QueryGym: LLMベースの Query Reformulation フレームワーク

検索システムの改善において、ユーザーの曖昧な入力意図を補完する「クエリ拡張(Query Reformulation)」は、LLMの登場により劇的な進化を遂げています。しかし、論文で提案される有望な手法も、実装コードが散逸していたり、再現性が低かったりと、実務への導入には高いハードルがあります。「最新の手法を比較検証したいが、それぞれの基盤整備に時間を取られすぎる」——そんな課題を抱えることも少なくありません。
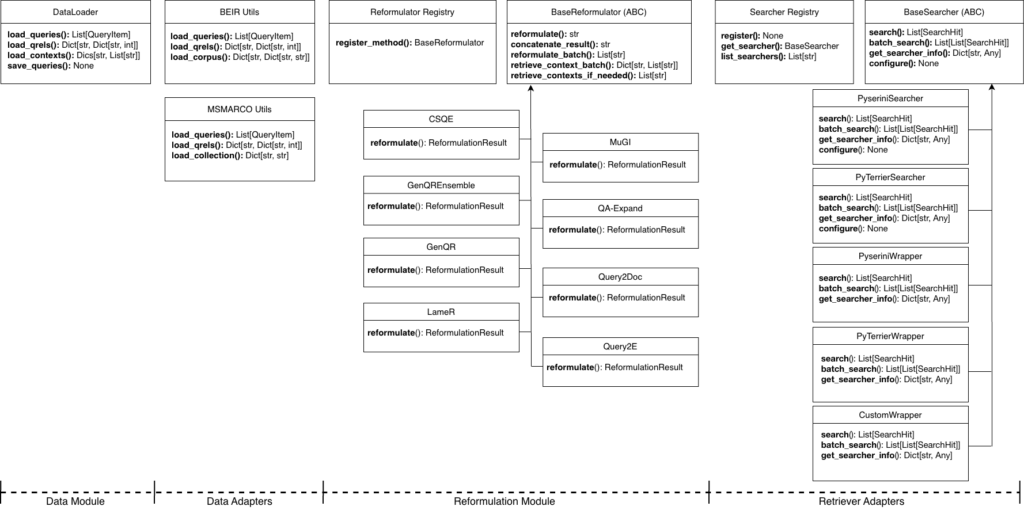
そこで、この記事では、これらの課題を一挙に解決するPythonツールキット「QueryGym」を紹介します。QueryGymは、GenQRやQuery2Docといった主要な書き換えアルゴリズムを統一的なインターフェースで提供する、軽量かつ拡張性の高いフレームワークです。今回は、そのアーキテクチャの設計思想から、既存の検索パイプライン(PyseriniやPyTerrier等)への統合方法について解説します。
QueryGymのアーキテクチャと設計思想
QueryGymの最大の強みは、特定のモデルや検索エンジンに依存しない「モジュラー設計」にあります。研究用の実験コードでありがちな「特定データセット専用の実装」とは異なり、以下のコンポーネントを自由に組み合わせ、既存のプロダクション環境や実験パイプラインへ柔軟に組み込むことが可能です。
- 統一されたReformulationインターフェース GenQRやQuery2Docなど、本来実装や入力形式が異なる多様なアルゴリズムを、共通のAPI(BaseReformulator)を通して操作可能です。入出力フォーマットが標準化されているため、メソッドを切り替える際もコードの書き換えは最小限で済み、バッチ処理による大量データの実験や結果の保存も効率的に行えます。
- 検索エンジン非依存(Retrieval-Agnostic)な設計 検索バックエンドとの連携は疎結合に保たれています。PyseriniやPyTerrierといった学術界で標準的なライブラリとシームレスに連携できるほか、抽象基底クラスであるBaseSearcherを継承することで、自社独自の検索システムやElasticsearchなどのバックエンドも容易にラップして統合可能です,。これにより、検索エンジンを変更することなく、クエリ拡張ロジックのみを差し替えて検証することができます。
- OpenAI互換のLLMクライアント LLMの呼び出しはOpenAI互換APIで統一されています。これにより、OpenAIの公式APIはもちろん、Azure OpenAI Serviceや、vLLM、OllamaなどでホストしたローカルLLMにも設定一つで切り替え可能です。機密情報を扱うため外部APIを利用できないオンプレミス環境でも、コードを変更することなく導入できる点は、実務において大きなメリットとなります。
サポートされている主要なアルゴリズム
QueryGymには、最新の研究で提案された主要なクエリ拡張手法が実装されています。これらは大きく、「LLMの内部知識のみを利用する手法(Context-Free)」と、「検索結果をコンテキストとして利用する手法(Context-Dependent)」の2つに分類され、プロジェクトの要件や計算リソースに応じて柔軟に選択可能です。
コンテキスト不要な手法(Zero-shot / Few-shot)
初期検索を行わず、LLMの知識だけでクエリを拡張します。検索エンジンへの負荷が少なく、導入が容易な点が特徴です。
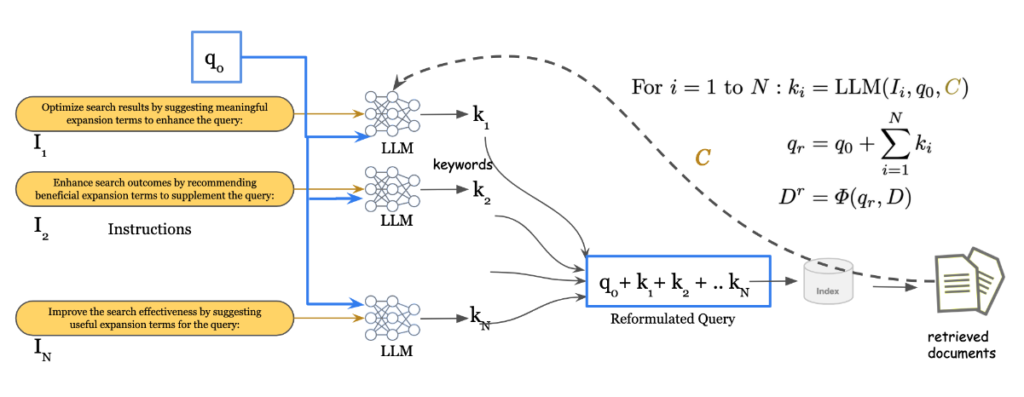
- GenQR / GenQR Ensemble: LLMを用いてクエリに関連するキーワードを生成し、拡張する手法です。特に「GenQR Ensemble」では、複数の異なるプロンプト指示を用いてキーワードを生成・統合することで、単一のプロンプトよりも多様で堅牢な拡張を実現します。
- Query2Doc: クエリに対する「擬似的なドキュメント(Pseudo-Document)」を生成させる手法です,。関連語を単に羅列するのではなく、文脈を持った文章を生成してクエリに加えることで、語彙の不一致(Vocabulary Mismatch)を解消し、高密度な検索(Dense Retrieval)においても高い効果を発揮します。
- Query2E: クエリから主要なエンティティ(固有表現など)を抽出し、それに関連するエンティティを拡張することで検索意図を明確化します。
コンテキスト依存の手法(Retrieval-Augmented)
一度検索を行った結果(Context)をLLMに入力し、その内容に基づいてクエリを洗練させます。処理コストは上がりますが、外部知識を参照するため、ハルシネーション(幻覚)のリスクを抑制しやすい傾向があります。
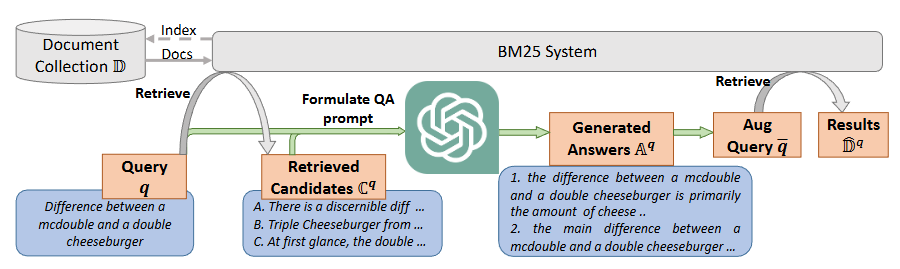
- LameR: 初期検索で得られた上位ドキュメントを参照し、クエリの回答となり得る適切なパッセージをLLMに合成させます。生成されたパッセージをクエリとインターリーブ(交互に配置)させることで、再ランキング(Re-ranking)に強い入力を構築します。
- CSQE: 検索されたドキュメントの中から、生成ではなく「抽出」を行うアプローチです。ドキュメント内の重要な一文を特定してクエリを拡張するため、正確性が求められる検索タスクに適しています。
実装と具体的な使用例
QueryGymは、複雑な研究手法を「数行のPythonコード」で実行できるよう設計されています。ここでは、環境構築から基本的なクエリ拡張、そして検索エンジンと連携した手法まで、具体的な実装フローを解説します。
基本的なセットアップ
環境構築は非常にシンプルです。PyPIから直接インストールするか、依存関係が含まれたDockerイメージを利用できます。
pipによるインストール
最小限の構成で始める場合、以下のコマンドで完了します。
$ pip install querygym
# PyseriniやBEIRなど特定の機能を使う場合はオプションを指定
$ pip install querygym[pyserini,beir]Dockerによるクイックスタート
GPU環境やPyseriniのJava依存関係(OpenJDK等)を気にせず即座に動かしたい場合は、公式のDockerイメージが推奨されます。
$ docker run -it --gpus all ghcr.io/ls3-lab/querygym:latestコード例1:基本的なクエリ書き換え (Context-Free)
まずは、外部知識(検索結果)を必要としない基本的な手法(例: GenQR Ensemble)の実装です。TSVファイルからクエリを読み込み、拡張して保存するまでの流れは以下の通りです。
import querygym as qg
# 1. データの読み込み (TSVやJSONL形式に対応)
queries = qg.load_queries("data/queries.tsv")
# 2. Reformulatorの作成
# 手法名(method_name)と使用するモデルを指定します
reformulator = qg.create_reformulator(
method_name="genqr_ensemble",
model="gpt-4",
params={"repeat_query_weight": 3} # 元のクエリを繰り返す重みなどのパラメータ
)
# 3. バッチ実行 (プログレスバーが表示されます)
results = reformulator.reformulate_batch(queries)
# 4. 結果の保存
qg.DataLoader.save_queries(
[qg.QueryItem(r.qid, r.reformulated) for r in results],
"output/reformulated.tsv"
)
コード例2:検索エンジンとの統合 (Retrieval-Augmented)
QueryGymの真価は、既存の検索システムと連携できる点にあります。以下は、Pyseriniのインデックスを利用して検索を行い、その結果(コンテキスト)を用いてクエリを再構成するLameR手法の実装例です。
from pyserini.search.lucene import LuceneSearcher
import querygym as qg
# 1. Pyseriniのサーチャーを準備 (既存のインデックスを使用)
searcher = LuceneSearcher.from_prebuilt_index('msmarco-v1-passage')
searcher.set_bm25(k1=0.9, b=0.4)
# 2. QueryGym用にラッパーで包む
# これにより、Pyserini以外の検索エンジンでも同じインターフェースで扱えます
wrapped_searcher = qg.wrap_pyserini_searcher(searcher, answer_key="contents")
# 3. コンテキスト依存の手法(LameR)を初期化
reformulator = qg.create_reformulator(
"lamer",
model="gpt-4",
params={
"searcher": wrapped_searcher, # ラップしたサーチャーを渡す
"retrieval_k": 10, # コンテキストとして利用する上位文書数
"gen_passages": 5 # 生成するパッセージ数
}
)
# 4. 実行 (内部で自動的に検索→コンテキスト取得→生成が行われます)
results = reformulator.reformulate_batch(queries)
ローカルLLMの利用 (On-Premises / Cost-Effective)
機密データを扱う場合やコストを抑えたい場合、OpenAIのAPIではなく、自社でホストしているローカルLLM(Llama 3, Mistralなど)を利用することも容易です。QueryGymのクライアントはOpenAI互換であるため、base_urlとapi_keyを指定するだけで切り替え可能です。
reformulator = qg.create_reformulator(
"genqr",
model="meta-llama/Meta-Llama-3-8B-Instruct", # ローカルモデル名
llm_config={
"base_url": "http://localhost:8000/v1", # vLLMやOllamaのエンドポイント
"api_key": "EMPTY", # 必要に応じて設定
"temperature": 0.7
}
)
プロンプト管理と再現性の確保
LLMアプリケーションの開発において、コード内に散在する「ハードコーディングされたプロンプト」は、保守や改善を妨げる大きな要因となります。QueryGymは、エンジニアリングの観点からこれらの管理コストを最小化し、実験の再現性を担保するための機能を備えています。
- Prompt Bank(プロンプトバンク)による一元管理: QueryGymでは、プロンプトをPythonコードから分離し、YAML形式のファイル(Prompt Bank)として一元管理する設計を採用しています。各プロンプトには一意のIDに加え、バージョン、作成者、タグ、説明といったメタデータを付与できます。これにより、Gitを用いたバージョン管理が容易になるだけでなく、チーム内での共有や、設定ファイル内のIDを変更するだけで異なるプロンプトのA/Bテストを実施することが可能になります。
- 実験の再現性とトレーサビリティ: 学術研究やプロダクション運用では、結果の再現性が不可欠です。QueryGymは、LLMの確率的な挙動を制御するためのシード値(Seed)固定をサポートしており、同一条件下での出力を保証します。また、実験実行時には、使用したプロンプトのバージョン、モデルのハイパーパラメータ、生成時の設定などが自動的にメタデータとして記録されます。これにより、「どの設定でその結果が得られたのか」を後から確実に追跡(監査)できるため、信頼性の高い開発サイクルを回すことができます。
このように、QueryGymは単なるツールキットにとどまらず、LLMを用いた検索システム開発における「Ops(運用・管理)」のベストプラクティスを自然と適用できる基盤となっています。
おわりに
QueryGymは、LLMを用いたクエリ書き換え技術を、研究段階の実験から実務レベルのエンジニアリングへと昇華させる強力なツールキットです。
最大の特徴である「統一されたAPI」と「検索エンジン非依存の設計」により、既存のMLパイプラインへの統合コストを劇的に下げることができます。これは、最新のRAG(Retrieval-Augmented Generation)システムの精度向上や、検索エンジンの改善に取り組む際に、極めて実用的な選択肢となり得ます。
導入の第一歩として、まずは公式リポジトリのExampleコードや、環境構築不要なDockerイメージを利用して、その手軽さと効果を体感してみてください。最新のアルゴリズムがもたらす検索体験の進化を、ぜひ手元のデータで確認してみましょう。
More Information
- arXiv:2511.15996, Amin Bigdeli et al., 「QueryGym: A Toolkit for Reproducible LLM-Based Query Reformulation」, https://arxiv.org/abs/2511.15996
関連記事

GluonTS入門: Pythonによる確率的時系列モデリング
時系列予測とは、過去の観測データに見られるパターンが将来も継続するという前提に基づき、未来の値を予測する技術です。これは、電力網における需給バランスの維持や、レストランや小売業における在庫の最適化など、ビジネスの様々な場 […]

X-ANFISではじめる適応型ニューロファジィ推論システム入門
AI技術の進化はめざましく、特に深層学習は画像認識から自然言語処理まで、多様な分野で驚異的な成果を上げています。その強力な予測能力は目を見張るものがありますが、時に「なぜそのような判断を下したのか」という意思決定プロセス […]

YOLO26: 次世代のエッジAI物体検出
2026年1月、Ultralytics社はYOLOシリーズの最新版となる「YOLO26」をリリースしました。YOLOv8やYOLO11といった歴代モデルの正統進化でありながら、今回の設計思想は「エッジデバイスでの推論効率 […]