3), # 全結合層
)
# 損失関数を定義 (平均二乗誤差)
loss_function = nn.MSELoss()
# ------------------------------------------------
# 2. 影響関数モデルの準備
# ------------------------------------------------
# pyDVLのDirectInfluenceクラスを使い、モデルと損失関数をラップ
# これにより、モデルが影響関数を計算できるようになります
# hessian_regularizationは、計算を安定させるための小さな正則化項
influence_model_wrapper = DirectInfluence(convolutional_model, loss_function, hessian_regularization=0.01)
# fitメソッドを呼び出し、影響関数計算に必要な事前計算(ヘッセ行列の逆行列など)を行う
# このステップは計算の「準備」であり、まだ個々のデータの影響は未計算
influence_model_wrapper = influence_model_wrapper.fit(training_dataloader)
# ------------------------------------------------
# 3. 影響の計算 (2つの方法)
# ------------------------------------------------
# これ以降で、テストデータに対する訓練データの影響を実際に計算
# ### 方法A: 全てをメモリ上で行う方法 (小規模データセット向け) ###
print("方法A: メモリ上で一括計算を実行中...")
# .influencesメソッドに直接テンソルを渡すと、影響行列全体(テストデータ数 x 訓練データ数)が
# 一度に計算され、結果がメモリ上に展開される
# データが少ない場合は最もシンプルで手軽な方法となる
influences_in_memory = influence_model_wrapper.influences(test_inputs, test_targets, training_inputs, training_targets)
print(f"計算完了。影響行列の形状: {influences_in_memory.shape}") # (テストデータ数, 訓練データ数) = (5, 10)
print("-" * 30)
# ### 方法B: 遅延評価と逐次計算 (大規模データセット向け) ###
print("方法B: 逐次計算(遅延評価)の準備中...")
# データセットが大きい場合、方法Aではメモリ不足になります。
# そのため、SequentialInfluenceCalculatorを使って、計算を少しずつ実行する計画を立てる
influence_calculator = SequentialInfluenceCalculator(influence_model_wrapper)
# .influencesメソッドにDataLoaderを渡すと、すぐには計算が実行されません。
# 代わりに、「計算方法」を定義したLazyオブジェクトが返却される。
# これにより、実際にデータが必要になるまで計算を遅らせることができる。
lazy_influence_results = influence_calculator.influences(test_dataloader, training_dataloader)
print("Lazyオブジェクトが作成されました。まだ実際の計算は行われていません。")
# B-1: 計算をトリガーし、結果をメモリに集約
print("B-1: 計算を実行し、結果をメモリに読み込みます...")
# .compute()が呼び出された時点で、初めてバッチごとの計算が実行されます。
# aggregatorは、バッチごとに得られる計算結果を最終的にどのように結合するかを指定
# ここでは、NestedTorchCatAggregatorを使い、全ての結果を一つのTorchテンソルにまとめる。
influences_from_lazy = lazy_influence_results.compute(aggregator=NestedTorchCatAggregator())
print(f"計算完了。影響行列の形状: {influences_from_lazy.shape}")
# B-2: 計算をトリガーし、結果をディスクに直接書き込む
print("\nB-2: 計算を実行し、結果をバッチごとにディスクに書き込みます...")
# メモリに全結果を保持できないほど巨大なデータの場合は、結果を直接ディスクに保存
# .to_zarr()は、バッチごとに計算を実行し、その結果を逐次的にZarr形式でディスクに保存する
# Zarrは大規模な配列データを効率的に扱うためのフォーマット
# TorchNumpyConverterは、TorchテンソルをNumPy配列に変換する役割を担う。
lazy_influence_results.to_zarr("influences_result.zarr", TorchNumpyConverter())
print("計算とディスクへの書き込みが完了しました。'influences_result.zarr'というディレクトリが作成されました。")
TracIn(Tracing Influence)
TracInは、影響関数が抱えるヘッセ行列計算の複雑さを回避し、より直接的かつスケーラブルな方法で訓練データの影響を評価するために提案された手法です。その名称が示す通り、このアプローチの核心は、確率的勾配降下法(SGD)による訓練プロセスそのものを「トレース(追跡)」することにあります。訓練中に保存された複数のモデルのチェックポイントを利用し、訓練データとテストデータの損失関数の勾配の内積を通じてデータの影響を評価します。勾配ベクトルが同じ方向を向いている(内積が正)ほど、訓練データがテストデータの損失を減少させるのに貢献したと解釈されます。
TracInは、ヘッセ行列計算が不要なため実装が容易で計算効率が高く、大規模な深層学習モデルにも適用しやすいという利点があります。予測の説明(支持者と反対者の特定)や、訓練データが自分自身の予測に与える「自己影響スコア」を用いた誤ラベル検出に有効です。誤ラベルデータは、自身の誤ったラベルにフィッティングしようとする圧力と、他の正しいデータからの汎化圧力との間で矛盾が生じるため、高い(正の)自己影響スコアを示す傾向があります。

学習ダイナミクスに基づく手法
このアプローチは、深層学習モデルの訓練過程そのものに着目します。特に注目されるのが「忘却イベント(Forgetting Event)」という概念です。これは、ある訓練エポックで正しく分類されていたサンプルが、その後のエポックで誤って分類されるようになる現象と定義されます。
モデルは通常、「簡単」なパターンから学習を始め、その後、より複雑なデータやノイズの多いデータを「記憶」しようとします。誤ラベルデータは、その誤ったラベルへのフィッティングと正しいパターンへの汎化の間で矛盾が生じるため、訓練中に予測が不安定になり、頻繁に忘れられる傾向が強くなります。そのため、訓練全体を通しての忘却イベントの回数を数えることで、各サンプルの「学習のしにくさ」や「ノイズらしさ」を定量化し、誤ラベルデータや学習困難なデータを特定できます。この手法は高い検出精度が報告されており、直感的で理解しやすいという利点があります。しかし、訓練の全エポックにわたって各訓練サンプルの予測結果を記録し続ける必要があり、特に大規模データセットでは計算・ストレージコストが高めになるという限界があります。また、クラス境界付近の「困難な」サンプルと、本質的に「有害な」誤ラベルデータとを区別することが難しい場合もあります。
教師なし・密度ベースの手法
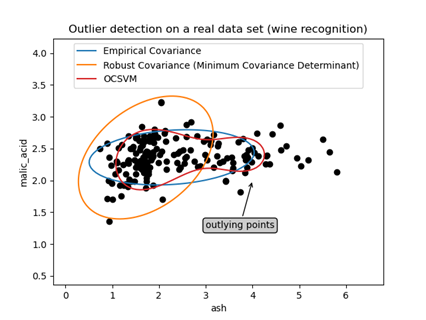
これまでの手法がモデルの学習プロセスに密接に関連しているのに対し、教師なし・密度ベースの手法は、モデルの学習とは独立して、データそのものの特徴空間における分布に基づいて異常なデータポイントを検出します。Zスコアや四分位範囲(IQR)といった古典的統計手法の効果が限定的な高次元データに対して、より柔軟に適応できます。
代表的な手法としては、Isolation Forest、One-Class SVM、Autoencodersなどがあります。Isolation Forestは、異常な点は少ない分割で孤立させられるという直感に基づき、ランダムな決定木を構築して異常スコアを計算します。One-Class SVMは、正常なデータの分布を学習し、その分布から外れる点を異常とします。Autoencodersは、正常なデータで学習した復元誤差の大きさを異常スコアとして利用します。これらの手法は、主にデータの前処理段階や、ラベル情報が利用できない状況での異常点スクリーニングに有用です。モデル非依存性と非線形・高次元データへの対応が利点ですが、検出される「異常」が常にモデルの予測性能にとって「有害」であるとは限らないという限界があります。例えば、珍しいが正当なクラスのサンプルを誤って異常と判定する可能性があります。
Treeベースアンサンブルモデルに特化した影響度・貢献度評価
ランダムフォレストや勾配ブースティング木(XGBoost、LightGBM、CatBoostなど)といったTreeベースアンサンブルモデルは、特に表形式データにおいて、深層学習モデルとしばしば同等かそれ以上の高い予測性能を示すことから、実務で広く利用されています。しかし、これらのモデルは数百から数千もの個別の決定木を組み合わせる(アンサンブルする)という複雑な構造的特性を持っています。この特性は、深層学習モデルのような連続的なパラメータ空間とは根本的に異なり、影響度を推定する上で独自のアプローチを必要とします。アンサンブルモデルはしばしば「ブラックボックス」と見なされ、特定の予測がなぜそのようになったのか、またどの訓練データがその予測に最も影響を与えたのかを直接的に把握することは困難でした。
GBDTのための影響関数
深層学習の文脈で開発された影響関数のアイデアを、GBDT(勾配ブースティング決定木)のようなTreeアンサンブルモデルに適応させる試みがなされています。GBDTはTreeの構造が離散的であり、パラメータ(葉の値)もブースティングの過程で逐次的に決定されるため、古典的な影響関数の理論は直接適用できません。そこで、GBDTの学習メカニズムに特化したいくつかの近似的な影響度推定手法が提案されています。
これらの手法の多くは、「Treeの構造は、訓練データに小さな摂動を加えても変化しない」という強い仮定の下で、訓練データの重みを変化させたときに、各Treeの葉の出力値がどのように変化するかを追跡します。
LeafInfluence は、影響関数のフレームワークをGBDTに拡張したものです。これは、訓練サンプルがテストサンプルに与える予測値の変化を、各ブースティングステップにおける葉の出力値の変化を合計することで計算します。
BoostIn は、深層学習におけるTracInのアナロジーとして提案されました。BoostInは、GBDTのブースティング過程、すなわち各Treeが逐次的に追加されていくプロセスを追跡します。各ステップで、訓練サンプルが学習に使われたときの、テストサンプルの損失の変化を捉えることで影響を評価します。このアプローチはヘッセ行列の計算を必要とせず、LeafInfluenceよりも数桁高速に動作すると報告されています 。
これらのGBDTのための影響関数は、主にGBDTモデルの予測デバッグに利用されます。具体的には、「なぜこのテストサンプルの予測値はこのようになったのか?」という問いに対し、影響の大きい訓練サンプルを特定することで説明を提供できます。例えば、不正検知モデルが特定の取引を「不正」と予測した場合、その判断に最も寄与した過去の類似した不正取引(支持者)を特定するのに役立ちます。
import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from lightgbm import LGBMClassifier from tree_influence.explainers import BoostIn # pip install tree-influence # ------------------------------------------------ # 1. データの準備 # ------------------------------------------------ # scikit-learnに組み込まれているIris(アヤメ)のデータセットを読み込む data = load_iris() X, y = data['data'], data['target'] # 今回は2クラス分類(0か1か)の問題に単純化するため、ラベルが2以外のデータだけを抽出 idxs = np.where(y != 2)[0] X, y = X[idxs], y[idxs] # データをモデル学習用の「学習データ」と、モデルの性能評価や影響分析に使う「テストデータ」に分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1) # ------------------------------------------------ # 2. GBDT(勾配ブースティング決定木)モデルの学習 # ------------------------------------------------ # LightGBM分類器のインスタンスを作成しモデルを学習 model = LGBMClassifier().fit(X_train, y_train) # ------------------------------------------------ # 3. BoostInによる影響分析の準備と実行 # ------------------------------------------------ # BoostInのインスタンスを作成 explainer = BoostIn().fit(model, X_train, y_train) # explainer.get_local_influence()を使い、影響値を計算 # 引数にテストデータ(X_test, y_test)を渡すことで、 # 「テストデータ1件1件の予測に対して、学習データ全件がそれぞれどのような影響を与えたか」 # を網羅的に計算する # # 結果の`influence`は行列で、その形は (学習データの数, テストデータの数) になる # 例えば `influence[i, j]` の値は、 # 「i番目の学習データ」が「j番目のテストデータ」の予測に与えた影響の大きさを表す。 influence = explainer.get_local_influence(X_test, y_test) # ------------------------------------------------ # 4. 特定のテストデータに対する影響の分析 # ------------------------------------------------ # 計算結果の行列から、最初のテストデータ(インデックス=0)に関する影響だけを抽出します。 values = influence[:, 0] # `values`(影響値)を元に、学習データのインデックスを並べ替えます。 # # `np.argsort(values)`: # 影響値を小さい順(最も予測に悪影響を与えた順)に並べたときの、元のインデックスを返す。 # # 結果として`training_idxs`には、 # 最初のテストデータの予測に対して... # # - 最もポジティブな影響を与えた(=予測の損失を最も減らした)学習データのインデックスから、 # - 最もネガティブな影響を与えた(=予測の損失を最も増やした)学習データのインデックスへ # # ...と順番に並んだ配列が格納される。 training_idxs = np.argsort(values)[::-1] # 例えば、training_idxs[0] が最も良い影響を与えた学習データのインデックス、 # training_idxs[-1] が最も悪い影響を与えた学習データのインデックスとなります。 # これにより、「なぜこのテストデータはこのように予測されたのか?」を、 # 影響の大きかった学習データを具体的に見ることで分析できる。
TreeSHAP:個別の予測に対する特徴量貢献度評価
データ点の影響度を直接計算するアプローチとは別に、TreeSHAP は特徴量の貢献度を介して間接的に影響の大きいデータ点を特定する方法を提供します。
SHAP(SHapley Additive exPlanations)は、協力ゲーム理論におけるシャープレイ値(Shapley Value)の概念を応用し、ある一つの予測値を説明するために、各特徴量の貢献度を公正に分配するフレームワークです。機械学習の文脈では、モデルの入力特徴量を「プレイヤー」、予測値を計算するプロセスを「ゲーム」、実際の予測値とベースライン値(データセット全体の平均予測値)との差を「利得」と見なします。SHAP値は、この差分を各特徴量に「公正に」分配した値であり、個々の特徴量がその予測をベースラインからどれだけ押し上げたか(または押し下げたか)を示します。
シャープレイ値の厳密な計算は、特徴量の全ての組み合わせを考慮するため、通常は指数的な計算量を要し、非現実的です。しかし、TreeSHAP は、モデルが決定木のアンサンブルであるという構造的特性を利用することで、この計算を多項式時間で高速かつ厳密に実行するアルゴリズムです。
TreeSHAPは、個別の予測に対するローカルな説明を提供することに非常に優れています。これにより、従来の大域的な特徴量重要度では不可能だった、より詳細なモデル解釈が可能になります。例えば、「なぜこの顧客は解約すると予測されたのか?」という問いに対し、「『契約期間』が短いことが予測値を+0.3押し上げ、『月額料金』が安いことが-0.1押し下げた」といった具体的な説明を提供できます。
また、TreeSHAPは直接データ点の影響度を測るものではありませんが、その代理指標として利用できます。もしある予測において、特定の特徴量が異常に大きなSHAP値を示した場合、それはそのデータ点のその特徴量の値が特異であり、予測に大きな影響を与えたことを示唆します。例えば、ある住宅の価格予測で「部屋数」のSHAP値が極端に大きい場合、その住宅の部屋数がデータセット内で外れ値である可能性が高いと推測できます。
TreeSHAPは、shap というPythonライブラリとして広く普及しており、デファクトスタンダードとなっています。このライブラリは、XGBoost、LightGBM、CatBoost、scikit-learnの木ベースモデルなど、主要な実装に幅広く対応しています。shapライブラリは、個別の予測を説明するウォーターフォールプロットや、データセット全体の特徴量の影響と分布を可視化するビースワームプロットなど、豊富な可視化ツールを提供しており、実務での利用を強力にサポートします。
import pandas as pd
import xgboost
import shap
from sklearn.model_selection import train_test_split
# 1. データの準備
X, y = shap.datasets.california()
# データを訓練用とテスト用に分割します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. モデルの学習
# XGBoostの回帰モデルを学習
model = xgboost.XGBRegressor(objective='reg:squarederror')
model.fit(X_train, y_train)
# 3. TreeSHAP Explainerの作成とSHAP値の計算
# 学習済みモデルを元に、TreeExplainerを作成
explainer = shap.TreeExplainer(model)
# テストデータに対してSHAP値を計算します。
shap_values = explainer.shap_values(X_test)
# 4. 結果の可視化
# Jupyter Notebook/Colabで可視化を有効にするための初期化
shap.initjs()
# --- 可視化①:サマリープロット(バー) ---
# 各特徴量がモデルの予測に与える影響の大きさ(SHAP値の絶対値の平均)を棒グラフで表示
# どの特徴が全体的に重要かを把握するのに使用する。
shap.summary_plot(shap_values, X_test, plot_type="bar")
# --- 可視化②:サマリープロット(ドット) ---
# 各データポイントにおける各特徴の影響を散布図で表示
# 特徴量の値の大小(色で表現)と、予測への影響(横軸)の関係性が一目でわかる
shap.summary_plot(shap_values, X_test)
# --- 可視化③:フォースプロット(単一の予測) ---
# 特定の1つのデータ(ここではテストデータの最初のデータ)の予測がどのように行われたかを示す。
# ベース値(平均的な予測値)から、各特徴が予測値を押し上げたり(赤)、押し下げたり(青)する様子が分かる。
shap.force_plot(explainer.expected_value, shap_values[0,:], X_test.iloc[0,:])
# --- 可視化④:フォースプロット(複数の予測)---
# テストデータ全体(ここでは最初の500件)のフォースプロットをまとめて表示。
# 予測の傾向が似ているサンプルをクラスタリングして表示。
shap.force_plot(explainer.expected_value, shap_values[:500,:], X_test.iloc[:500,:])
# --- 可視化⑤:依存プロット ---
# 特定の特徴量(ここでは 'MedInc')が、予測にどのような影響を与えるかを示す
# 横軸が特徴量の値、縦軸がその特徴のSHAP値
# interaction_indexを'auto'にすると、その特徴と最も交互作用の強い他の特徴を色で示してくれる。
shap.dependence_plot("MedInc", shap_values, X_test)
データの価値を定量化するフレームワークとMLOpsへの統合
データセットデバッグのさらに進んだアプローチとして、個々のデータ点の「価値」を定量的に評価するフレームワークが注目されています。これは、単なる有害データの特定やクリーニングに留まらず、より積極的なデータ活用戦略を可能にします。具体的には、効率的なデータセットの要約、ドメイン適応のための戦略的なデータ選択、さらにはデータ市場における公正な価格設定といった目的にも貢献します。
Data Shapley:理論的公正性を追求するデータ評価
Data Shapley は、協力ゲーム理論のシャープレイ値の概念を機械学習のデータ評価に応用したフレームワークです。このアプローチでは、データセットの構築を、各データ点を「プレイヤー」、データサブセットで学習したモデルの性能を「利得」と見なし、各データがモデル性能向上にどれだけ貢献したかを公平に分配することで、その価値を定量化します。
Data Shapleyは、効率性、対称性、ダミープレイヤー、加法性という4つの公正性に関する公理を唯一満たす評価手法であることが数学的に証明されており、その高い理論的な公正性が最大の特長です。これにより、モデル性能に負の貢献をするデータ点(シャープレイ値が負)をノイズや誤ラベルデータとして検出し、除去することでモデル性能を向上させることが可能です。また、ドメイン適応においてターゲットドメインの検証セットに対し高いシャープレイ値を持つ訓練データを選択する指針にもなります。
しかし、Data Shapleyの最大の、そして非常に深刻な限界は、その計算コストが非常に高い点です。データセットのサイズを \(n\) とすると、考えうるデータサブセットの数は \(2^n\) となり、シャープレイ値を厳密に計算することは指数的な時間を要するため、大規模データセットには非現実的です。この問題を緩和するため、Truncated Monte Carlo (TMC) ShapleyやGradient Shapleyといった近似アルゴリズムが提案されていますが、それでもなお多数回のモデル再学習が必要であり、実用上の課題は残ります。
強化学習によるデータ評価(DVRL):スケーラビリティと適応性
強化学習によるデータ評価(DVRL: Data Valuation using Reinforcement Learning) は、Data Shapleyが抱える計算コストの問題に対し、全く異なるアプローチでスケーラブルなデータ評価を実現しようとするフレームワークです。DVRLは、データ評価をメタ学習の問題として再定義し、強化学習(RL)の技術を用いて解きます。
DVRLシステムは、データごとに「価値」に相当するスコアを出力するデータ価値評価器(DVE)と、そのDVEが選択したデータを用いて学習する予測器モデルの二つのモデルから構成されます。DVEは、予測器モデルの性能向上に貢献するデータを選択するように強化学習(REINFORCEアルゴリズムなど)によって訓練されます。
このアプローチの最大の利点は、その計算効率(スケーラビリティ)にあります。Data Shapleyのようにデータ数の指数関数的な計算を必要とせず、通常のモデル訓練の約2倍程度の計算時間で価値評価が可能であると報告されており、大規模データセットへの適用が可能です。DVRLは、ノイズの多いデータセットから頑健に学習したり、訓練データと検証・テストデータの分布が異なるドメイン適応のシナリオで、ターゲットドメインの性能を最大化するようなデータを選択したりするのに有効です。また、誤ラベルや破損したサンプルを特定するための強力な指標ともなります。
一方で、DVRLは、DVEと予測器という二つのモデルを同時に学習させるフレームワークの複雑さや、強化学習特有のハイパーパラメータ調整が必要となる点が課題です。また、Data Shapleyのような公正性に関する厳密な理論的保証はありません。
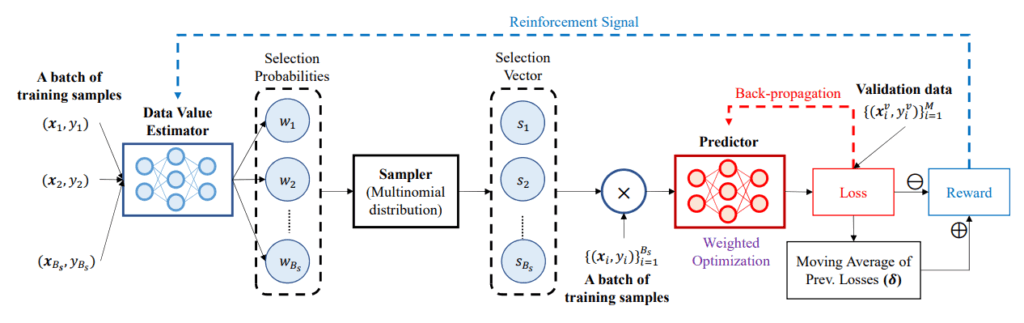
各バッチの訓練データはまず Data Value Estimator に入力され、各サンプルの「データ価値」に対応する選択確率 \(w_i\)が出力される。サンプラーはこれらの確率に基づきサンプルを選択し、その選ばれたデータのみを用いて予測モデル (Predictor) を学習する。予測モデルは検証データで評価され、得られた損失と過去の移動平均損失との差分から報酬 (Reward) が算出される。この報酬が強化学習のシグナルとして Data Value Estimator を更新し、データ選択戦略の改善につながる(https://arxiv.org/pdf/1909.11671 より引用)
MLOpsへの統合:継続的なデータ品質モニタリング
データセットデバッグは一度行えば完了するタスクではなく、特に本番環境で継続的に新しいデータが流入し、モデルが再学習されるような動的なシステムにおいては、MLOps(Machine Learning Operations)のループに組み込まれた継続的なデータ品質モニタリングが不可欠です。
このプロセスにおいて、Evidently AI や Deepchecks のようなオープンソースのMLオブザーバビリティ(可観測性)ツールが重要な役割を果たします。これらのツールは、訓練時と推論時でデータの統計的分布が変化していないかを監視するデータドリフト検出、欠損値の割合や範囲外の値の存在といったデータ品質メトリクスの監視、そしてモデルの精度や再現率などのモデル性能の監視といった機能を提供します。
データドリフトが検出され、モデル性能の低下が確認された場合、本レポートで紹介した影響度分析手法(例:影響関数、TracIn)と連携することで、「どの新しいデータが性能低下の主な原因となっているのか?」という根本原因分析を行うことができます。これにより、単にモデルを再学習させるだけでなく、問題のあるデータを特定して修正したり、データ収集プロセスそのものを見直したりといった、より的確なアクションを取ることが可能になります。このように、データセットデバッグ技術をMLOpsパイプラインに統合することは、データ中心AIの思想を実践し、頑健で信頼性の高いAIシステムを維持するための鍵となります。
おわりに
今回は、AIモデルの性能を最大化するためのデータ品質管理手法について、多角的な視点から包括的に解説しました。古典的な統計的手法から、深層学習やTreeベースアンサンブルモデルに特化した先進的な影響度推定技術、そしてデータ点の「価値」を定量的に評価するData ShapleyやDVRLといったフレームワークまで、その進化を辿ってきました。
これらの手法を選択する上で、実務家は「忠実性(Fidelity)」と「スケーラビリティ(Scalability)」という根本的なトレードオフのスペクトラムを深く理解する必要があります。例えば、Data Shapleyはその高い理論的公正性が魅力ですが、計算コストが非常に高いという課題があります。一方で、TracInや学習ダイナミクスに基づく手法はスケーラビリティに優れるものの、厳密な理論的保証は劣ります。金融や医療のように厳密な説明責任が求められる領域では忠実性を、大規模Webデータでの高速なノイズスクリーニングではスケーラビリティを優先するなど、自身のユースケースに応じて最適な手法を戦略的に選択することが不可欠です。
今後の展望として、既存手法間の統合と理論の深化、GPTシリーズのような超大規模モデルへのスケーラビリティ向上は、依然として研究の最重要課題です。また、データ品質診断プロセスの高度な自動化や、AIの倫理・プライバシー問題(機械学習忘れ、公正なデータ市場の実現など)への貢献も期待されます。
More Information
- arXiv:1703.04730, Pang Wei Koh et al., 「Understanding Black-box Predictions via Influence Functions」, https://arxiv.org/abs/1703.04730
- arXiv:1705.07874, Scott Lundberg et al., 「A Unified Approach to Interpreting Model Predictions」, https://arxiv.org/abs/1705.07874
- arXiv:1802.03888, Scott M. Lundberg et al., 「Consistent Individualized Feature Attribution for Tree Ensembles」, https://arxiv.org/abs/1802.03888
- arXiv:1802.06640, Boris Sharchilev et al., 「Finding Influential Training Samples for Gradient Boosted Decision Trees」, https://arxiv.org/abs/1802.06640
- arXiv:2002.08484, Garima Pruthi et al., 「Estimating Training Data Influence by Tracing Gradient Descent」, https://arxiv.org/abs/2002.08484
- arXiv:2205.00359, Jonathan Brophy et al., 「Adapting and Evaluating Influence-Estimation Methods for Gradient-Boosted Decision Trees」, https://arxiv.org/abs/2205.00359
- arXiv:2404.00751, Niki Kiriakidou et al., 「C-XGBoost: A tree boosting model for causal effect estimation」, https://arxiv.org/abs/2404.00751
- arXiv:2406.11730, Huaiguang Cai, 「CHG Shapley: Efficient Data Valuation and Selection towards Trustworthy Machine Learning」, https://arxiv.org/abs/2406.11730
- arXiv:2409.19998, Zhe Li et al., 「Do Influence Functions Work on Large Language Models?」, https://arxiv.org/abs/2409.19998
- arXiv:2501.10555, Dongjie Wang et al., 「Towards Data-Centric AI: A Comprehensive Survey of Traditional, Reinforcement, and Generative Approaches for Tabular Data Transformation」, https://arxiv.org/abs/2501.10555
- arXiv:2502.08828, Wangyang Ying et al., 「A Survey on Data-Centric AI: Tabular Learning from Reinforcement Learning and Generative AI Perspective」, https://arxiv.org/abs/2502.08828
- arXiv:2505.04139, Hongyi Li et al., 「LHT: Statistically-Driven Oblique Decision Trees for Interpretable Classification」, https://arxiv.org/abs/2505.04139
関連記事

Neuro-Symbolic AI: ブラックボックス時代における信頼性と論理の融合
現在の自然言語処理(NLP)やコンピュータビジョン(CV)の分野では、深層学習モデルが目覚ましい成果を上げています。しかし、これらのモデルはデータ効率の悪さや予測の根拠(説明性)が不透明であるという根本的な課題を抱えてい […]

LLM入門者必見!50の質問で学ぶ大規模言語モデルの基礎知識
AI、特に大規模言語モデル(LLM)の分野では、日々新しい技術やフレームワークが発表され、その進化は留まるところを知りません。最近、このLLMの中心的な概念をQ&A形式でまとめた「Top 50 Large Lan […]

scikit-upliftで始めるアップリフトモデリング入門
データ駆動型の意思決定において、機械学習モデルは「どの顧客が商品を購入する可能性が高いか」という相関関係の予測に広く活用されています。しかし、マーケティング施策や介入の予算を真に最適化するためには、「我々の施策(介入)に […]