Agentic Code Reasoning: 構造化された準形式的推論の威力

大規模言語モデル(LLM)を活用したコーディングエージェントが普及する中、コードを実際に実行することなく、その意味や振る舞いを正確に読み解く「Agentic Code Reasoning(エージェントによるコード推論)」の能力が注目を集めています。
しかし、従来のChain-of-Thought (CoT)のような非構造化プロンプトでは、エージェントが関数の中身などを最後まで追跡せず、不十分な証拠のまま推測で結論を出してしまう課題がありました。
本記事では、この課題を解決する「準形式的推論(Semi-formal Reasoning)」という新しいプロンプト設計の手法を解説します。
これは、自然言語の使いやすさを保ちつつ、エージェントに「前提の明示」や「実行パスの追跡」などを証拠として要求することで、解析の厳密さを高めるアプローチです。テスト環境を用意せずにバグの特定やパッチの検証を進める上で、様々なタスクの精度を飛躍的に高める具体的な仕組みをご紹介します。
1. エージェントによるコード推論における現状の課題
「Agentic Code Reasoning(エージェントによるコード推論)」とは、AIエージェントが自律的にリポジトリ内を探索し、関数やファイルの依存関係を追跡しながら、コードを実際に実行することなく深い意味解析(Semantic Analysis)を進める能力を指します。この能力は、複数のファイルにまたがるバグの特定や、修正パッチが想定通りに動作するかを検証するタスクにおいて非常に重要です。
しかし、エージェントがコードを正確に理解できているかを評価し、単なる当てずっぽうではなく徹底的な推論を促すことには、大きな課題が存在していました。これまでのアプローチには、大きく分けて2つの極端な手法があり、それぞれに弱点がありました。
- 自由な推論による「推測」の危険性:
従来の非構造化プロンプト(自由な推論)では、エージェントがコードの動作を明確な根拠なしに推測してしまう傾向があります。たとえば、別のファイルで定義されている同名の関数を標準ライブラリのものだと勘違いしたり、確認すべき特殊なケース(エッジケース)を見落としたりして、不十分な証拠のまま誤った結論を導き出してしまうことが珍しくありません。 - 完全な形式的検証の「実用性の低さ」:
一方で、LeanやCoqといったツールを用いた完全な「形式的検証(Formal Verification)」のアプローチも存在します。これは極めて厳密な解析が可能ですが、プログラミング言語の仕様を数学的に厳密に定義しなければなりません。そのため、様々な言語やフレームワークが複雑に絡み合う実務の巨大なコードベースに適用するには、実用上のハードルが高すぎるという問題がありました。
このように、「自然言語の推論が抱える危うさ」と「形式的証明のハードルの高さ」というジレンマをどう克服するかが、コード推論を実用化する上での大きな壁となっていました。
2. 準形式的推論(Semi-formal Reasoning)のアプローチ
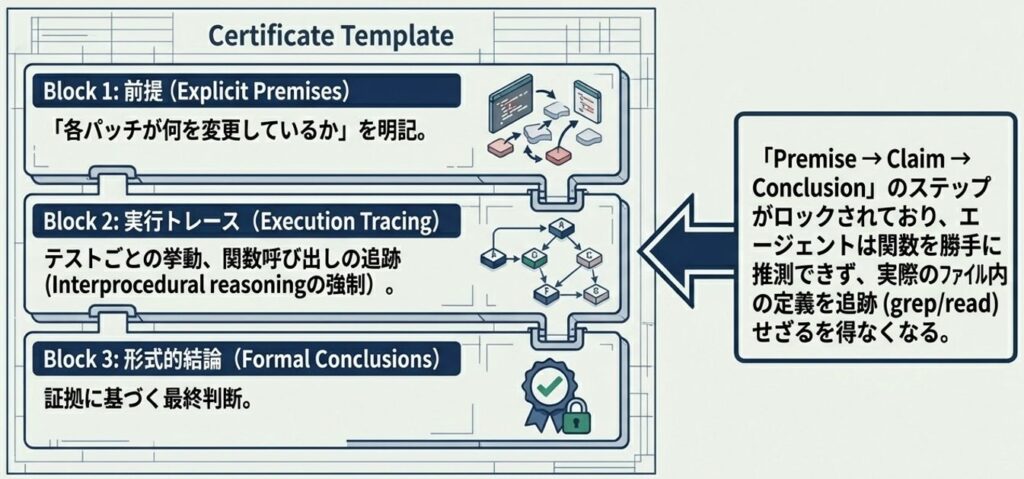
前述した「自由な推測の危うさ」と「形式的検証のハードルの高さ」というジレンマを解消するために考案されたのが、「準形式的推論(Semi-formal Reasoning)」という新しいアプローチです。これは、自然言語の扱いやすさを活かしつつ、エージェントの推論プロセスに厳密な構造を持たせる手法です。
具体的には、エージェントに専用の「推論テンプレート」をプロンプトとして提供し、推論の過程全体を一つの「証明書」のように機能させます。このテンプレートでは、主に以下の3つのステップをエージェントに強制します。
- 前提の明示: どのコード領域が修正されたかなど、検証のスタート地点となる客観的な事実を明確に記述させます。
- 実行パスの追跡: コードが実際にどう動くのか、テストごとに経路や関数呼び出しをステップ単位で徹底的に追いかけさせます。
- 形式的な結論の導出: 収集した具体的な証拠に基づいて、最終的な結論を論理的に導き出させます。
この手法の最大のポイントは、単に出力の見た目を整えることではありません。「結論を出す前に、必ずソースコードから検証可能な証拠を集めなければならない」という制約をエージェントに設ける点にあります。
たとえば、これまでのエージェントは、関数の名前だけを見て「標準ライブラリの機能だろう」と直感で推測しがちでした。しかし、準形式的推論によって実行パスの追跡を義務付けることで、「実際に関数の中身をたどると、別のファイルで独自に定義された関数だった」といった重大な見落としを防ぐことができます。結果として、直感に基づく早計な判断が排除され、コード解析の精度を大幅に引き上げることが可能になります。
3. 実践例:プロンプト設計の比較
ここでは、実際のオープンソースプロジェクト(ローカルLLM実行環境である「Ollama」)のコードベースを対象に、エージェントにコードの挙動を説明させるタスクを用いて、「一般的な推論(Standard Reasoning)」と「準形式的推論(Semi-formal Reasoning)」の出力結果を比較します。
テーマは 「Ollamaにおけるモデルロード時のVRAM空き容量計算と、GPU/CPU間のレイヤー分割(オフロード)の仕組み」 です。
3-1. 一般的な推論(Standard Reasoning)
入力プロンプト
対象コードの動作について、詳細な説明を求めるシンプルな指示を与えます。
Ollamaのソースコードにおいて、モデルをロードする際のメモリ管理とオフロードの仕組みについて質問します。 以下の点について、コードの動作を詳細に説明してください。
1. モデルをロードする際、VRAMの空き容量はどのように計算されていますか?
2. GPUとCPUの間で、モデルのレイヤーはどのように分割(オフロード)されていますか?その決定ロジックを教えてください。Agentの回答
一般的な推論プロンプトに対するエージェントの回答は、一見すると非常に尤もらしく、綺麗なマークダウンで構成されます。
回答内容は概ね合っているように見えますが、「なぜそう言えるのか」というコード上の具体的な証拠(ファイルパス、行番号、実際の条件式)が欠落しています。エージェントは過去の学習データや関数名から尤もらしいストーリーを生成(推測)している可能性があり、実際にコード内のエッジケースを見落としがちです。複雑なリポジトリにおいて、この「もっともらしいが根拠の薄い推測(ハルシネーション)」は、致命的なバグ見落としに繋がります。
# Ollamaにおけるモデルのメモリ管理とオフロードの仕組み
Ollamaのソースコード(主に `llm/` および `ml/` ディレクトリ配下)における、モデルロード時のVRAM空き容量計算とレイヤー分割(オフロード)のロジックについて解説します。
## 1. VRAM空き容量の計算方法
モデルロード時におけるVRAMの空き容量計算は、Ollamaのメインプロセスと、バックエンドで実際に推論を実行する `runner` プロセスとの通信によって動的に行われます。
1. **Runnerプロセスへの問い合わせ**:
Ollamaはモデルをロードしたりシステム状態を確認したりする際、`runner` プロセスのHTTPエンドポイント(通常 `http://127.0.0.1:<port>/info`)にアクセスしてデバイス情報を要求します(`ml/device.go` の `GetDevicesFromRunner`)。
2. **GGML(バックエンド)を通じたハードウェアからの直接取得**:
リクエストを受け取った `runner` プロセスは、GGMLのC APIを経由してハードウェアのドライバから直接メモリ情報を取得します。`ml/backend/ggml/ggml.go` の `BackendDevices` 関数内で `C.ggml_backend_dev_memory(dev, &props.memory_free, &props.memory_total)` が呼び出され、各GPU(CUDA, Metal, ROCmなど)の「総VRAM」と「現在の空きVRAM」が正確に取得されます。
3. **安全マージンの適用 (`llm/server.go` の `buildLayout`)**:
取得した空きVRAMを100%割り当てに使うことはしません。計算グラフ展開用のメモリや、最低限システムが要求するVRAM容量(`MinimumMemory`)、さらにOllama側のオーバーヘッド(`GpuOverhead`)を差し引いた上で、安全マージンを考慮した係数(`backoff`)を適用した値が、実際にモデルのレイヤーを配置できる**有効な空きVRAM**として計算されます。
## 2. GPUとCPU間のレイヤー分割(オフロード)の決定ロジック
GPUとCPU間でレイヤーをどのように分割するかは、`llm/server.go` 内の `buildLayout`, `assignLayers`, `findBestFit`, `greedyFit` といった一連のアルゴリズムによって決定されます。
1. **各レイヤーのサイズ計算 (`buildLayout`)**:
まず、モデルの重み(Weights)やキャッシュ(Cache)のサイズを合算し、レイヤーごとの必要メモリサイズを算出します。
2. **GPUのソートと配置戦略 (`assignLayers`)**:
利用可能なGPUは、空きメモリ量や性能に基づいてソートされます。
デフォルトでは、通信オーバーヘッドを避けるために**なるべく少数のGPUにレイヤーを詰め込む(パッキングする)**戦略がとられます。ただし環境変数で `OLLAMA_SCHED_SPREAD` が有効な場合は、搭載されている全GPUに対して均等に負荷を分散させようとします。
3. **最適なバランスの探索 (`findBestFit`)**:
複数GPU間でレイヤーを分割する際、一部のGPUだけを100%使い切るのではなく、各GPUのVRAM容量比率に合わせてバランス良く配置するために、`0.0` から `1.0` の間の「キャパシティ係数(Capacity Factor)」を二分探索(Binary Search)で見つけ出します。
4. **逆順でのレイヤー割り当てとスピルオーバー (`greedyFit`)**:
実際の割り当ては、モデルの**後ろのレイヤー(出力に近いレイヤー)から順番に逆順で**GPUに配置していきます。
- 対象レイヤーのサイズが現在のGPUの「空き容量 × キャパシティ係数」に収まる場合は、そのGPUに割り当てます。
- 収まらなくなった場合は、次のGPUデバイスに処理を移します(スピルオーバー)。
- すべてのGPUが一杯になった場合、入り切らなかった残りのレイヤー(主にモデルの前半のレイヤー)は自動的に**CPUのシステムメモリへフォールバック**されます。
5. **出力レイヤーの特別扱い (`assignLayers`)**:
もしすべてのレイヤーがVRAMに収まりきらない場合、全体のスループットを維持するため、2回目の試行では「最もサイズが大きくなりやすい最後の出力レイヤーを意図的にGPUから除外し、それ以外のレイヤーのオフロードを優先する」という工夫も行われています。
6. **システムリミットの検証 (`verifyLayout`)**:
最後に、計算された配置プランがシステムの物理メモリ(RAM)やスワップ領域の上限を超えないかを検証します。これを超える場合はエラーとし、安全のために古いモデルの退避(Evict)などのフォールバック処理を促します。3-2. 準形式的推論(Semi-formal Reasoning)
一方、準形式的推論では、単に説明を求めるのではなく、「推論テンプレート」を提供し、証拠の提示を強制します。
入力プロンプト
以下のようなステップをテンプレートとしてプロンプトに組み込みます。
- Function Trace Table: 調査した関数名、ファイル名、正確な動作のリスト化。
- Data Flow Analysis: 重要な変数(VRAM容量など)の伝播の追跡。
- Semantic Properties with Explicit Evidence: 主張に対する具体的なコードスニペット(証拠)の提示。
- Alternative Hypothesis Check: エッジケースや代替挙動の検証。
- Final Conclusion: 上記の証拠に基づく最終結論。
Ollamaのソースコードにおいて、モデルをロードする際のメモリ管理とオフロードの仕組みについて調査します。
直感や関数名からの推測は避け、必ず以下の「Semi-formal Reasoning Template」に従って、コードの実行経路と証拠を体系的に文書化してから結論を出してください。
**【分析対象のタスク】**
1. モデルをロードする際、VRAMの空き容量はどのように計算されていますか?
2. GPUとCPUの間で、モデルのレイヤーはどのように分割(オフロード)されていますか?その決定ロジックを教えてください。
**【Semi-formal Reasoning Template】**
**1. Function Trace Table(関数トレーステーブル)**
このタスクに関連して調査したすべての関数をリストアップし、推測ではなく実際のコードに基づく動作を記述してください。
* 関数名:
* ファイル名 (可能な場合は行番号):
* 確認された正確な動作:
**2. Data Flow Analysis(データフロー分析)**
メモリ計算とオフロード決定に関わる重要な変数(例:利用可能なVRAM容量、モデルの必要メモリサイズ、オフロードされるレイヤー数など)が、関数間でどのように伝播し、計算・変更されているかを追跡して記述してください。
**3. Semantic Properties with Explicit Evidence(明確な証拠に基づくコードの性質)**
タスクの質問に対するあなたの主張を記載し、それを裏付ける**具体的なコードスニペットや処理条件**を証拠として提示してください。
* 主張1(VRAMの計算方法):
* 証拠1(該当するコード行やシステムコールの詳細):
* 主張2(レイヤーの分割・オフロード決定ロジック):
* 証拠2(該当する計算式や条件分岐の詳細):
**4. Alternative Hypothesis Check(代替仮説の検証)**
特定の条件下(例:VRAMが全く足りない場合、複数GPUが存在する場合など)で、あなたの主張したロジックとは異なるエッジケースの挙動が存在しないか、コードを検証して記述してください。
**5. Final Conclusion(最終的な結論)**
上記1〜4で収集した**検証済みの証拠のみ**に基づいて、VRAMの計算方法とオフロードの分割ロジックを詳細かつ正確に説明してください。Agentの回答
このプロンプトを与えられたエージェントは、結論を出す前に必ずコードを深く読み込み、以下のような検証プロセスを経た回答を出力します。
- 具体的な証拠の提示:
「ml/backend/ggml/ggml.goにおけるC.ggml_backend_dev_memory(dev, &props.memory_free, ...)によって取得されています」 といった、実際のコード行を具体的な証拠として提示します。 - 例外処理やエッジケースの発見:
「代替仮説の検証(Alternative Hypothesis Check)」 のステップにおいて、「macOS(Darwin)環境においては、計算されたVRAMの合計がTotalMemoryを超えるとシステムハングアップを防ぐため、強制的にNumGPUを0にリセットする処理がある」 といった、プラットフォーム固有の重要な例外処理を自律的に発見し、報告します。これは単なる推測では決して辿り着けない深い洞察です。
**【Semi-formal Reasoning Template】**
**1. Function Trace Table(関数トレーステーブル)**
このタスクに関連して調査したすべての関数をリストアップし、推測ではなく実際のコードに基づく動作を記述してください。
* 関数名: `getFreeMemory`
* ファイル名: `discover/gpu_info_darwin.m`
* 確認された正確な動作: Darwin (macOS) 環境において、`host_statistics64` と `HOST_VM_INFO64` を利用して `free_count`、`speculative_count`、`inactive_count` を取得し、ページサイズを掛けて合計することで、システムが利用可能な総空きメモリ容量を計算します。
* 関数名: `BackendDevices`
* ファイル名: `ml/backend/ggml/ggml.go`
* 確認された正確な動作: ランナー側のプロセスにて、C言語の関数 `C.ggml_backend_dev_memory` を呼び出すことで、バックエンド(ggml)が認識している各GPUの実際のTotalMemoryとFreeMemoryを取得し、`ml.DeviceInfo` 構造体に格納して返します。
* 関数名: `GetDevicesFromRunner`
* ファイル名: `ml/device.go`
* 確認された正確な動作: サブプロセスとして起動したランナー(例: `ollamarunner`)のHTTPエンドポイント(`/info`)にリクエストを送り、JSON形式で返されるデバイス情報(`ml.DeviceInfo`のリスト)をデコードして取得します。
* 関数名: `buildLayout`
* ファイル名: `llm/server.go` (行番号 939-1000付近)
* 確認された正確な動作: 取得したGPUリストを空きVRAM容量の降順でソートします。各レイヤーに必要なメモリ量(WeightsとCacheの合計)を計算し、GPU側から取得した `FreeMemory` から、MinimumMemoryやオーバーヘッド(`Graph`サイズなど)などの予約済みメモリ(`reserved`)を差し引いた上で、実際のオフロード計算(`assignLayers`)に渡します。
* 関数名: `assignLayers`
* ファイル名: `llm/server.go` (行番号 1064-1104付近)
* 確認された正確な動作: 指定されたGPUリストを使ってレイヤーをGPUに割り当てます。できるだけ少ない数のGPUにパッキングするためにループを回し、内部で `findBestFit` を呼び出します。一部のレイヤーがどうしても乗らない場合は、出力層から順にオフロード対象から除外する(`layers[:len(layers)-1]`)試みを行います。
* 関数名: `findBestFit`
* ファイル名: `llm/server.go` (行番号 1106-1137付近)
* 確認された正確な動作: 容量係数(`capacity`)を0〜1の間で二分探索(Binary Search)し、指定された条件を満たしつつ全GPUのVRAMに最も効率良く収まる係数を見つけます。ユーザーが強制的にオフロード数(NumGPU)を指定している場合は、`high = 1000` と設定して擬似的にVRAMを無限とみなし、強制的に割り当てを試みます。
* 関数名: `greedyFit`
* ファイル名: `llm/server.go` (行番号 1139-1160付近)
* 確認された正確な動作: 決定された容量係数(`capacity`)を元に、後ろのレイヤー(出力層側)からインデックスを逆順にたどり、対象GPUの `FreeMemory * capacity` (`freeSpace`)に収まる限りレイヤーを順番に詰め込みます。空き容量が足りなくなれば次のGPU(配列の前の要素)へ移行します。
* 関数名: `verifyLayout`
* ファイル名: `llm/server.go` (行番号 1001-1062付近)
* 確認された正確な動作: オフロードのレイアウトが決定された後、必要なCPUメモリがシステムのFreeMemoryを超過していないかチェックします。Darwin(macOS)の場合、計算されたVRAMの合計がTotalMemoryを超えるとシステムハングアップを防ぐため、強制的にNumGPUを0(オフロードなし)にリセットします。
**2. Data Flow Analysis(データフロー分析)**
メモリ計算とオフロード決定に関わる重要な変数は以下のように伝播・計算されます。
1. **VRAMの取得元**: `ml/backend/ggml/ggml.go` 内の `BackendDevices` にて、ggml側の関数 `C.ggml_backend_dev_memory` によってGPUハードウェアの `memory_free` が取得され、`DeviceInfo.FreeMemory` に格納されます。
2. **ランナーからの伝達**: ランナープロセスが取得した `DeviceInfo` のリストは、`/info` エンドポイントを通じて親プロセス(Ollamaサーバ)の `GetDevicesFromRunner` へJSONで渡されます。
3. **VRAMの実質容量の計算**: `llm/server.go` の `buildLayout` にて、各GPUの `FreeMemory` から、オーバーヘッドやグラフサイズ(`reserved := uint64(float32(gl[i].FreeMemory)*backoff) + gl[i].MinimumMemory() + envconfig.GpuOverhead() + memory.GPUs[j].Graph`)が差し引かれます。これが実質的なオフロード用の空き容量となります。
4. **レイヤーの必要メモリ計算**: `layers` 配列に、各レイヤーごとの `Weights`(重み)と `Cache`(KVキャッシュ)のメモリ使用量の合計が格納されます。
5. **オフロード割り当て**: `assignLayers` -> `findBestFit` -> `greedyFit` の順でデータが流れます。`findBestFit` は `capacity`(初期値0〜1)を二分探索で調整し、`greedyFit` において `freeSpace = FreeMemory * capacity` として計算します。`greedyFit` は `layers` の最後尾から逆順にループし、`layers[i] <= freeSpace` の条件を満たせばGPUに割り当て、`freeSpace -= layers[i]` で残量を更新しながら分割を決定します。
**3. Semantic Properties with Explicit Evidence(明確な証拠に基づくコードの性質)**
* **主張1(VRAMの計算方法)**:
VRAMの空き容量は、ggmlのバックエンドを通じてC言語のAPIから直接取得されます。その後、Ollama本体でモデルを割り当てる前に、バックオフ比率、GPUの最低必須メモリ、環境変数のGPUオーバーヘッド、およびコンピュートグラフのメモリを合算した「予約済みメモリ」を差し引いて、実際にレイヤー割り当てに使用できる安全なVRAM容量が計算されています。
* **証拠1(該当するコード行やシステムコールの詳細)**:
`ml/backend/ggml/ggml.go` におけるC関数呼び出し:
```go
C.ggml_backend_dev_memory(dev, &props.memory_free, &props.memory_total)
info.FreeMemory = (uint64)(props.memory_free)
```
`llm/server.go` (`buildLayout` 関数) におけるVRAMの削減処理:
```go
reserved := uint64(float32(gl[i].FreeMemory)*backoff) + gl[i].MinimumMemory() + envconfig.GpuOverhead() + memory.GPUs[j].Graph
if gl[i].FreeMemory > reserved {
gl[i].FreeMemory -= reserved
} else {
gl[i].FreeMemory = 0
}
```
* **主張2(レイヤーの分割・オフロード決定ロジック)**:
レイヤーの分割は、モデルの出力層(後ろのレイヤー)から逆順に行われます。また、複数のGPUにまたがる場合は「二分探索」と「貪欲法(Greedy)」を組み合わせて最適な容量係数を算出し、なるべく少数のGPUで済むように(フラグメンテーションを防ぐように)各デバイスに詰め込めるだけ詰め込むロジックになっています。
* **証拠2(該当する計算式や条件分岐の詳細)**:
`llm/server.go` (`greedyFit` 関数) の逆順ループと貪欲なパッキング:
```go
freeSpace := uint64(float32(gpus[device].FreeMemory) * capacity)
for i := len(layers) - 1; i >= 0; i-- {
// ... (中略) ...
for {
if layers[i] <= freeSpace {
gpuLayers[0].Layers = append([]int{i}, gpuLayers[0].Layers...)
freeSpace -= layers[i]
break
}
device-- // 現在のGPUに収まらない場合は前のGPUへ移動
// ...
```
`llm/server.go` (`findBestFit` 関数) の二分探索:
```go
for high-low > 1e-6 {
mid := (low + high) / 2
assignments := greedyFit(layers, gl, mid, requestedLayers)
// 最大の割り当て数となるまでcapacityを調整
```
**4. Alternative Hypothesis Check(代替仮説の検証)**
このレイヤー決定アルゴリズムには、いくつかの明確なエッジケース(代替挙動)がコード上に実装されています。
* **強制的なレイヤー数指定が行われた場合 (`requestedLayers >= 0`)**:
ユーザーパラメータ(`NumGPU` 等)で明示的にオフロードするレイヤー数が指定されている場合、VRAMが足りないように見えても強制的に割り当てる必要があります。そのため、`findBestFit` の二分探索で上限値となる `high` 変数が通常の `1` から `1000` に跳ね上げられ(`forceRequest == true` の場合)、擬似的に「ほぼ無限のVRAMがある」状態として計算されます。これにより、OOM(Out Of Memory)のリスクを承知で指定通りのレイヤーオフロードが試行されます。
* **macOS(Darwin)環境における全VRAM超過リスク**:
MacなどのUnified Memory環境では、VRAMとシステムメモリが共有されています。`verifyLayout` のロジックにおいて、`runtime.GOOS == "darwin"` の条件分岐が存在し、計算されたオフロードの `vramSize` が `systemInfo.TotalMemory` を超える場合、システム全体がフリーズ(ロックアップ)するのを防ぐために、部分的なオフロードも含めてすべて無効化され(`s.options.NumGPU = 0`)、CPUのみで動作するようフォールバックされます。
**5. Final Conclusion(最終的な結論)**
検証済みのコードから得られた証拠に基づき、モデルロード時のVRAM計算およびレイヤー分割(オフロード)メカニズムは以下の通り結論付けられます。
**VRAMの空き容量計算について:**
Ollamaは直接ハードウェアを叩くのではなく、バックグラウンドで起動したランナー(ggmlエンジン)を通じてC API(`C.ggml_backend_dev_memory`)経由で実際のGPUのTotal/Free VRAMを取得しています(Macの場合は`host_statistics64`を用いて算出)。
得られた生の空きVRAM容量はそのまま使われるわけではありません。モデルのコンピュートグラフ(`Graph`)サイズ、GPU固有の最低確保容量(`MinimumMemory`)、環境変数のオーバーヘッド、および安全係数(`backoff`)を合計した「予約分」を算出し、生VRAMから差し引くことで「安全にオフロード可能な実質VRAM容量」を導き出しています。
**レイヤー分割・オフロードの決定ロジックについて:**
各GPUの利用可能VRAMと、各レイヤーごとの「重み(Weights)+KVキャッシュ(Cache)」のサイズを突き合わせ、以下のアルゴリズムで分割します。
1. **最小GPU数のパッキング**: 極力少ないGPUの枚数に全レイヤーを収めるため、使用するGPUを1台から徐々に増やしていくアプローチを取ります。
2. **二分探索と貪欲法(Greedy)**: 複数のGPUを並行利用する際、VRAM容量に対してどれくらいの割合(Capacity: 0.0〜1.0)までなら均等かつ無駄なくパッキングできるかを、二分探索で探し出します。レイヤーの割り当て自体は、モデルの後ろのレイヤー(出力層側)からインデックスを逆順にたどり、対象GPUの「利用可能VRAM × Capacity」に収まる限り貪欲に詰め込みます。収まらなくなったら次のGPUへと移ります。
3. **安全機構(フォールバック)**: これらの計算を経て、VRAMに収まり切らないレイヤーはCPUで計算(一部オフロード)されることになります。また、macOS環境などでVRAMの割り当て要求がシステムの物理メモリ総量を超えると判定された場合は、OSのハングアップを防ぐためにオフロードが完全にキャンセルされるフェールセーフ機構が働いています。3-3. 比較のまとめ
2つのアプローチを比較すると、その違いは明確です。
- 一般的な推論: 「関数名や文脈からの推測」に依存しやすく、回答は読みやすいものの、証拠が不十分で信頼性に欠ける。
- 準形式的推論: 「コードパスの追跡と明示的な証拠」に基づくため、推測が排除され、プラットフォーム固有の制約やエッジケースの発見率が飛躍的に向上する。
以上のように、準形式的推論のプロンプト設計は、エージェントを「知ったかぶりをするアシスタント」から「事実ベースで徹底的に調査する厳格なコードレビュアー」へと変貌させる力を持っています。
4. 実務における3つの適用タスクと効果
準形式的推論は、コードを実行せずに意味(セマンティクス)を正確に理解するタスクにおいて、通常の推論手法を大きく上回る精度を示しています。具体的な適用例として、以下の3つのタスクにおける効果をご紹介します。
- パッチの等価性検証(
Patch Equivalence Verification):
実行環境でのテストを実施せずに、2つのパッチが同じ結果をもたらすかを検証するタスクにおいて、Opus-4.5モデルを使用した場合、93%という極めて高い精度で判定に成功しました。これにより、テスト用のサンドボックス環境を都度構築する手間が省けるため、強化学習(RL)パイプラインにおける報酬モデルの評価コストを大幅に削減できる可能性があります。 - バグの特定(
Fault Localization):
テストの失敗情報のみを頼りに、巨大なリポジトリからバグの原因行を特定するタスクです。エージェントに構造化された仮説検証と実行パスの徹底的な追跡を義務付けることで、上位5つの予測内に正解が含まれる精度(Top-5精度)が、標準的な推論と比べて5〜12パーセントポイント向上しました。 - コードに関する質問応答(
Code QA):
複雑な仕様やコードの挙動に関する質問に回答するタスクです。エージェントに対して、データフローや関数トレース(呼び出し履歴)を明確な証拠として文書化させることで、関数名などに依存した推測による誤答を防ぎました。結果として、標準的な手法から回答精度が約9パーセントポイント向上しています。
このように、プロンプトの設計に構造化された制約を持たせるだけで、様々なコード解析タスクの信頼性を実用レベルにまで引き上げることが可能です。
おわりに
「準形式的推論(Semi-formal Reasoning)」は、テスト環境の構築やサンドボックスでの実行に頼ることなく、LLMによる静的なコード解析の精度と信頼性を高める非常に実用的なアプローチです。
従来の静的解析(Static Analysis)ツールのように、言語固有の専門アルゴリズムを実装する必要はありません。タスクに合わせた構造化プロンプトを用意するだけで、様々なプログラミング言語や複雑なフレームワークに対して柔軟に適用できる点が大きな強みです。
このように、プロンプトの段階で「論理的な証拠収集」の制約を組み込む手法は、今後のソフトウェア開発に大きな影響を与えます。自動化されたコードレビュー(Code Review)の高度化や、AIコーディングエージェントの検証プロセスを効率よく進める上で、間違いなく重要な役割を果たしていくでしょう。
More Information
- arXiv:2603.01896, Shubham Ugare, Satish Chandra, 「Agentic Code Reasoning」, https://arxiv.org/abs/2603.01896
関連記事

ベイジアンネットワーク入門:pgmpyによる因果探索と因果推論の実践
近年の機械学習(ML)モデルは、ビッグデータ解析において非常に高い予測精度を達成しています。しかし、その意思決定に至るプロセスが不透明な「ブラックボックス」となってしまう課題が指摘されています。データから相関関係を発見す […]

Intent Formalization: AI時代の信頼できる開発
近年、「Vibe coding」に代表される、自然言語で要件を伝えてAIが生成したコードをそのまま受け入れる開発スタイルが普及しつつあります。AIコーディングツールは高速でコードを出力します。ですが、ここで大きな問題とな […]

LitServe: 機械学習モデルの効率的なデプロイ
機械学習モデルは、FlaskやFlastAPIなどのWebフレームワークを使用して、WebAPIとしてデプロイされることが一般的です。これらのフレームワークは、WebAPIを構築するための便利な機能が豊富に含まれています […]