AIコーディングエージェントの限界と課題:3万件のプルリクエスト分析から見る現実
GitHub CopilotやDevinといったAIツールは、今や単なるコード補完のアシスタントではなく、自律的にコードを書き、プルリクエスト(PR)まで作成する「エージェント」へと進化を遂げています。しかし、彼らは実際の開発チームにおいて、本当に頼れるパートナーとなっているのでしょうか。
今回は、主要なAIエージェント(OpenAI Codex, GitHub Copilot, Devinなど)が作成した33,000件以上のPRを分析した実証研究をもとに、その「現実」を徹底解説します。高いマージ率を誇るタスクがある一方で、なぜ多くのPRがCIパイプラインで失敗し、あるいはレビューすらされずに放置されてしまうのか。定量的なデータと定性的な拒否理由の分析を通じて、AIエージェントの限界と、彼らを効果的に活用するための具体的な指針を紐解いていきます。
1. AIエージェントの貢献における成功率と得意分野
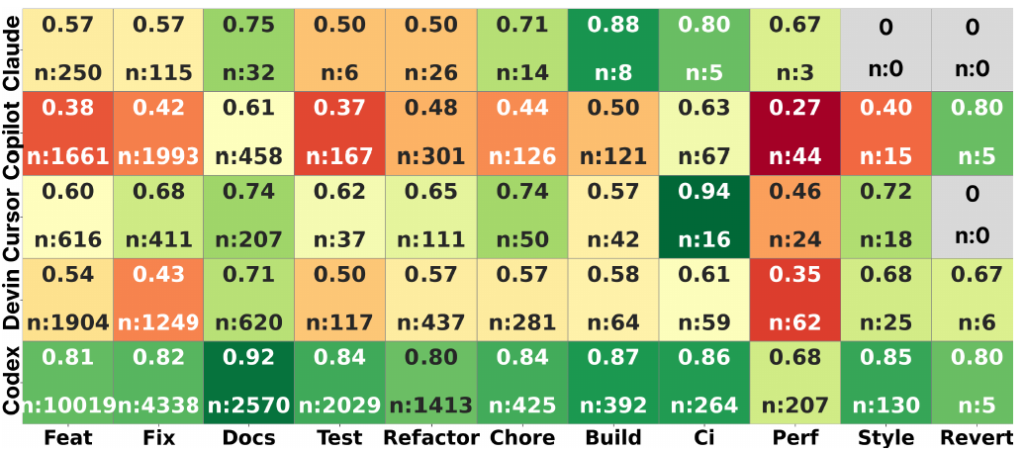
GitHub上の5つの主要なAIエージェント(OpenAI Codex, GitHub Copilot, Devinなど)が生成した計33,596件のプルリクエスト(PR)を分析した結果、全体のマージ率(採用率)は約71.5%と高い数値を記録しています。
しかし、この数字だけで「AIは優秀だ」と判断するのは早計です。エージェントごとの成績には大きな開きがあるためです。具体的には、分析対象の中で最も多くのPRを生成したOpenAI Codexが約82.6%という圧倒的なマージ率を誇る一方で、自律型エージェントとして注目されるDevinは約53.8%、そしてGitHub Copilotは約43.0%と、ツールによって明暗が分かれる結果となりました。
では、AIエージェントは具体的にどのようなタスクで成果を上げているのでしょうか。タスクごとのマージ率を見ると、彼らの「得意・不得意」が明確に浮かび上がります。
- 得意なタスク(定型・メンテナンス業務)
ドキュメントの更新(約84%)、CI(継続的インテグレーション)の設定(約79%)、ビルド構成の更新(約74%)などは、どのエージェントでも一貫して高い成功率を維持しています。これらは「やるべきこと」が明確で、複雑な文脈理解をそれほど必要としないため、現在のAIにとって扱いやすい領域だと言えます。 - 苦手なタスク(複雑なロジック・改善)
対照的に、パフォーマンス改善(約55%)やバグ修正(Fix)(約64%)といったタスクは成功率が低迷しています。特にパフォーマンス改善は全カテゴリー中で最も低い数値となっており、既存コードベースへの深い洞察や、複雑な依存関係の理解が必要なタスクにおいて、AIは依然として苦戦している現実が見て取れます。
2. マージされないPRの技術的特徴
マージに至らなかった(拒否された)PRのデータを分析すると、そこには明確な定量的特徴(パターン)が存在します。ここでは、開発者がレビュー時に直面する「負荷」と「リスク」の要因を3つの観点から解説します。
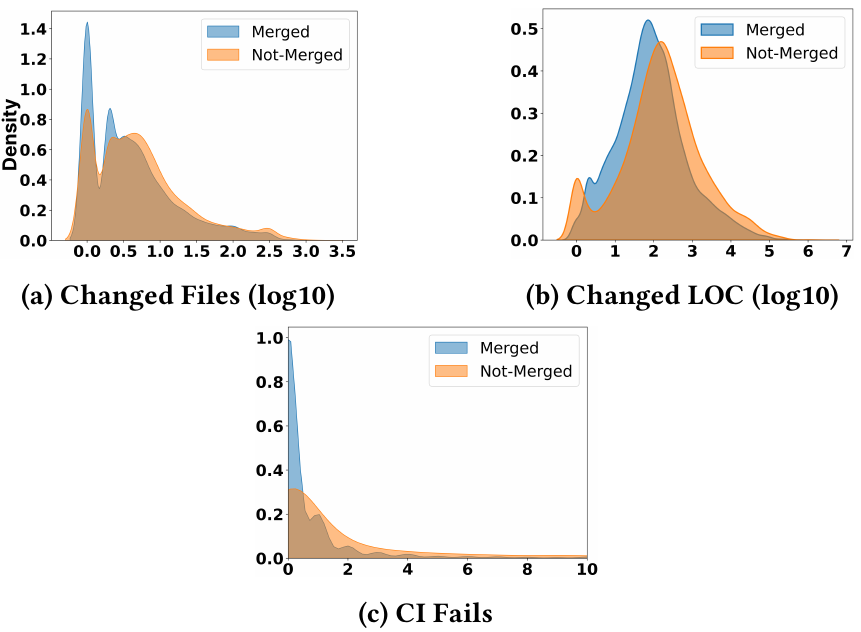
- 変更規模の大きさ(Big Changes)
拒否されるPRは、マージされたものと比較して、変更行数(LOC)や対象ファイル数が明らかに多い傾向にあります。AIエージェントが生成した大規模で広範囲にわたる変更は、人間にとってレビューの負担が重く、また既存システムへの予期せぬ副作用(リスク)が高いと判断されやすいためです。 - CIパイプラインの失敗
マージされるPRの大多数が自動テストやビルドチェックをスムーズに通過しているのに対し、拒否されるPRの多くはCI(継続的インテグレーション)パイプラインで失敗しています。統計モデルによると、失敗したCIチェックが1つ増えるごとに、そのPRがマージされる確率は約15%低下することが示されており、自動テストをパスできないコードは門前払いされている現実が分かります。 - レビュー工数の浪費
見逃せないのが、不採用のPRほど多くのレビュー工数を消費しているという事実です。データによると、拒否されたPRは採用されたものよりも多くの修正(Revisions)やコメントのやり取りが発生している傾向があります。これは、最終的にゴミ箱行きとなるコードに対し、人間の開発者がフィードバックや修正指示のために貴重なリソースを浪費してしまっている「見えないコスト」を示唆しています。
3. なぜAIの提案は拒否されるのか(定性分析)
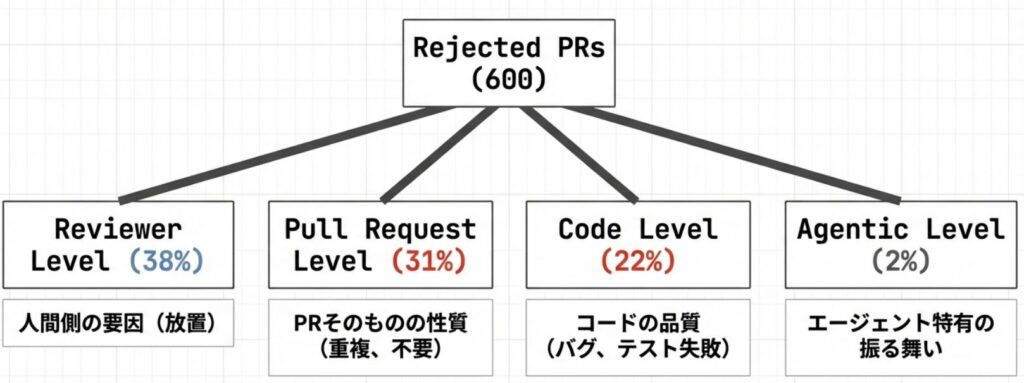
数値データだけでは見えてこない「拒否の真因」を掘り下げるため、600件の拒否されたPRに対する詳細な定性分析の結果を見ていきましょう。そこには、技術的な正誤以前の、AIと人間の協調における根本的な課題が潜んでいます。
- レビューアーによる放置(Reviewer Abandonment)
驚くべきことに、拒否された理由の中で最も多いのは「技術的な指摘」ではありません。約38%のPRは、人間の開発者から有意義なリアクションを得られないまま放置され、クローズされています。これは、AIが作成したPRに対して開発者が「レビューする優先度や価値が低い」と判断しているか、あるいは単にAIの提案に対する信頼がまだ十分に醸成されていない可能性を示唆しています。 - 重複したPR(Duplicate PR)
次に多いのが「重複」による拒否で、約23%を占めます。すでに別の開発者が着手しているタスクや、完了済みの修正をAIが認識できずに再提案してしまうケースです。「PR #715ですでに対応済み」といったコメントと共に却下されることが多く、プロジェクト全体の進行状況や他者の作業内容(コンテキスト)を把握する能力が、現在のAIエージェントには欠けていることが分かります,。 - 不要な機能と文脈の欠如
プロジェクトの目標に沿わない機能追加や、現場が求めていない大規模な変更を提案し、「不要(Unwanted Feature)」と判断されるケースも約4%存在します。文脈を読まない提案は、レビューアーにとってノイズでしかありません。 - 技術的な不備とアライメントの欠如
CIの失敗(約17%)に加え、深刻なのが「アライメントの欠如」です。これは、レビューアーが修正指示を出したにもかかわらず、AIがそれを正しく理解できずに誤った修正を繰り返す現象です。何度指摘しても直らないAIに対し、開発者が苛立ちを露わにするコメントも記録されており、対話による修正プロセスの難しさを物語っています。
4. AIエージェント活用のためのヒントと今後の展望
ここまでのデータ分析から見えてくるのは、「AIは万能な魔法使いではないが、使い方次第で強力な味方になる」という現実です。現時点での限界を理解し、AIエージェントをチームの一員として機能させるための重要な指針をまとめます。
- タスクの切り出し:適材適所を徹底する
AIエージェントには、ドキュメントの更新、CI設定、ビルド構成の修正といった「スコープが明確で孤立したタスク」を任せるのが最も効果的です。一方で、パフォーマンス改善や複雑なバグ修正など、システム全体への深い理解を要するタスクについては、AIの成功率は著しく低下します。当面の間、こうした領域では人間のエンジニアによる設計と介入が不可欠です。 - 「空気を読む」能力の補完
今回の分析で明らかになった失敗の多くは、コード生成能力の不足よりも、プロジェクトの文脈(既存のPR、ブランチ戦略、貢献ガイドラインなど)を理解できない「協調性の欠如」に起因しています。重複PRや不要な機能提案を防ぐため、人間側が事前に「今、何が必要か」という文脈を明確に与えるか、AIの提案がプロジェクトの現状と矛盾していないかを確認するプロセスが必要です。 - 運用上の鉄則:小さく、確実に
AIによるPRを成功させる鍵は、「変更を小さく保つこと」です。大規模な変更はレビュー負荷を高め、拒否されるリスクを跳ね上げます。タスクを局所的な変更に分解し、PR作成前に必ずCI(自動テスト)を通過させるワークフローを確立することで、マージ率は格段に向上するはずです。

AIエージェントが真に自律的な貢献者となるためには、技術的なスキルだけでなく、開発チームの「阿吽の呼吸」を理解する社会技術的な進化が待たれます。
おわりに
AIコーディングエージェントは、ドキュメント更新やCI設定など特定のタスクにおいて高い有用性を示していますが、自律的な貢献者としてはまだ発展途上にあります。特に課題として浮き彫りになったのは、コードを書く技術力以上に、「プロジェクト全体の文脈」を理解する能力や、重複作業の回避、指示への正確な追従といったチーム開発における「社会技術的(Socio-technical)」な協調性の不足でした。
したがって、現時点での最適解は、AIを「自律した開発者」として放置するのではなく、人間が適切に監督し、スコープを限定したタスクを処理させるツールとして活用することです。AIが真のチームメイトへと進化する過程において、どのように彼らをマネジメントしていくかが、開発効率を左右する鍵となります。
More Information
- arXiv:2601.15195, Ramtin Ehsani et al., 「Where Do AI Coding Agents Fail? An Empirical Study of Failed Agentic Pull Requests in GitHub」, https://arxiv.org/abs/2601.15195
関連記事

BERT-as-a-Judge: LLM評価の精度と効率を両立する新手法
LLMを活用したシステム開発において、モデルの生成した回答が正しいかを正確に評価するプロセスは、システムの信頼性を担保する上で非常に重要です。従来、回答の判定には正規表現(Regex)などを利用した字面の一致に頼る手法が […]

Efficient-SAM2: セグメンテーションの高速化と効率化
Segment Anything Model 2 (SAM2) は、画像や動画のセグメンテーションにおいて非常に強力な性能を発揮する基盤モデルです。すでに実務でMLシステムへ組み込もうと検討された方も多いのではないでしょ […]

GPyTorch ではじめる深層ガウス過程入門
ガウス過程(GP: Gaussian Process)は、関数そのものに確率分布を定義するノンパラメトリックなモデルです。このモデルの最大の強みは、単なる予測値だけでなく、その不確実性(信頼区間)を定量的に示せる点にあり […]