Conversational Search入門: LLM時代の検索技術最前線

現代のデジタル社会において、検索エンジンは情報アクセスに不可欠な存在となっています。しかし、単一のキーワードや短いフレーズに依存する従来の検索では、ユーザーの複雑で曖昧な情報ニーズに十分に応えきれません。
近年、人工知能(AI)と自然言語処理(NLP)技術、特に大規模言語モデル(LLM: Large Language Models)の急速な進展は、この検索体験を根本から変えつつあります。検索エンジンは今、自然言語による対話を通じて文脈を維持し、複雑なクエリに対応する「対話型検索(Conversational Search)」という新たなパラダイムへと進化しています。Perplexity.aiやSearchGPTのような商用サービスも既に登場し、急速にユーザーを獲得しています。
今回は、このLLM時代の検索技術最前線である対話型検索の基本概念について、サーベイ論文である「A Survey of Conversational Search」をベースに掘り下げます。クエリ再構築(Query Reformulation)、検索の明確化(Search Clarification)、対話型情報検索(Conversational Retrieval)、応答生成(Response Generation)といった主要コンポーネント、LLMによる機能強化、実世界での応用例、そして主要な技術的課題と将来展望について、網羅的に解説します。
従来の検索と対話型検索の違い
現代において、検索エンジンは情報アクセスの基盤として不可欠な存在です。しかし、日常的に利用してきた従来の検索エンジンは、主に単一のキーワードや短いフレーズに基づく「キーワードベースの検索」に依存しています。このアプローチでは、ユーザーが持つ複雑で曖昧な情報ニーズや、検索過程で変化する文脈 (context) を、システムが適切に理解し維持し続けることに本質的な課題を抱えています。
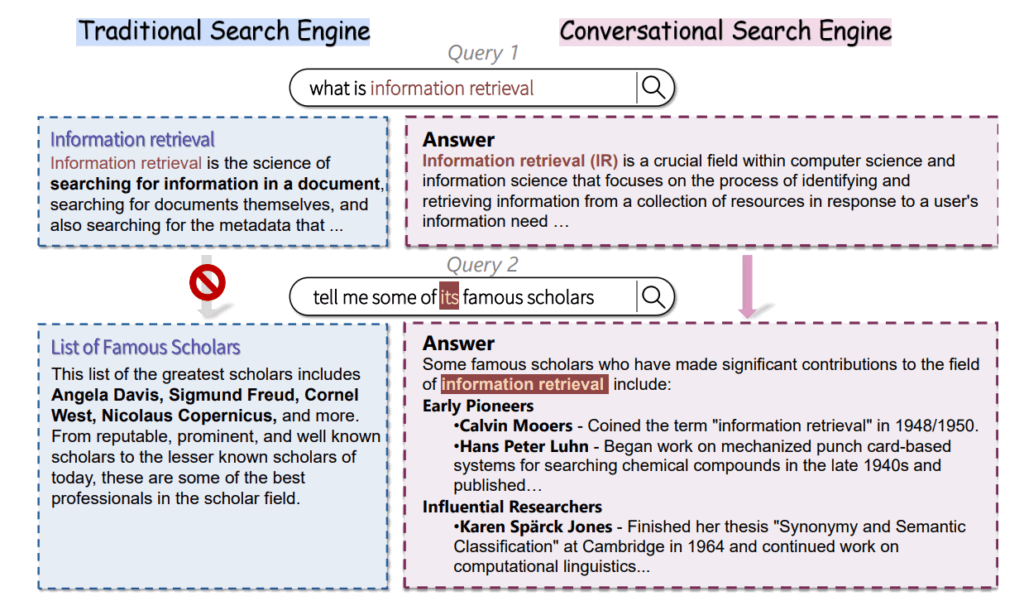
例えば、あるユーザーが「情報検索とは何ですか?」と尋ね、続けて「その分野の有名な学者を教えてください」と質問したとします。従来の検索システムでは、二番目のクエリに含まれる「その分野の」という部分が、直前の会話の文脈である「情報検索」を指していることを認識できませんでした。これは、自然言語特有の照応 (Anaphora) や省略 (Ellipsis) といった現象をシステムが解決できないためであり、結果として、ユーザーの意図とは無関係な、的外れな情報が提示されてしまう可能性がありました。このような状況は、情報交換の効率を低下させ、ユーザーの認知的負荷を高める要因となっています。
これに対し、近年急速に発展している対話型検索 (Conversational Search) は、この課題を根本から解決する新しいパラダイムとして登場しました。対話型検索システムは、自然言語による対話 (multi-turn dialogue) を通じて、ユーザーとの間で文脈を継続的に維持します。これにより、たとえユーザーの最初の情報ニーズが漠然としていても、対話の中でそれが徐々に洗練されていく過程をサポートし、複雑なクエリにも正確に対応できるようになります。
対話型検索の大きな特徴は、単にユーザーの入力に「反応する (reactive)」だけでなく、必要に応じてシステム側から明確化の質問 (clarifying questions) を投げかけたり、関連する情報や提案をプロアクティブに提示したりする「混合イニシアティブ (mixed initiative)」なインタラクションを可能にする点です。これにより、情報交換の効率は劇的に向上し、ユーザーはより自然で直感的な方法で目的の情報を探索し、最終的なタスクを完了できる、最適化されたユーザー体験を享受できます。その目標は、単なる情報の「関連性」を超え、「効率性」「認知的負荷の軽減」「探索の促進」「ユーザー満足度」といった、より豊かな価値の提供を目指しています。
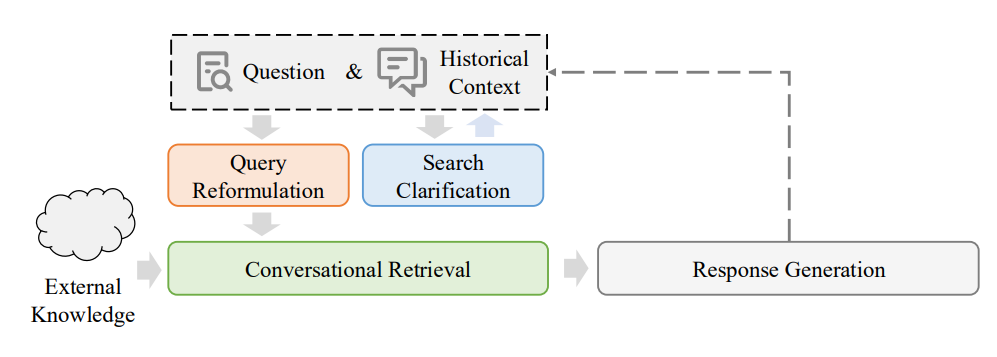
対話型検索システムがこれらの高度な機能を実現するためには、「クエリ再構築 (Query Reformulation)」、「検索の明確化 (Search Clarification)」、「対話型情報検索 (Conversational Retrieval)」、そして「応答生成 (Response Generation)」といった、複数の主要コンポーネントが協調して機能することが不可欠です。次のセクションでは、これらのコンポーネントについて、その役割と技術的な側面を詳しく掘り下げていきます。
対話型検索システムの主要コンポーネント
対話型検索システムは、ユーザーとの多ターン対話を通じて複雑な情報ニーズを効果的に満たすために、主に以下の4つの主要なコンポーネントが協調して機能するように設計されています。これらのコンポーネントは、ユーザーのクエリ理解、関連情報の検索、そして最終的な自然言語応答の生成という一連の流れを支えています。
クエリ再構築 (Query Reformulation)
クエリ再構築は、ユーザーの現在の質問と過去の会話履歴を基に、検索エンジンがより効果的に情報を検索できる形式へとクエリを変換する技術です。特に、自然言語での会話に頻繁に現れる指示語 (Anaphora) や省略 (Ellipsis) といった文脈依存的な現象に対処し、現在の検索意図を正確に反映した、文脈を考慮したクエリを生成することがその目的です。従来の検索システムでは、対話における複雑で長大な文脈を適切に処理し続けることに課題がありました。
この分野の手法には、主に「クエリ拡張」と「クエリ書き換え」、そしてそれらを組み合わせた「ハイブリッドアプローチ」があります。クエリ拡張 (Query Expansion) は、関連性の高い用語を元のクエリに追加することで、検索の網羅性を高める手法です。初期の研究では、対話履歴や疑似適合フィードバック (pseudo relevance feedback) から関連用語を抽出するアプローチが用いられてきました。一方、クエリ書き換え (Query Rewriting) は、文脈依存的なクエリを独立した形式のクエリに変換する基本的なアプローチです。この領域では、大規模言語モデル (LLM: Large Language Models) の登場により大きな進展が見られ、LLMの強力な長文理解とテキスト生成能力を活用することで、プロンプティングフレームワークや多段階生成を通じてクエリ書き換えの精度が大幅に向上しています。また、ハイブリッドアプローチ (Hybrid Approaches) では、クエリ拡張と書き換えの双方の利点を組み合わせ、LLMの質問応答能力を用いて生成された回答を書き換え後のクエリに追加することで、検索性能の向上が期待されています。
しかし、クエリ再構築には、データセットの偏りや評価の難しさ、そして長大な会話履歴におけるエラーの蓄積といった課題が残っています。LLMの文脈理解能力と明示的な再構築モジュールの最適な連携方法も、今後の探求が求められる点です。
# クエリ拡張 (Query Expansion) のプロンプト例
あなたは検索支援システムです。以下の会話履歴とユーザーの直近の発話をもとに、検索エンジンで効果的に使える「完全な検索クエリ」を生成してください。
要件:
- ユーザーの意図を明確に反映すること
- 代名詞や省略表現を解消し、スタンドアロンで理解できる文にすること
- 不要な雑談や感情的な表現は除去すること
- 出力は検索クエリのみとする
会話履歴:
{conversation_history}
直近のユーザー発話:
{user_input}
出力フォーマット:
検索クエリ: <生成されたクエリ>検索の明確化 (Search Clarification)
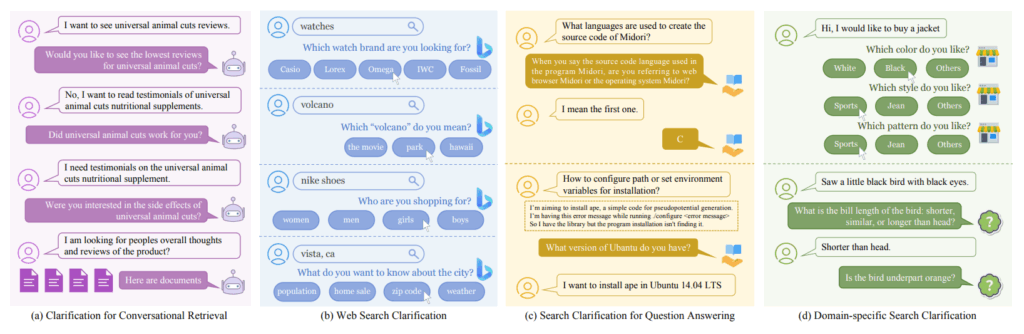
検索の明確化は、ユーザーの検索意図が曖昧または多岐にわたる場合に、システムが能動的に明確化の質問 (clarifying questions) を投げかけ、ユーザーにクエリを具体化してもらう機能です。これにより、システムはユーザーの真の意図をより正確に把握し、関連性の高い情報を提供することが可能になります。この機能は、単にユーザーの入力に反応するだけでなく、システムが対話の一部を主導する「混合イニシアティブ (mixed initiative)」なインタラクションを可能にし、より効率的な情報交換を実現します。
明確化は、ウェブ検索、質疑応答 (QA: Question Answering) システム、対話型文書検索、さらには推薦システム、法律検索、プログラミング支援といった特定のドメインなど、多岐にわたるシナリオで活用されています。
手法としては、当初は固定された質問プールから最適な質問を選択するアプローチが主流でしたが、近年ではユーザーの実際のニーズに基づいて質問を生成する方向へと進化しています。LLMは、その強力な自然言語生成能力を活用し、ファセットベースの質問生成やゼロショット学習による質問生成において大きな進歩をもたらしました。ウェブ検索の明確化では、質問だけでなく、ユーザーがクリックして選択できる複数の候補ファセットを提示することで、よりインタラクティブなユーザー体験を提供します。LLMは、その豊富な一般的知識やドメイン固有の知識を活用し、より効果的なファセット生成を可能にしています。
LLMは、その強力な自然言語生成能力と指示追従能力により、明確化の質問生成やユーザー応答のシミュレーションにおいて、既存システムの性能を向上させています。また、コード生成のための意図明確化や、ユーザーの興味を誘発する質問生成など、新たな明確化シナリオの開拓にも貢献しています。しかし、いつ明確化が必要か、どのような質問が適切かを正確かつ効率的に特定すること、またLLM自体の振る舞いの明確化など、今後も研究すべき課題が残されています。
対話型情報検索 (Conversational Retrieval)
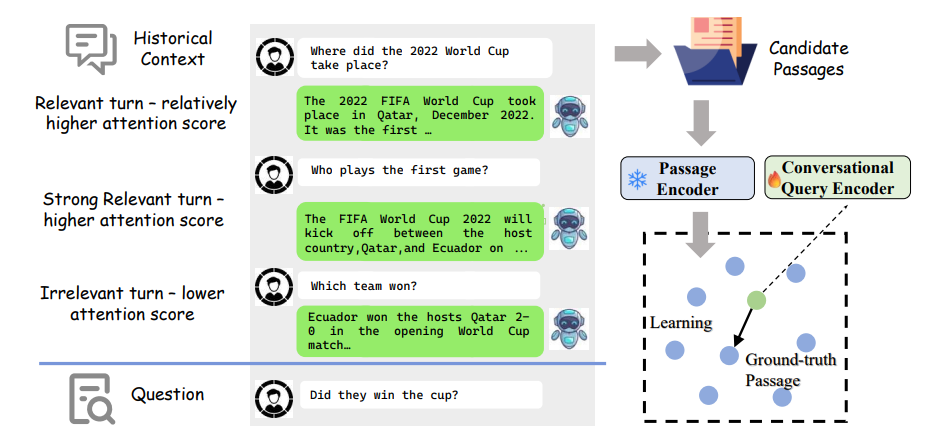
対話型情報検索は、再構築され、必要に応じて明確化されたクエリと会話文脈を用いて、大規模な知識ベースから最も関連性の高い情報を抽出するプロセスです。従来の検索とは異なり、複数ターンにわたる複雑な文脈やノイズの多い履歴の中から、ユーザーの変化する情報ニーズに対応する有用な知識の塊を効率的に見つけ出すことが求められます。
この分野にはいくつかの主要な課題があります。第一に、BERTやT5、そしてLLMといった最先端の自然言語モデルの進歩にもかかわらず、複数ターンにわたる自然言語形式の会話全体を完全に解釈することは依然として困難です。第二に、会話セッション内のすべての履歴が現在の情報ニーズに関連するわけではなく、無関係なノイズが含まれることがあります。そのため、有用な文脈を正確に特定し、ノイズを除去する技術(文脈のノイズ除去 (Context Denoising))が不可欠です。これには、モデルアーキテクチャや訓練戦略にノイズ除去を組み込む暗黙的な手法と、関連要素を明示的に選択・除去する手法があります。第三に、人間による対話のアノテーションは時間とコストがかかるため、十分な訓練データが不足しており、様々なデータ拡張技術が開発されています。最後に、高密度な表現を用いるモデルは、なぜ特定の情報を取得したのかという説明可能性 (Explainability) に課題を抱えています。
対話型情報検索の手法としては、会話の複雑な相関関係を理解するための会話モデリング (Conversation Modeling) が重要です。BERTや注意メカニズム、グラフベースのアプローチなどが用いられてきましたが、LLMは、その強力な文脈理解能力により、より洗練された会話モデリングアプローチを可能にしています。特に、対話型高密度検索 (Conversational Dense Retrieval) は、明示的なクエリ書き換えを避け、セッションエンコーダを訓練して会話全体を直接エンコードすることで、ランキング信号を直接最適化し、優れた性能を発揮する有望なアプローチです。また、最初の検索段階で取得された文書を、会話文脈に基づいてより正確に順序付けし直す再ランキング (Re-ranking) も、後続の応答生成の精度を向上させるために不可欠です。
LLMは、その強力な文脈理解能力と生成能力により、会話モデリング、データ拡張(関連性判断、対照サンプル、会話セッションの生成など)といった対話型情報検索の様々な側面で活用され、性能向上に貢献しています。
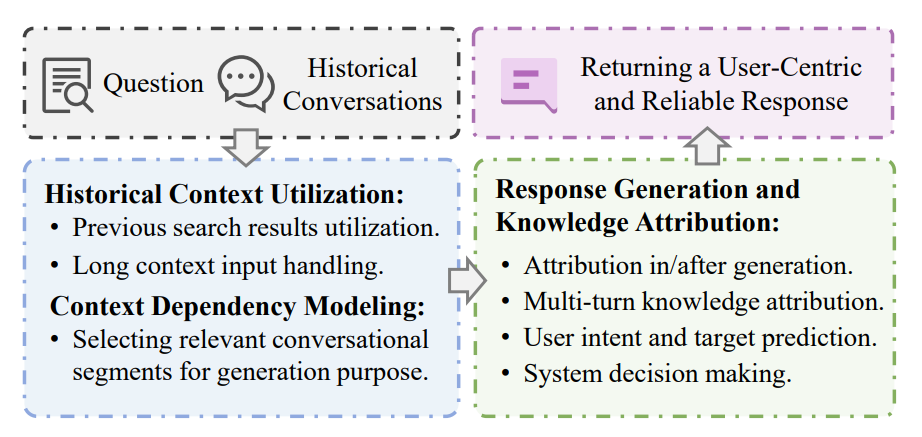
応答生成 (Response Generation)
応答生成は、検索で得られた情報と会話の文脈を統合し、ユーザーのニーズに合わせた自然言語での応答を生成するプロセスです。従来の検索システムのように単に検索結果のリストを提供するだけでなく、簡潔な回答、要約、または表形式のような構造化されたデータ形式で情報を提供することで、ユーザー体験を豊かにすることが目標とされています。
LLMの発展により、応答生成はリトリーバルと密接に連携したRAG (Retrieval-Augmented Generation) パラダイムを通じて行われるようになりました。RAGは、LLMが外部知識に基づいて、より正確で文脈に沿った応答を生成することを可能にします。これにより、生成コンポーネントは単に情報を提示するだけでなく、取得した知識を進行中の会話文脈の中で積極的に統合し、ユーザーの情報ニーズを満たす役割を担うようになりました。
しかし、応答生成にはいくつかの重要な課題が存在します。まず、過去のターンで得られた検索結果(歴史的検索結果)も、現在のRAGにおける生成を補完するために役立つ可能性がありますが、その最適な活用原則はまだ不明確です。長大な会話セッションと多数の検索結果が入力となることで、入力コンテキストの長さが増大し、モデル入力の制限を超えたり、高いレイテンシコストが発生したりする課題もあります。次に、会話における文脈依存性モデリング (Context Dependency Modeling) を正確に捉えることは、応答生成の精度向上に不可欠です。特に生成プロセスにおいては、検索と生成の段階が分離していることや、関連性の低い情報の干渉を避けるためのメカニズムが重要となります。最後に、生成された応答の信頼性を高めるために、その内容を知識源に帰属させる(引用元を明示する)会話型知識帰属 (Conversational Knowledge Attribution) は極めて重要ですが、マルチターン会話シナリオにおけるこの側面は十分に研究されていません。マルチターンでの知識帰属、ユーザーの意図とターゲットに基づく動的な帰属調整、そしてシステム意思決定との連携などが今後の課題として挙げられます。
LLMは、その強力な生成能力を活かし、RAGパラダイムにおいて中心的な役割を担いますが、生成内容の忠実性や引用の正確性を確保すること、そして検索コンポーネントとのシームレスな統合が引き続き重要な課題となっています。
会話型検索の実用化
大規模言語モデル(LLM: Large Language Models)の発展は、対話型検索システムの各コンポーネントに革命的な変化をもたらしています。LLMは、クエリ再構築、検索の明確化、対話型情報検索、応答生成といった、これまで個別に機能していた要素間の境界を曖昧にし、より統合的でエンドツーエンドなアプローチを可能にしました。
LLMによる機能強化
LLMは、その強力な自然言語理解(NLU)と自然言語生成(NLG)能力により、ユーザーの曖昧な意図をより深く解釈し、関連性の高い情報を効率的に検索し、文脈に即した自然な応答を生成できます。実際に、Perplexity.aiやSearchGPTといった商用サービスでは、既にLLMを基盤とした対話型AI検索エンジンが広く利用され、急速にユーザーベースを拡大し、大きな成長を遂げています。LLMの登場は、対話型検索における技術とアプリケーションシナリオを大きく進展させました。
ドメイン特化型アプリケーション
対話型検索システムは、その汎用性を活かし、特定の専門分野における情報アクセスを大きく革新しています。
- 医療分野: 複雑な病状の相談や専門用語の解説、過去の病歴を考慮した情報提供が可能です。しかし、極めて高い正確性と情報の鮮度が必須であり、LLMのハルシネーション(誤情報生成)は特に危険な課題です。患者の言語と医療専門用語の橋渡しが不可欠です。
- 金融分野: 市場トレンドの分析、複雑な金融商品の説明、リアルタイムデータの利用が求められます。数値的推論の堅牢性と規制遵守が特に重要ですが、LLMによる多段階の数値推論は依然として課題です。
- 法律分野: 判例の検索、専門用語の解釈支援、法的文書からの証拠抽出に活用されます。高精度な論理的推論が不可欠であり、取得された証拠が文脈的に適切で法的に健全であるかの保証が課題となります。
- e-コマース: 顧客の購買履歴や好みに基づくパーソナライズされた商品推薦や、マルチモーダルな商品情報(テキストや画像など)への対応により、顧客サービスを強化します。

課題と将来展望
対話型検索は大きな可能性を秘めている一方で、まだ克服すべき課題も多く存在します。
主要な技術的課題
既存のデータセットはアノテーションの偏りや規模の限定性を抱え、汎化性能を妨げます。評価指標も、語彙的重複度のような間接的な評価では実際の検索効果を測りきれず、エンドツーエンド評価もモデルバイアスに影響されがちです。 技術的には、長大な対話におけるエラーの累積や、ノイズの多い履歴からの有用情報選別が困難です。また、LLMによる「幻覚」(hallucination)問題(事実と異なる内容の生成)は医療など高リスクドメインで深刻であり、応答の信頼性を担保する「知識帰属」(knowledge attribution)の正確性が重要です。効率性、汎化性能、そして「説明可能性」(explainability)の確保も継続的な研究テーマです。
対話型検索の未来
将来的には、LLMエージェントがユーザー意図やシステム信頼度に基づき、「質問する」「検索する」「生成する」「外部ツールを呼び出す」といった最適なアクションを自律的に決定できるようになると期待されています。また、システムは能動的にユーザーに働きかけ、パーソナライズされたプロアクティブな対話体験を提供し、豊かな情報探索を可能にするかもしれません。 評価では、実際のユーザー行動を忠実に模倣する「高忠実度なシミュレーション」(high-fidelity user simulations)による評価手法の確立が不可欠です。加えて、テキストだけでなく「マルチモーダル情報」(multi-modality information)の統合、多様で情報量の多い応答形式の提供も今後の鍵です。
おわりに
今回は、サーベイ論文「A Survey of Conversational Search」をベースに、従来の検索との違いから、対話型検索を構成する主要なコンポーネント(クエリ再構築、検索明確化、対話型情報検索、応答生成)について解説しました。大規模言語モデル(LLM: Large Language Models)の急速な進化は、これらの機能を統合し、より直感的でインテリジェントなユーザー体験を提供する対話型検索の実現を加速しています。
対話型検索は、単に情報を提供するだけでなく、自然言語による対話を通じてユーザーの複雑なニーズに能動的に応えることで、情報探索のあり方を根本から変える可能性を秘めています。この分野では、今後もデータの偏りやハルシネーション(幻覚)といった主要な技術的課題を克服しつつ、より賢く、よりユーザー中心の検索システムを実現するための継続的な研究開発が期待されます。
More Information
- arXiv:2410.15576, Fengran Mo et al., 「A Survey of Conversational Search」, https://arxiv.org/abs/2410.15576
関連記事

PINN入門: 物理法則を組み込んだAIで微分方程式を解く
近年、ディープラーニングの技術は目覚ましい進歩を遂げ、画像認識、自然言語処理、ロボティクスなど、多岐にわたる実世界の問題解決に応用されています。しかし、複雑な物理現象や数学的な問題、特に微分方程式の解決においては、従来の […]

LangCodeではじめるAIコードアシスタント入門
AIコードアシスタントは、コードの自動生成だけでなく、既存の複雑なコードベースの理解やタスクの自動実行を通じて、開発者の作業を大きく変えつつあります。今回は、最近リリースされた「LangCode」と呼ばれるツールを紹介し […]

Prompt Repetition: プロンプト反復によるLLMの改善
LLMの精度向上のために、日々プロンプトの試行錯誤を繰り返しているエンジニアは多いはずです。Google Researchの研究チームは、そのような課題に対し、非常にシンプルかつ強力な解決策である「Prompt Repe […]