機械学習における分布シフト(分布外データ)への対応
機械学習(ML)モデル、特に深層ニューラルネットワーク(DNN)は、コンピュータービジョンや自然言語処理といった多岐にわたる分野で、これまでにない成功を収めています。これらのモデルは通常、i.i.d.(独立同分布)という前提の下で訓練データ内の統計的相関を利用し、非常に高い性能を発揮します。しかし、現実世界でモデルを運用する際には、このi.i.d.仮説が常に成り立たず、データ分布の変化(分布シフト)が発生することが多々あります。
このような分布シフトは、モデルの精度を著しく低下させ、その予測結果を信頼できないものにするという重大な課題を引き起こします。特に、医療診断や自動運転車のように安全性に関わる重要なシステムにおいては、これらの脆弱性に対処することが不可欠です。本記事では、この分布シフト、特に「共変量シフト」と「概念/意味的シフト」という2つの主要なタイプに焦点を当て、その検出、測定、そして緩和に向けた様々なアプローチについて解説していきます。
分布シフトとは?
従来の機械学習モデル、特に深層ニューラルネットワーク(DNN)は、訓練データとテストデータがi.i.d.(独立同分布)であるという基本的な仮定の下で動作することで、コンピュータビジョンや自然言語処理などの幅広い分野で目覚ましい成功を収めてきました。しかし、現実世界でモデルを運用する際には、このi.i.d.仮説が常に成り立つとは限らず、データ分布の変化(分布シフト)が発生することが多々あります。このような分布シフトは、サンプル選択の偏り、非定常的な環境、データ生成メカニズムに内在する特殊性など、いくつかの要因によって引き起こされる可能性があります。
分布シフトが発生すると、モデルの精度は著しく低下し、その予測結果が信頼できなくなるという重大な課題が生じます。例えば、訓練データから学習した知識が、実際のテスト時に遭遇する条件と異なる条件下でサンプリングされている場合があります。この脆弱性は、特に医療診断や自動運転車、産業監視といった安全性に関わる重要なシステムにおいて、誤った予測が深刻な結果を招く可能性があるため、対処が不可欠です。例えば、ある病院のデータで訓練された医用画像モデルが、データ取得デバイス、患者の人口統計、画像プロトコルの違いにより、別の病院のスキャンでうまく機能しないことがあります。

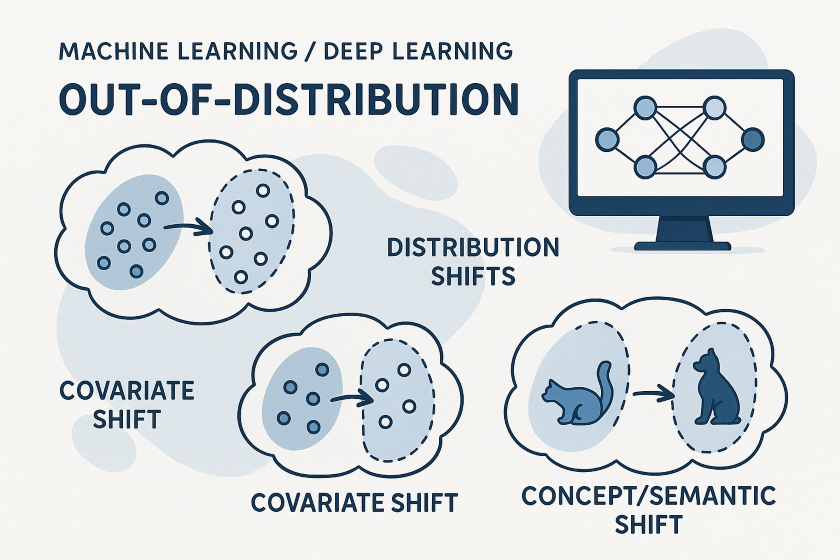
データ分布の変化は、図1に示すように、訓練データとテストデータの間の統計的特性が異なる場合に発生します。このような分布シフトを形式化し、結合確率分布 (\(P(X,Y)\)) を、以下の2つの主要な構成要素に分解して説明します。
$$
P(X,Y) = P(X) \cdot P(Y|X)
$$
この分解に基づき、主に以下の2種類の分布シフトが定義されます。
共変量シフト(Covariate Shift)
共変量シフトは、特徴空間におけるデータ分布が変化する現象を指します。これは、訓練データの入力特徴(共変量)の分布がテストデータのそれと異なる一方で、入力が与えられたときの出力の条件付き分布(\(P(Y|X)\))は変化しない場合に発生します。数学的には、\(P^{tr}(X) \neq P^{te}(X)\) かつ \(P^{tr}(Y|X) = P^{te}(Y|X)\) と表現されます。
例えば、訓練データには草の前に座っている犬の画像が含まれているが、テストデータ(図1の青色でハイライトされた部分)では、犬がレインコートを着て暗い背景の前にいる場合がこれに該当します。この場合、犬であるという「ラベル」は変わらないものの、犬の「見た目(特徴)」が大きく変化しています。このような状況下では、モデルは訓練データから学習した見せかけの相関関係を捉えてしまい、ロバストな特徴を見落とすことで、新しいデータに対する汎化性能が低下する可能性があります。
概念/意味的シフト(Concept/Semantic Shift)
概念/意味的シフトは、入力と出力の関係(\(P(Y|X)\))そのものが変化する現象を指します。これは、入力変数の周辺分布(\(P(X)\))が変化するかどうかにかかわらず発生する可能性があります。数学的には、\(P^{tr}(Y|X) \neq P^{te}(Y|X)\) と表現されます。このタイプのシフトは、時間とともにデータの複雑で動的な性質により、新しい概念(例:新しいオブジェクトカテゴリ)がいつでも出現する可能性があるために発生します。
例えば、犬と猫のカテゴリで訓練された二値分類器が、突然キツネを見た場合がこれに当たります(図1の赤色でハイライトされた部分)。犬とキツネの共変量は類似性を持つかもしれませんが、それらは完全に異なるセマンティクス(意味)を表します。従来の機械学習アルゴリズムの「閉空間仮定」は、訓練セットに存在しないクラスがテストセットに含まれるオープンな世界では成り立ちません。
OODリスクの最小化
これらの分布シフトに直面すると、経験的リスク最小化(ERM)という従来の訓練フレームワークは、訓練データ内の統計的相関を利用して高い性能を発揮するものの、分布外のシナリオを考慮しないため、最適な汎化性能や予測性能を達成できません。モデルが実世界でロバストに機能するためには、このERMの枠組みを超えて、OOD(Out-Of-Distribution)入力に対応する必要があります。
一般に、テストデータが訓練データとOODである場合\(D^{tr}(X,Y) \neq D^{te}(X,Y)\)、OODリスク \(R_{OOD}\) を最小化することが目的になります。これは、共変量シフト下でのリスク \(R_{cov}(f)\) と、意味的シフト下でのリスク \(R_{sem}(f)\) を同時に最小化することに等しいと述べています。
$$
\underset{f}{\operatorname{arg\,min}}\, R_{\text{OOD}}(f) = \underset{f}{\operatorname{arg\,min}}\, R_{\text{cov}}(f) +
\underset{f}{\operatorname*{arg\,min}}\, R_{\text{sem}}(f)
$$
このことから、現実世界での機械学習モデルの信頼性を確保するためには、これら二つの主要な分布シフトに包括的に対処するアプローチが不可欠であることが理解できます。
分布シフトに対するアプローチ
機械学習モデル、特に深層ニューラルネットワークは、訓練データとテストデータが同じ分布に従うというi.i.d.(独立同分布)の仮定のもとで高い性能を発揮する一方で、現実世界で遭遇するデータ分布の変化(分布シフト)に対しては脆弱性を示します。このような分布シフトは、データの収集プロセスのバイアスや、環境の時間的・空間的な非定常性など、さまざまな要因によって引き起こされる可能性があります。
このような分布シフトに対応するため、多岐にわたる研究とアプローチが提案されてきました。これらの方法は、主に共変量シフト(入力特徴の分布の変化)と概念/意味的シフト(入力と出力の関係性の変化)という2つの主要なタイプに応じて分類されます。これらのアプローチは、モデルが未知のデータに遭遇した際に、その性能の低下を防ぎ、予測の信頼性を高めることを目指しています。
共変量シフト緩和方法
共変量シフトとは、入力特徴(共変量)の分布が訓練時とテスト時で異なるにもかかわらず、入力が与えられたときの出力の条件付き分布(\(P(Y|X)\))は変わらない現象を指します。このシフトを緩和するために、以下の手法が用いられます。
転移学習(Transfer Learning, TL)
転移学習は、データが豊富に存在するソースドメインから学習した知識や表現を、データが限られた、しかし類似性のあるターゲットドメインのタスクに適用することで、モデルのパフォーマンスを向上させる手法です 。このアプローチの主な目的は、ターゲットドメインで新たに必要となるラベル付きデータの量を削減し、データ収集のコストを回避することにあります 。過去の研究では、特定のモデルの一部をタスク間で転移させることに焦点が当てられていましたが 、近年ではデータ分布の変化、特に共変量シフトへの対応に多くの研究が集中しています 。転移学習では、特徴量やラベルを位置・スケールシフトによって変換することでシフトに対応したり 、条件付きシフト下での回帰タスクにおいて、予測誤差を減らしつつ条件付き分布の全体的な特性を維持するハイブリッド損失関数が提案されたりしています 。また、表現の事前学習を非教師ありで行い、訓練セットと異なる分布のインスタンスへの汎化に役立てる研究もあります 。動的なデータストリームに対しては、少量の新しいデータで正確なモデルを学習する適応的転移学習 や、新しいドメインの訓練データが順次到着することを仮定するオンライン転移学習 といった派生手法も存在します。
ドメイン適応(Domain Adaptation, DA)
ドメイン適応は、訓練データとテストデータの分布の不一致によって生じるモデル性能の低下に対処する、転移学習の特定のサブセットです 。その主要な目的は、ソースドメインのラベル付きデータを用いて、ドメイン分布間の差異を最小化することで、ターゲットドメインにうまく汎化できるモデルを学習することです 。これは、時間とともに変化するデータの統計的特性や、異なるソースから収集された新しいサンプルによって生じるドメインシフトに対応するために重要です 。DAには教師あり、半教師あり、非教師ありの様々なアプローチが研究されています。共変量分布とターゲットデータの条件付き分布の両方のシフトに対応するため、分布のカーネル平均埋め込みに基づくアプローチが提案され、実世界の問題でその有効性が検証されています 。また、ラベル分布が予期せず変化し、新たな概念が出現する可能性のあるオープンセットラベルシフト下でのドメイン適応も研究されており、新規クラスを含むターゲットラベル分布を推定するアプローチが提案されています 。現代のDAの多くは、オープンセットDA、部分的DA、ユニバーサルDA、クラス増分DAのように、ラベル空間の不一致(意味的シフトの側面)にも対処するよう進化しています 。
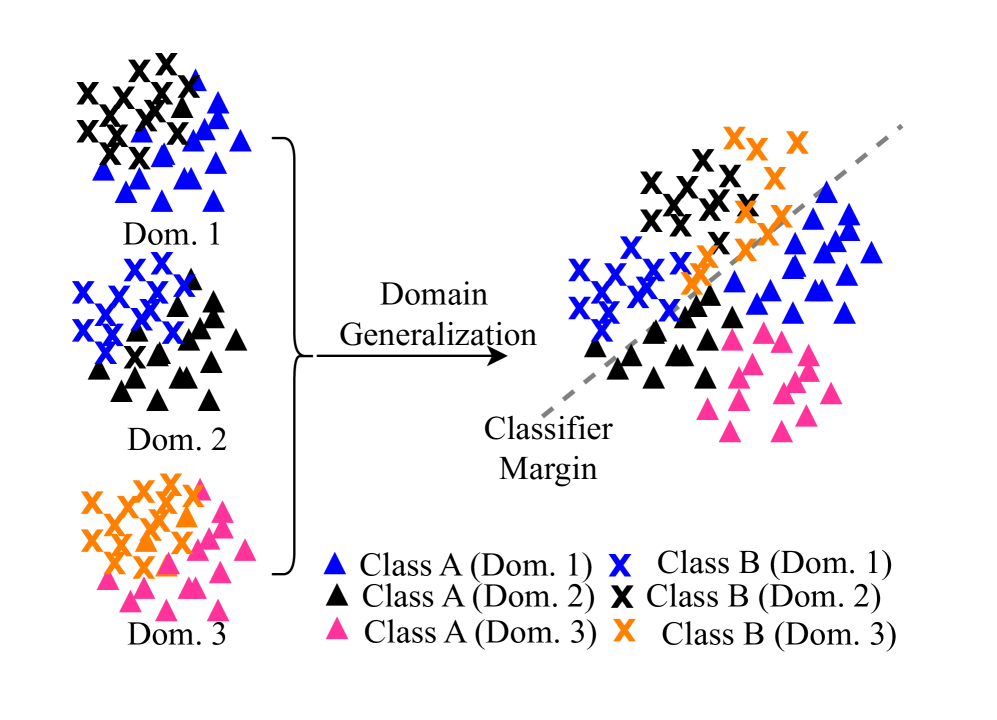
ドメイン汎化(Domain Generalization, DG)
実用的なシナリオでは、あらゆるドメインの訓練データを収集することは不可能です。ドメイン汎化は、一つまたは複数のソースドメインのデータを用いてモデルを訓練し、学習時に完全に未知のターゲットドメインに適切に汎化できる能力を育むことを目指します。このアプローチでは、訓練フェーズ中にターゲットドメインのデータにアクセスすることはありません。ドメイン汎化の主な目標は、ドメインに依存しない(domain-agnostic)表現を学習することで、未知のドメインに対しても良好な汎化性能を発揮することです。モデルの汎化能力は、訓練データの量と多様性に大きく依存するため、データセットが限られている場合には、データ拡張がサンプルを増やし、汎化性を高める費用対効果の高い戦略となります。研究では、ドメイン不変の表現を未知の真のターゲットラベルの代理モデルとして使用し、分布シフト下でのモデルのターゲット誤差を正確に推定できることが示されています 。また、グラフデータにおけるOOD汎化の問題に取り組む研究もあり、グラフにおける異なるタイプの分布シフトに直面しても、最先端のGNNモデルとロバストなグラフ拡張方法の最適な組み合わせが効果的に機能することが示されています 。特に、ラベル割り当ての背後にある因果関係に関する情報を持つサブグラフに焦点を当てることで、因果関係に影響されないグラフ学習を通じてOOD汎化が達成可能であるという主張もあります 。
意味シフト緩和方法
意味的シフト(または概念シフト)は、入力と出力の関係性(\(P(Y|X)\))そのものが変化する現象を指し、新しい概念(例えば、オブジェクトの新しいカテゴリ)がいつでも出現する可能性から生じます。これは、入力分布が変化するかどうかにかかわらず発生し得ます。このシフトを緩和するために、以下の手法が用いられます。
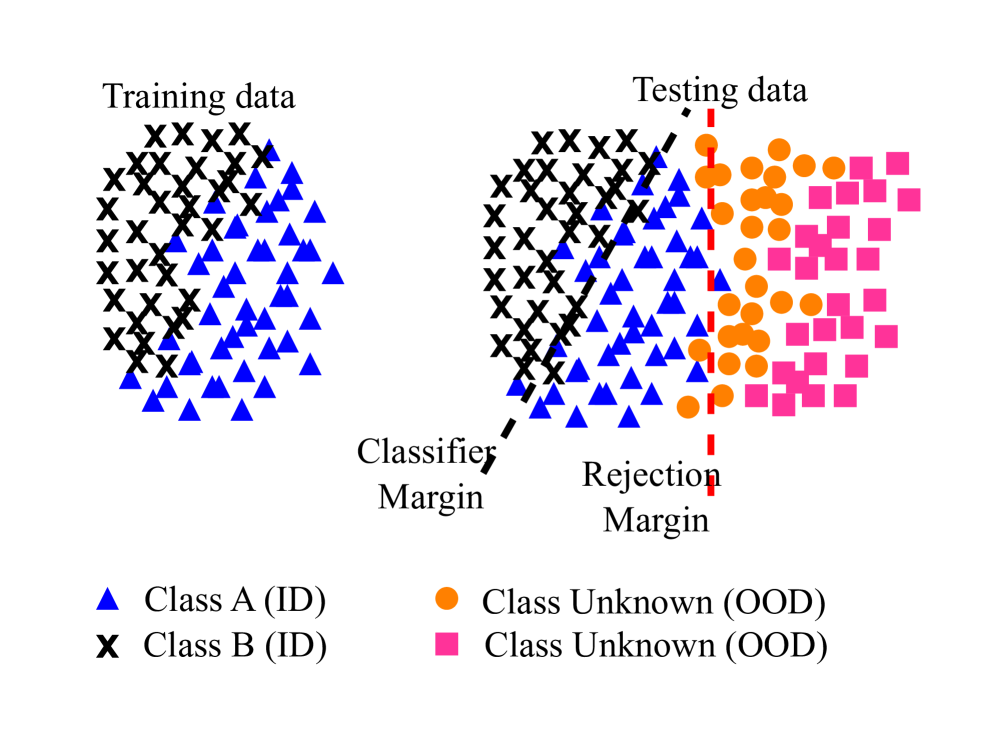
オープンセット認識(Open Set Recognition, OSR)
従来の分類器は、すべてのテストインスタンスを訓練された既知のクラスのいずれかに分類することを要求しますが、現実世界では未知のクラスが出現する「オープンワールド」の状況が頻繁に発生します。オープンセット認識(OSR)は、この課題に対応するために、モデルが既知のカテゴリにサンプルを正確に分類しつつ、学習したものとは無関係で意味のない未知のサンプルを検出して拒否することを可能にします。これは「オープンワールド機械学習」とも呼ばれ 、未知のインスタンスを誤って既知のカテゴリに分類するリスクを排除することを目指します。DNNの最終層に多く用いられるSoftmax層は、訓練された既知の概念の総数に対する確率分布を生成しますが、未知のサンプルに低い確率を割り当てるという単純なしきい値設定では不十分であることが判明しました。これは、未知のサンプルが広大なサンプル空間を持つことや、対抗的なサンプルがモデルを欺き高い信頼度スコアを生成しうるためです。この問題に対処するため、OpenMaxはDNNの最終層に新たな層を導入し、入力が未知の概念に属する可能性を評価することで、効果的に未知の画像を拒否することを可能にしました。また、クラス再構成誤差に基づくスパース表現を用いたOSR研究も行われ、極値理論(EVT)の原理に基づいて、複雑なOSR問題を仮説検定に変換するアプローチが提案されています 。

分布外検出(Out-of-Distribution Detection, OOD-D)
分布外検出は、深層学習分野において、モデルが画像分類やテキスト分類タスクにおいて、訓練分布と異なるセマンティック分布のサンプルに対して過信してしまうという一般的な問題への対策として登場しました。この手法は、入力データをOODスコアに変換するスコアリング関数に依存しており、このスコアは、そのサンプルが訓練データとどの程度異なって分布しているかを示します 。OOD入力は極めて多様であるため、事前の仮定なしにID(In-Distribution)データとOODデータを完全に分離することは困難です。そのため、IDとOODの分布が何らかの特徴空間において十分に異なる(例えば、互いに重複しないサポートを持つ、あるいは最小限の重なりしかない)という仮定がよく用いられます。OOD検出の手法としては、勾配空間からの情報を用いるGradNormがあり、勾配のノルムがIDデータの方がOODデータよりも大きいという仮定に基づいています 。また、展開時にIDサンプルが不足している場合でも、新しい分布に迅速に適応できるような継続的適応OOD検出(CAOOD)フレームワークも開発されています 。多くのOOD研究では、補助データセットを用いてモデルを正則化し、IDとOODデータの判別能力を向上させるアプローチが取られています。この前提は、補助データセットが真のOODデータを表しており、これらを既知の事前情報としてIDデータと共に訓練することで、未知の分布の検出に役立つというものです。代表的な手法としては、Outlier Exposureが挙げられます 。
異常および新規性検出(Anomaly and Novelty Detection, AD/ND)
機械学習システムが、現実世界で遭遇する可能性のあるすべてのオブジェクトを訓練することは不可能なため、テスト時に既知の情報と未知の情報を区別できることが重要です。異常検出と新規性検出は、システム内の異常な概念や新しい概念を認識する問題に対処します。両者には微妙な違いがあり、前者は珍しい、極端な外れ値や特異点を見つけることに焦点を当てる一方、後者は全く新しい概念を発見し、それを意思決定モデルに組み込むことに重点を置きます。しかし、どちらもデータにおける概念の突然の変化(OOD性)を見つけることに共通の関心があります。これらの問題に対処するため、訓練時にしばしば欠落している、あるいは不十分に定義されている新規クラスに対して、ワンクラス分類器が適切な解決策となることが示されています 。GANにインスパイアされたエンドツーエンドのワンクラス分類器のアーキテクチャが提案され、訓練されたインライアと歪んだアウトライア間の分離可能性を大幅に高めることで、新規性検出器として機能します 。また、深層オートエンコーダとパラメトリック密度推定器を組み合わせた包括的なフレームワークが提案され、潜在表現の基礎となる確率分布を自己回帰的に学習し、正規サンプルの再構築と組み合わせることでタスクを効果的に正則化します 。さらに、対照学習(CL)のフレームワークを利用して、類似および非類似のサンプルペアを意味的に対比させることで異常検出を行う研究も注目されています 。

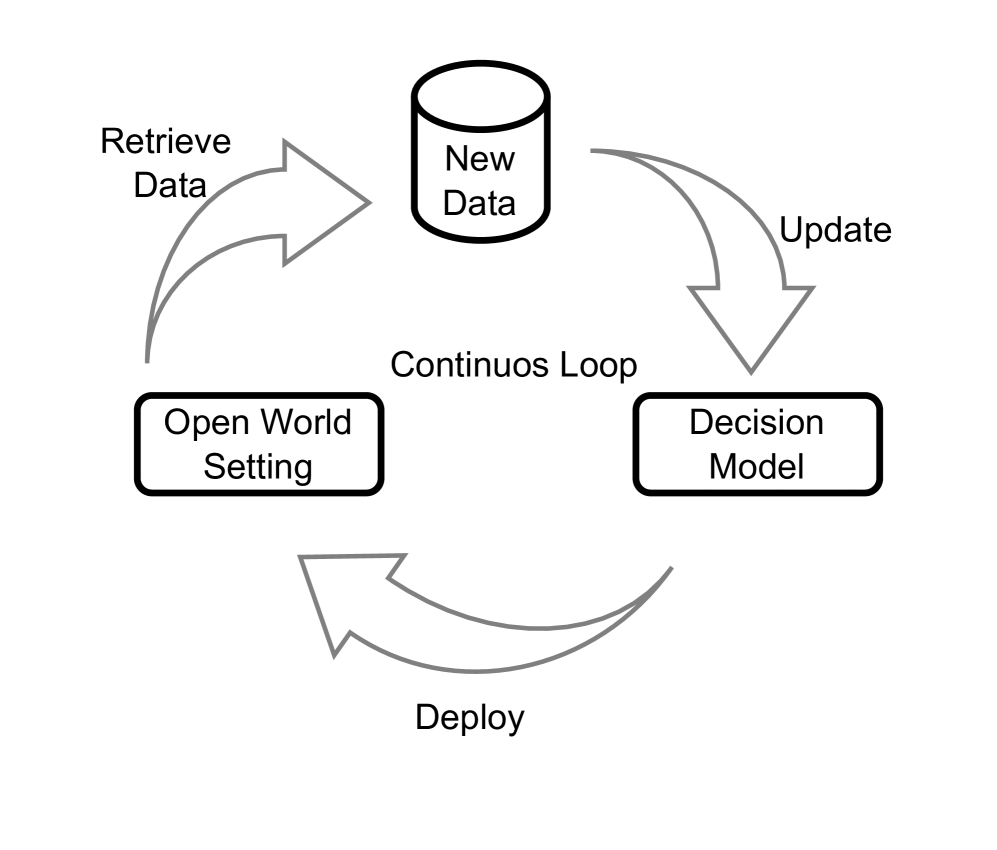
継続学習(Continual Learning, CoL)
人間の学習が絶え間なく変化する環境で優れているのに対し、現在の機械学習システムはバランスの取れた均質なデータに対してのみ効果的に機能します。データが不均質である場合、モデルは性能の著しい低下だけでなく、以前に学習したタスクに対する壊滅的忘却(catastrophic forgetting)現象を示すことがよくあります 。継続学習(CoL)は、学習を停止せず、時間とともにモデルパラメータを更新し知識を蓄積していくことを目指す機械学習アルゴリズムの開発を目標としています 。これは生涯学習(Lifelong Learning)やインクリメンタル学習(Incremental Learning)とも呼ばれます 。時間の経過とともにクラスの特性が突然変化する「概念ドリフト」のようなシフトが現代の動的なデータソースに影響を与える可能性があるため、データストリームマイニングタスクにおいて概念ドリフトシナリオに効果的に適応できるCoLモデルが求められています。継続学習の要件として、モデルが以前のタスクでの性能を維持し、新しいタスクを学習しながら以前の知識を活用し、さらにスケーラブルであることなどが挙げられます 。CoLシステムは、新しい知識の獲得(可塑性)と古い知識の保存(安定性)の両方を維持することが期待されます。壊滅的忘却は安定性の失敗であり、新しい経験が以前のものを上書きしてしまいます。この忘却を緩和するために、脳科学のアプローチから着想を得た過去の経験のリプレイ(replay of past experiences)を用いる手法があります 。また、教師なしドメイン適応と継続学習を組み合わせた教師なしCoLの研究も行われており、エピソード記憶のリプレイとバッファ管理、コントラスト損失を統合することで、モデルの適応性と保持能力を向上させています 。
現状と課題
これまでの調査により、分布シフトへの対応に関するいくつかの重要な洞察が明らかになっています。既存のMLモデル、特に深層ニューラルネットワーク(DNN)は、訓練データ内の微妙な統計的相関関係を利用することで、i.i.d.(独立同分布)仮説の下では優れた性能を発揮してきました。しかし、実世界のデータ分布シフトに対しては脆弱性を示す経験的証拠が増えています。訓練時とは異なる条件でテストデータがサンプリングされると、モデルの精度が阻害され、その結果が信頼できなくなる可能性があります。
モデルの性能と限界
分布シフトを軽減するためのさまざまなアプローチが存在しますが、それぞれの手法が異なるシナリオで優れており、すべての種類のシフトにおいて単一のアプローチが支配的であるわけではありません。例えば、「共変量シフト」(特徴空間の分布が変化し、入力に対するターゲットの条件付き分布は変化しない場合)のシナリオでは、ドメイン汎化手法であるSWADやPromptStylerは、ベンチマークデータセットで従来の経験的リスク最小化(ERM)をしばしば上回ります。一方で、「意味シフト」(入力とターゲット変数の関係が変化する場合)のシナリオでは、OpenMaxやARPLのようなオープンセット認識(OSR)手法が強力な性能を示します。
こうした手法の専門化は、実際のアプリケーションで「複合シフト」に遭遇した際に脆弱性を生じさせます。共変量シフト用に設計された手法が意味シフトに対して限定的な効果しか持たない一方、逆もまた同様です。これは、ERMによって訓練されたモデルが、しばしば訓練データからスプリアスな(見せかけの)特徴を学習して分類を行うためであり、これはサンプルの安定した特性ではありません。このような固有の事実は、偏りのない新しいデータに対してモデルの汎化性能が低下する原因となることがよくあります。
評価の複雑さ
現在の評価プロトコルは、単一のシフトタイプのみに対して手法をテストすることが多く、実践で遭遇する複雑で多面的なシフトに対するモデルの堅牢性を評価することが困難です。これは、MLモデルが限定的な実世界サンプルの知識で訓練される一方で、野外でのテスト時には特徴空間または意味空間において、同様または異なる分布の入力全体に遭遇する可能性があるためです。高次元の実世界データにおけるシフトを検出するための最善の慣行がまだ確定されていないという課題もあります。
理論的・実用的なギャップ
個々のアプローチはそれぞれのドメイン内で強固な理論的基盤を持っていますが、異なる手法を最適に組み合わせる方法や、同時発生するシフトを処理する方法についての理論的理解は限られています。実際、訓練段階でMLモデルが遭遇するテストデータは、訓練分布に厳密に従っていません。テストデータは、共変量シフトまたは意味シフトのいずれかにシフトする可能性があります。従来のMLアルゴリズムの「閉空間」の仮定は、予期せぬ状況が不意に現れるオープンな世界では確かに成り立ちません。
実世界での影響
分布シフトは、モデルの実用アプリケーションにおける性能に深刻な影響を及ぼし、下流タスクの精度を大幅に低下させる可能性があります。この低下は、医療診断、自動運転、故障検出、侵入検出、敵対的防御といった重要なシステムにおける意思決定プロセスに重大な影響を及ぼす可能性があります。例えば、ある病院のデータで訓練された医療画像モデルが、データ取得デバイス、患者の人口統計、または画像プロトコルの違いにより、別の病院のスキャンではうまく機能しないことがあります。
将来の展望と研究の方向性
MLモデルがデータ分布シフトに効果的に対応できるよう開発するためには、多くの研究分野にわたる協調的な努力が必要です。
- 統合されたアプローチの必要性: 共変量シフトと意味シフトの両方を同時に検出し、適応し、汎化できるモデルの開発が、今後の重要な研究方向性の一つです。現在の個別のアプローチの限界を乗り越え、より包括的な戦略を実現することが求められています。
- 強化された評価とベンチマーク: 共変量シフトと意味シフトの両方を同時に検出し、適応し、汎化できるモデルの開発が、今後の重要な研究方向性の一つです。現在の個別のアプローチの限界を乗り越え、より包括的な戦略を実現することが求められています。
- 学際的な視点: 因果関係 や認知科学 などの分野からの洞察、そしてドメイン専門家との協力は、データ分布シフト問題に対処するための新しいフレームワークを効果的に開発する上で不可欠な要素となり得ます。
- 動的監視システム: システムが実行中にシフトの発生を検出し、適切な緩和戦略を自動的にトリガーできる「ランタイムモニタリング」システムの開発も重要です。これにより、MLモデルが安全性を損なう可能性のある予測を行う前に、それらを特定し破棄することができます。
- LLMのロバスト性: 大規模言語モデル(LLM)の多様なアプリケーションでの展開が増加していることを鑑み、分布シフトに対する回復力を高めることに特化した焦点が必要です。LLMは、入力言語 、ドメイン 、またはタスク分布の変更によって脆弱になります。例えば、訓練されていないスタイルに直面すると、ゼロショット設定ではパフォーマンスが急激に低下することが明らかになっています。また、言語使用パターンが変化し、モデルが学習した相関関係がもはや成り立たなくなった場合(例:以前は否定的な感情を示していた単語が、肯定的なスラングとして採用されるなど)、意味シフトが発生する可能性があります。これらの課題に対処するための戦略には、新しいデータを用いたモデルの再訓練やファインチューニング、プロンプティングや検索によるオンザフライでの調整、不確実性の評価などが含まれます。
おわりに
今回は、機械学習モデルの訓練段階とデプロイ段階でデータ分布が変化する「分布シフト」という根本的な課題について紹介しました。実世界でのAIシステムを信頼性高く運用するため、このシフトへの対応は不可欠です。
このシフトは、医療診断や自動運転など安全性が重視される応用分野において、モデルの性能を著しく低下させ、その結果に深刻な影響を及ぼす可能性があります。例えば、特定の病院データで訓練された医療モデルが、異なるデータ取得環境の他の病院では機能しない場合などが挙げられます。
分布シフトを相互に関連する課題として包括的に捉え、共変量シフトと意味シフトを同時に処理できる統一フレームワークの必要性が重要です。これは、現実世界の複雑なシフトに対応できる、より適応的で堅牢なAIシステムへの道を開くものです。
今後の研究では、この統一的なアプローチをさらに深化させ、動的監視システムや学際的アプローチの統合を通じて、より信頼性の高い機械学習技術の発展が期待されます。
More Information
- arXiv:2507.21160, Lakpa Tamang, Mohamed Reda Bouadjenek, Richard Dazeley, Sunil Aryal, 「Handling Out-of-Distribution Data: A Survey」, https://arxiv.org/abs/2507.21160
関連記事

BERTopic: 高性能トピックモデリングの概要
近年、大量のテキストデータから有益な情報を抽出するために、トピックモデルが注目されています。トピックモデルは、文書集合に潜在するテーマ(トピック)を発見するための強力なツールであり、自然言語処理、情報検索、テキストマイニ […]
PyTorch Metric Learningではじめる深層距離学習
近年のAI技術の発展において、画像認識、自然言語処理、推薦システムなど、様々なタスクでデータ間の「類似性」を理解し、活用することが重要となっています。このような背景から、入力データを効果的な特徴空間にマッピングし、類似す […]

TruthTorchLMによるLLMのハルシネーション検出
大規模言語モデル(LLM)の目覚ましい進化は生活やビジネスに革新をもたらす一方で、事実に基づかない情報を生成するハルシネーションが問題となっています。特に医療や金融といった高リスクな分野では、LLM出力の信頼性と正確性が […]