Group-Evolving Agents: 経験共有によるAIの自己進化

LLMエージェントの開発において、人間の介入なしにシステムが自らの構造を改善し続ける「自己進化(Open-Ended Self-Improvement)」のアプローチが注目を集めています。しかし、従来の自己進化は「個体単位」のツリー型分岐が主流であり、ある個体の有用な発見が他のエージェントに共有されにくいという課題がありました。
本記事では、この課題を解決するため「エージェントのグループ」を進化の基本単位とし、経験やログを全体で共有する新しいフレームワーク「Group-Evolving Agents(GEA)」について解説します。
GEAは、SWE-benchなどのコーディングベンチマークにおいて、人間が設計した最高峰のフレームワーク(OpenHandsなど)と同等以上の性能を達成しました。本記事ではGEAの仕組みを紐解きながら、エージェント間での経験共有が、実際のシステム構築における汎用性やバグに対するロバスト性の向上にどう役立つかを探ります。
1. 従来の自己進化フレームワークの課題
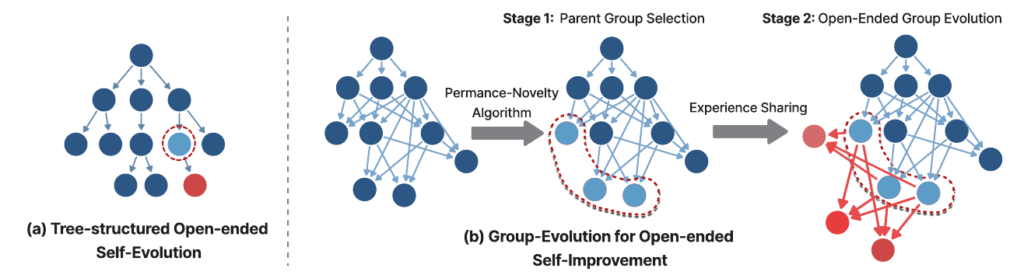
これまでにも、AIシステムが人間の介入なしに自らを改善していく「自己進化」の試みは数多く存在しました。既存のアプローチの多くは、生物学的な進化に着想を得ています。つまり、単一の「親」となるエージェントが選ばれ、そこから「子」エージェントが生成されるという、個体を基本単位とした木構造(Tree-structured)の進化プロセスを採用していました。
このツリー型のアプローチは、複数の異なる方向へ探索を進めることができるため、システム全体としては様々な特性を持つエージェントを生み出すことができます。しかし、ここに大きな構造的欠点が存在します。それは、進化の枝(ブランチ)が互いに完全に孤立してしまうという点です。
たとえば、ある枝にいるエージェントが、コードの修正に役立つ非常に有望な新しいツールやワークフローを発見したとします。本来であれば、その優れた手法をシステム全体で共有し、さらに発展させたいところです。しかし、従来のツリー構造では、枝と枝の間で情報や経験を直接共有する仕組みがありません。
そのため、せっかくの有用な発見も特定の系統の中だけで留まってしまい、他の枝にいるエージェントの進化には全く活かされません。結果として、全体として様々なアイデアが生まれるものの、それらは短命なバリエーションとして消えていくことが多く、「一時的な多様性」にとどまってしまいます。
このように、個々のエージェントが獲得した知見を効果的に組み合わせ、システム全体の長期的な性能向上(累積的な進歩)へと繋げることが難しいという非効率性が、従来の自己進化フレームワークが抱える大きな壁となっていました。
2. Group-Evolving Agents (GEA) の仕組み
従来のシステムが抱えていた「枝の孤立」という課題に対し、GEAは「エージェントのグループ」を進化の単位とするアプローチで解決を図ります。その具体的な仕組みを2つのステップに分けて解説します。
2.1 親グループの選択(PerformanceとNoveltyのバランス)
GEAでは、進化のステップごとに、全エージェントが保存されたアーカイブの中から「親」となるエージェントのグループを選択します。このとき、単にタスクの成功率(Performance)が一番高いエージェントだけを選ぶわけではありません。
GEAは、タスク成功率に加えて、他のエージェントの解答パターンとどれくらい異なるかという「新規性(Novelty)」を計算し、両者を掛け合わせたスコアを利用して親を決定します。具体的には、以下の2つの指標でバランスを取って評価を進めます。
- Performance(タスク成功率): すぐに役立つ実装能力の高さ
- Novelty(新規性): 他のエージェントとは異なる、未開拓で有望なアプローチを持っているか
この仕組みにより、直近のスコアは低くても、他にはないアプローチを持つエージェントを親として残すことができます。結果として、特定の解法に偏るのを防ぎ、システム全体の探索に様々な方向性を維持できるようになります。
2.2 経験のプールとグループ進化
親グループが選択されると、次はいよいよエージェント同士での「経験の共有」を実施します。ここが従来のツリー型進化と最も異なるポイントです。
親グループに選ばれたエージェントたちは、自分たちが得た知見をひとつの共有プールに集約します。ここでプールされる具体的な情報は以下の通りです。
- コードの修正履歴(パッチ): エージェントのフレームワークに対して実際に適用された修正内容
- 実行ログ: ツールの呼び出し履歴やタスク解決に至るまでの具体的なワークフロー
- 評価結果と失敗の要因: 失敗したタスクから得られた、改善のためのヒント
各エージェントは、自分自身の過去の履歴だけでなく、このグループ全体の共有経験をLLM(リフレクションモジュール)に入力します。そして、集約された情報を分析し、次のステップへ向けた改善方針(ディレクティブ)を生成します。
この情報共有プロセスにより、あるエージェントが見つけた便利なツールや優れたワークフローを、グループ内の他のエージェントも即座に自分のコードベースへ統合することが可能になります。つまり、互いの有益な発見を取り入れながら、より強力なエージェントへと効率よく進化していくことができるのです。
3. GEAの技術的な利点と実装へのヒント
ここでは、GEAがもたらす技術的な利点と、そこから得られる実務的なシステム構築のヒントを3つの観点から解説します。
3.1 複数機能の効率的な統合
従来の孤立した進化プロセスでは、あるエージェントが新しいファイル編集ツールの追加やデバッグロジックの改善といった有用な機能を発見しても、それが他のエージェントに伝播せずに失われてしまうことが多くありました。対照的に、GEAはグループ全体で経験を共有するため、様々なエージェントが発見した個別の機能を、1つの優秀なエージェントに効率よく集約することができます。
実装へのヒント: 複数のエージェントや推論プロセスを並行して稼働させるシステムを設計する場合、各プロセスが完全に独立して動くのではなく、実行ログやエラー解決の痕跡を共有データベース(またはコンテキスト)に集約する仕組みが有効です。そして、集約された情報を定期的に振り返り、システム全体で有用なアプローチを共有する設計にすることで、タスク解決能力を効率的に底上げできます。
3.2 バックボーンモデルに依存しない汎用性
GEAによる性能向上は、特定のLLM(バックボーンモデル)に対するプロンプトの過学習によるものではありません。エージェントのワークフローや、ツールの利用方法そのものを根本的に最適化することで達成されています。
実際に、Claudeモデルを用いて進化させたエージェントの構造をそのままGPTシリーズで稼働させても、進化前(初期状態)を上回る高い性能が維持されることが確認されています。
実装へのヒント: システムを構築する際、プロンプトエンジニアリングに過度に依存すると、将来的な基盤モデルの変更時に大幅な改修が必要になるリスクがあります。そのため、システム側のツール定義や実行フロー自体を動的に最適化する仕組みを構築することで、特定のモデルに依存しない汎用性の高いシステムを作ることができます。
3.3 エラーからの自己修復能力(ロバスト性)
自律型エージェントの運用において、システムが予期せぬエラーやバグに直面した際の復旧能力(ロバスト性)は極めて重要です。
研究チームが意図的にフレームワークレベルのバグを混入させた実験では、従来の手法が自己修復に平均5回のイテレーションを要したのに対し、GEAはわずか平均1.4回のイテレーションでバグを修復しました。これは、バグを抱えたエージェントが、グループ内にいる他の正常なエージェントの成功経験を参照し、そこから正しい動作のヒントを得ることができたためです。
実装へのヒント: 本番環境で自律型システムを稼働させる場合、正常に動作したプロセスの実行トレースをフォールバック(障害時の代替処理)用のテンプレートとして保持・共有する仕組みの導入が推奨されます。これにより、予期せぬエラーが発生した際にも、他のプロセスの成功例を参照して自動復旧(セルフヒーリング)を素早く進めることが可能になります。
4. Python による GEAの実装
ここでは、GEAの核となるアルゴリズムをPythonで実装した例を紹介します。この実装では、LLMへのアクセスに様々なプロバイダを統一的に扱える LiteLLM を採用しています。
4.1 必要なパッケージのインストール
まずは、必要なパッケージをインストールします。
# LiteLLMのインストール pip install litellm
LLMの呼び出しには LiteLLM が使用されるため、OpenAIやGeminiなどのAPIキーを環境変数として設定しておきます。
export OPENAI_API_KEY="your-openai-api-key" export GEMINI_API_KEY="your-gemini-api-key"
4.2 ディレクトリ構成と各ファイルの役割
実装は、責務ごとにディレクトリを分割しています。
gea/
├── domain/ # エージェントやアーカイブなどの核となるデータ構造
│ ├── agent.py # 個々のエージェントの状態や経験を保持するクラス
│ └── archive.py # 歴代のエージェントを保存・管理するクラス
├── application/ # GEAの主要なアルゴリズム(選択・進化)のビジネスロジック
│ ├── selection.py # パフォーマンスとノベルティを計算し、親グループを選択するサービス
│ └── evolution.py # 親グループ間で経験を共有し、新しいエージェントを生成するサービス
└── infrastructure/ # LLMへのアクセスやコード実行環境などの外部とのインターフェース
├── llm_client.py # LiteLLMを用いたLLMへのプロンプト送信とパッチ生成処理
└── sandbox.py # 生成されたコードを安全に評価するサンドボックス環境(今回は簡易実装)
main.py # 全体を統合してGEAのサイクルを実行するエントリポイント
4.3 domain/:データ構造の定義
domain/agent.py
個々のエージェントの情報を保持するシンプルなデータクラスです。エージェントのソースコードやパフォーマンススコア、そして「進化のトレース(経験)」を保持します。
from dataclasses import dataclass, field
from typing import Any
@dataclass
class Agent:
"""
個々のエージェントの状態や経験を保持するデータクラス。
"""
id: str
code: str
performance_score: float
task_vector: list[int] # 各タスクの成功(1)・失敗(0)の履歴
# 過去に適用された修正パッチや実行ログなどの「経験データ」
evolutionary_traces: dict[str, Any] = field(default_factory=dict)
domain/archive.py
これまで生成された全てのエージェントを保存し、親グループの選択候補として管理するクラスです。
from collections.abc import Iterator
from gea.domain.agent import Agent
class Archive:
"""
条件を満たした歴代の全 Agent を保存するクラス。
"""
def __init__(self) -> None:
self._agents: list[Agent] = []
def add(self, agent: Agent) -> None:
self._agents.append(agent)
@property
def agents(self) -> list[Agent]:
return self._agents
def __iter__(self) -> Iterator[Agent]:
return iter(self._agents)
def __len__(self) -> int:
return len(self._agents)
4.4 application/:アルゴリズムの中核
application/selection.py
アーカイブの中から「現在の優秀さ」と「他との違い(新規性)」のバランスを取って親グループを選出します。タスクの成功履歴(タスクベクトル)からコサイン距離を計算し、類似度の低さからノベルティ(新規性)スコアを算出します。
import math
from gea.domain.agent import Agent
from gea.domain.archive import Archive
def calculate_cosine_distance(v1: list[int], v2: list[int]) -> float:
"""タスクベクトル間のコサイン距離を計算し、エージェント間の違いを数値化する。"""
if not v1 or not v2 or len(v1) != len(v2):
return 1.0 # ベクトル長が合わない場合は最大の距離とする
dot_product = sum(a * b for a, b in zip(v1, v2, strict=True))
norm_v1 = sum(a * a for a in v1) ** 0.5
norm_v2 = sum(b * b for b in v2) ** 0.5
epsilon = 1e-9 # ゼロ除算を防ぐための微小値
denominator = norm_v1 * norm_v2 + epsilon
return max(0.0, 1.0 - (dot_product / denominator))
class ParentSelectionService:
"""
アーカイブから親となるエージェントを選択するサービス。
パフォーマンスとノベルティ(新規性)のバランスを取って K 個選ぶ。
"""
def __init__(self, m_neighbors: int, k_parents: int) -> None:
self.m_neighbors = m_neighbors
self.k_parents = k_parents
def select(self, archive: Archive) -> list[Agent]:
agents = archive.agents
if len(agents) <= self.k_parents:
return list(agents)
scored_agents: list[tuple[float, Agent]] = []
for i, agent in enumerate(agents):
distances: list[float] = []
for j, other in enumerate(agents):
if i != j:
dist = calculate_cosine_distance(agent.task_vector, other.task_vector)
distances.append(dist)
distances.sort()
# 最も距離が近い(似ている) M 個のエージェントとの距離の平均値をノベルティスコアとする
m_nearest = distances[:self.m_neighbors]
nov_score = sum(m_nearest) / len(m_nearest) if m_nearest else 0.0
# パフォーマンスを主軸とし、ノベルティで調整した総合スコアを計算 (論文の数式に基づく)
final_score = agent.performance_score * math.sqrt(nov_score)
scored_agents.append((final_score, agent))
# 総合スコアが高い順に上位 K 個を選択して返す
scored_agents.sort(key=lambda x: x[0], reverse=True)
return [agent for _, agent in scored_agents[:self.k_parents]]
application/evolution.py
選択された親グループ内で経験を共有し、新たなエージェント(子)を生成するモジュールです。
import uuid
from typing import Any, Protocol
from gea.domain.agent import Agent
from gea.domain.archive import Archive
class ILLMClient(Protocol):
"""LLMへのアクセスを抽象化するインターフェース"""
def reflect_on_traces(self, shared_pool: list[dict[str, Any]], agent_code: str) -> str: ...
def generate_patch(self, agent_code: str, directive: str) -> str: ...
class ISandbox(Protocol):
"""安全にコードを評価するサンドボックス環境のインターフェース"""
def evaluate(self, code: str) -> tuple[float, list[int], dict[str, Any]]: ...
class EvolutionService:
"""
選ばれた親グループ内で「経験」を共有し、新しい子エージェントグループを作成するサービス。
"""
def __init__(self, llm_client: ILLMClient, sandbox: ISandbox) -> None:
self.llm_client = llm_client
self.sandbox = sandbox
def evolve(self, parents: list[Agent], archive: Archive) -> list[Agent]:
if not parents:
return []
# 1. 経験の収集と共有プール化:親全員の進化のトレースを1つにまとめる
shared_pool = [parent.evolutionary_traces for parent in parents]
children: list[Agent] = []
for parent in parents:
# 2. リフレクション(内省): 共有プールから「どこをどう直すべきか」の改善方針を策定
directive = self.llm_client.reflect_on_traces(shared_pool, parent.code)
# 3. 進化: 改善方針に従い、対象エージェントのコードにパッチ(修正)を適用
new_code = self.llm_client.generate_patch(parent.code, directive)
# 4. 評価: サンドボックス内で新しいコードを実行し、性能を測定
perf_score, task_vec, traces = self.sandbox.evaluate(new_code)
# 評価結果をもとに新しいエージェントを作成
child_id = str(uuid.uuid4())
child = Agent(
id=child_id,
code=new_code,
performance_score=perf_score,
task_vector=task_vec,
evolutionary_traces=traces
)
# サンドボックスでの評価が正常(エラー以外)であれば、アーカイブと次世代に追加
if traces.get("status") != "error":
archive.add(child)
children.append(child)
return children
4.5 infrastructure/:外部との連携
infrastructure/llm_client.py
LiteLLM を用いて、リフレクション(改善方針の策定)とコード修正(パッチの生成)のそれぞれに最適なモデルを呼び出します。今回の例では、複雑な内省には gemini-2.5-pro を、高速なコード生成には gpt-4o-mini を使用しています。
import json
from typing import Any
from litellm import completion # type: ignore
from gea.application.evolution import ILLMClient
class LiteLLMClient(ILLMClient):
"""
LiteLLMライブラリを利用して各LLMプロバイダーへアクセスするクライアント実装。
"""
def __init__(self, reflection_model: str = "gemini/gemini-2.5-pro", patch_model: str = "gpt-4o-mini") -> None:
self.reflection_model = reflection_model
self.patch_model = patch_model
def reflect_on_traces(self, shared_pool: list[dict[str, Any]], agent_code: str) -> str:
# グループ全体の過去の成功・失敗のトレース(共有プール)をプロンプトに埋め込む
prompt = f"""
あなたはAIエージェントの専門家です。
エージェントグループの過去の経験(共有プール)を分析し、対象エージェントのコードの改善方針を作成してください。
共有プール:
{json.dumps(shared_pool, ensure_ascii=False, indent=2)}
対象エージェントの現在のコード:
```python
{agent_code}
```
"""
response: Any = completion(
model=self.reflection_model,
messages=[{"role": "user", "content": prompt}]
)
return str(response.choices[0].message.content or "")
def generate_patch(self, agent_code: str, directive: str) -> str:
# 生成された改善方針(directive)をもとに、実際にコードを書き換える
prompt = f"""
あなたは優秀なPythonエンジニアです。以下の改善方針に従って、コードを書き換えてください。
結果はPythonコードのみを出力してください。
改善方針:
{directive}
対象コード:
```python
{agent_code}
```
"""
response: Any = completion(
model=self.patch_model,
messages=[{"role": "user", "content": prompt}]
)
# 余計なマークダウン記法を取り除く処理(省略)
return str(response.choices[0].message.content or "").strip()
infrastructure/sandbox.py
サンドボックス環境の実装例です。本番環境ではDockerなどの隔離されたコンテナ環境が必須ですが、今回はPythonのサブプロセスを用いた簡易実装となっています。
import os
import subprocess
import sys
import tempfile
from typing import Any
from gea.application.evolution import ISandbox
class SubprocessSandbox(ISandbox):
"""
サブプロセスを用いて安全にコードを評価するサンドボックス環境の簡易実装。
"""
def evaluate(self, code: str) -> tuple[float, list[int], dict[str, Any]]:
# 一時ファイルにコードを保存して外部プロセスから実行する
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f:
f.write(code)
temp_file = f.name
try:
# 1. 構文チェックとしてコンパイル実行
compile_result = subprocess.run(
[sys.executable, '-m', 'py_compile', temp_file],
capture_output=True,
text=True,
timeout=5
)
if compile_result.returncode != 0:
# 構文エラー発生時はパフォーマンス 0 とする
return 0.0, [0, 0, 0, 0], {"status": "error", "reason": "compile_error"}
# 2. 実行チェック(本来はここでタスクを実行させてスコアを計算する)
# 今回は簡易的にコード内に特定のキーワードが含まれているかでスコアを判定
tasks_passed = [
1 if "def " in code else 0,
1 if "class " in code else 0,
1 if "return" in code else 0,
1 if len(code) > 20 else 0
]
perf_score = sum(tasks_passed) / len(tasks_passed) if tasks_passed else 0.0
return perf_score, tasks_passed, {"status": "success"}
except Exception as e:
return 0.0, [0, 0, 0, 0], {"status": "error", "reason": "exception"}
finally:
if os.path.exists(temp_file):
os.remove(temp_file)
4.6 main.py:全体の実行例
これまでのコンポーネントを統合し、GEAのサイクルを回すエントリポイントです。
import os
import uuid
from gea.application.evolution import EvolutionService
from gea.application.selection import ParentSelectionService
from gea.domain.agent import Agent
from gea.domain.archive import Archive
from gea.infrastructure.llm_client import LiteLLMClient
from gea.infrastructure.sandbox import SubprocessSandbox
def main() -> None:
# 1. アーカイブの初期化と初期エージェントの追加
archive = Archive()
initial_agent = Agent(
id=str(uuid.uuid4()),
code="class SimpleAgent:
def act(self):
return 'Hello World'",
performance_score=0.5,
task_vector=[1, 1, 0, 0],
evolutionary_traces={"status": "initial"}
)
archive.add(initial_agent)
# 2. サービスのインスタンス化
selection_service = ParentSelectionService(m_neighbors=1, k_parents=1)
# リフレクションにGemini、パッチ生成にOpenAIを使用するよう指定
llm_client = LiteLLMClient(
reflection_model="gemini/gemini-2.5-pro",
patch_model="gpt-4o-mini"
)
sandbox = SubprocessSandbox()
evolution_service = EvolutionService(llm_client=llm_client, sandbox=sandbox)
# 3. GEA ループの実行(例として1世代のみ実行)
generations = 1
for gen in range(generations):
# フェーズ1: アーカイブから親グループの選択
parents = selection_service.select(archive)
# フェーズ2: 経験の共有(プール化)と新しいエージェントの生成
children = evolution_service.evolve(parents, archive)
# 4. 最終的なベストエージェントの出力
best_agent = max(archive.agents, key=lambda a: a.performance_score)
print(f"Best Agent Score: {best_agent.performance_score}")
print(f"Code:
{best_agent.code}")
if __name__ == "__main__":
main()
おわりに
個体ではなくグループ単位で経験を共有しながら進化するGEAは、従来の自己進化システムが抱えていた「探索の孤立」という課題を解消しました。その結果、SWE-bench Verifiedで71.0%、Polyglotで88.3%という優れたタスク成功率を記録しています。
この手法の強みは、特定のモデルに依存したプロンプト調整ではなく、ワークフローやツール利用の自律的な改善を促す点にあり、結果として高い汎用性とロバスト性を備えています。
複雑なタスクを処理するLLMエージェントシステムを設計する際、プロセス間の明示的なログ共有や、性能と新規性のバランスを取る選択アルゴリズムの導入は、システムを継続的に改善させるための強力なアプローチとなるはずです。
More Information
- arXiv:2602.04837, Zhaotian Weng et al., 「Group-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing」, https://arxiv.org/abs/2602.04837
関連記事

LangFair: LLMアプリケーションのバイアスと公平性を評価する
近年、大規模言語モデル(LLM) は、テキスト生成、分類、推薦など、様々な分野で活用されています。しかし、LLMにはバイアスが存在することが指摘されており、特定のグループに対して不公平な結果を生み出す可能性があります。こ […]

ベイジアンネットワーク入門:pgmpyによる因果探索と因果推論の実践
近年の機械学習(ML)モデルは、ビッグデータ解析において非常に高い予測精度を達成しています。しかし、その意思決定に至るプロセスが不透明な「ブラックボックス」となってしまう課題が指摘されています。データから相関関係を発見す […]

LLM時代の自律型コーディング・エージェントはソフトウェア開発の在り方をどのように変えるか?
大規模言語モデル(LLM)の目覚ましい進化は、ソフトウェア開発(Software Development)の領域に根本的な変化をもたらしています。これまで、AIによるコーディング支援の多くは、自然言語の記述を静的なコード […]