3D Gaussian Splatting: 3次元表現の新たなパラダイム

近年、実世界の画像から3Dシーンを再構築し、任意の視点から画像を生成する技術が急速に発展しています。
その代表格としてNeRF (Neural Radiance Fields)が広く知られていますが、計算コストが高く、描画にかかる時間に課題を抱えていました。そんな中、NeRFに代わる新たな技術として登場したのが「3DGS (3D Gaussian Splatting)」です。
3DGSは、NeRFが抱えていたレンダリング速度の課題を克服し、リアルタイムでの高品質な画像生成を可能にしました。これにより、自動運転のシミュレーションやロボティクスなど、様々なAIシステムの構築手法が大きく変わろうとしています。
本記事では、3DGSの基本原理を紐解くとともに、AIシステム開発においてどのような技術的利点と実用的な可能性をもたらすのかを解説します。さらに、次世代の空間知能である「World Model」との関連性を交えながら、この新しい3次元表現のパラダイムに迫ります。
1. 3D Gaussian Splattingの基本原理
従来手法であるNeRFは非常に高品質な画像を生成できる一方で、その計算コストの高さが実用化の大きな壁となっていました。3DGSは、この課題を根本から解決するアプローチを採用しています。ここでは、3DGSを支える3つの基本原理を解説します。
NeRFとの決定的な違い:暗黙的か、明示的か
NeRFは、空間の情報をニューラルネットワークの中に閉じ込める「暗黙的(Implicit)」な表現を採用しています。画像を生成する際は、視点から光線を飛ばし、その経路上で何度もネットワークに問い合わせて色と密度を計算する「ボリュームレンダリング」を実施するため、膨大な時間がかかります。
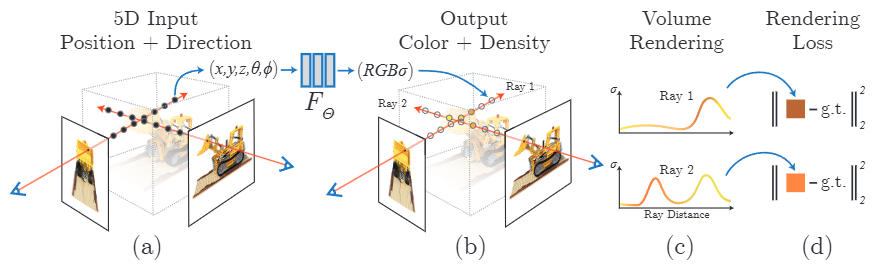
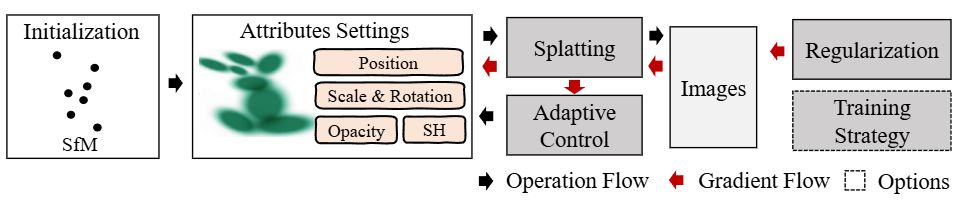
これに対し、3DGSは空間を数100万個の「3Dガウシアン(楕円体)」の集合として直接配置する「明示的(Explicit)」な表現を採用しました。ニューラルネットワークというブラックボックスを通さず、データ構造として直接空間をモデリングしている点が最大のブレイクスルーです。

3Dガウシアンを形作る学習パラメータ
空間に配置される数百万個の3Dガウシアンは、ただの点の集まりではありません。それぞれのガウシアンは、以下のような学習可能なパラメータを持っています。
- 位置: 3D空間上のどこに存在するか(中心座標)
- 共分散(スケールと回転): どのくらいの大きさで、どの方向を向いているか。これにより、細長い楕円体や平べったい楕円体など、様々な形状を表現できます。
- 不透明度: そのガウシアンがどれくらい透けているか
- 色(球面調和関数 /
Spherical Harmonics): どの方向から見るかによって色が変化する、視線依存の光沢や反射を表現するパラメータ
システムは、実際の画像と生成された画像の誤差を計算し、これらのパラメータを微調整(最適化)していくことで、複雑なシーンを正確に再構築します。
リアルタイム性を支える高速化の仕組み
明示的な表現を手に入れたとはいえ、数百万個の楕円体を力技で描画しようとすれば、処理は追いつきません。そこで3DGSは、「Tile-based Differentiable Rasterizer」という手法を導入しました。
具体的には、生成する画像を小さなタイル(例えば16×16ピクセル)に分割します。そして、GPUの高度な並列処理能力を最大限に引き出し、各タイルに影響を与えるガウシアンだけを効率的に選別して描画を進めます。この仕組みにより、何も存在しない空の領域での無駄な計算を省くことができ、GPU上で極めて高速な最適化とリアルタイムレンダリング(30 fps以上)を実現しているのです。
このように、3DGSは表現手法そのものを根本から見直し、ハードウェアの特性を活かした設計を取り入れることで、圧倒的なパフォーマンスを獲得しました。
2. AIシステム開発における技術的利点
3DGSは単なる「速くて綺麗なレンダリング技術」にとどまりません。AIシステムを開発するエンジニアにとって、表現手法の構造そのものが、従来の技術にはない様々な利点を提供します。ここでは、大きく3つの技術的利点に整理して解説します。
- 明示的表現による高い操作性
NeRFのような暗黙的(Implicit)なモデルは、空間全体がニューラルネットワークの重みとしてブラックボックス化されているため、シーンの一部だけを修正することが困難でした。一方、3DGSは空間が数百万個のガウシアンの集合として明示的(Explicit)に配置されています。
これにより、特定のオブジェクトを構成するガウシアンの群を特定し、削除、移動、変形させるといったシーンの編集が非常に容易になります。たとえば、自動運転のシミュレーション環境で「道路上の障害物だけを取り除く」「車両の配置を変える」といった空間の操作を、直感的に進めることが可能です。 - 計算リソースの効率化と高速性
AIシステムの運用において、計算リソースの効率化は常に重要な課題です。3DGSは、生成済みのモデルからの推論(レンダリング)がリアルタイム(30 fps以上)で実行できるだけでなく、モデルの学習自体も数十分程度と非常に効率的です。
さらに、この高速な処理能力は、時間変化を伴う「動的シーン(4D)」のモデリングにも適しています。フレームごとにシーン全体をゼロから再計算するのではなく、動くオブジェクトのガウシアンだけを変形・移動させることで、リアルな動的環境を限られたリソースで構築できます。 - マルチモーダル情報の統合
AIエンジニアにとって特に注目すべき点は、各ガウシアンのパラメータに、色や形だけでなく、追加の属性を持たせることができる拡張性の高さです。
たとえば、画像とテキストを関連付けるAIモデルであるCLIP (Contrastive Language-Image Pre-training)の特徴量や、セマンティック(意味的)な情報をガウシアンに直接付与する研究が進んでいます。これにより、「木製の椅子」や「赤い車」といった自然言語の指示(プロンプト)を用いて、特定のオブジェクトを検索したり、編集したりするシステムへと拡張しやすくなります。未知の概念にも対応できる「オープンボキャブラリ」な空間理解の基盤として、3DGSは非常に強力なツールとなります。

3. 具体的な実用例と実装へのヒント
3DGSは、すでに研究室の枠を飛び出し、実際のAIシステムやアプリケーションへと実装され始めています。ここでは、AIエンジニアの皆さんが自身のプロジェクトに応用するヒントとして、特に注目すべき3つの実用例をご紹介します。
- 生成AI(AIGC)への組み込みによる3Dアセット生成
画像生成でおなじみの「拡散モデル(Diffusion Model)」と3DGSを組み合わせるアプローチが急速に普及しています。テキストの指示や単一の画像から、高品質な3Dモデルを生成するText-to-3DやImage-to-3Dのパイプラインが代表的です。従来のNeRFベースの手法では最適化に数時間を要していましたが、3DGSの高速な描画能力と明示的な構造を活かすことで、生成時間を大幅に短縮できるようになりました。生成AIシステムを構築する際、3DGSを出力フォーマットとして採用すれば、実用的な処理速度と品質の両立が期待できます。 - ロボティクスと高精度なSLAMシステムへの統合
ロボットが自律的に動くためには、自分の位置を推定しながら周囲の環境をマッピングするSLAM (Simultaneous Localization and Mapping)という技術が欠かせません。カメラ画像や深度センサーの情報をもとに、3DGSを用いて空間を再構築するSLAMシステムへの統合が進んでいます。ニューラルネットワークの計算を繰り返すNeRFを用いたSLAMと比較して、3DGSはリアルタイムでの密な3Dマップ構築に優れています。これにより、ロボットによる複雑な物体操作(マニピュレーション)や、自動運転におけるシミュレーション環境の構築を、よりスムーズに進めることが可能です。 - 4D(動的)シーンとリアルタイム・アバター生成
3次元の空間に「時間軸(Temporal)」のパラメータを追加した「4DGS」の検証も活発です。特にデジタルヒューマンの領域では、人間の骨格モデルなどと連携させることで、複雑な表情の変化や衣服の自然な変形を伴う動的なアバターを生成できます。フレームごとに空間全体を再計算するのではなく、特定のオブジェクトを構成するガウシアンの配置や形状を時間に合わせて変形させるため、高いフレームレートでのリアルタイムレンダリングが可能です。VR/ARアプリケーションやオンラインミーティング用のシステムを開発する上で、非常に強力な選択肢となります。

4. 3DGSとWorld Model: 空間知能とEmbodied AIへの飛躍
これまでのセクションで、3DGSがいかに高速で柔軟な3次元表現をもたらすかを見てきました。AIシステムを開発する上で、この技術が真価を発揮するのは「ただ視覚的に綺麗な空間」から「物理法則を持ち、AIが干渉できる空間」へと進化したときです。ここでは、その飛躍を支える3つの重要な観点を整理します。
- World Modelとは何か
自動運転車やロボットなどのAIエージェントが、実世界で安全かつ適切に動作するためには、周囲の環境を理解し、「もし自分が前進したら、周囲の障害物はどう見えるか」「この物体を推したらどう動くか」を内部で予測・シミュレーションする能力が必要です。この外界の計算的な予測モデルを「World Model」と呼びます。これまでのシステムでは2D画像ベースの予測が主流でした。しかし、現実世界は3次元であるため、真に汎用的なAIを実現するには、3次元空間の構造を直接的にモデリングできるWorld Modelが不可欠とされています。 - 高機能なシミュレータへと進化する3DGS
3DGSは、現実世界のデータを収集して再構築するだけでなく、物理法則や意味情報(セマンティクス)を組み込んだシーン表現へと発展を遂げています。空間が明示的に表現されているため、自動運転のシミュレーション環境を構築する際にも、他車両の動きに伴う視点の変化や、障害物の配置変更などをリアルタイムで反映できます。これにより、3DGS自体が、ロボットやAIモデルを訓練するための、フォトリアルで様々なパターンの合成データを生成する「シミュレータ」として機能するようになります。 - 物理法則の学習(Physics-aware)によるインタラクティブな世界
さらに研究の最前線では、大規模なデータセットからリアルな物理的ダイナミクスを抽出し、3DGSの各ガウシアンに直接付与する取り組みが進められています。これを「Physics-aware(物理法則を考慮した)」なアプローチと呼びます。
例えば、ガウシアンに「質量」や「弾性」といった物理的な属性を持たせ、物理エンジンと連動させる検証が進んでいます。これにより、「押すと変形する柔らかい物体」や「ぶつかると崩れる障害物」をデジタル空間上で正確に再現できます。未知の環境であっても現実と同様に振る舞う、インタラクティブなWorld Model(Physically Embodied Gaussian Splattingなど)の構築がすでに現実のものとなりつつあります。
このような技術の飛躍により、3DGSは単なる画像生成のフォーマットという枠を超え、次世代のAIエージェントが実世界を理解するための極めて重要な基盤技術となることが期待されています。
おわりに
これまでの解説を通して、3DGSが単なる「速くて綺麗なレンダリング手法」にとどまらないことがお分かりいただけたのではないでしょうか。その明示的で柔軟なデータ構造は、3Dビジョン、生成AI、そしてロボティクスといった様々な領域をシームレスに繋ぐ、強力な基盤表現となりつつあります。
一方で、実運用に向けて解決すべき技術的な課題も残されています。数百万個のガウシアンを保持するためのメモリ消費の大きさは、依然としてシステム構築におけるハードルです。また、空間を点の集合として扱う性質上、医療用のCTスキャンのように、物体内部の緻密なボリューム構造をモデリングすることは現在のところ困難とされています。
しかし、これらの課題を乗り越えた先には、さらなる可能性が広がっています。今後、物理シミュレーションとAIが融合する「身体性AI(Embodied AI)」や空間コンピューティングの領域において、3DGSをどのようにシステムへ組み込むかは、AIエンジニアにとって非常に重要な選択肢となるはずです。本記事が、皆さんの新たなシステムアーキテクチャ設計の一助となれば幸いです。
More Information
- arXiv:2308.04079, Bernhard Kerbl et al., 「3D Gaussian Splatting for Real-Time Radiance Field Rendering」, https://arxiv.org/abs/2308.04079
- arXiv:2401.03890, Guikun Chen et al., 「A Survey on 3D Gaussian Splatting」, https://arxiv.org/abs/2401.03890
- arXiv:2403.11134, Tong Wu et al., 「Recent Advances in 3D Gaussian Splatting」, https://arxiv.org/abs/2403.11134
- arXiv:2405.03417, Anurag Dalal et al., 「Gaussian Splatting: 3D Reconstruction and Novel View Synthesis, a Review」, https://arxiv.org/abs/2405.03417
- arXiv:2405.09717, Siming He et al., 「From NeRFs to Gaussian Splats, and Back」, https://arxiv.org/abs/2405.09717
- arXiv:2407.17418, Yanqi Bao et al., 「3D Gaussian Splatting: Survey, Technologies, Challenges, and Opportunities」, https://arxiv.org/abs/2407.17418
- arXiv:2410.12262, Siting Zhu et al.,「3D Gaussian Splatting in Robotics: A Survey」, https://arxiv.org/abs/2410.12262
- arXiv:2508.09977, Shuting He et al., 「A Survey on 3D Gaussian Splatting Applications: Segmentation, Editing, and Generation」, https://arxiv.org/abs/2508.09977
- arXiv:2510.26694, Bernhard Kerbl, 「The Impact and Outlook of 3D Gaussian Splatting」, https://arxiv.org/abs/2510.26694
関連記事

AI学習データの品質管理 - 有害データ検出の最新手法
AI開発の潮流は、近年、「モデル中心AI(Model-Centric AI)」から、訓練データの品質向上に焦点を当てる「データ中心AI(Data-Centric AI)」へと大きく転換しました。AIシステムの最終的な精度 […]

AIコーディングエージェントの限界と課題:3万件のプルリクエスト分析から見る現実
GitHub CopilotやDevinといったAIツールは、今や単なるコード補完のアシスタントではなく、自律的にコードを書き、プルリクエスト(PR)まで作成する「エージェント」へと進化を遂げています。しかし、彼らは実際 […]

強化学習の世界を俯瞰してみる - 基礎から最前線の課題・応用・トレンドまで
強化学習(RL)は、エージェントが試行錯誤を通じて最適な行動を学習する機械学習の一分野です。近年、囲碁やビデオゲーム、大規模言語モデル(LLM)の制御など、多岐にわたる分野で著しい進展を遂げ、応用されています。 特に、深 […]