Lightlyで実践 - 自己教師あり学習入門

近年、機械学習プロジェクトで扱うデータ量は増大し続けています。しかし、その膨大なデータすべてに手作業でアノテーション(教師ラベル付け)を行うのは、コストと時間の面で大きな課題です。この「アノテーションの壁」を乗り越える技術として、今「自己教師あり学習(Self-Supervised Learning)」が大きな注目を集めています。
本記事では、この自己教師あり学習を驚くほど手軽に実践できるPythonライブラリ「Lightly」について、その概要と使い方を紹介します。Lightlyの概要から、SimCLRなどの代表的なアルゴリズム、そして実際にコードを動かすところまで、順を追って見ていきます。
なお、自己教師あり学習の理論的な背景については、以前の記事「アノテーション不要 - 機械学習エンジニアのための自己教師あり学習入門」も併せてご参照ください。
Lightlyの概要
Lightlyは、自己教師あり学習(Self-Supervised Learning, SSL)のパイプラインを劇的に簡素化し、手元にあるデータセットの価値を最大限に引き出すために設計された、強力なPythonライブラリです。特に、手作業でのアノテーション(ラベル付け)が困難な、大量の画像や動画といった非構造化データを扱う際に真価を発揮します。
このライブラリが多くの開発者から支持される理由は、主に以下の4つの特徴にあります。
- 豊富なSSLアルゴリズムの実装 SimCLR, MoCo, BYOL, Barlow Twinsといった、最先端の自己教師あり学習アルゴリズムが多数実装されています。これにより、自分のデータセットに最適な手法はどれか、という比較検討を簡単に行うことができます。
- 直感的で使いやすいAPI PyTorchやPyTorch Lightningとシームレスに連携できるように設計されており、わずか数行のコードを記述するだけで、自己教師あり学習のトレーニングを開始できます。複雑な設定に悩まされることなく、本質的なモデル開発に集中できます。
- 賢いデータサンプリング機能 ただ学習するだけでなく、大規模なデータセットの中からモデルにとって「学習価値の高い」サンプルを自動的に選択する機能も提供しています。これにより、学習の効率と精度を同時に向上させることが可能です。
- 便利な可視化ツール 学習がどのように進んでいるのか、またモデルがデータの特徴をどのように捉えているのかを視覚的に確認できるツールが組み込まれています。これにより、モデルの挙動を直感的に把握し、デバッグや改善のヒントを得やすくなります。
Lightlyは、画像分類、物体検出、セマンティックセグメンテーションなど、様々なコンピュータビジョンタスクの「事前学習」フェーズで絶大な効果を発揮します。例えば、何十万枚ものラベルなし画像データを使ってLightlyでモデルを事前学習させ、その後、少量のラベル付きデータでファインチューニングを行う、といったアプローチです。これにより、アノテーションにかかる膨大なコストと時間を削減しつつ、非常に高い性能を持つモデルを構築することが可能になります。
Lightlyに実装されているアルゴリズムの例
Lightlyの大きな魅力の一つは、数多くの自己教師あり学習アルゴリズムをサポートしている点です。これにより、研究のトレンドを追いかけたり、自身のタスクに最適な手法を試したりすることが容易になります。
以下に、Lightlyに実装されている代表的なアルゴリズムとその特徴をまとめました。それぞれに異なるアプローチや得意な点があるため、どのような手法が存在するのか、全体像を掴む参考にしてください。
| アルゴリズム | 概要 | メリット | デメリット | 主に対応する損失関数 |
|---|---|---|---|---|
| AIM | 画像を部分的にマスクし、予測するタスクで学習。MAEと同様のアイデア。 | シンプルで実装が容易。大規模データで高い性能。 | MAEに比べて普及率が低い。 | L1 Loss (MAE), L2 Loss (MSE) など一般的な回帰損失関数 |
| Barlow Twins | 2つの異なるビューから生成された特徴ベクトルが、同じ次元で相関するように学習。 | バッチサイズに依存しない。シャムネットワークと相関行列の正則化で学習が安定。 | ネットワークの出力次元数に依存し、大規模な出力次元が必要。 | BarlowTwinsLoss |
| BYOL | オンラインネットワークがターゲットネットワークを予測するように学習。ターゲットネットワークはオンラインネットワークの重みの移動平均。 | バッチサイズに依存しない。ネガティブサンプルが不要。 | ターゲットネットワークの重み更新メカニズムが複雑。学習が不安定になる可能性。 | NegativeCosineSimilarity, SymNegCosineSimilarityLoss |
| DenseCL | クエリをネガティブサンプルと比較するコントラスティブ学習をピクセルレベルに拡張。 | オブジェクト検出やセグメンテーションタスクで高い性能。 | 計算コストが高い。 | DCLLoss, DCLWLoss |
| DINO(DINOv2) | ビジョン・トランスフォーマー(ViT)を活用し、教師なしで画像をクラスター化。パッチごとの特徴を学習。 | 高性能な視覚表現を学習。特にViTとの相性が良い。 | 計算コストが高い。 | DINOLoss |
| iBOT | ビジョン・トランスフォーマーを用いたDINOの派生。トークンレベルでのSSLに焦点を当てる。 | DINOと同様にViTと相性が良く、ViTの学習を安定させる。 | DINOと同様に計算コストが高い。 | IBOTPatchLoss |
| MAE | 画像の大部分をマスクし、マスクされた部分を予測して学習する。 | シンプルで効率的な学習が可能。大規模データでのスケーラビリティが高い。 | 復元タスクのため、高解像度の特徴学習には向かない場合がある。 | L1 Loss (MAE), L2 Loss (MSE) など一般的な回帰損失関数 |
| MSN | 画像を異なるパッチに分割し、パッチ間の類似性を学習。 | バッチサイズに依存せず、ネガティブサンプルが不要。 | パッチ分割とマッチングのメカニズムが複雑。 | MSNLoss |
| MoCo | メモリバンクを使い、大規模なネガティブサンプルを効率的に利用。 | バッチサイズを小さくても学習可能。既存のコントラスティブ学習を改善。 | メモリバンクの管理が必要。学習に時間。 | NTXentLoss (+ MemoryBankModule) |
| NNCLR | 最近傍法(Nearest Neighbor)を利用し、ネガティブサンプルを使わずにコントラスティブ学習を行う。 | ネガティブサンプルが不要。計算コストを削減。 | 最近傍探索の計算コストが発生。 | – |
| PMSN | 複数の画像を組み合わせることで、より多様な画像を生成し、学習に利用。 | データセットの多様性を増やすことができる。 | 複数の画像を組み合わせる手法が複雑になる可能性。 | PMSNLoss, PMSNCustomLoss |
| SimCLR | 異なるデータ拡張を適用した同じ画像を近づけ、異なる画像を遠ざけることで学習。 | 非常にシンプルで効果的。ベースラインとして広く使われる。 | 大規模なバッチサイズが必要。計算コストが高い。 | NTXentLoss |
| SimMIM | MAEと同様に画像のマスクされた部分を予測するタスク。ビジョン・トランスフォーマーで特に効果的。 | シンプルで効率的。ViTの事前学習に有効。 | MAEと同様、復元タスクのため、他のタスクに転移しにくい場合。 | L1 Loss (MAE), L2 Loss (MSE) など一般的な回帰損失関数 |
| SimSiam | 停止勾配(stop-gradient)を利用し、ネガティブサンプルや大きなバッチサイズなしで学習。 | シンプルで実装が容易。学習が比較的安定。 | ネットワークの収束が保証されていないため、学習が発散する可能性。 | NegativeCosineSimilarity |
| SwaV | 複数のデータ拡張のビューを生成し、異なる解像度の画像間で学習。 | 大規模なバッチサイズが不要。多解像度に対応。 | 複数のクロップやクラスタリングのメカニズムが複雑。 | SwaVLoss |
| VICReg | 2つのビューから生成された特徴ベクトルの分散、不変性、共分散を正規化して学習。 | バッチサイズに依存しない。ネガティブサンプルが不要。 | 正規化のメカニズムが複雑。 | VICRegLoss |
Lightlyの使い方
ここからは、実際にLightlyを使って自己教師あり学習を行うための具体的な手順を、コードと共に見ていきましょう。今回は代表的なアルゴリズムであるSimCLRを例に進めていきます。
インストール方法
まずは、Lightlyおよび関連ライブラリをインストールします。PyTorch, torchvision, PyTorch Lightningが事前に必要です。
# PyTorch関連のライブラリをインストール
$ pip install torch torchvision pytorch-lightning
# Lightly本体をインストール
$ pip install lightly
# 結果を可視化するためにmatplotlibもインストール
$ pip install matplotlibデータセットの準備
自己教師あり学習では、ラベルなしの画像データが大量に必要です。今回は、手元でも動作確認しやすい「Tiny ImageNet」データセットを使用します。
1. データセットのダウンロードと展開
# データセットをダウンロード $ wget http://cs231n.stanford.edu/tiny-imagenet-200.zip # zipファイルを展開 $ unzip tiny-imagenet-200.zip
2. ディレクトリ構成の変更
ダウンロードしたままのTiny ImageNetは、クラスごとにフォルダが分かれています。Lightlyで扱いやすくするために、すべての画像ファイルを一つのディレクトリにまとめるスクリプトを実行します。
import os
import shutil
from pathlib import Path
from typing import Iterator, Tuple
def _flatten_images(path_generator: Iterator[Tuple[Path, Path]], dst_dir: Path) -> None:
"""
画像パスのジェネレータを受け取り、指定されたディレクトリに画像をコピーする共通ヘルパー関数。
Args:
path_generator: (コピー元パス, コピー先パス) のタプルを返すイテレータ。
dst_dir: まとめ先のフォルダのパス。
"""
os.makedirs(dst_dir, exist_ok=True)
counter = 0
for src_path, dst_path in path_generator:
shutil.copy(src_path, dst_path)
counter += 1
print(f"✅ {counter} 枚の画像を {dst_dir} に集約しました。")
def _generate_train_paths(src_dir: Path, dst_dir: Path) -> Iterator[Tuple[Path, Path]]:
"""
trainデータのソースパスと宛先パスを生成するジェネレータ。
宛先ファイル名: {クラス名}_{連番}.jpeg
"""
total_counter = 0
# クラスごとのディレクトリを取得
class_dirs = [d for d in src_dir.iterdir() if d.is_dir()]
for class_dir in class_dirs:
images_dir = class_dir / 'images'
if not images_dir.exists():
continue
# 各クラスの画像ファイルを取得
for img_file in images_dir.glob('*.jpeg'):
# ファイル名が被らないようにクラス名と全体の連番でリネーム
dst_filename = f"{class_dir.name}_{total_counter}.jpeg"
yield img_file, dst_dir / dst_filename
total_counter += 1
def _generate_val_paths(src_dir: Path, dst_dir: Path) -> Iterator[Tuple[Path, Path]]:
"""
valデータのソースパスと宛先パスを生成するジェネレータ。
宛先ファイル名: {0埋め5桁の連番}.jpeg
"""
images_dir = src_dir / 'images'
if not images_dir.exists():
return
# ファイルの処理順序を保証するためにソート
image_files = sorted(images_dir.glob('*.jpeg'))
for i, img_file in enumerate(image_files):
dst_filename = f"{i:05d}.jpeg"
yield img_file, dst_dir / dst_filename
def flatten_train_imagenet_images(src_dir: str, dst_dir: str) -> None:
"""
Tiny ImageNetのクラス別フォルダから全画像を1つのフォルダにまとめる。
Args:
src_dir: 例 './tiny-imagenet-200/train'
dst_dir: まとめ先のフォルダ(存在しない場合は作成)
"""
src_path = Path(src_dir)
dst_path = Path(dst_dir)
path_generator = _generate_train_paths(src_path, dst_path)
_flatten_images(path_generator, dst_path)
def flatten_dev_imagenet_images(src_dir: str, dst_dir: str) -> None:
"""
Tiny ImageNetの検証用画像を1つのフォルダにまとめる。
"""
src_path = Path(src_dir)
dst_path = Path(dst_dir)
path_generator = _generate_val_paths(src_path, dst_path)
_flatten_images(path_generator, dst_path)
# スクリプトとして実行される部分
if __name__ == "__main__":
print("--- 訓練用画像の処理を開始 ---")
flatten_train_imagenet_images('./tiny-imagenet-200/train', './tiny-imagenet-200/train_flat')
print("\n--- 検証用画像の処理を開始 ---")
flatten_dev_imagenet_images('./tiny-imagenet-200/val', './tiny-imagenet-200/val_flat')
実装例
準備が整ったので、いよいよ学習コードを実装します。
1. 必要なパッケージのインポート
import matplotlib import matplotlib.pyplot as plt import numpy as np import torch import torch.nn as nn import torch.optim as optim import torchvision # Lightlyの主要コンポーネントをインポート from lightly.loss import NTXentLoss from lightly import transforms from lightly.data import LightlyDataset from lightly.models.modules import heads # PyTorch Lightning関連をインポート from pytorch_lightning import LightningModule, Trainer from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint # ベースとなるモデルをインポート from torchvision.models import resnet18
2. 最適化設定(オプション)
学習速度を向上させるためのおまじないです。
# cuDNNの自動チューナーを有効化し、ハードウェアに最適なアルゴリズムを選択させる
torch.backends.cudnn.benchmark = True
# TensorFloat32(TF32)の使用を許可し、計算を高速化する
torch.set_float32_matmul_precision('medium')
3. データセットとデータローダーの準備
Lightlyのコンポーネントを使って、データセットを読み込みます。
# SimCLR用のデータ拡張(Data Augmentation)を定義
# 1つの画像から2つの異なる「ビュー」を生成する
transform = transforms.SimCLRTransform(input_size=64)
# 画像が格納されたフォルダを指定してデータセットを作成
train_dataset = LightlyDataset(input_dir="./tiny-imagenet-200/train_flat/", transform=transform)
val_dataset = LightlyDataset(input_dir="./tiny-imagenet-200/val_flat/", transform=transform)
# PyTorchのデータローダーを作成
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=256, # 対照学習ではバッチサイズが大きい方が効果的
shuffle=True, # 学習データをシャッフルするのは重要
drop_last=True, # バッチサイズに満たない最後のバッチを捨てる
pin_memory=True, # GPUへのデータ転送を高速化
num_workers=8, # データ読み込みを並列化するプロセス数
)
val_dataloader = torch.utils.data.DataLoader(
val_dataset,
batch_size=256,
shuffle=False, # 検証データはシャッフルしない
drop_last=True,
pin_memory=True,
num_workers=4,
)
4. SimCLRモデルの定義
PyTorch LightningのLightningModuleを継承して、学習ロジック全体をカプセル化したSimCLRモデルを構築します。
class SimCLR(LightningModule):
def __init__(self) -> None:
super().__init__()
# 事前学習済みのResNet18をベースモデルとしてロード
resnet = resnet18()
# 最終の全結合層(分類器)は不要なので、恒等写像に置き換える
resnet.fc = nn.Identity()
# 特徴抽出器となるバックボーン
self.backbone = resnet
# バックボーンから得た特徴量を低次元に射影するヘッド
self.projection_head = heads.SimCLRProjectionHead(
input_dim=512, # ResNet18の出力次元数
embed_dim=256, # 中間層の次元数
output_dim=128, # 最終的な出力次元数
)
# SimCLRで使われる損失関数 (NTXentLoss)
self.criterion = NTXentLoss()
# 学習/検証の損失を記録するためのリスト
self.training_step_outputs: list[torch.Tensor] = []
self.validation_step_outputs: list[torch.Tensor] = []
self.train_losses: list[np.float32] = []
self.val_losses: list[np.float32] = []
# 順伝播の定義
def forward(self, x: torch.Tensor) -> torch.Tensor:
# バックボーンで特徴を抽出
features = self.backbone(x).flatten(start_dim=1)
# 射影ヘッドでさらに変換
z = self.projection_head(features)
return z
# 最適化手法と学習率スケジューラを定義
def configure_optimizers(self) -> tuple:
optimizer = optim.AdamW(self.parameters(), lr=1.0E-3, betas=(0.9, 0.999))
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.95)
return [optimizer, ], [scheduler, ]
# コールバック(学習中に特定のタイミングで実行される処理)を定義
def configure_callbacks(self) -> list:
# 検証損失が改善した場合にモデルを保存する
checkpoint = ModelCheckpoint(
monitor="val_loss",
dirpath="checkpoint",
filename="SimCLR",
every_n_epochs=1,
save_weights_only=False,
)
# 検証損失が5エポック改善しなかったら学習を早期終了する
early_stopping = EarlyStopping("val_loss", mode="min", patience=5)
return [checkpoint, early_stopping]
# 1ステップごとの学習処理
def training_step(self, train_batch: list[torch.Tensor], batch_idx: int) -> torch.Tensor:
loss = self._common_step(train_batch, batch_idx)
self.log("loss", loss, on_step=True, on_epoch=True, batch_size=len(train_batch[0]), prog_bar=True)
self.training_step_outputs.append(loss)
return loss
# 学習エポック終了時の処理
def on_train_epoch_end(self) -> None:
# そのエポックの平均損失を計算して記録
losses = np.array([item.detach().cpu() for item in self.training_step_outputs])
self.train_losses.append(np.mean(losses))
self.training_step_outputs.clear()
# 1ステップごとの検証処理
def validation_step(self, val_batch: list[torch.Tensor], batch_idx: int) -> torch.Tensor:
loss = self._common_step(val_batch, batch_idx)
self.log("val_loss", loss, on_step=False, on_epoch=True, batch_size=len(val_batch[0]), prog_bar=True)
self.validation_step_outputs.append(loss)
return loss
# 検証エポック終了時の処理
def on_validation_epoch_end(self) -> None:
# そのエポックの平均検証損失を計算して記録
losses = np.array([item.cpu() for item in self.validation_step_outputs])
self.val_losses.append(np.mean(losses))
self.validation_step_outputs.clear()
# 学習済みモデル(バックボーン部分のみ)の重みを保存
def save_weights(self) -> None:
torch.save(self.backbone.cpu().state_dict(), "SimCLR.pth")
# 学習曲線をプロットして保存
def plot_train_history(self) -> None:
x1 = [i + 1 for i in range(len(self.train_losses))]
x2 = [i + 1 for i in range(len(self.val_losses))]
plt.figure(figsize=(8, 5))
plt.plot(x1, self.train_losses, label="loss")
plt.plot(x2, self.val_losses, label="val_loss")
plt.title("Training Loss vs Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid()
plt.legend(loc="best")
plt.savefig("SimCLR.png")
plt.show()
# 学習と検証で共通の損失計算処理
def _common_step(self, batch: list[torch.Tensor], _batch_idx: int) -> torch.Tensor:
# データローダーから2つのビューを取得
(view0, view1), _, _ = batch
# それぞれのビューをモデルに入力して特徴量を得る
z0 = self.forward(view0)
z1 = self.forward(view1)
# 2つの特徴量から損失を計算
loss = self.criterion(z0, z1)
return loss
5. 学習の実行
最後に、定義したモデルとデータローダーを使って学習を開始します。
# モデルをインスタンス化
model = SimCLR()
# PyTorch LightningのTrainerをセットアップ
trainer = Trainer(
max_epochs=100, # 最大エポック数
devices=1, # 使用するGPUの数
accelerator="gpu", # "gpu" or "cpu"
num_sanity_val_steps=0, # 学習開始前の検証ステップをスキップ
)
# 学習を開始
trainer.fit(model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader)
# 学習完了後、重みを保存し、学習履歴をプロット
model.save_weights()
model.plot_train_history()
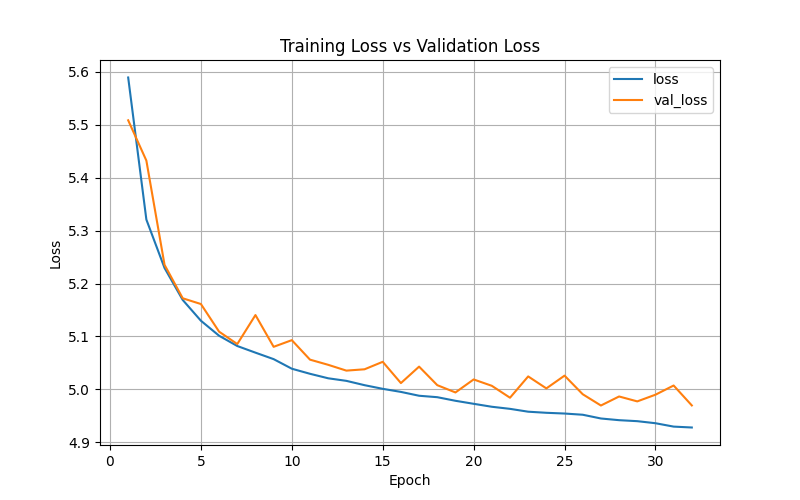
結果と考察
上記コードを実行したところ、31エポックでEarly Stopping(早期終了)が作動しました。
SimCLRの原論文ではバッチサイズを4096という非常に大きな値に設定していますが、今回の実装ではリソースの都合上256としています。対照学習では、バッチ内に多様な「負例(異なる画像)」が含まれていることが重要になるため、バッチサイズが小さいと学習がうまく進まず、早い段階で損失が下がらなくなった(=早期終了した)可能性があります。
また、論文ではオプティマイザにLARS(Layer-wise Adaptive Rate Scaling)を使用していますが、この例では一般的なAdamWを採用している点も結果に影響しているかもしれません。
このように、自己教師あり学習はデータセットの規模、モデルサイズ、バッチサイズ、オプティマイザなど、様々な要因が結果に影響します。実務で利用する際は、これらのハイパーパラメータを適切に調整することが重要です。
おわりに
今回は、自己教師あり学習を手軽に実践できるライブラリ「Lightly」について、その概要から具体的な実装方法までを解説しました。SimCLRの実装例でご覧いただいたように、PyTorch Lightningと組み合わせることで、対照学習のような複雑な学習パイプラインを、非常にシンプルに構築できることがお分かりいただけたかと思います。
アノテーションのコストと時間は、多くの機械学習プロジェクトにおいて依然として大きな壁です。自己教師あり学習は、この課題に対する強力な解決策となり得ます。Lightlyを使いこなせば、手元に眠っている大量のラベルなしデータを有効な「資産」へと変え、モデルの性能をもう一段階引き上げる道が開けるでしょう。
この記事が、皆さんのプロジェクトに自己教師あり学習を取り入れるきっかけとなれば幸いです。ぜひ、今回紹介したコードを参考に、ご自身のデータセットでLightlyのパワフルな機能を試してみてください。
More Information
関連記事

ローカルLLMはソフトウェア開発に活用できるのか?
近年、大規模言語モデル(LLM)の進化は目覚ましく、多くの分野でその活用が期待されています。しかし、その強力な性能を享受するには、クラウドベースでの運用が主流であり、API利用コストや外部APIへソースコードを送信するこ […]

DSPy入門: LLMパイプライン構築の効率化
LLM(大規模言語モデル)を活用したアプリケーション開発が盛んになる中、LangChainやLlamaIndexといった優れたフレームワークが注目されています。これらのツールは、LLMの活用を容易にする様々な機能を提供し […]

DINOv3: 自己教師あり学習による汎用ビジョン基盤モデル
高精度なAIモデルの構築には、大量かつ高品質な手動アノテーションが不可欠ですが、これは時間、コスト、労力の大きなボトルネックとなっています。特に医療画像や衛星画像のような特殊なドメインでは、ラベリングが極めて困難です。 […]