Nested Learning: Deep Learning の新たなパラダイム

ChatGPTやGeminiをはじめとする大規模言語モデル(LLM)は、人間が書いたかのような自然な文章を生成し、複雑な質問にも答えるなど、驚異的な能力を見せています。しかし、その万能に見える能力の裏で、根本的な問題を抱えています。それは、一度学習を終えると、その知識がほぼ固定されてしまい、新しい情報を継続的に学び続けることができない、という「静的な」性質です。
この課題に対し、Google Research が発表した論文「Nested Learning: The Illusion of Deep Learning Architectures」では、全く新しい視点を提供します。Nested Learning(NL)は、ディープラーニングモデルとその訓練プロセスを、それぞれが独自の勾配フロー(コンテキストフロー)を持つ階層的な最適化問題のシステムとして捉えることで、深層学習に新たな視点を提供します。
この記事では、NLの学習メカニズムやその可能性について解説していきます。
なぜAIは学び続けられないのか? ― 既存モデルが抱える「記憶」の課題
ChatGPTやGeminiをはじめとする大規模言語モデル(LLM)は、人間が書いたかのような自然な文章を生成し、複雑な質問にも答えるなど、驚異的な能力を見せています。しかし、その万能に見える能力の裏で、根本的な問題も抱えています。それは、一度学習を終えると、その知識がほぼ固定されてしまい、新しい情報を継続的に学び続けることができない、という「静的な」性質です。
この課題をより身近に理解するために、ある神経科学の概念を借りてみましょう。現在のLLMの記憶システムは、順向性健忘症(Anterograde Amnesia)—新しい長期記憶を形成できなくなる症状—に非常によく似ている、と論文では指摘されています。
LLMが持つ知識は、大きく分けて2種類しかありません。
- 膨大な過去の記憶: 事前学習(Pre-training)の段階で得た、いわば「刷り込まれた」知識。これはモデルのパラメータ(MLP層など)に固定されています。
- ごく短期の現在の記憶: プロンプトとして与えられた、コンテキストウィンドウ内の情報。これは会話が終われば消えてしまいます。
つまり、LLMは人間との対話を通じて新しい事実や経験に触れても、それを自身の知識ベースである「長期記憶」に統合し、恒久的な学びへと昇華させることができません。
この状態は、人間の記憶形成プロセスと比較すると、より鮮明になります。人間の脳は、新しい経験を記憶に定着させるために、少なくとも2段階のプロセスを踏むと考えられています。まず、学習直後に起こる素早い「オンライン統合(Synaptic Consolidation)」があり、その後、主に睡眠中に、その記憶が脳の異なる領域へと転送・再編成される「オフライン統合(Systems Consolidation)」が行われます。
現在のLLMに決定的に欠けているのは、この最初のステップである「オンライン統合」のメカニズムです。新しい情報が長期記憶へと向かうための、いわば最初のゲートウェイが存在しないのです。
もちろん、これまでもモデルの層を深くしたり、パラメータ数を増やしたりすることで、モデルの表現力を高める研究は進められてきました。しかし、こうしたアプローチだけでは、新しいタスクへ迅速に適応したり、未知の状況に対応したりする「継続的な学習能力」そのものを向上させることは困難です。
では、どうすればAIは「記憶喪失」の状態を乗り越え、真に学び続ける存在になれるのでしょうか。その鍵は、これまで単なる「訓練テクニック」だと考えていた、モデルの最適化プロセスそのものに隠されています。
Nested Learningの核心 ― すべての計算は「記憶の学習」である
従来のディープラーニングでは、モデルのパラメータを更新する「最適化アルゴリズム」は、学習を効率的に進めるための単なるツールだと考えられてきました。しかし、Nested Learning(NL)は、この常識を覆す画期的な視点を提供します。NLの根本的な主張は、機械学習モデルを構成するすべての要素、すなわちオプティマイザやニューラルネットワーク自体が、自身のコンテキストフローを圧縮する連合記憶システム(Associative Memory System)である、という点です。
「学習」と「記憶」の再定義
AIの文脈では、「学習(Learning)」と「記憶(Memorization)」という言葉はしばしば混同されがちです。しかし、NLは神経心理学の知見に基づき、これらを明確に区別します。
- 記憶(Memory): ある入力によって引き起こされる、単なる神経(ニューラル)の更新を指します。これは、情報が一時的に保持される状態と考えることができます。
- 学習(Learning): その無数の記憶の中から、効果的で有用な記憶だけを獲得し、統合していくプロセスを指します。
この定義に基づくと、上で説明したLLMの「順向性健忘症」は、新しい入力(記憶)は絶えず受け取っているものの、それを有用な知識(学習)として長期的に定着させるメカニズムが欠けている状態である、と理解できます。
連合記憶としてのモデルと最適化の分解
NLでは、連合記憶 \(M\) を、キーの集合 \(K\) と値の集合 \(V\) の間のマッピングを学習する演算子として定義します。この学習プロセスは、目的関数 \(\tilde{L}(\cdot; \cdot)\) を最小化する最適化問題として定式化されます。
$$
M^* = \underset{M}{\text{arg min}} \tilde{L}(M(K); V) \quad
$$
ここで、数式中の各シンボルは以下を示しています。
- \(M\): 連合記憶(モデルのパラメータや状態)
- \(K\): キーの集合(入力データ、特徴量など)
- \(V\): 値の集合(ターゲット、出力など)
- \(\tilde{L}\): 目的関数(マッピングの品質を測る尺度)
この最適化プロセスは、ネットワーク \(M(\cdot)\) が、キーと値のマッピングを自身のパラメータに圧縮し、より低次元の空間で表現しようとする訓練プロセスとして解釈できます。つまり、モデルはデータを「記憶」し、その記憶を効率的に「学習」しているのです。
さらにNLは、モデルの訓練プロセスとアーキテクチャのコンポーネントを、その更新頻度(Update Frequency)に基づいて階層的な最適化問題として分解します。
定義(更新頻度): コンポーネント \(A\) の頻度 \(f_A\) は、単位時間あたり(データポイント一つあたりの処理)の更新回数として定義されます。この頻度に基づいて、コンポーネントは「レベル」に順序付けられ、レベルが高いほど、更新頻度は低い(遅い)と定義されます。

この考え方に基づくと、これまで単一の最適化問題として捉えられていたアルゴリズムも、複数のレベルを持つ入れ子構造として見えてきます。
- 運動量付き勾配降下法(Gradient Descent with Momentum)の分解例:
このアルゴリズムは、内側レベルと外側レベルを持つ2レベル最適化プロセスとして解釈できます。 - 内側レベル: 運動量項 \(m_{t+1}\) は、過去の勾配を自身のパラメータに圧縮するキーレスの連合記憶として最適化されます。これは、勾配情報を効率的に「記憶」する役割を担います。
- 外側レベル: 主要な重み \(W_{t+1}\) は、内側レベルで学習された記憶値(運動量項)を用いて更新されます。これは、より「遅い」時間スケールでモデルの知識を「学習」するプロセスです。
- 線形アテンションの分解例:
Transformerの基礎となる線形アテンションのメモリ更新(\(M_{t} = M_{t-1} + v_t k_t^{\top}\))もまた、キーと値のマッピングを圧縮するための行列値の連合記憶 \(M\) の最適化プロセスと等価です。これは、以下の2レベルの最適化プロセスとして見なされます。 - 外側ループ(訓練プロセス): 射影層(\(W_k, W_v, W_q\))のパラメータが勾配降下法によって最適化されます。
- 内側ループ: メモリ \(M_t\) が勾配降下法によって最適化されます。
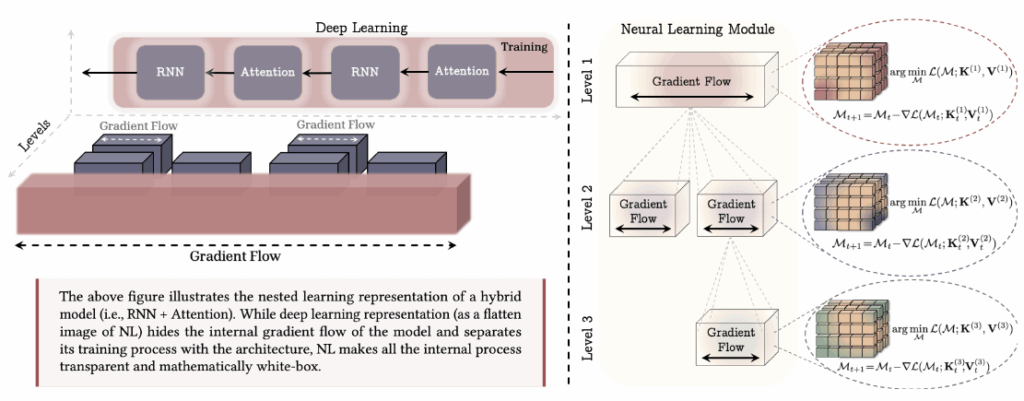
以上のように、NLはディープラーニングの「深さ」を、単なる層の積み重ねではなく、異なる更新頻度を持つ最適化問題の階層として捉え直します。この新しい視点は、AIが真に継続的に学習し、自己改善していくための設計原則を提示していると示唆されます。
新たな設計思想 ― より賢いオプティマイザと記憶システムへ
Nested Learning(NL)のパラダイムシフトは、従来のディープラーニングのコンポーネントを、より表現力の高い学習モジュールとして再設計する道筋を示します。上で述べたように、最適化アルゴリズム自体が「記憶を学習するモジュール」であるというNLの知見は、AIの能力を飛躍的に向上させる新たな設計思想へと繋がります。
深層オプティマイザ(Deep Optimizers)の設計
運動量項が勾配を記憶するメタ記憶モジュールであるというNLの洞察に基づき、より表現力の高いオプティマイザが提案されています。従来の運動量付き勾配降下法では、運動量項はキーレスの連合記憶として機能し、過去の勾配を圧縮していました。しかし、このアプローチには表現力の限界があります。
NLは、この運動量項の内部目的関数を改善することで、記憶(運動量)が限られた容量をより適切に管理し、過去の勾配の系列をより良く記憶できるようになることを示します。例えば、ドット積類似性ではなく、キーと値のマッピング適合度を測る \(\ell_2\) 回帰損失 \(|m \nabla L(\cdot)^\top – P_i|_2^2\) を使用することで、デルタルールに基づく更新則が導出されます。
$$
m_{i+1} = (\alpha_{i+1} I – \nabla L(\cdot)^\top \nabla L(\cdot)) m_i – \eta_t P_i \nabla L(\cdot) \quad
$$
ここで、数式中の各シンボルは以下を示しています。
- \(m_{i+1}\): 次のタイムステップにおける運動量項
- \(\alpha_{i+1}\): 適応的な学習率および運動量率
- \(I\): 単位行列
- \(\nabla L(\cdot)\): 目的関数の勾配
- \(\eta_t\): 学習率
- \(P_i\): 値パラメータ(勾配に対応する値)
この更新則は、記憶(運動量)が過去の勾配の系列をより効果的に管理し、記憶する能力を高めることを可能にします。
さらに、運動量項を線形層(行列値)としてではなく、多層パーセプトロン(MLP)として実装する深層運動量勾配降下法(Deep Momentum Gradient Descent: DMGD)も提案されています。これにより、運動量項は過去の勾配の基礎となる非線形なダイナミクスを捕捉する記憶容量を大幅に増加させることができます。これは、オプティマイザ自体がより「深く」学習し、複雑な勾配パターンを記憶できるようになることを意味します。
連続的記憶システム (Continuum Memory System: CMS)
NLは、長期記憶と短期記憶という従来の2元論的な見方を一般化する、新しい記憶システムの定式化である連続的記憶システム(Continuum Memory System: CMS)を提案します。CMSは、複数のMLPブロック \(\text{MLP}^{(f_{\ell})}(\cdot)\) の連鎖として形式化されます。
$$
Y_t = \text{MLP}^{(f_k)} (\text{MLP}^{(f_{k-1})}( \cdots \text{MLP}^{(f_1)}(x_t) \cdots )) \quad
$$
ここで、数式中の各シンボルは以下を示しています。
- \(Y_t\): 時刻 \(t\) におけるCMSの出力
- \(\text{MLP}^{(f_{\ell})}(\cdot)\): \(\ell\) 番目のMLPブロック。上付き文字 \(f_{\ell}\) は、このブロックが特定の更新頻度を持つことを示します。
- \(x_t\): 時刻 \(t\) における入力
各 \(\ell\) 番目のMLPブロックのパラメータ \(\theta^{(f_{\ell})}\) は、特定のチャンクサイズ \(C^{(\ell)}\) ごとに更新されます。
$$
\theta^{(f_{\ell})}_{i+1} = \begin{cases} \theta^{(f_{\ell})}_i – \sum_{t=i-C^{(\ell)}}^{i} \eta_t^{(\ell)} f(\theta^{(f_{\ell})}_t; x_t) & \text{if } i = 0 \pmod{C^{(\ell)}} \\ \theta^{(f_{\ell})}_i & \text{otherwise} \end{cases} \quad
$$
ここで、数式中の各シンボルは以下を示しています。
- \(\theta^{(f_{\ell})}_{i+1}\): 次の更新ステップにおける \(\ell\) 番目のMLPブロックのパラメータ
- \(\eta_t\): 学習率
- \(C^{(\ell)}\): \(\ell\) 番目のMLPブロックのチャンクサイズ(更新頻度を決定)
- \(f(\cdot; \cdot)\): 任意のオプティマイザのエラーコンポーネント(例: 勾配降下法における勾配)
この定式化は、パラメータ \(\theta^{(f_{\ell})}\) が自身のコンテキストを圧縮し、そのコンテキストの抽象的な知識を表現する役割を担うことを示唆しています。つまり、CMSは、異なる時間スケールで情報を処理し、記憶を統合する能力を持つ、より柔軟で強力な記憶システムを提供します。これは、脳が持つ多時間スケール更新の構造を計算モデルに取り入れる試みと言えるでしょう。
NLに基づくこれらの新しい設計思想は、AIが単なる静的な知識ベースではなく、動的に学習し、自己改善する存在へと進化するための重要な一歩となります。次は、これらの理論と設計思想を結実させた具体的なアーキテクチャ「HOPE」について詳しく見ていきます。
自己参照的に進化するHOPEアーキテクチャ
Nested Learning(NL)の理論と設計思想を結実させた具体的なモデルとして、論文ではHOPE(A Self-Referential Learning Module with Continuum Memory)アーキテクチャが提案されています。HOPEは、NLの洞察を最大限に活用し、LLMが抱える静的な性質を克服するための斬新なアプローチを提示します。
自己修正能力を持つアーキテクチャ
HOPEの最も革新的な特徴は、自己参照型学習モジュールと上で紹介した連続的記憶システム(CMS)を組み合わせている点です。これにより、HOPEは自身の更新アルゴリズムそのものを学習し、いわばモデル自身を動的に修正する能力を獲得します。これは、固定されたルールに従って学習する従来のモデルとは一線を画す、大きな飛躍と言えるでしょう。
アーキテクチャ上の利点と内部オプティマイザ
NLの視点から見ると、HOPEは従来のアーキテクチャにはない複数の利点を備えています。例えば、コンテキストに基づいてキー(Key)、値(Value)、クエリ(Query)の射影を動的に変更する能力や、より深い記憶モジュールを持つことができます。
さらに、HOPEの内部オプティマイザには、データの依存関係をより適切に考慮するため、\(\ell_2\)回帰目的関数に基づく勾配降下法の新しい変種が採用されています。この更新則は以下のように表されます。
$$
W_{t+1} = W_t (I – x_t x_t^\top) – \eta_{t+1} \nabla_{W_t} L(\cdot) \quad
$$
ここで、数式中の各シンボルは以下を示しています。
- \(W_{t+1}\): 次のタイムステップにおける重み行列
- \(W_t\): 現在の重み行列
- \(I\): 単位行列
- \(x_t\): 入力ベクトル
- \(\eta_{t+1}\): 学習率
- \(\nabla_{W_t} L(\cdot)\): 目的関数の勾配
この更新則により、モデルは入力データの構造をより繊細に捉え、学習プロセスを適応的に調整することが可能になります。
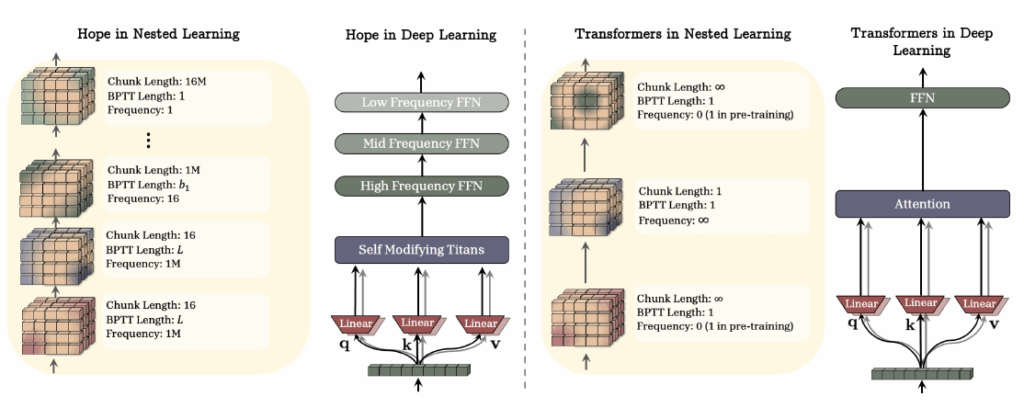
優れた性能と実用的な価値
HOPEは、言語モデリングや常識推論タスクといった主要なベンチマークにおいて、目覚ましい性能を示しています。論文によると、340M、760M、1.3Bのすべてのスケールで、Transformerや、RetNet、Titansといった最新のリカレントニューラルネットワーク(RNNs)を上回る結果を達成しています。
この性能は、NLの能力(多レベルの学習)とCMSの組み合わせがもたらす実用的な価値を明確に示しています。特に、HOPEは従来のモデルが苦手としてきた継続学習(Continual Learning)や長文コンテキスト推論(Long-context Reasoning)のタスクで有望な結果を示しており、これはAIがより動的で適応的なシステムへと進化するための大きな可能性を秘めていることを意味します。
HOPEアーキテクチャは、NLという新しいパラダイムが単なる理論に留まらず、現実の課題を解決するための具体的な設計指針を提供できることの力強い証明と言えます。
おわりに
Nested Learning(NL)は、ディープラーニングモデルを、それぞれ異なる時間スケールで動作する入れ子構造の連合記憶システムとして捉え直すことで、ディープラーニングの基礎概念に光を当て、その拡張の道筋を示しました。
このパラダイムシフトの最も重要な貢献は、最適化アルゴリズムを単なる更新ルールではなく、勾配を圧縮し、過去の経験を記憶する学習モジュールとして定義し直した点です。この知見は、Deep Optimizers の開発を導きました。さらに、連続的記憶システム(CMS)と組み合わせたHOPEアーキテクチャは、LLMsが抱える継続学習の静的な性質を打破し、動的で自己適応的なシステムへと進化するための具体的な設計指針を提供します。
NLによって、ディープラーニングの「深さ」は、単なる層の積み重ね(静的な視点)から、多レベルの最適化と多時間スケールでのコンテキスト圧縮(動的な視点)へと再定義されます。これは、継続的な適応と学習が求められる複雑なAIシステム構築において、今後不可欠なフレームワークとなる可能性を秘めています。
More Information
- NeurIPS 2025, Ali Behrouz, Meisam Razaviyayn, Peilin Zhong , Vahab Mirrokni, 「Nested Learning: The Illusion of Deep Learning Architectures」, https://neurips.cc/virtual/2025/loc/san-diego/poster/116123
関連記事

3D Gaussian Splatting: 3次元表現の新たなパラダイム
近年、実世界の画像から3Dシーンを再構築し、任意の視点から画像を生成する技術が急速に発展しています。 その代表格としてNeRF (Neural Radiance Fields)が広く知られていますが、計算コストが高く、描 […]

DSPy入門: LLMパイプライン構築の効率化
LLM(大規模言語モデル)を活用したアプリケーション開発が盛んになる中、LangChainやLlamaIndexといった優れたフレームワークが注目されています。これらのツールは、LLMの活用を容易にする様々な機能を提供し […]

企業環境においてRAGを実装するための要件と課題
Retrieval-Augmented Generation for Large Language Models: A Survey より引用 近年、Retrieval-Augmented Generation(RAG) […]