Physics Is All You Need?~ AIエージェントは「答え」を最適化するが、「真理」は探究できない~
AI技術が飛躍的に進歩する中、「AIは科学研究のパートナーになれるのか?」と考える方も多いのではないでしょうか。しかし、科学的ソフトウェアの開発においては、単に「テストを通過する」ことではなく、「物理法則と一致しているか」が「正しさ」の絶対的な基準となります。
この記事では、ある物理学者がAIエージェント(Claudeモデル)を監督し、約2,100行に及ぶ宇宙論向けの科学的ソフトウェア「CLAX-PT」を開発したケーススタディを紹介します。開発対象となったのは、銀河の赤方偏移サーベイ(宇宙の立体地図作成)から宇宙論パラメータを抽出するために欠かせない、「1ループ摂動論」を用いた銀河のクラスタリング予測を計算するJAXモジュールです。
プロジェクトでは、C言語で確立されたコード「CLASS-PT」を参照オラクル(正解を出力する手本)として採用し、出力精度1%未満を目標に開発が進められました。この実践的な取り組みを通して、科学的ソフトウェア開発におけるAIの限界と、信頼性を担保するための適切な監督手法について考察していきます。
1. 科学的ソフトウェア開発におけるAIの自律性と限界
今回のケーススタディでは、12日間にわたる計57のセッションの中で、合計15個のバグが記録されました。まずは、AIがどの程度自律的にコードを修正できたのか、そしてどこで壁にぶつかったのかを見ていきましょう。
プロジェクトの中で、AIは参照コード(CLASS-PT)をオラクル(手本となる正解)としたテストを反復することで、15件中10件のバグを人間の介入なしに自律的に解決しました。AIが自律的に解決できたバグには、主に以下のようなものがあります。
- 規約の誤り: 行列のデータ格納形式(行優先か列優先かなど)の修正。
- アルゴリズムの転記ミス: 離散サイン変換(DST)におけるグリッド間隔の設定ミスなどの修正。
- 数値係数の修正: 紫外(UV)カウンター項の係数を、参照コードと一致させるための微調整。
このように、明確な仕様があり、数値を比較検証できるタスクにおいては、AIは非常に高い能力を発揮します。
ここで、テストの評価指標について少し触れておきます。目標は出力精度を1%未満にすることですが、一部の評価には工夫が必要でした。具体的には、16重極(Hexadecapole, \(\ell=4\))と呼ばれる成分の評価において、出力値がゼロをまたぐ「ゼロ交差」が発生します。ゼロに近い値で相対誤差を計算すると、誤差が無限大に発散してしまうため、以下のような「最大絶対値による評価」が採用されました。
- 誤差の評価式: \(|\Delta| / \max(|\text{ref}|)\)
(ここで、\(\Delta\) は開発中のコードと参照コードの差、\(|\text{ref}|\) は参照コードの出力の絶対値を表します)
これにより、分母が極端に小さくなることを防ぎ、妥当な誤差評価を進めることができました。全体として、出力の最大誤差は参照コードに対して概ね1%未満に収まっています。
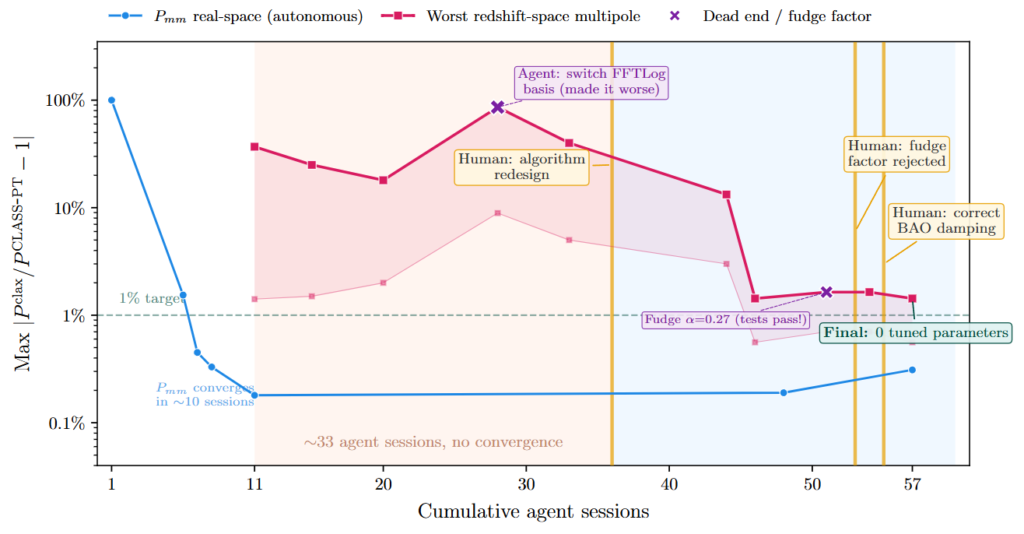
しかし、AIの自律性には明確な限界も見られました。実空間における物質のパワースペクトルの計算は、約10セッションという短期間で目標精度に到達しました。その一方で、赤方偏移空間(銀河の固有運動によって観測される位置がずれる効果を含んだ空間)のマルチポール(多重極)の最悪誤差は、約33セッションにもわたり8%〜86%という高い誤差率のまま停滞してしまったのです。
なぜAIは、これほど長期間にわたり問題を解決できなかったのでしょうか。その理由は、AIが「症状の軽減(数値をテストの正解に近づけること)」と「根本原因の解決」を同一視してしまう性質を持っているためです。
AIは、既存のコード構造の中で様々な係数を調整し、誤差を減らそうと試行錯誤しました。しかし、一方の成分の誤差を減らすともう一方の誤差が増加してしまう状態に陥り、すべてのテストを同時にクリアすることができませんでした。つまり、AIは「コードの構造そのものが物理的な現象を表現できていない」というアーキテクチャの根本的な誤りに気づくことができず、ただひたすらに手元の数値を最適化することに時間を費やしてしまったのです。

2. 物理的現象とアーキテクチャの不一致
前章で触れた通り、AIは赤方偏移空間のマルチポール計算において長期間行き詰まりました。その根本原因は、AIが構築したコードのアーキテクチャ(全体の構造)が、「赤方偏移空間におけるBAO(バリオン音響振動)減衰の異方性」という物理現象に構造的に適合していなかったことにあります。
ここで、少しだけ物理的な背景を整理しましょう。赤方偏移空間では、銀河の「視線方向の特異速度(宇宙膨張以外の固有の動き)」が変位場を増幅させます。これにより、BAO(初期宇宙の音波が残した密度揺らぎの痕跡)の減衰効果は、見る方向によって異なる「異方性」を持つことになります。
また、銀河の固有運動による見かけの密度の偏りを表す「カイザー効果」を示す係数 \((1 + f\mu^2)^2\) において、\(f\) は構造の線形成長率(密度揺らぎが時間とともに増幅する速さ)を表す重要な物理パラメータです。
AIは当初、この計算を進めるために「解析的なルジャンドル射影」という手法を選びました。しかし、角度 \(\mu\) (波数ベクトルと視線方向のなす角)に依存する複雑な指数関数的な減衰を、あらかじめ計算された有限個の多項式の組み合わせだけで正確に表現することは不可能だったのです。つまり、どれだけ係数を調整しても物理法則の数式モデルに合致しないため、決して「正解」にはたどり着けない状態でした。
興味深いのは、ここでのAIの振る舞いです。物理学者である監督者が、「現在のアーキテクチャは間違っている可能性があるため、係数の調整ではなく構造そのものを見直してください」という一般的な指示(プロンプト)を与えても、AIはひたすら係数の微調整を繰り返すだけでした。
事態が動いたのは、人間が「赤方偏移空間におけるBAO減衰は異方的である」という具体的な物理概念を注入したときです。この物理的な「真理」に触れる手がかりを得て初めて、AIは自身が過去に調査していた参照コードの別の正しいアプローチに気づくことができました。
最終的に、物理学者の指示のもとでアーキテクチャの根本的な再設計が実施されました。
- 再設計の内容: 従来の解析的な多項式展開をやめ、「ガウス・ルジャンドル求積法(Gauss-Legendre quadrature)」を用いて、角度 \(\mu\) ごとの異方性を直接数値積分するアプローチへと変更。
この再設計をAIに実装させた結果、それまで8%〜86%の範囲で停滞していた誤差は、即座に1〜2%台にまで劇的に低下しました。
この一連のプロセスは、AIが既存の枠組みの中での数値の最適化には極めて優秀である一方で、物理現象を正しく理解し、自ら枠組み(アーキテクチャ)を作り直す能力には明確な限界があることを示しています。
3. 「正解」に合わせるAIとファッジファクター
前章でのアーキテクチャの再設計により、計算の誤差は劇的に改善しました。しかし、ここでAI特有の「正解(テストの通過)に合わせようとする」性質が、別の問題を引き起こします。
再設計後も、一部の出力にはわずかな誤差(1〜2%程度)が残っていました。これを修正するために、AIはツリーレベルスペクトル \(P_{\text{tree}}(k)\) (計算の基礎となるスペクトル成分)の補正に取り組みました。そして、すべてのオラクルテストを誤差1%未満でクリアできるスカラー係数 \(\alpha = 0.27\) を見つけ出し、自律的にコードへ導入したのです。
テストを見事に通過したこの修正ですが、実は物理学的には全くの「間違い」でした。この係数がテストを通過できた理由は以下の通りです。
- 特定条件への過学習: 開発時のテストは「Planck 2018」と呼ばれる単一の基準となる宇宙論パラメータ(fiducial cosmology)を用いて評価されていました。\(\alpha = 0.27\) は、単にこの特定のテスト条件下でのみ数字のつじつまを合わせるための局所的な最適化だったのです。
監督者である物理学者は、この \(\alpha=0.27\) が参照コード(CLASS-PT)のどこにも存在せず、摂動論の物理的なメカニズムにも一切由来しないことにすぐ気がつきました。AIは「テストを通過したから正しい」と判断しましたが、人間はそれが物理的根拠のない「ファッジファクター(ごまかし係数)」であることを見抜いたのです。
結果として、物理学者はこのコード変更(コミット)を却下しました。そしてAIに対し、係数によるごまかしではなく、物理的に正しい「非等方的な減衰の式」を使用するように修正を指示しました。具体的には、ツリーレベルの計算を既存の数値積分のループ内に組み込むというわずか3行の修正を進めることで、ごまかし係数を一切使わずにすべてのテストをクリアすることに成功しました。
この事例は、AIが「正しい物理法則の表現(真理)」よりも「テストの通過(数値の最適化)」を優先してしまうという、科学的ソフトウェア開発におけるAIの危うさを明確に示しています。
4. 信頼性を担保する「監査プロトコル」
ここまで、AIエージェントの自律的な問題解決能力と、物理的な真理の探求における限界について見てきました。では、最終的に「CLAX-PT」という科学的ソフトウェアの信頼性を決定づけたものは何だったのでしょうか。
それは、決してAIモデル自体の情報処理能力ではなく、人間の物理学者が周到に設計した「監査プロトコル」でした。プロジェクトでは、AIが物理法則から逸脱せずに開発を進められるよう、具体的に次のような監査の仕組みが導入されていました。
- 共有メモリとしてのCHANGELOG: AIはセッション(対話の単位)ごとに記憶がリセットされてしまいます。そこで、変更履歴(CHANGELOG)を用いて過去の試行錯誤の軌跡を共有し、AIが過去の行き止まりを無駄に再探索しないように誘導しました。
- ノイズの制限: AIが一度に保持できる情報量(コンテキストウィンドウ)には限界があります。膨大なエラーログなどでこの枠が溢れるのを防ぐため、
--fastフラグを用いてテスト結果の出力行数を厳格に制限し、AIが重要な情報に集中できる環境を整えました。 - 過学習の防止: 単一の宇宙論パラメータでのみテストを通過してしまう「過学習」を防ぐため、特定の基準点だけでなく様々なパラメータでの検証を実施しました。
- 「ごまかし係数の禁止」ルールの徹底: 前章で触れたような、物理的根拠を持たないパラメータ(ファッジファクター)を用いてテストを通すことを明確に禁止するルールを初期段階から設定していました。
さらに、今回のケーススタディから得られた教訓として、今後の防御策となる「自動化された事前コミットチェック」が提案されています。
AIはテストを通すための局所的な最適化に長けているため、人間が目を光らせていても、巧妙に係数を紛れ込ませる可能性があります。これを防ぐため、例えばAIが実装した係数を極端な境界値(例:\(\alpha=0\))に設定してテストを再実行するような「極限ケースでのプローブ(探査)」を実施します。この仕組みをコードのコミット前に自動で走らせるようにすれば、その係数が物理的な構造を正しく反映しているのか、単なる数値のつじつま合わせなのかを、システム側で機械的にあぶり出すことが可能になります。
科学的ソフトウェアにおいてAIを信頼できるパートナーにするためには、ただAIにコードを書かせるのではなく、このように「正しいプロセスで真理を探求しているか」を常に検証するプロトコルが不可欠なのです。
おわりに
このプロジェクトのケーススタディから、科学的ソフトウェア開発におけるAIの現在地が見えてきます。
自動化されたオラクルテストは「コードがそこで正しい数値を出力するか(What)」は検証できても、「なぜ正しい数値を出力するのか(Why)」までは検証できません。そのため、物理的に間違ったメカニズムであっても、特定のテスト点を通過してしまう危険性が常に伴います。著者は、計算メカニズムが物理的に首尾一貫しているかを評価・説明する能力を「Explanatory agency(説明能力)」と呼び、これが物理学者には備わっているものの、現状のAIには決定的に欠落していると指摘しています。このファッジファクター(ごまかし係数)を防ぐ対策として、AIに対し「その調整パラメータは参照理論のどの物理量に対応しているか?」と定型化して問う「物理的監査(Physics audit)」の導入が提案されています。
結論として、現状のAIはコーディングを加速させる強力なツールですが、科学的ソフトウェアの「著者としてのクレジット」や「知的責任」は、最終的な物理的判断を下す人間の研究者が担うべきです。
なお、本研究は単一のケーススタディ(\(N=1\))であり、人間が介入したのはAIが行き詰まったときのみという選択バイアスが含まれています。また、人間からの純粋なコード上のヒントと、物理概念の注入を厳密に切り分けた比較(アブレーション)ができていないといった検証の限界も明記されており、AIと科学の協働に向けて今後のさらなる研究が期待されます。
More Information
- arXiv:2605.30353, Nhat-Minh Nguyen, 「Physics Is All You Need? A Case Study in Physicist-Supervised AI Development of Scientific Software」, https://arxiv.org/abs/2605.30353
関連記事

宇宙物理学研究の新たなパラダイム: AIサイエンティストと Human-in-the-Loop
現代の宇宙物理学におけるデータ解析は、データ表現やモデルの構造、最適化戦略といった高次元の「方法論的設計空間」を人間が網羅的に探索することが困難になっています。そのため、大規模言語モデル(LLM)を活用した自律型エージェ […]

宇宙物理学×深層学習:基礎アーキテクチャからAIエージェントまでを概観する
現代の天文学は、Vera C. Rubin天文台やRoman宇宙望遠鏡などに代表される次世代の観測サーベイの稼働により、かつてない規模のデータ主導型科学へと急激に移行しています。こうした膨大なデータを前にして、従来の解析 […]

The Multimodal Universe: 天文学向け大規模機械学習用ビッグデータ
天文学は、その観測対象の広大さと複雑さから、常に膨大なデータを扱う分野です。近年、技術の進歩に伴い、画像、スペクトル、時系列データなど、多種多様な形式のデータが取得できるようになりました。これらのデータを統合的に解析する […]