Agent-as-a-Judge: 次世代の自律的評価システムに向けたロードマップ
AI評価の分野では、LLM自身の高度な理解力を活用して他のモデルを評価する「LLM-as-a-Judge」が広く普及しています。しかし、AIが生成する回答が高度化し、専門領域における多段階のタスクへと進化するにつれ、単一の推論ステップで評価を完結させる従来の手法は限界を迎えつつあります。
従来の LLM-as-a-Judge は、文章の長さなどのバイアスに左右されやすく、また外部の世界と対話できない「受動的な観察者」であるため、事実関係を検証せずに「もっともらしい」評価を下してしまう課題がありました。こうした限界を打破するために登場したのが、「Agent-as-a-Judge」という新たなパラダイムです。
これは、自律的なエージェントが計画(Planning)・ツール利用(Tool Integration)・記憶(Memory)・マルチエージェント連携(Multi-Agent Collaboration)を駆使し、より堅牢で検証可能な評価を実現する仕組みです。本記事では、この次世代評価システムの全貌と、将来に向けたロードマップを詳しく解説します。
1. LLM-as-a-Judgeが直面している3つの技術的限界
現在、AI評価のデファクトスタンダードとなっている「LLM-as-a-Judge」ですが、生成AIがより複雑で専門的なタスクをこなすようになるにつれ、実務上の課題が浮き彫りになっています。主要な限界は、大きく以下の3点に集約されます。
パラメトリック・バイアス (Parametric Bias)
LLM-as-a-Judge は、中立性を損なう固有の偏向(バイアス)を抱えています。代表的な例として、内容の質に関わらず文章が長い回答を高く評価してしまう「冗長性バイアス (Verbosity Bias)」や、自分自身の出力パターンに近い回答を好む傾向が挙げられます。こうしたバイアスは、モデル間の公平な比較を困難にする要因となります。
「もっともらしい嘘」の検出しにくさ
従来の LLM-as-a-Judge は、外部の世界や環境と対話できない受動的な「観察者 (Passive Observer)」に過ぎません。そのため、回答が「正しく見えるか」という言語的なパターンのみに基づいて評価を下してしまい、実際の事実関係や計算結果を検証しません。その結果、専門的なドメインにおいて、もっともらしい嘘である「ハルシネーション (Hallucination)」を見逃し、誤った合格点を与えてしまうリスクがあります。
認知的過負荷 (Cognitive Overload)
高度な評価タスクでは、正確性や論理性など、様々な評価基準を同時に適用する必要があります。しかし、これらを一度の推論ステップで全て処理しようとすると、LLMは「認知的過負荷」に陥ります。その結果、細かなニュアンスを反映できない、大まかで精度の低いスコアしか算出できないという限界が生じています。
これらの課題は、単一のモデルに評価を丸投げする従来の手法が、限界を迎えつつあることを示唆しています。
2. Agent-as-a-Judgeの進化段階とアーキテクチャ
エージェント型評価システムへの移行は、単一のモデルによる推論から、分散化された意思決定と実行ベースの検証へとアーキテクチャが根本から変化することを意味します。この進化の過程は自律性と適応性のレベルに応じて、様々な手法を以下の3段階の発展途上モデルとして整理できます。
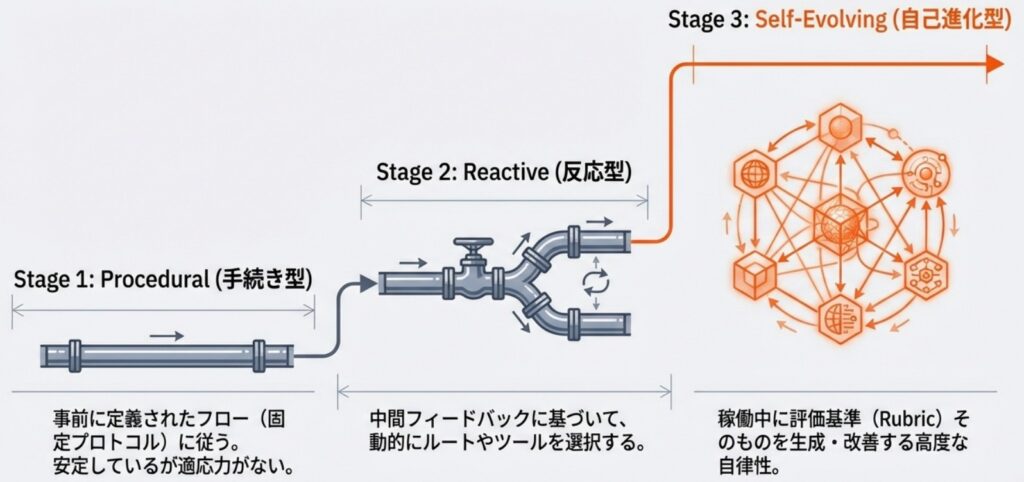
① 手続き型 (Procedural Agent-as-a-Judge)
この段階では、単一の推論プロセスを、あらかじめ定義されたワークフローや固定されたサブエージェント間の構造化された議論へと分解します。
- 特徴: 複数のエージェントが「検察官」や「弁護士」などの役割を持って議論したり、タスクを分割して評価を進めたりします。
- 限界: 決定ルールが事前に固定されているため、想定外の評価シナリオに適応する能力には欠けています。
➁ 反応型 (Reactive Agent-as-a-Judge)
中間的なフィードバックや実行結果に基づき、動的に評価プロセスを調整できる段階です。
- 特徴: 実行パスを動的にルーティングしたり、必要に応じて外部ツールやサブエージェントを呼び出したりします。
- 利点: 評価対象の回答内容に応じて、より適切な検証手段をその場で選択することが可能です。
③ 自己進化型 (Self-Evolving Agent-as-a-Judge)
最も高度な段階であり、評価システム自体が動作中に自身の構成要素を洗練させていく能力を持ちます。
- 特徴: 評価基準(ルーブリック)を状況に応じて動的に生成・洗練し、過去の経験を「メモリ(Memory)」として蓄積して自身の評価能力を自律的に向上させます。
- 展望: 固定されたプロトコルを超え、評価対象のモデルと共に進化し続ける「真に自律的な評価者」としての役割を担います。
このように、Agent-as-a-Judgeは単なる「評価の自動化」に留まらず、状況を認識して自律的に判断を下す、より高度な知的システムへと進化を続けています。
3. Agent-as-a-Judgeのコア機能
Agent-as-a-Judgeの実装において、従来の LLM-as-a-Judge と一線を画すのは、評価を単なる「推論」ではなく「能動的なプロセス」として捉える点です。その中核は、以下の4つの機能に集約されます。
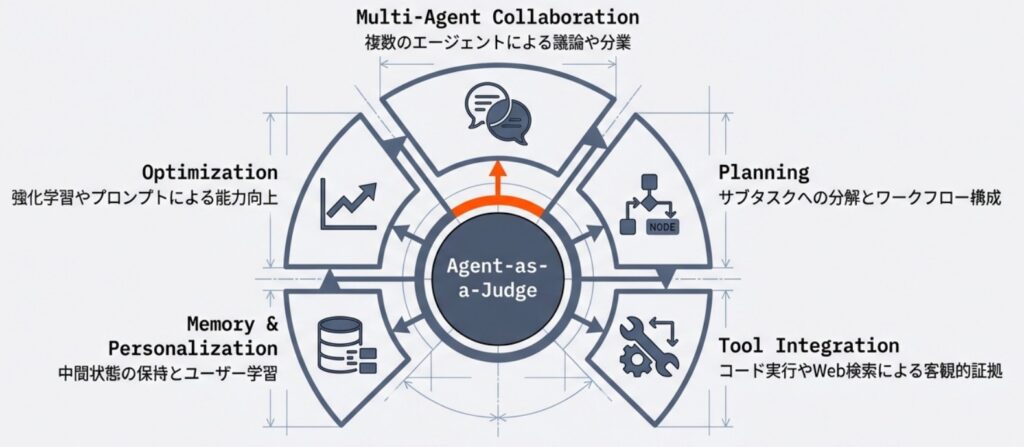
マルチエージェント・コラボレーション
複数のエージェントを連携させることで、評価の堅牢性を高めます。「集団的合意(水平的な議論)」では、異なる視点を持つエージェント同士が議論を交わすことで、個々のモデルが持つバイアスを相殺します。また、「タスク分解(垂直的な分担)」では、複雑な評価目標を専門的なサブタスクに切り分け、各エージェントが特定の役割を果たすことで、きめ細やかな評価を実現します。
動的プランニング
評価の目的を理解し、自律的に実行可能なステップへと分解します。固定された手順に従うだけでなく、評価の途中で得られた中間結果やフィードバックに基づき、様々な評価手順を動的に調整したり、戦略を柔軟に変更したりする能力を持っています。これにより、想定外の回答に対しても最適な検証経路を選択できます。
ツール統合による実証
外部環境と対話する能力は、Agent-as-a-Judgeの最も強力な武器です。コード実行、数式の定理証明、Web検索といったツールを駆使し、回答が「正しく見える」かではなく、「実際に正しいか」を客観的な証拠に基づいて実証します。これにより、言語的なパターンのみに頼った評価から脱却し、事実に基づいた検証が可能になります。
メモリとパーソナライゼーション
評価の過程で得られた中間状態や過去の履歴を「メモリ」として保持します。これにより、長い推論が必要なタスクでも評価の一貫性を維持できます。また、ユーザー固有の好みや過去の評価基準を長期的に記憶することで、個別のニーズに最適化されたパーソナライズ評価の提供も可能になります。
これらの機能が統合されることで、評価システムは「受動的な観察者」から、自ら考え、行動し、検証する「能動的なエージェント」へと進化を遂げます。
4. Agent-as-a-Judgeのユースケースと課題
Agent-as-a-Judgeは、単なるテキストの流暢さを評価する段階を超え、高度な専門知識や厳格な検証が求められる様々な領域で真価を発揮します。
活用シナリオ
- 数学的推論とコード生成: 回答が「正しく見えるか」ではなく、論理的に正しいかを検証します。エージェントが定理証明ツールやコード実行環境を自律的に利用し、実行結果に基づいた客観的な評価を実施します。これにより、長い推論過程における微妙なエラーも正確に特定可能です。
- プロフェッショナルドメイン:
- 法務: 検察官や弁護士の役割をエージェントに演じさせ、対立する議論を通じて結論の妥当性を評価する「法廷シミュレーション」が行われています。
- 医療: 放射線診断レポートの精緻なスコアリングや、複数の専門家視点での多角的な検証に活用されます。
- 金融: アナリストレポートの論理構造を抽出して評価したり、ハルシネーションによる投資リスクを監査したりする用途が期待されています。
- パーソナライズされた報酬モデル: 強化学習(RLHF)の報酬信号として活用されます。ユーザー固有の好みや過去のフィードバックを「メモリ」に蓄積することで、一人ひとりのニーズに最適化された評価が可能になります。
実装上の課題とトレードオフ
実務への導入に際しては、その高度な機能ゆえのコストとリスクを管理する必要があります。
- 計算コストと遅延 (Cost & Latency): エージェント間通信や多段階の推論、外部ツールの呼び出しを繰り返すため、従来の評価手法に比べてリソース消費と実行時間が増大します。特に、リアルタイムなフィードバックが求められる学習ループへの組み込みには、速度とのトレードオフが課題となります。
- 安全性とプライバシー (Safety & Privacy): ツールを通じて外部システムにアクセスするため、意図しない副作用やセキュリティ上の脆弱性を突かれるリスクがあります。また、メモリに蓄積された機密情報や個人情報をいかに保護するかという点も、医療や法務などの分野では極めて重要です。
これらの課題を乗り越え、評価対象のモデルと共に自律的に進化し続けるシステムの構築が、今後の大きな焦点となるでしょう。
おわりに
Agent-as-a-Judgeへの移行は、AI評価を単なる「静的なスコアリング」から、能動的な「動的検証プロセス」へと進化させるものです。単独のモデルでは難しかったバイアスの排除や事実確認が、エージェントの自律的な行動によって可能になります。
今後の展望として、強化学習(RL)を用いた評価能力の直接的な最適化や、人間とエージェントが協力して評価基準を磨き上げる「人間とエージェントの協調的なキャリブレーション(Human-Agent Collaborative Calibration)」が重要な研究・開発の方向性となります。
信頼できるAIシステムの構築にとって、この自律的評価フレームワークの理解と実装は、次世代のLLMアプリケーション開発における不可欠な要素となります。様々な技術が目まぐるしく進化する今、評価プロセスそのものを「エージェント」として再定義する時期にきているのかもしれません。
More Information
- arXiv:2601.05111, Runyang You et al., 「A Survey on Agent-as-a-Judge」, https://arxiv.org/abs/2601.05111
関連記事

Conversational Search入門: LLM時代の検索技術最前線
現代のデジタル社会において、検索エンジンは情報アクセスに不可欠な存在となっています。しかし、単一のキーワードや短いフレーズに依存する従来の検索では、ユーザーの複雑で曖昧な情報ニーズに十分に応えきれません。 近年、人工知能 […]

AIは「奇妙な知性」である: 線形モデルから多元的理解へ
近年、大規模言語モデル(LLM)の進化は目覚ましく、コーディングやクリエイティブなタスクでは人間を凌駕するパフォーマンスを見せています。その一方で、人間なら間違えないような単純な論理推論や常識的なタスクで、不可解な失敗を […]

Socratic Self-Refine: 問答的自己改善によるLLMの推論能力向上
大規模言語モデル(LLM)は、Chain-of-Thought(CoT)プロンプティングを用いることで、数学的な問題解決から複雑な論理推論に至るまで、目覚ましい推論能力を発揮しています。しかし、推論過程を明示するCoTは […]