SkillOpt: AIエージェントのスキルを最適化するための手法

最近、LLM(大規模言語モデル)を自律的なエージェントとして活用するケースが増えてきました。エージェントに特定のタスクを遂行させる際、自然言語で書かれた「スキル(指示書や手順書)」を与えるアプローチが一般的です。しかしながら、手作業での作成や、LLMによる一度きりの生成(ワンショット生成)で作られたスキルには限界があります。様々な環境の変化に対して脆く、実行時のフィードバックをもとに着実に改善を進めることが困難です。また、モデル自体の重みを更新するファインチューニングは、クローズドなモデルでは利用できず、コストの面でもハードルが高いのが実情です。
こうした課題に対して、Microsoftなどの研究チームは「SkillOpt」という新手法を提案しました。これは、モデルの重みを固定したまま、自然言語のスキル文書をエージェントの「外部状態」と見なすアプローチです。そして、ディープラーニングの学習プロセス(バッチ処理や学習率、検証データの活用など)の概念をテキスト空間に適用し、スキルを体系的に最適化します。この記事では、この新しいフレームワークの全体像を詳しく解説します。
1. テキスト空間最適化の基本概念
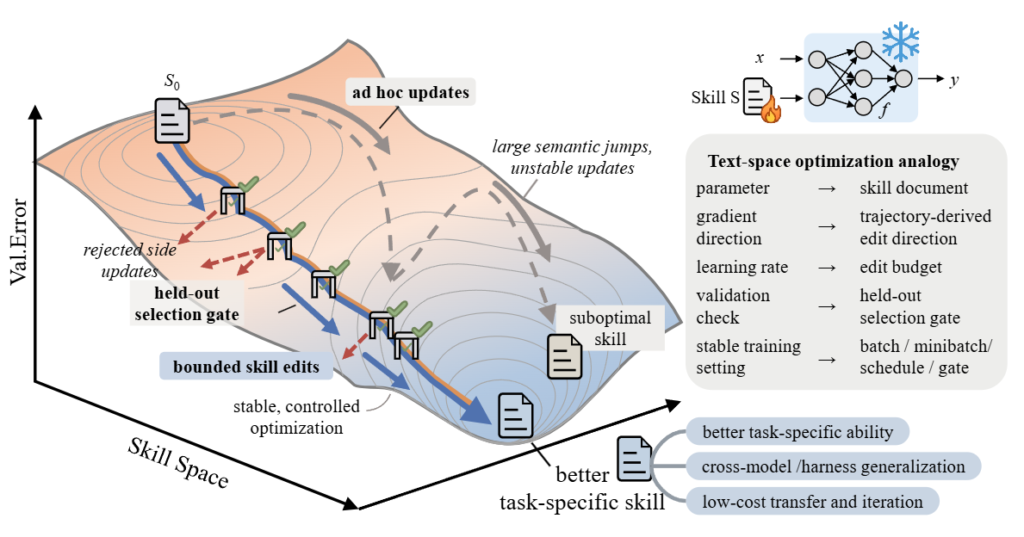
SkillOptのユニークな点は、自然言語のスキル文書をまるでニューラルネットワークの「パラメータ」のように扱い、最適化していく点にあります。この仕組みを明確にするため、まずは基本となる数式とプロセスを見ていきましょう。
最適化の土台となるのは、エージェントの実行プロセスです。ターゲットモデル(\(M\))、実行環境であるハーネス(\(h\))、そして現在のスキル(\(s\))を組み合わせて、特定のタスク(\(x\))を処理させます。この実行によって、エージェントがどのように動いたかを示す軌跡(\(\tau\))と、評価スコアとなる報酬(\(r(s)\))が得られます。
$$(\tau(s), r(s)) = h(M, x, s), \quad r(s) \in [0, 1]$$
次に、訓練データ(\(D_{\text{tr}}\))の実行結果をもとに生成された様々な候補スキルの集合(\(C(D_{\text{tr}})\))から、最終的にデプロイする最適なスキル(\(s^\star_{\text{sel}}\))を選定します。ここで重要なのは、未知の検証セット(\(D_{\text{sel}}\))を用いて選定を実施し、汎化性能を担保している点です。
$$s^\star_{\text{sel}} = \arg \max_{s \in C(D_{\text{tr}})} \frac{1}{|D_{\text{sel}}|} \sum_{x \in D_{\text{sel}}} r(s)$$
このようにして厳しい選定ゲートを通過した最良のスキルのみが、最終的なテストセット(\(D_{\text{test}}\))での性能評価に用いられます。
$$\text{Test}(s^\star_{\text{sel}}) = \frac{1}{|D_{\text{test}}|} \sum_{x \in D_{\text{test}}} r(s^\star_{\text{sel}})$$
この一連のプロセスは、従来の深層学習における最適化の概念と美しく対応しています。SkillOptの論文では、各要素のマッピングを以下のように整理しています。
| 深層学習の概念 | SkillOpt(テキスト空間)でのアプローチ | 具体的な意味合い |
|---|---|---|
| パラメータ | スキル文書 (Skill Document) | 学習によって更新されていく、外部状態としての自然言語の指示書です。 |
| 勾配の方向 | 軌跡から導かれる編集方向 | 実行結果(成功や失敗の軌跡)を分析して導き出される、スキルの具体的な修正方針です。 |
| 学習率 | 編集予算 (Edit Budget) | 一度のステップで許容されるスキルの最大変更回数であり、更新の大きさを制御します。 |
| 検証チェック | 選定ゲート (Selection Gate) | Hold-outされた検証データを用いて、スキルの修正が本当にスコアを向上させるかを確認する関門です。 |
| 安定した学習 | バッチ処理 / スケジューラ等 | バッチやミニバッチ処理、スケジュール管理により、局所的なノイズに過適合しない安定した学習設定を提供します。 |
自然言語のテキスト修正を無制限に許可するのではなく、「編集予算」という形で学習率を設けたり、検証データによる「選定ゲート」でスコア向上を厳格にチェックしたりします。これにより、モデルの重みを更新するファインチューニングと同じような着実で安定した進化を、テキスト空間でも実現しているのです。
2. 最適化パイプラインとアルゴリズム
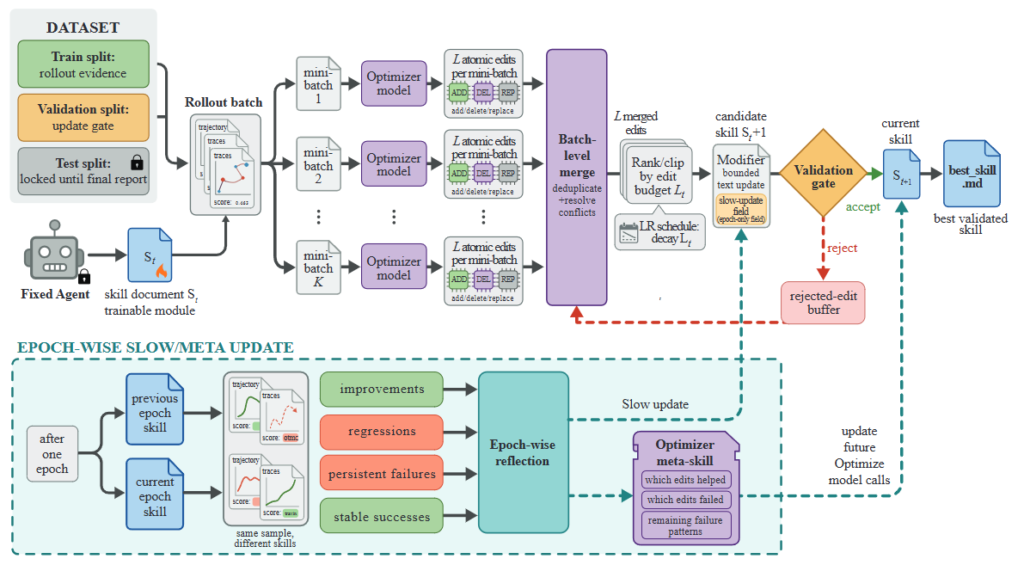
SkillOptの最適化プロセスが具体的にどのように進むのか、パイプラインの主要なメカニズムを4つの要素に分けて解説します。
- ミニバッチ処理と失敗修正の優先: エージェントの実行結果(軌跡)からスキルを修正する際、オプティマイザモデルは成功例と失敗例を分けて別々の「ミニバッチ」として処理します。1つの失敗例だけを見て修正案を作ると、特定の事例にしか通用しない局所的な修正になりがちです。ですが、ミニバッチとして様々な事例をまとめて分析することで、「出力フォーマットを毎回間違える」「検索手順を飛ばす」といった一貫した手順エラーを特定しやすくなります。さらに、複数の修正案を統合(マージ)する段階では、成功パターンの強化よりも、失敗を修正する案が優先して採用されます。
- 編集予算による上限付きテキスト更新: プロンプトを毎回ゼロから書き直すような手法では、うまく機能していたルールまで消えてしまうリスクがあります。そこでSkillOptは、学習率に相当する「編集予算(\(L_t\))」という概念を導入し、1回のステップで適用できる修正回数に制限を設けました。この「上限付きテキスト更新(Bounded Text Updates)」により、スキルの過度な書き換えを防ぎます。結果として、スキルは少しずつ連続性を保ちながら進化するため、「過去のどの修正が良くて、どれが悪かったか」という最適化の履歴が意味を持つようになります。
- 検証ゲートと拒否バッファ: 提案されたスキルの修正案は、未知の検証データセットを使った「検証ゲート」で評価されます。ここでは、スコアが以前のバージョンを「厳密に上回った場合のみ」採用されるという、非常に保守的な基準が適用されます(同点の場合は拒否されます)。人間から見て筋の通ったテキスト修正であっても、実際のモデルには悪影響を与えることがあるためです。 また、このゲートで不採用となった修正案は単に破棄されるわけではありません。「拒否バッファ(Rejected-edit buffer)」に記録され、オプティマイザに対する負のフィードバックとして次の最適化で再利用されます。これにより、同じ失敗を何度も繰り返すことを防ぎます。
- エポックごとの長期的な更新(Slow/Meta Update): 細かいステップごとの更新に加えて、エポック(学習の一区切り)ごとに長期的な視点での最適化も実施します。ここでは、スキル文書内にステップレベルの細かい編集では上書きできない「保護されたセクション(Protected section)」を設け、そこへ長期的なガイダンス(Slow update)を書き込みます。 さらに、オプティマイザ専用の「メタスキル(Meta skill)」という仕組みも存在します。メタスキルは「どの編集パターンが役立ち、どれが失敗したか」を要約し、オプティマイザ自身の判断力を向上させます。重要な点として、このメタスキルは本番環境のエージェントにはデプロイされません。これにより、エージェントが実際に読み込むスキル文書のサイズをコンパクトに保つ工夫がなされています。
3. アブレーションとハイパーパラメータの挙動
テキスト空間の最適化において、ハイパーパラメータ(学習率やバッチサイズなど)や各機能がどのように影響するのかを見ていきましょう。論文のアブレーションスタディから、SkillOptの堅牢さ(ロバスト性)と各メカニズムの重要性が明らかになっています。
- バッチサイズに対する高いロバスト性: 深層学習では、バッチサイズの調整が性能に大きく影響することがあります。しかし、SkillOptでは、軌跡の分析に用いるミニバッチサイズ(1〜32)や、一度のステップで取得するロールアウト(実行結果)のバッチサイズ(8〜エポック全体)を変化させても、性能は極めて安定しています。一部のタスクでは学習データが増えるほど性能が向上しますが、少量のデータや小さなバッチサイズでも十分に機能することが確認されています。
- スケジューラよりも「予算上限の設定」が重要: 1回のステップでスキルをどれだけ書き換えるかを示す「編集予算(学習率)」についても興味深い結果が出ています。論文では定数やコサイン減衰など様々な減衰スケジュールを検証していますが、スケジュールの種類による性能差はそれほど大きくありません。それよりも決定的に重要なのは、「無制限な書き換えを防ぎ、上限を設けること」自体です。予算上限を取り外した設定では明確にスコアが低下しており、過去の有用なルールを保護しつつ少しずつ更新していくアプローチの正しさが裏付けられています。
- 長期タスクにおけるSlow/Meta Updateの不可欠さ: 特に複雑な推論が求められるタスク(例えばスプレッドシートの操作を進めるSpreadsheetBenchなど)では、長期的なガイダンスを提供する「Slow Update」と「Meta Update」の機構が不可欠です。実際にこれらの機構を外すと、スコアが最大で\(22.5\)ポイントも著しく低下してしまいます。これは、局所的な失敗を修正するための細かい編集だけを繰り返すと、長期的に維持すべき重要な手順やルールが破損してしまうためです。保護されたセクションに長期的な教訓を書き込む仕組みが、この問題を見事に防いでいます。
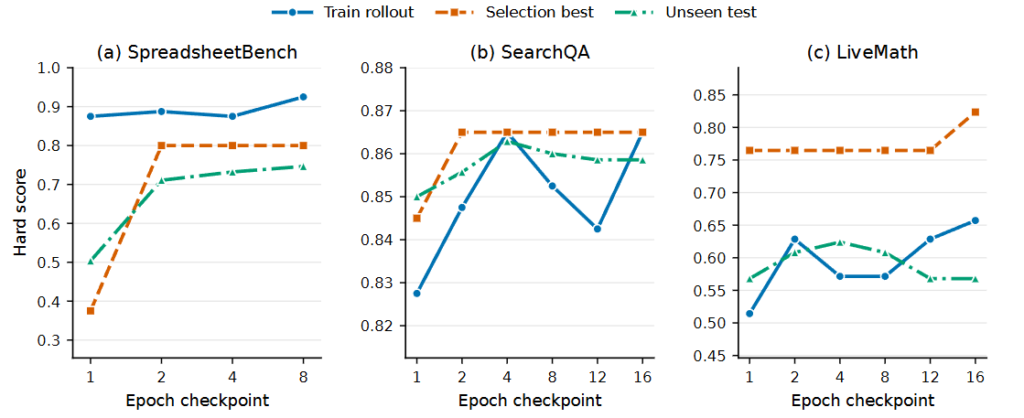
- 検証スコアと汎化性能の連動: また、SkillOptの検証ゲートが正しく機能していることも確認されています。未知の検証セット(Hold-outデータ)で評価した最高スコアの推移と、最終的なテストセットでの汎化性能の推移が綺麗に連動していることが示されています。これは、検証ゲートが単に検証データに過適合した(特定のデータにだけ強い)スキルを選んでいるのではなく、本当に実力のある未知のデータにも通用するスキルを確実に見つけ出していることを意味しています。
4. 転移学習と獲得したルール
SkillOptによって最適化されたスキルは、学習データに過剰に適応してしまう「過学習(Overfitting)」に陥ってはいないのでしょうか。論文で実施された転移学習の実験や、実際に獲得されたルールの中身から、そのロバストな実態を見ていきましょう。
3つの軸で機能する高い汎化性能
実験では、学習済みのスキルが元の環境以外でも通用するかを検証しています。
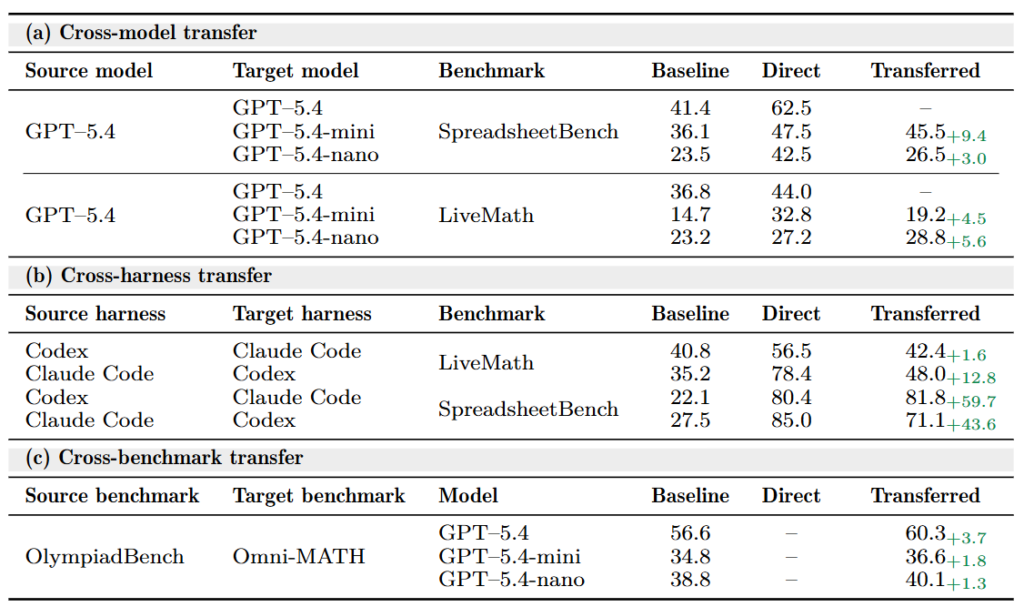
- モデル間の転移(Cross-model): 大規模モデル(GPT-5.4)で学習したスキルを小規模モデル(GPT-5.4-nanoなど)に適用しても、スコアが向上することが確認されました。
- 実行環境間の転移(Cross-harness): Codexで最適化されたスキルを、API環境が異なるClaude Codeに適用しても、大きな性能向上(スコアが約60ポイント向上した事例など)が見られました。
- ベンチマーク間の転移(Cross-benchmark): 数学タスクのOlympiadBenchで得たスキルを、別の数学タスクであるOmni-MATHに適用しても効果を発揮しました。
特定事例のパッチではなく「手続き的知識」を獲得
なぜこれほど柔軟に異なる環境へ転移できるのでしょうか。実際に生成されたルールの出力例を見ると、特定の質問やファイル名に依存するような「その場しのぎのパッチ」は含まれていません。例えば、探索タスク(ALFWorld)では、「同じ種類の失敗を繰り返した後は探索方法を多様化する」「訪問済みの場所とそうでない場所(探索フロンティア)を管理する」といった、様々な状況で応用できる汎用的な「手続き的(Procedural)な知識」が獲得されていました。
SearchQA: 「手がかりとなる文言から期待される回答タイプを推論し、共起する特徴的な証拠によって裏付けられた最も短い正準的なエンティティを選択する。」
SpreadsheetBench: 「ワークブックの構造と数式を確認し、Excel の再計算に依存するのではなく、要求されたターゲット範囲全体に評価済みの静的値を書き込む。」
OfficeQA: 「オラクルが解析したページを主要な証拠として扱い、表・日付・単位の文脈を固定し、余計なラベルを付けずに要求された丸め値を正確に出力する。」
DocVQA: 「表、フォーム、チャート、凡例については、まず質問を該当する視覚的な行・ヘッダー・フィールドに正確に結びつけ、その後、対応する回答部分のみを抽出する。」
LiveMathematicianBench: 「最も強い主張を問う選択式問題では、定理の強さで選択肢を順位付けし、真ではあるが弱い系よりも、正当化されたより強い結果を選ぶ。」
ALFWorld: 「探索範囲を意識した訪問済み/未探索リストを維持し、同種の失敗が続いた場合は探索を多様化し、目標物を取得するまでは目的地を再訪しないようにする。」高い監査性と推論時コストゼロのメリット
さらに注目すべきは、最終的にできあがったスキル文書のコンパクトさです。数百から2,000トークン未満に収まっており、人間が数分で読んで中身を監査(Audit)することが十分に可能です。また、驚くべきことに、これらのスキルは厳しい検証ゲートを通過した、平均わずか1〜4回の採用された編集のみで構築されています。
システムへの組み込み時には、この小さなテキストファイルをエージェントに読み込ませるだけです。モデル自体の重みを変更せず、実行時にオプティマイザを呼び出す必要もないため、推論時の追加コストはゼロに抑えられます。これは、実運用を想定するエンジニアにとって非常に魅力的な特長と言えるでしょう。
| Benchmark | Initial (tok) | Final (tok) | Edits | Train tokens | Cost / pt |
|---|---|---|---|---|---|
| SearchQA | 16 | 857 | 4 | 213.8M | 37.9M |
| SpreadsheetBench | 224 | 1,995 | 4 | 21.4M | 0.6M |
| OfficeQA | 145 | 883 | 1 | 20.8M | 1.1M |
| DocVQA | 81 | 959 | 3 | 188.2M | 46.4M |
| LiveMath | 154 | 379 | 1 | 23.2M | 3.6M |
| ALFWorld | 516 | 1,321 | 2 | 59.3M | 15.9M |
5. 考察
実運用を見据えた際、SkillOptはどのようなポテンシャルと限界を持っているのでしょうか。論文で示されているオプティマイザのモデル規模と性能のトレードオフ、およびシステム導入時の適用条件について考察します。
モデル能力とコストのトレードオフ
SkillOptの学習プロセスでは、軌跡を分析してスキルを修正する「オプティマイザ」として、高性能なフロンティアモデル(GPT-5.5など)を使用することが推奨されています。しかし、運用コストの都合から、エージェントと同じ小規模なモデルをオプティマイザとして起用したいケースもあるはずです。 興味深いことに、小規模モデルをオプティマイザに起用した場合でも、フロンティアモデルを用いた際の改善幅の56〜74%を維持できることが実験結果から判明しています。この理由として、厳格な「検証ゲート」と「編集予算」の仕組みが挙げられます。小規模モデルが誤った修正や過度な書き換えを提案しても、検証ゲートが確実にそれらをブロックするため、着実な改善だけが積み重なります。つまり、高性能なモデルの知識に依存するのではなく、最適化のループ設計自体が性能向上に大きく貢献しているのです。
適用条件とシステム導入時の限界
一方で、SkillOptの仕組みには明確な限界も存在します。 第一に、学習プロセスを回すための「フィードバックシグナル」の要件です。検証ゲートでスキルの良し悪しを自動で評価するためには、出力が正解と完全に一致するかどうかや、プログラムが正常に実行できるかなど、明確な自動検証器が必要となります。そのため、人間の主観による評価が必要なオープンエンドなタスクや、正解の定義が多次元的で複雑なタスクに対しては、現状の枠組みのまま適用することが困難です。 第二に、多様なタスクが混在する複雑なドメインへの対応力です。SkillOptはデプロイの容易さを優先し、意図的に「単一のコンパクトなスキルファイル」を最適化するように設計されています。ですが、様々な種類の異質な手順を無数に必要とするシステムにおいては、1つのテキストファイルにすべてのルールを詰め込む設計そのものがボトルネックになる可能性があります。
おわりに
これまで見てきたように、SkillOptは単なるプロンプトエンジニアリングの延長ではありません。勘や試行錯誤に頼っていたプロンプト作成から、ディープラーニングの手法を応用した「テキストアーティファクトの体系的な訓練」へと、開発のパラダイムを大きく移行させるものです。
最適化によって得られるスキルは、コンパクトな自然言語のファイルとして出力されるため、私たち人間が簡単に中身を読んで解釈できます。さらに、推論時の計算コストを一切増加させずに、様々なモデルや環境で再利用できる高い汎用性も備えています。
LLMをシステムに組み込む際、コストや制御の難しさが壁になることは少なくありません。ですが、モデルの重みではなく「外部の指示書を最適化する」というSkillOptのアプローチは、今後のAIエージェント開発において、実用的かつ非常に強力な選択肢となるはずです。
More Information
- arXiv:2605.23904, Yifan Yang et al., 「SkillOpt: Executive Strategy for Self-Evolving Agent Skills」, https://arxiv.org/abs/2605.23904
関連記事

進化する知能: LLMエージェントの最新動向とエンジニアが知るべき技術的視点
近年、LLM(Large Language Model)エージェントがAI分野において急速に注目を集めています。LLMエージェントは、単にユーザーの入力に応答する従来のAIシステムとは異なり、大規模言語モデルを基盤とし、 […]

Agent-as-a-Judge: 次世代の自律的評価システムに向けたロードマップ
AI評価の分野では、LLM自身の高度な理解力を活用して他のモデルを評価する「LLM-as-a-Judge」が広く普及しています。しかし、AIが生成する回答が高度化し、専門領域における多段階のタスクへと進化するにつれ、単一 […]

MetaGPT: マルチLLMエージェントフレームワークを使ってみる
近年、AI技術は目覚ましい進化を遂げており、特に大規模言語モデル(LLM)の発展がソフトウェア開発の分野に革新をもたらしています。その中でも、MetaGPTは、マルチエージェントシステムを活用してソフトウェア開発の自動化 […]