コンテキスト・エンジニアリング 2.0: 究極の知性へのロードマップと設計原則

近年、大規模言語モデル(LLM)とAIエージェントの急速な台頭により、システムにおける「コンテキスト」(文脈情報)の役割に大きな注目が集まっています。コンテキストウィンドウに配置された情報が、モデルの性能に著しく影響することが実証されているためです。
コンテキスト・エンジニアリング(Context Engineering)とは、機械が人間の意図に沿って行動できるように、コンテキスト情報を設計、整理、管理する体系的な実践を指します。これは、人間と機械の間に存在する認知的ギャップを埋めるための技術であり、情報エントロピーを削減するプロセスとして捉えることができます。
この分野は、最近の登場した技術と見なされがちですが、実際には20年以上にわたる歴史的進展があります。この記事では、このコンテキスト・エンジニアリングについて、「Context Engineering 2.0: The Context of Context Engineering」をもとに深堀していきます。特に、現在主流となっている「Era 2.0(エージェント中心の知性)」の技術的基盤 を中心に、さらに未来の知性(3.0、4.0)に至るための具体的な設計原則とロードマップについて解説します。この進化の道のりを理解することは、信頼性の高いAIシステムを構築し、人間と機械の協働(Human-Agent Interaction: HAI)の可能性を広げるための重要な一助となります。
コンテキスト・エンジニアリングの核心:なぜ設計が必要なのか
コンテキスト・エンジニアリング(Context Engineering)の根本的な動機は、人間と機械の間に存在する認知的なギャップを埋める点にあります。機械が人間の状況や目的に沿って動作するためには、このギャップを体系的に解消する設計が不可欠です。
まず、この議論の基盤となる「コンテキスト」(Context)の定義を確認します。コンテキストは、「ユーザーとアプリケーション間のインタラクションに関連すると見なされるエンティティの状況を特徴づけるために使用できるあらゆる情報」と定義されます。ここでいうエンティティには、ユーザー自身、アプリケーションのシステム設定、現在の環境、使用可能なツール、さらには短期・長期の記憶モジュールなどが含まれます。
人間は、会話や共同作業を行う際、共有された知識や状況認識を通じて、コミュニケーションに含まれる欠落したコンテキスト(文脈)を推論し、補完することができます。これは、情報エントロピーが高い状態から、意味を理解できる低エントロピーな状態へと、能動的に情報を変換する能力です。しかし、現在の機械には、この「行間を読む」能力、すなわち、高エントロピーなコンテキストを効果的に処理する能力が不足しています。
したがって、コンテキスト・エンジニアリングは、エントロピー削減のプロセスとして捉えられます。人間の意図や高エントロピーな形式のコンテキストを、機械が正確に理解し、タスクパフォーマンスを向上させるために最適化された低エントロピーな表現へと変換する体系的な「努力」そのものを指します。システムを信頼できるものにし、人間の期待に沿って機能させるために、このコンテキストの設計、整理、管理が不可欠です。
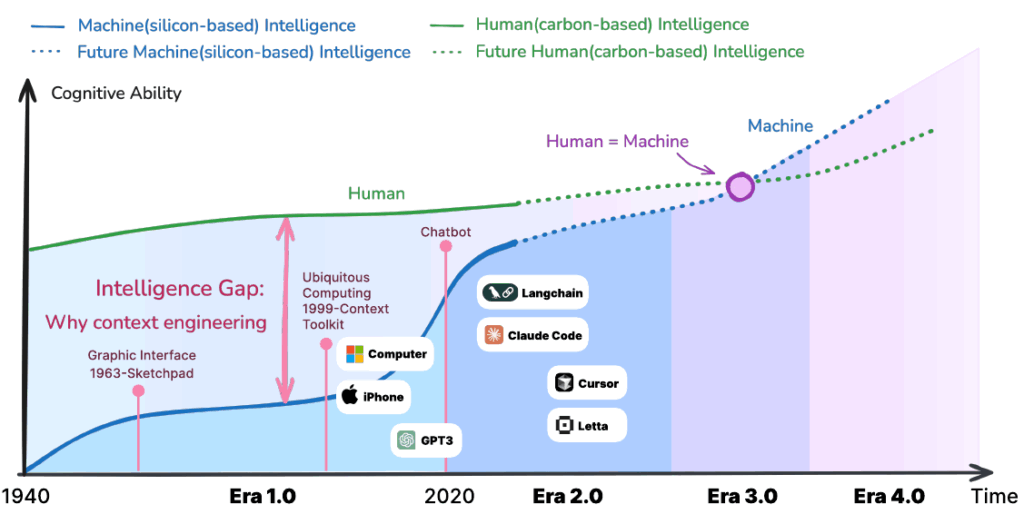
知性のロードマップ:コンテキスト・エンジニアリングの進化
コンテキスト・エンジニアリングの進化は、機械の知性レベルの急速な進歩と密接に結びついています。機械の知性が高まるほど、システムはより大きなコンテキスト処理能力を獲得し、結果として人間とAIとのインタラクションコスト(Human-AI Interaction Cost)が低下するという明確な傾向が示されています。
この進化の道のりは、機械の知性レベルに基づき、4つの明確な段階に概念化されています。
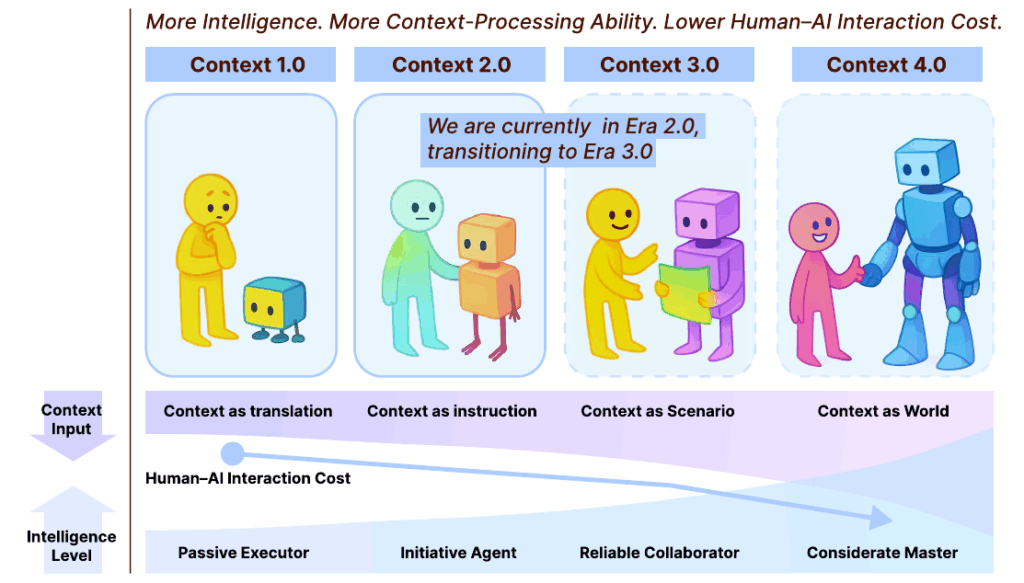
Era 1.0: 受動的な実行者 (Passive Executor) の時代(1990年代〜2020年)
この初期段階は、ユビキタスコンピューティング、コンテキストアウェアシステム、HCI(Human-Computer Interaction)といった技術的背景のもとで発展しました。機械は「受動的な実行者」(Passive Executor)の役割に留まり、コンテキストとして利用できる情報は、GPS座標や時刻、あるいは定義済みのユーザー状態など、構造化された入力に厳しく限定されていました。システムは自然言語の意味を理解できず、人間の意図を機械が処理できる低エントロピーな形式へと明示的に「翻訳する努力」が必要でした。
Era 2.0: インテリジェントなエージェント (Intelligent Agent) の時代(2020年〜現在)
大規模言語モデル(LLM)の登場 は、コンテキスト・エンジニアリングの転換点となりました。機械は「インテリジェントなエージェント」(Intelligent Agent)として主導権を握り始め、自然言語の入力を理解し、ある程度の暗黙的な意図を推論する能力を獲得しました。
Era 2.0の実践手法には、プロンプトエンジニアリング(Prompt Engineering)、RAG(検索拡張生成、Retrieval-Augmented Generation)、ツールコーリング(Tool Calling) など、曖昧さや不完全な情報を含む高エントロピーなコンテキストを処理するための技術が含まれます。現在、私たちはこの2.0時代にあり、次の段階へと移行しつつあります。
未来の段階:3.0と4.0
- 3.0:人間レベルの知性(Reliable Collaborator) この段階では、AIは「信頼できる協力者」(Reliable Collaborator)となり、人間レベルの推論と理解に近づきます。解釈可能なコンテキストの範囲が大幅に広がり、社会的合図や感情状態、環境ダイナミクスといったニュアンスに富んだ情報 を理解できるようになり、人間と機械の自然な協調が実現すると予想されています。
- 4.0:超人的知性(Considerate Master) さらに進んだこの段階では、AIは「思慮深い管理者」(Considerate Master)の役割を担い、人間の能力を凌駕します。AIは、人間が明示的に表現していない潜在的なニーズを発見し、人間自身のためにコンテキストを積極的に構築するようになると予測されています。
実装のためのコア設計原則:コンテキストの管理と抽象化
コンテキスト・エンジニアリング Era 2.0 の時代において、信頼性の高いAIシステムを構築するための主要なエンジニアリング課題は、増大し続けるコンテキスト情報を、いかに効率的に管理し、エージェントが利用できる知識構造へと抽象化するかという点に集約されます。
メモリの階層化アーキテクチャ
大規模言語モデル(LLM)は、あたかもCPUのように推論を行い、そのコンテキストウィンドウが高速ですが容量に制限のあるRAM(ワーキングメモリ)に例えられる、というオペレーティングシステム(OS)のアナロジーが提唱されています。この考え方に基づき、コンテキスト管理は、情報が時間的な関連性と重要性に応じて階層化されることで、大きな恩恵を受けます。
具体的には、以下の2層モデルが基本となります。
- 短期記憶(Short-term Memory):時間的関連性が高い、直近の対話やイベントを高速に保持します。
- 長期記憶(Long-term Memory):処理され、抽象化された重要性の高い知識を、セッションを超えて安定的に保持します。
この階層構造により、システムは応答性を最適化しつつ、重要な知識を永続的に維持できます。
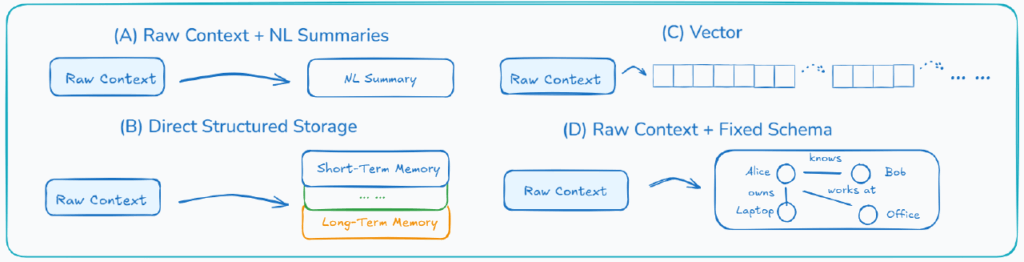
コンテキストの自己抽象化(Self-Baking)
コンテキストの量が増えてもシステムが破綻しないために不可欠なのが、「自己抽象化」(Self-Baking)と呼ばれるプロセスです。これは、エージェントが生のコンテキストを選択的に消化し、よりコンパクトで構造化された永続的な知識構造に変換することを指します。これは、人間の認知プロセスにおいて、エピソード記憶が抽象的な意味記憶へと発展するのと同様であり、エージェントが単に情報を想起するだけでなく、知識を蓄積するための鍵となります。
Era 2.0で採用されている主要な自己抽象化のパターンは以下の通りです。
- 自然言語による要約の追加(Natural-Language Summaries):元の完全なコンテキストを保持しつつ、要約を定期的に生成し、主要なイベントの概要を提供します。例えば、Claude Codeは、主要な情報を構造化されたメモとして外部メモリに書き出すことで、長期的なタスクの進捗を管理します。
- 固定スキーマを用いた主要事実の抽出(Key Facts using a Fixed Schema):生のコンテキストから、事前に定義されたスキーマ(例:エンティティマップ、イベント記録、タスクツリー)に情報を抽出します。これにより、CodeRabbitのコードレビューにおけるファイル間の依存関係のエンコードのように、明示的な構造内での分析と推論が可能になります。
- 意味を捉えるベクトルへの漸進的圧縮(Progressively Compress into Vectors):情報を、意味を反映した密な数値ベクトル(エンベディング)としてエンコードし、古いエンベディングを集約・圧縮することで、より抽象的で安定した意味記憶を構築します。これはセマンティック検索において特に有用です。
コンテキストの分離(Context Isolation)
コンテキストウィンドウの制限を回避し、コンテキスト汚染(Context Pollution)のリスクを減らすための戦略として、情報の分離も重要です。
- サブエージェント(Subagent):機能的な分離を通じてコンテキストを隔離します。各サブエージェントは独自のコンテキストウィンドウとカスタムプロンプトを持ち、メインシステムのコンテキストを汚染せずに、タスクを独立して実行します。
- 軽量リファレンス(Lightweight References):大容量のデータは外部に格納し、モデルのコンテキストウィンドウには、そのデータへの簡潔な参照のみを露出させます。例えば、サンドボックスアプローチのように、モデルは簡潔な参照のみを操作し、必要なときに完全なデータにアクセスします。
実用的な利用法:マルチエージェント協調と効率的な運用
コンテキスト・エンジニアリング Era 2.0 の重要な応用分野の一つが、マルチエージェントシステムです。現代のLLMアプリケーションは、全体として単一のエージェントが処理できるトークン量を超過し、大規模な推論ワークフローに対応するため、複数のエージェントが連携してタスクを解決する構造が一般的になっています。このような協調を成功させるには、エージェント間で正確かつ効率的にコンテキストを共有することが不可欠です。
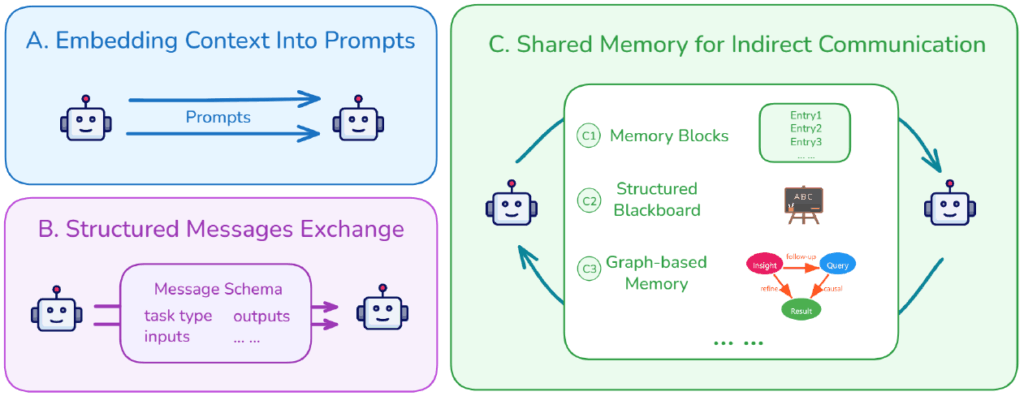
エージェント間のコンテキスト共有パターン
複数のエージェント間で情報を共有する方法には、主に以下の2つのパターンがあります。
- 構造化メッセージの交換:エージェントは、タスクタイプ、入力データ、出力結果、推論ステップといった固定スキーマを持つ構造化メッセージを交換します。これにより、情報の一貫性と明確性が保たれ、後続のエージェントがスムーズにタスクを引き継ぐことができます。Letta やMemOS のようなシステムでこのアプローチが採用されています。
- 共有メモリによる間接通信:エージェントは、中央の外部ストレージや、トピックやタスクごとに区分けされた「共有ブラックボード」(Shared Blackboard)を介して情報を非同期的に読み書きします。特に、Task Memory Engine (TME) のように、推論プロセスをタスクグラフとして表現し、ステップ間の依存関係を追跡することで、複雑なマルチステップ推論の信頼性を高めることが可能です。
効果的なコンテキスト選択(フィルタリング)
利用可能なすべてのコンテキストが現在のタスクに役立つわけではありません。ノイズの多い、あるいは無関係な情報がコンテキストウィンドウに入ると、推論の品質が低下し、コストが増大します。そのため、コンテキストを絞り込むための効果的なフィルタリングが重要になります。
選択基準としては、以下の要素が考慮されます。
- 意味的な関連性:現在のクエリと意味的に最も類似したメモリ要素を、ベクトルベースの検索(RAG)によって選択します。
- 論理的依存関係:現在のタスクが論理的に依存している情報(例:以前の計画決定、ツールの出力結果)を選び出します。MEM1 のように、推論の依存関係グラフをたどることで、タスクの論理的な流れに沿ったコンテキストのみを確実に取得します。
- 最近性(Recency)と頻度(Frequency):最近使用された、または頻繁にアクセスされたコンテキストは、再び有用である可能性が高いため、優先度を高く設定します。
最新エンジニアリングの実践
効率的な運用とデプロイメントを支える実践として、KV(Key-Value)キャッシュの最適化とツール設計が注目されています。
- KVキャッシュの最適化:推論効率を向上させるために、システムプロンプトの安定性を保ち、アペンドオンリー(追記のみ)の更新を徹底するなど、キャッシュの再利用率(ヒット率)を高めることが重要です。
- ツール設計:エージェントに提供するツールの目的は正確で明確に定義されている必要があり、曖昧な記述は動作の失敗を招きます。また、ツールセットの規模が大きすぎるとエージェントの信頼性が低下する可能性があるため、適切なスケール(例えば、あるモデルでは30ツール以内)を維持することが、信頼性の高いシステムを構築するための鍵となります。
コンテキスト・エンジニアリングの実践
コンテキスト・エンジニアリング Era 2.0 の設計原則は、すでに複雑な実務タスクを扱う多くのシステムで具体的に活用され始めています。特に、ソフトウェア開発やDeep Researchといった、長期的なコンテキスト管理が必須となる分野において、その有効性が実証されています。
CLIエージェントによるプロジェクトコンテキスト管理
GoogleのGemini CLIは、プロジェクト指向のコンテキスト管理の代表的な事例です。
このシステムの中核メカニズムは、プロジェクトの背景、役割定義、依存関係、コーディング規約などを記録するGEMINI.mdファイルです。コンテキストは、ファイルシステムの階層を通じて整理されており、ユーザーのホームディレクトリやプロジェクトルート、サブディレクトリに配置することで、情報の継承と隔離が実現されています。
Gemini CLIでは、コンテキストの効率化のために「自己抽象化」の原則を適用しています。長時間の対話履歴をそのまま保持するのではなく、AIが生成した要約に置き換えることで、コンテキストの圧縮を実行します。この要約は、全体的なゴール、主要な知識、ファイルシステムの状態、現在の計画などを含む事前定義されたフォーマットに従って作成され、エージェントが迅速かつ一貫性をもって主要なコンテキストを再利用できるようにしています。
Deep Researchエージェントによる長期記憶の実現
オープンエンドな知識集約型クエリに対応するDeep Researchエージェント、例えばTongyi DeepResearchは、コンテキストの制約を打破するための洗練された手法を採用しています。
リサーチタスクは、多くの場合、膨大な量の観測結果、思考プロセス、および行動履歴を生成するため、コンテキストウィンドウの容量をすぐに超えてしまいます。Tongyi DeepResearchは、この課題に対処するため、探索の途中で専門の要約モデルを定期的に呼び出し、蓄積された履歴をコンパクトな「コンテキストスナップショット」に圧縮します。
この手法により、エージェントは完全な生の履歴ではなく、この圧縮されたスナップショットに基づいて推論と再利用を行うことが可能となります。これにより、コンテキストの制約から解放され、スケーラブルで長期的なリサーチ能力を実現しています。これは、コンテキストの収集から、定期的な抽象化、そして再利用に至るまでのライフサイクルを、体系的に実装した好例と言えます。
おわりに
この記事を通じて、コンテキスト・エンジニアリングが、単にLLM時代に突如出現した技術ではなく、20年以上にわたり人間と機械の間の意図の橋渡しを試みてきた、進化し続ける学問分野であることがご理解いただけたかと思います。
現在主流のEra 2.0では、プロンプトエンジニアリングやRAGといった手法により、LLMの能力を活用して高エントロピーなコンテキストを解釈・処理できるようになりました。しかし、将来の知性(4.0)への移行を果たすには、いくつかの根本的な課題に直面しています。
最大の課題は、生涯にわたるコンテキストを蓄積・更新し、意味的な一貫性を維持するためのスケーラブルなストレージと管理機構の構築です。また、Transformerモデルの持つ2次複雑性の問題に対処し、大規模なコンテキストを効率的かつ確実に理解するためのMambaやLongMambaといった新しいアーキテクチャが不可欠です。
この要請に応えるのが、「セマンティック・オペレーティング・システム」(Semantic Operating System)の概念です。このシステムは、知識を積極的に追加、修正、そして忘却するという人間のようなメモリ管理能力を持ち、さらに推論ステップを追跡し、自己説明できる必要があります。
機械の理解能力が人間を超越するにつれて、AIは単に私たちの意図を理解するだけでなく、私たち人間自身を照らし、理解を深める源となるでしょう。コンテキスト・エンジニアリングは、この未来の人間と機械の協働の可能性を切り開く、最も重要な基盤技術であり続けます。
More Information
- arXiv:2510.26493, Qishuo Hua et al., 「Context Engineering 2.0: The Context of Context Engineering」, https://arxiv.org/abs/2510.26493
関連記事

Nested Learning: Deep Learning の新たなパラダイム
ChatGPTやGeminiをはじめとする大規模言語モデル(LLM)は、人間が書いたかのような自然な文章を生成し、複雑な質問にも答えるなど、驚異的な能力を見せています。しかし、その万能に見える能力の裏で、根本的な問題を抱 […]

Pythonで始める因果推論入門
昨今、ビジネスでは、データに基づいた意思決定がますます求められています。しかし、データから得られるのは、あくまで相関関係です。因果関係を正しく理解することで、我々はより確実な予測を行い、効果的な対策を立てることができるよ […]

torchmil入門:PyTorchによる深層マルチインスタンス学習の実践
現代の機械学習では、詳細なラベルを全てのデータに付与することが困難な場面が多く見られます。特に医療画像診断のような分野では、ピクセル単位の精緻なアノテーション(Annotation)には専門家の多大な労力が必要となり、実 […]