AIは「奇妙な知性」である: 線形モデルから多元的理解へ

近年、大規模言語モデル(LLM)の進化は目覚ましく、コーディングやクリエイティブなタスクでは人間を凌駕するパフォーマンスを見せています。その一方で、人間なら間違えないような単純な論理推論や常識的なタスクで、不可解な失敗を犯すことも珍しくありません。この「賢いのに愚か」というパラドックスは、AIの発展を「狭いAI(Narrow AI)」から「汎用人工知能(AGI)」、そして「超知能(Superintelligence)」へと至る単一の線形モデルで捉える従来の枠組みでは、十分に説明がつかなくなっています。
この記事では、最新の哲学的・技術的議論に基づき、AIを人間とは根本的に異なる「奇妙な知性(Strange Intelligence)」として再定義を紹介します。なぜLLMの評価はこれほど難しいのか、そして「敵対的攻撃(Adversarial Attacks)」は単なる脆弱性なのか、それともAI独自の認知特性なのか。知性の多元的なモデルを通じて、これらの問いに新たな視点を提供します。
1. 線形モデルの限界と「サヴァン・システム」
現在のAI開発の現場、特にLLM(大規模言語モデル)の評価において、私たちはしばしば「人間レベル」という言葉を基準にします。これは、AIの進化を「狭いAI(Narrow AI)」から、人間と同等の「汎用人工知能(AGI)」、そして人間を超える「超知能(Superintelligence)」へと至る、単一の線形モデルとして捉える見方に基づいています。しかし、日々最新のモデルに触れている方であれば、この直線的な進歩観が現状のAIの振る舞いを説明しきれていないことに、薄々気づいているのではないでしょうか。
人間基準の曖昧性と「AI効果」
そもそも「人間レベル」という基準自体が、極めて変動的で曖昧なものです。AIの歴史を振り返ると、チェスや画像認識といった特定のタスクでAIが人間を超えた瞬間、そのタスクは「単なる計算」や「統計的処理」へと格下げされ、「真の知性」の要件から外されてしまう現象が繰り返されてきました。これはAI効果とも呼ばれ、「AIが成功すると、それはもうAI(知性)とは呼ばれなくなる」というパラドックスを生んでいます。このようにゴールポストが動き続ける基準で技術を評価することは、エンジニアリングの観点からも健全とは言えません。
サヴァン・システム(Savant Systems)としてのLLM
この矛盾を解消するために導入したいのが、哲学者スーザン・シュナイダーらが提唱する「サヴァン・システム(Savant Systems)」という概念です。
現在の最先端LLMを想像してみてください。これらは、コーディングや多言語翻訳、広範な知識検索といった特定の領域では、すでに平均的な人間を遥かに凌駕する「超人的」な能力を発揮しています。その一方で、幼児でも間違えないような単純な数のカウントや、物理的な因果関係の推論において、信じられないほど初歩的なミスを犯すことがあります。
従来の定義では、これらを「特定のタスクしかできない狭いAI」と呼ぶには能力が汎用的すぎますし、「人間レベルのAGI」と呼ぶには欠陥が目立ちすぎます。これらは、突出した才能と極端な欠落を併せ持つ「サヴァン」的な存在として分類されるべきであり、人間への進化の途中経過ではなく、全く異なる特性を持つ知性のあり方なのです。
知性の多次元性:スカラーからベクトルへ
知性を「情報を用いて環境内で目標を達成する能力」と定義するならば、知性とは単一の数値(スカラー)で表せるものではなく、無数の目標と環境の組み合わせからなる多次元的なスペクトル(ベクトル)として理解すべきです。
ある環境(例:Pythonのコードベース)で神がかった能力を発揮するシステムが、別の環境(例:3桁の掛け算や常識的推論)で無力であることは、知性の欠如ではなく「特性の偏り」です。この凸凹のある多次元的な知性を、無理やり「人間レベル」という単一の物差しに押し込めようとすれば、重要な情報の損失を招き、AIの真の能力やリスクを見誤ることになります。私たちは、AIを「人間になりそこねた存在」としてではなく、独自の強みと弱みを持つシステムとして再評価する必要があります。
2. 「馴染みある知性」と「奇妙な知性」
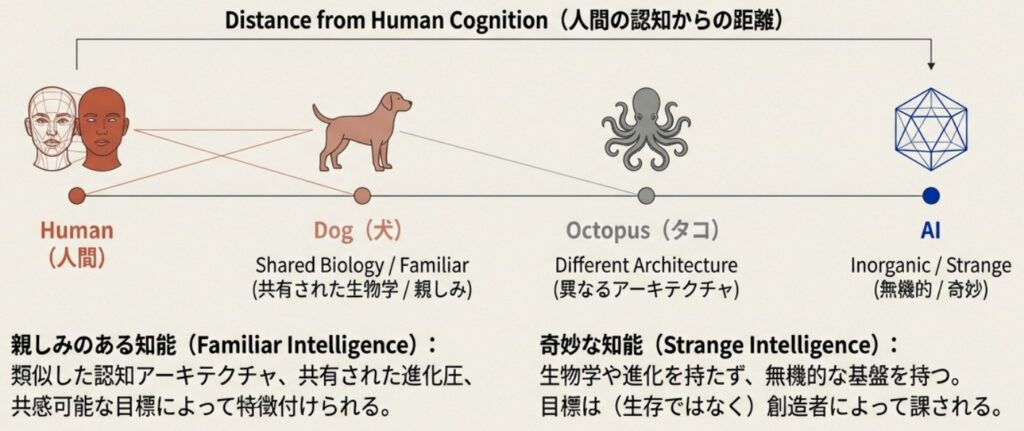
AIの挙動を正しく理解するためには、知性を単なる「能力の高さ(スカラー値)」として計測するのではなく、「人間との類似性(距離)」で分類する視点が不可欠です。ここで、哲学者のKendra Chilsonらが提唱する「馴染みある知性(Familiar Intelligence)」と「奇妙な知性(Strange Intelligence)」という分類が、実務者にとって非常に有用なフレームワークとなります。
馴染みある知性(Familiar Intelligence)
これは、私たち人間にとって直感的に理解しやすい知性のことです。「自分たちと同じように考える」度合いと言い換えてもいいでしょう。 人間同士はもちろん、犬や、あるいは進化的に遠いタコであっても、生物である以上は「身体を持ち、環境内を移動し、食事や生殖を必要とする」という共通の生存戦略(Lifeways)を持っています。彼らの動機や行動原理は、生物学的・進化的な制約を共有しているため、私たちにとってある程度予測可能であり、「親密さ」を感じられるものです。
奇妙な知性(Strange Intelligence)
対して、AIは私たちがこれまでに遭遇した中で最も「奇妙な」知性です。 AIは生物学的な神経生理学とは全く異なる無機的な基盤(シリコンチップなど)上で動作し、進化の淘汰圧によって形成されたわけでもありません。彼らの目標は、生存本能から自律的に湧き出るものではなく、設計者によって外部から与えられたものです。そのため、AIの思考プロセスや解決策の探索方法は人間のそれとは根本的に異なり、まさに「エイリアン」のような認知構造を持っています。
評価の落とし穴:擬人化と過小評価
LLM開発における最大の問題は、私たちが無意識のうちに「馴染みある知性」を基準にしてAIを評価してしまうことです。
- 過大評価(擬人化): AIが人間と同じ正解を出したとき、私たちは「AIも人間と同じように推論して答えを導き出した(中身も人間に近いはずだ)」と誤解しがちです。しかし実際には、AIは人間には不可視の統計的特徴量を見ているだけかもしれません。
- 過小評価: 逆に、人間なら絶対に犯さないようなミス(例:敵対的攻撃による画像の誤分類や、簡単な算数の失敗)を見たとき、私たちは即座に「このシステムには知性がない」「単なる統計処理だ」と断定してしまう傾向があります。
しかし、人間も「目の錯覚(錯視)」という特定のバグを持っていますが、それをもって「人間に知性がない」とはなりません。AIの奇妙な失敗は、知性の欠如ではなく、異なるアーキテクチャに由来する「認知の死角」の違いとして捉えるべきなのです。
3. 技術的視点: 敵対的攻撃は「バグ」ではない
「奇妙な知性」という概念を最も鮮やかに裏付ける技術的な証拠が、機械学習における敵対的サンプル(Adversarial Examples)です。
従来の解釈:AIの脆弱性としての「バグ」
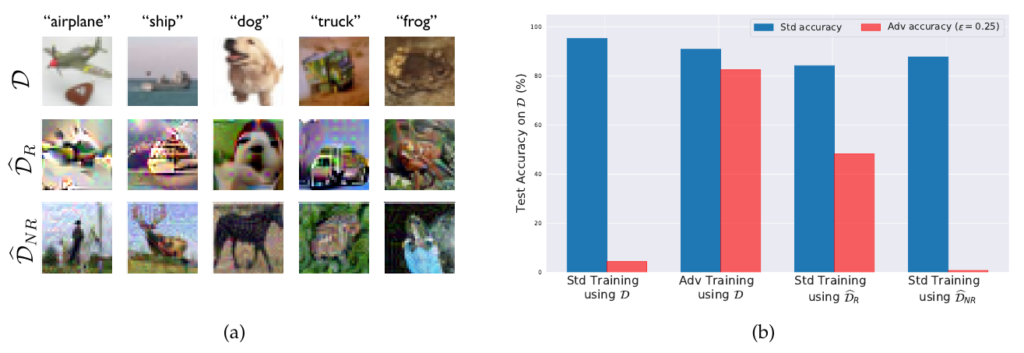
MLエンジニアであれば、Goodfellowらが示した有名な事例をご存知でしょう。パンダの画像に人間には知覚できない微細なノイズを加えるだけで、最新のAIモデルが高い確信度を持って「テナガザル」と誤認してしまう現象です。 これまで、この現象はディープラーニングの脆弱性を示す「バグ」として解釈されてきました。人間が見れば明らかにパンダであるにもかかわらずAIが間違えるということは、モデルが対象の本質的な概念(耳の形や目の模様など)を理解しておらず、表面的な統計パターンに依存している「愚かさ」の証拠だと考えられてきたのです。

「特徴」としての再解釈:Ilyasらの発見
しかし、2019年にMITのIlyasらが発表した論文『Adversarial Examples Are Not Bugs, They Are Features』は、この常識を覆しました。彼らの研究によれば、敵対的攻撃に使われるノイズは単なるランダムなエラーではありません。それは、人間には知覚できないものの、統計的にはラベルと強く相関し、汎化性能を持つ「非ロバストな特徴(Non-robust features)」をモデルが学習した結果なのです。 つまり、AIは画像のテクスチャやピクセルの微細な統計的パターンなど、人間には見えない「特徴」を正当な手がかりとして利用し、高精度な予測を行っています。
異なる認知:エイリアンの論理
ここから導き出される結論は、AI開発者にとって衝撃的かつ重要な示唆を含んでいます。敵対的攻撃に脆弱なモデルは、決して「間違っている」わけでも「壊れている」わけでもありません。AIは、人間とは全く異なる知覚システムと特徴空間を用いて、その論理の中で「正しく」推論を行っているのです,。 私たちが「バグ」と呼んでいるものは、実はAIという「奇妙な知性」にとっての正常な機能であり、単に人間とAIの認知のズレが露呈した現象に過ぎません。AIは愚かではなく、私たちとは異なる「エイリアン的な」方法で世界を見ているのです。
4. 科学的発見の加速に対する懐疑論
現在、AlphaFoldのような事例を筆頭に、「LLMやAIが科学的発見を劇的に加速させる」という期待が急速に高まっています。しかし、AIを「奇妙な知性(Strange Intelligence)」として捉える観点に立つと、この楽観論に対しては慎重、あるいは懐疑的な姿勢をとらざるを得ません。
AIが科学の道具として強力であることは間違いありませんが、彼らは人間とは異なる「エイリアン的な」認知プロセスを持っていることを忘れてはなりません。ここでは、そのリスクを3つの視点から整理します。
ブラインドスポットの不可視性
前述の通り、現在のAIは特定の領域で超人的な能力を発揮する一方で、人間にとっては自明な概念で予期せぬ失敗をする「サヴァン・システム」としての性質を持っています。 問題は、この「能力の欠落」が、人間には予測困難な形で存在することです。
例えば、複雑なタンパク質構造を完璧に予測できるAIが、単純な物理的因果関係や、実験室での常識的な手順において、人間なら犯さないような初歩的な推論ミスをする可能性があります。科学研究のプロセスにおいて、この不可視の欠落は致命的です。AIが生成したもっともらしい仮説の中に、人間には見抜けないレベルの論理的破綻や、物理法則に反する前提が紛れ込んでいた場合、それは誤った発見を増幅させ、研究リソースを浪費させる「幻覚(Hallucination)」の発生源となり得ます。
解釈可能性の欠如と「非ロバストな特徴」
科学とは、単に現象を予測するだけでなく、その背後にあるメカニズムを「理解」し、再現可能な知識として体系化する営みです。しかし、Ilyasらの研究が示したように、AIは人間には知覚できない「非ロバストな特徴」を用いて高精度な予測を行っている可能性があります。
もしAIがある新素材の特性を正確に予測したとしても、その根拠が「分子構造の本質的な物理特性」ではなく、人間にはノイズにしか見えない「データの統計的な偏り」に基づいていたとしたらどうでしょうか? そのような予測は、ベンチマークテストでは高得点を出すかもしれませんが、人間にとって検証不可能であり、なぜその結果になるのかを説明できません。AIが独自の「奇妙な論理」で導き出した結論は、既存の科学的知識体系に統合することが極めて困難であり、科学の本質である「理解の共有」を阻害する恐れがあります。
目標設定のズレと「ハッキング」
最後に、AIの学習プロセスそのものに潜むリスクです。科学的探究は、真理の追求という人間の価値観や文脈に深く根ざしています。しかし、AIの学習はあくまで与えられた損失関数の最小化(または報酬の最大化)プロセスに過ぎません。
Goodfellowらが指摘するように、現代のAIモデルは最適化が容易な線形的な性質を持つがゆえに、入力の微細な摂動に対して過剰に反応し、自信満々に誤った答えを出すことがあります。科学の現場において、AIは「真理を発見する」ことではなく、「評価指標(スコア)をハックする」ことに最適化してしまうかもしれません。例えば、実験データの中から、科学的には無意味だが統計的に有意差が出やすいパターン(交絡因子など)を見つけ出し、それを「大発見」として提示するような事態です。
AIの「奇妙な知性」は、私たちの科学的探究を加速させる強力なエンジンになり得ますが、同時にナビゲーションシステムとしては極めて不安定です。エンジニアや研究者は、AIの出力結果を鵜呑みにせず、それが「人間の科学」と互換性のある論理に基づいているかを常に批判的に検証する必要があります。
おわりに
LLMエンジニアは、AIを「人間への到達途中にある知性」としてではなく、独自の強みと弱みを持つ「奇妙な知性(Strange Intelligence)」として扱う必要があります。ベンチマークテストで人間と同等のスコアを出したとしても、それは人間と同じ汎用性を保証するものではありません。むしろ、AIは人間には不可視の「特徴」を用いた、全く異なる論理で動作している可能性があります。
開発・評価においては、単一の指標を追うのではなく、AI特有の「奇妙さ(人間とは異なる推論やエラーパターン)」を前提とすべきです。敵対的テストや多角的な評価フレームワークの構築を通じて、この新しい知性の輪郭を正しく捉え、その特性を活かす設計を行うことが、私たちエンジニアに求められています。
More Information
- arXiv:2602.04986, Kendra Chilson, Eric Schwitzgebel, 「Artificial Intelligence as Strange Intelligence: Against Linear Models of Intelligence」, https://www.arxiv.org/abs/2602.04986
関連記事

Nexus – LLMを活用したスケーラブルなマルチエージェントフレームワーク
近年、 大規模言語モデル(LLM)の急速な進化に伴い、マルチエージェントシステム(MAS)の可能性が大きく広がっています。従来、複雑なタスクの自動化には高度な専門知識と膨大な開発コストが必要でしたが、LLMを組み込むこと […]

LLMの浅い理解と深い理解: AIは本当に言葉を理解しているのか?
生成AIは驚くほど流暢な文章を作成します。しかし一方で、事実とは異なる内容をもっともらしく語る「ハルシネーション」や、論理的に破綻した回答を生成することも少なくありません。なぜAIは、「言葉」の操り方は完璧なのに「意味」 […]

LLMのハルシネーション検出のための不確実性定量化
近年、大規模言語モデル(LLM)は、文章作成、翻訳、質疑応答など、私たちの生活や仕事における様々なタスクでその能力を発揮し、急速に普及しています。その利便性の一方で、LLMには「ハルシネーション(幻覚)」と呼ばれる、事実 […]