天文学における深層学習を用いたマルチモーダルデータ活用

宇宙は複数の物理プロセスが複雑に絡み合う空間であり、その振る舞いは様々な波長や時間スケール、エネルギー範囲にまたがっています。そのため、単一の観測データ(ユニモーダルデータ)のみに依存した解析では、天体現象の背後にあるメカニズムを完全に捉えきれず、解釈に偏りや不完全さが生じる限界がありました。
これまでにも多波長やマルチメッセンジャーを用いた解析は実施されてきましたが、その多くは前処理済みのデータや派生パラメータを統計的に関連付ける(空間的な位置照合など)にとどまっていました。つまり、異なるデータ形式(モダリティ)の間に潜む、複雑で非線形な関係性を直接モデル化するには至っていなかったのです。
こうした従来の解析手法が抱えるボトルネックを根本的に打破するアプローチとして、深層学習を用いた「MDF(Multimodal Data Fusion: マルチモーダルデータ融合)」が注目を集めています。深層学習を活用することで、様々なモダリティから自動的に特徴を抽出し、より高度な表現学習を進めることが可能になります。
この記事では、このMDFが天文学におけるデータ活用にどのような革新をもたらすのか、その全体像を解説します。
1. 5つの主要モダリティとその相互補完性
天文学で取り扱うデータは、主に「画像(Image)」「スペクトル(Spectral)」「時系列(Time-series)」「表(Tabular)」「テキスト(Text)」の5つのモダリティに分類されます。これらのデータはそれぞれが独自の次元情報を持っていますが、決して孤立しているわけではなく、同一の天体現象に対する別々の投影として互いに補完し合う関係にあります。
各モダリティの特徴と相互のつながりを以下に整理します。
- 画像データとスペクトルデータ: 画像データは、銀河の形態や空間的な構造を視覚的に捉える情報を提供します。一方でスペクトルデータは、天体からの光を波長ごとに分解し、赤方偏移や元素組成といった物理的・化学的性質を明らかにします。画像が空間的な文脈を提供するのに対し、スペクトルがその背後にある物理的な解釈を与えることで、両者は強力に補完し合います。
- 時系列データ: 時間経過に伴う観測量の変動を記録するデータです。これにより、静的なデータでは捉えきれない恒星の脈動、連星系の相互作用、あるいは超新星爆発などの突発的な現象(トランジェント)といった、宇宙の動的な変化を解析することが可能になります。
- 表(カタログ)データ: 座標や等級などが整理された表データは、情報密度が非常に高く、様々な多変量情報を提供します。大規模なデジタルスカイサーベイ間などで、座標などを基準にして異なるモダリティを交差マッチング(クロス照合)し、データを連携させるための重要な基盤として機能します。
- テキストデータ: 観測ログや学術論文などのテキストデータには、観測条件や理論的背景など、強力な文脈的意味の一貫性と天文学特有の専門用語が含まれています。固有表現抽出やトピックモデリングといった自然言語処理(NLP)技術を用いてこれらを構造化することで、観測による測定結果と理論的知識を結びつけ、「知識主導の推論」を進めることが実現します。
このように、これら5つのモダリティを連携させることで、単一のデータでは解明できなかった宇宙の複雑なメカニズムがより鮮明に描き出されます。
2. MDFを支える深層学習モデルの役割と優位性
宇宙物理学におけるマルチモーダルデータ融合(MDF)を実現するためには、各データの特性に応じた深層学習モデルの選択が不可欠です。ここでは、MDFを支える主要なモデルの役割とそれぞれの優位性について整理します。
画像データの処理においては、CNN(畳み込みニューラルネットワーク)が銀河の形態的なパターン抽出などに優れた性能を発揮します。しかし、ネットワークの受容野が限られているため、より大局的なパターンの把握には限界があります。また、光度曲線などの時系列データの分析にはRNN(回帰型ニューラルネットワーク)が有効です。ですが、RNNは系列が長くなるにつれて長期間の依存関係をモデル化することが難しくなるという課題を抱えています。
これらの課題を克服し、現在のMDFにおいて中核的な役割を担っているのがTransformerです。Transformerは、自己注意機構(Self-attention)を利用することで、離れたデータ間の大局的な依存関係(グローバルな関係性)を並列処理で捉えることが可能です。これにより、異なるモダリティ間での意味論的なアライメントや統合的な表現学習において極めて優れた性能を示しており、現在のMDFにおけるコアモデルとして機能しています。
さらに、稀な天体現象の研究などでは、特定の観測データが不足したり欠損したりするケースが頻発します。このようなデータ不足の課題に対しては、以下の生成的なアプローチを活用するモデルが重要な役割を果たします。
- オートエンコーダ(AE): 異なるモダリティを共有の潜在空間に投影し、データ間で共通する特徴を抽出することで、異質なデータの統合を進めます。
- 敵対的生成ネットワーク(GAN): データ拡張として希少なサンプルの高精細な疑似データを生成したり、あるモダリティから欠損している別のモダリティの情報を合成したりすることで、モダリティ間の情報のギャップを埋める役割を担います。
このように、様々なモデルの強みを組み合わせることで、単一の手法では捉えきれなかった複雑な天文学データから、より深い物理的な洞察を得ることが可能になります。
3. 4つのデータフュージョン戦略の比較と適用条件
MDFをモデルに組み込む際、どの段階でデータを融合させるか(フュージョン戦略)は、最終的な予測性能を左右する極めて重要な要素です。天文学におけるMDF研究では、主に以下の4つの戦略が議論されています。
| フュージョン戦略 | 概要 | 主な適用条件・留意点 |
|---|---|---|
| Data-level fusion | 生データを入力前に直接統合する | 同一の構造を持つデータ向けだが、天文学では非推奨 |
| Feature-level fusion | 中間層で抽出した特徴ベクトルを融合する | 意味的に一貫したデータに最適で、天文学のMDFにおける主流 |
| Decision-level fusion | 独立したモデルの最終出力(確率など)を統合する | データの独立した識別能力が高いタスクや非同期データ向け |
| Hybrid fusion | 複数の戦略をタスクに応じて動的に組み合わせる | 複雑なタスクに有効だが、高度なアーキテクチャ設計が必要 |
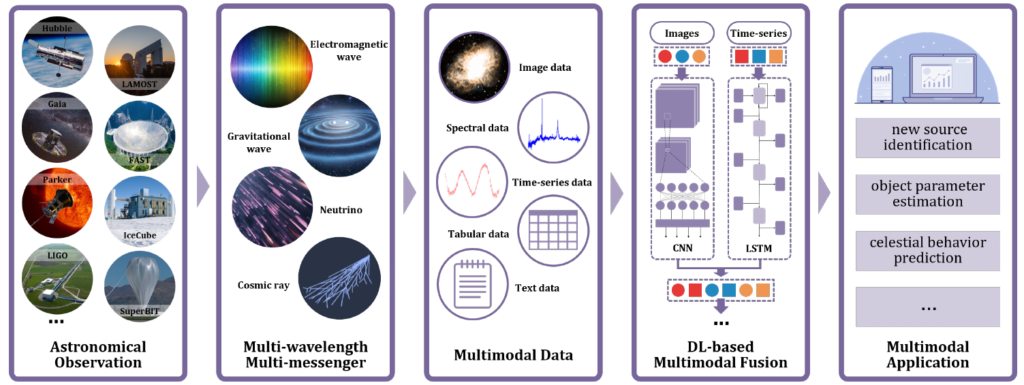
Data-level fusion(データレベルの融合)
入力前の生データを直接統合する最も初期のアプローチです。同じ観測領域を対象とした多波長画像のように、データ形式が揃っている場合には元の情報を完全に保持できるメリットがあります。しかし、画像とスペクトルのように形式が大きく異なるモダリティ間の意味論的・統計的な異質性には対処できません。無理に統合を進めると、高次元空間でのノイズ増幅や「次元の呪い」に陥りやすくなるため、現在の天文学においては推奨されていない手法です。
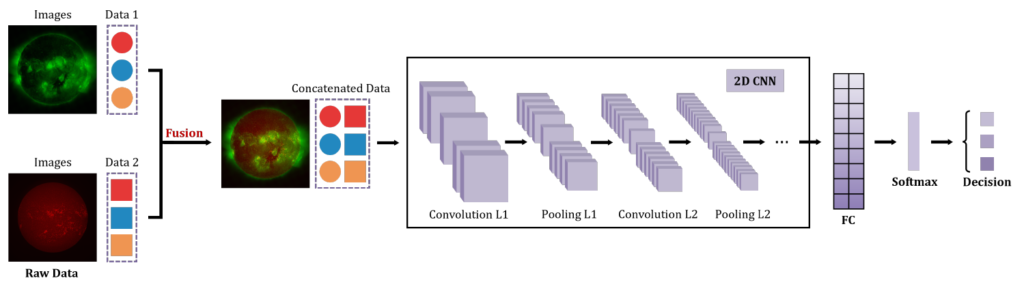
Feature-level fusion(特徴レベルの融合)
各モダリティから独立したネットワークで特徴を抽出した後に、中間層で融合を実施する戦略です。データの構造が異なっていても、対象とする天体現象に対する意味的な一貫性があれば適用できるため、天文学におけるMDF研究の圧倒的多数(約93%)を占める主流のアーキテクチャとなっています。高次元での冗長性や次元の呪いを回避するため、近年では単純な特徴の結合ではなく、Attention機構や射影メカニズムを利用して、モダリティ間の依存関係を動的に重み付けする工夫が積極的に採用されています。
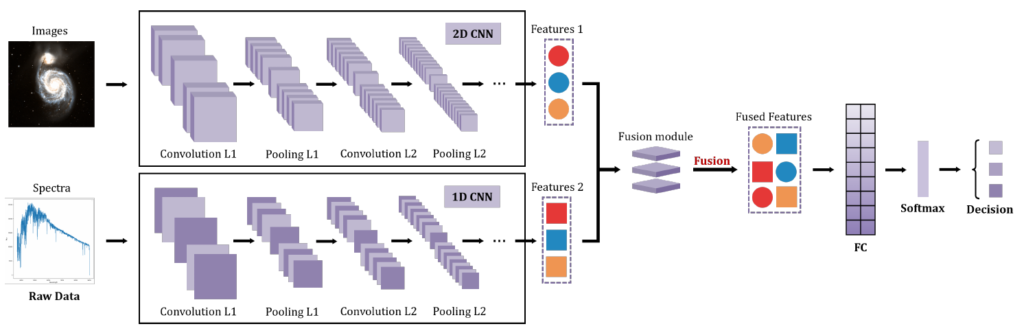
Decision-level fusion(決定レベルの融合)
各モダリティ専用のモデルが独立して推論を完結させ、その最終的な出力結果(分類の確率など)を統合する手法です。観測タイミングがずれている非同期データや、全く異なるアーキテクチャのモデルの統合に強いという特徴があります。各モダリティ単独での識別能力が十分に高い場合に最も効果を発揮します。リアルタイム性が求められ、データの非同期性が高い宇宙天気予報や太陽物理学の分野(太陽フレアの予測など)において、非常に効果的な選択肢として採用されています。

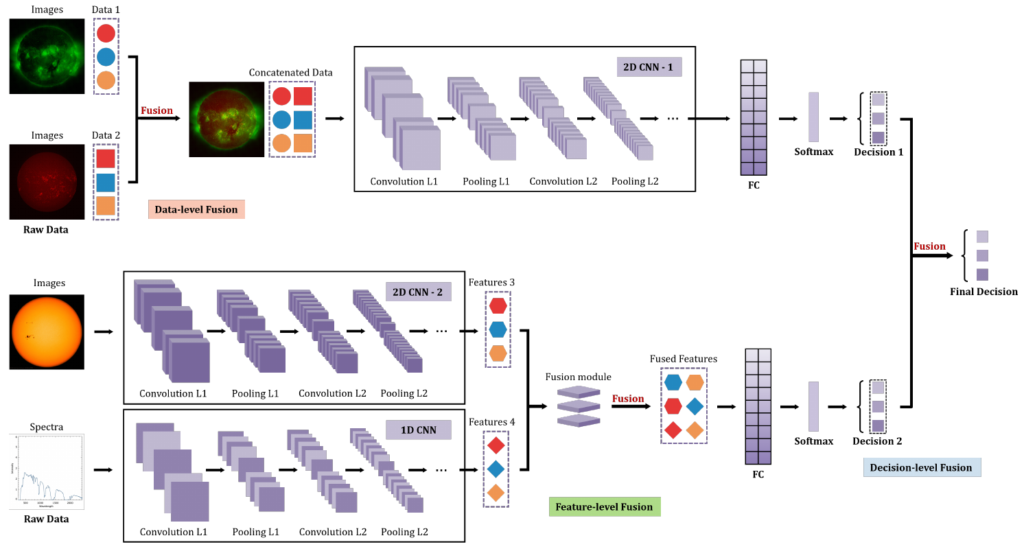
Hybrid fusion(ハイブリッド融合)
上記の複数の融合レベルをタスクに応じて動的かつ階層的に組み合わせる戦略です。例えば、低レベルで元の詳細情報を保持しつつ、高レベルで全体的な一貫性を捉えるといった複雑な情報統合タスクに最適です。一方で、計算の冗長性や情報の過負荷を防ぐためには、各レベルの貢献度を適切に調整するための高度なモデル設計と訓練戦略が必要となります。
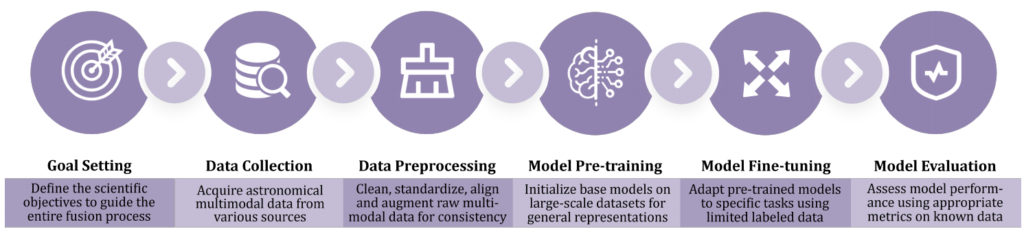
4. モデル構築・学習・評価のプロセス
MDFモデルの構築から評価に至るプロセスでは、天文学データの特性に合わせた慎重な設計が求められます。ここでは、実運用に向けて特に重要となる4つのフェーズを解説します。
- データアライメント(前処理): 異なる観測機器や条件から得られたデータを統合するためには、データ間の不整合を吸収する前処理が不可欠です。具体的には、座標ベースのクロス照合などを利用する「空間的アライメント」、タイムスタンプを同期させる「時間的アライメント」、そしてアノテーションなどを通じてテキスト記述と観測データの内容を合致させる「意味論的アライメント」を実施します。
- 事前学習(Pre-training): 主流である特徴レベルの融合において、モダリティ間の相互作用を捉えるための重要なステップです。モダリティを個別に学習させてから後段でアライメントするアプローチは、計算コストを抑えやすい反面、モダリティ間に潜む相補的な情報が失われるリスクを伴います。これに対し、共通の特徴空間で統合的に事前学習(ジョイント最適化)を進める手法は、クロスモーダルな意味的整合性をより強固に確立できるため非常に有効です。
- ファインチューニング: 事前学習で獲得した一般的な表現能力を、限られたラベル付きデータを利用して特定の宇宙物理学タスクに適応させます。軽量なモデルや、事前学習と対象タスクの性質が近い場合には、モデル全体を更新する「フルファインチューニング」が適しています。一方で、大規模な基盤モデルを扱う場合やデータ数が限られている状況では、LoRAなどのパラメータ効率の良い手法(PEFT)を使い分けることが推奨されます。
- モデル評価: 天文学データには特有のノイズが含まれており、稀な天体現象などによる極端なデータの不均衡も頻発します。そのため、単なる正解率(Accuracy)のみで判断するのではなく、AUC-ROC曲線や平均適合率(Average Precision)といった指標を用いた評価を実施する必要があります。さらに、モデルの汎化性能を客観的に測るため、クロスバリデーション(交差検証)などを取り入れることも重要です。
5. 現在の課題と将来の展望
深層学習を用いたマルチモーダルデータ融合(MDF)は、宇宙物理学のデータ解析に革新をもたらしつつありますが、実運用やより広範な普及に向けては、いくつかの重要な課題と今後の方向性が議論されています。
- 異質なモダリティの融合: 観測機器が異なれば、データの解像度やPSF(点像分布関数)、時間的なサンプリングレートも大きく異なります。これらの構造的・統計的に異質なデータを物理的な矛盾なく融合させるためには、単純な前処理に頼るのではなく、クロスモーダルなキャリブレーションや物理情報に基づく解像度マッチングを、モデルのアーキテクチャに直接組み込む工夫が求められています。
- 解釈可能性(Interpretability)の担保: 物理学的な厳密さが重視される天文学において、モデルが「なぜその予測に至ったのか」が分からないブラックボックス状態は大きな懸念事項です。データ内のノイズではなく真の物理的な相関をモデルが学習しているかを確認するため、物理学的な制約をAttention機構に組み込んだり、不確実性を明確に分解できる説明可能なAI(XAI)の導入を進めたりすることが必須となっています。
- 標準化ベンチマークの構築: これまでのMDF研究は、特定のタスクごとに小規模なデータセットを構築して進められることが多く、研究の分断が課題でした。しかし近年、「MultimodalUniverse」(約100TB規模)のような大規模かつ標準化されたデータセットが登場し始めました。これにより、コミュニティ全体で一貫してモデルを比較・検証する基盤が整い、アルゴリズムの進化と一般化が加速すると期待されます。
- スケーラビリティの確保: 複雑なMDFモデルや巨大な観測データを扱うにつれて、計算およびストレージコストは急増します。計算資源の制約から不本意なダウンサンプリング(情報の間引き)を実施してしまっては、MDFの本来の利点が失われてしまいます。これに対処するため、今後はローカル環境での計算に依存せず、クラウドストレージ上のデータに直接アクセスして分散処理を進める「クラウドネイティブな融合アルゴリズム」への移行が将来の鍵を握ります。
おわりに
深層学習を用いたMDFは、単一の観測データが抱える限界を超え、宇宙の複雑な物理現象を解明するための次世代のコア技術として確固たる地位を築きつつあります。
実用的なモデルを構築するには、最適なフュージョン戦略の選択にとどまらず、慎重なデータアライメントから、統合的な事前学習、LoRAなどを活用した効率的なファインチューニング、そして極端なデータの不均衡を考慮した客観的な評価に至るまで、一連のプロセスをタスクに応じて最適化する必要があります。
今後は、異質なデータ間に生じる物理的な矛盾の解消や、モデルの解釈可能性の向上、さらにはクラウドネイティブな計算環境の構築へ継続して取り組むことが求められます。これらの課題を克服することで、MDFが天文学における新たな科学的発見を力強く牽引する、スケーラブルな基盤となることが期待されます。
More Information
- arXiv:2603.00699, Wujun Shao et al., 「Deep learning-based astronomical multimodal data fusion: A comprehensive review」, https://arxiv.org/abs/2603.00699
関連記事

反証可能性の壁:LLMは科学的研究を促進させるのか?
近年、GPT-5などの最先端モデルが、数学や物理、生物学といった様々な分野で新たな知見を生み出し、人間レベルの知能を示しているという報告が相次いでいます。モデルが複雑な課題を解き、科学の研究プロセスを大幅に加速させる様子 […]

最先端技術の貢献度を体系化するデザインサイエンス妥当性フレームワーク
機械学習モデルを開発する際、私たちは精度(precision)や再現率(recall)、F1スコアといった定量的な指標を用いて性能を評価することが一般的です。これらの指標は、知識クレームの妥当性を確立するための尺度ですが […]

The Multimodal Universe: 天文学向け大規模機械学習用ビッグデータ
天文学は、その観測対象の広大さと複雑さから、常に膨大なデータを扱う分野です。近年、技術の進歩に伴い、画像、スペクトル、時系列データなど、多種多様な形式のデータが取得できるようになりました。これらのデータを統合的に解析する […]