大規模言語モデルのベンチマーク

Transformerアーキテクチャの導入以降、大規模言語モデル (Large Language Models, LLM) はAI分野に大きな進展をもたらしました。自然言語理解(Natural Language Understanding, NLU)から複雑な論理推論、エージェント機能まで、その性能は急速に拡大しています。
この進化の中で、LLMの客観的な性能評価にはベンチマークが不可欠です。モデル能力の測定、開発指針の提供、技術革新の促進に貢献します。しかし、評価には課題も存在します。データ汚染によるスコア誇張や、文化的・言語的偏見による不公平な評価などが挙げられます。また、プロセス信頼性や動的環境への評価不足も指摘されています。
今回は、「A Survey on Large Language Model Benchmarks」という論文を参考に、ベンチマークの種類や課題、また今後の方向性についてまとめます。
なぜベンチマークが重要なのか?
ベンチマークは、LLM の性能を定量的に測定するための不可欠な評価ツールです。異なるモデル間の能力を客観的に比較する「物差し」としての役割も果たします。単にモデルの優劣を判断するだけでなく、以下のような重要な役割を担っています。
- 開発の指針とボトルネックの特定: ベンチマークを通じて、研究者やエンジニアはモデルの強みと弱みを客観的に比較できます。これにより、技術的なボトルネックを正確に特定することが可能です。アルゴリズムの最適化やアーキテクチャの設計に対して、具体的なデータサポートを提供します。ベンチマークは、モデル開発の方向性を導き、技術革新を促進する上で重要な要素です。
- 信頼性の構築と倫理規範の遵守: 標準化された評価結果は、ユーザーの信頼を構築する上で役立ちます。また、モデルがセキュリティや公平性に関して社会・倫理規範に準拠していることを保証する上でも重要です。
- 汎化能力の評価: LLMの能力は、単一タスクからマルチタスクおよびマルチドメインへと指数関数的に拡大しています。このような背景において、ベンチマークはモデルが未知のタスクや新しいドメインにどれだけ適応できるかという汎化能力を評価するために不可欠です。複雑な推論や指示の理解、ツール使用といった新たな能力の測定にも欠かせません。

LLMベンチマークの主要カテゴリ3選
論文では、283の代表的な大規模言語モデル (LLM) ベンチマークが、その評価軸に基づいて以下の3つの主要カテゴリに分類されています。
一般能力ベンチマーク (General Capabilities Benchmarks)
このカテゴリのベンチマークは、モデルの基本的な言語理解、知識、および推論能力といった汎用的な「知能」を評価することを目的としています。LLMが多様なタスクに対してどの程度広範に機能するかを測定するための出発点となります。
- 評価される側面: コア言語学、知識、推論といった能力が評価対象となります。具体的には、自然言語理解 (NLU) やテキスト生成といった言語処理の基礎から、事実知識の有無、そして複雑な論理的推論能力までを網羅します。
このカテゴリのベンチマークは、モデルの総合的な基礎能力を把握するために不可欠であり、様々なアプリケーションへの適用可能性を測る上で重要な指標を提供します。
メイン特化型ベンチマーク (Domain-Specific Benchmarks)
このカテゴリは、特定の専門分野におけるLLMの知識の深さと、その知識を応用する能力に焦点を当てています。特定の業界向けのアプリケーションを開発する際に、モデルの専門性を評価するために不可欠なベンチマーク群です。
- 主な対象分野: 自然科学、人文社会科学、工学技術などが挙げられます。例えば、自然科学では数学、物理学、化学、生物学といった具体的な学術分野に特化した評価が行われ、人文社会科学では法学、知的財産 (IP)、教育、心理学、金融などの人間中心のドメインが対象となります。また、工学技術の分野ではソフトウェア開発や各種専門工学のタスクが評価されます。
ドメイン特化型ベンチマークは、特定の業務や専門知識が求められる場面でLLMがどれだけ有効に機能するかを、深く、かつ実践的に評価するための基盤となります。
ターゲット特化型ベンチマーク (Target-specific Benchmarks)
このカテゴリは、モデルの安全性、信頼性、エージェント能力といった、特定の機能横断的な側面に焦点を当てて評価を行います。LLMが実世界で責任を持って機能するための非機能要件(セキュリティ、公平性など)や、自律的な行動能力を評価するために用いられます。
- 主な評価側面: リスク、信頼性、エージェント能力などが含まれます。具体的には、モデルが出力する情報の「幻覚」(Hallucination、事実との矛盾や指示からの逸脱)、バイアスや倫理的な逸脱といった「安全性」、敵対的入力に対する「ロバスト性」、そして個人情報などの「データ漏洩」リスクといった側面が評価されます。また、複雑な目標を達成するために自律的に行動する「エージェント」としての能力もこのカテゴリで評価されます。
ターゲット特化型ベンチマークは、LLMを高リスクな実世界のシナリオに展開する際に、その安全性と信頼性、そして自律的な運用能力を検証するための重要なセキュリティチェックポイントとしての役割を担います。
ベンチマークカテゴリの詳細
一般能力ベンチマーク
一般能力ベンチマークは、以下の3つの主要な側面でモデルの性能を評価します。
言語コア能力 (Linguistic Core)
言語コア能力のベンチマークは、LLMが言語の構造、意味、文脈をどれだけ正確に処理できるかを測るために、言語的推論の深さを評価するために改良されてきました。
- 自然言語理解 (NLU):
- テキスト生成:
- マルチターンの対話:
- 多言語対応:
- 常識推論:
- HellaSwag や WinoGrande のようなベンチマークは、人間にとっては当たり前に正解できる一方で、モデルにとっては難しい問題を意図的に作り出しています。これにより、モデルが単なる単語のつながりに頼るのではなく、日常的な常識や状況に即した知識を用いて、文脈の中で「誰が何をしているのか」を正しく判断する力が求められるようになります。
- 包括的・詳細な評価:
知識能力 (Knowledge)
モデルの知識能力は、広範な実世界情報をどれだけ正確に記憶し、検索できるかを評価する、現代LLMの基礎的な柱です。これは、モデルが膨大な訓練コーパスから同化した知識の範囲と信頼性を定量化する重要な軸となります。この評価は通常、「閉鎖系試験」のような形式をとり、モデルが自身の内部パラメータ化された知識のみに依存することを強制します。
- 総合的な知識:
- 専門家レベルの知識:
- 試験ベース:
- AGIEval や GAOKAO-Bench は、大学入学試験や専門資格試験といった人間にとって高難度の試験から直接問題を収集し、人間の基準に基づいた評価を行います。
- 多言語・多モーダル知識:
- 階層的知識:
- KoLA は、知識を「想起、理解、応用」のレベルに分解する階層的なフレームワークを提案し、単一の精度スコアを超えた詳細な分析を提供。
推論能力 (Reasoning)
推論能力は、形式論理、常識的推論、および応用的な問題解決にわたる、LLMのより高次の思考能力を評価するものです。これは、モデルの認知的限界と実用的な可能性を理解するために不可欠な評価軸です。
- 論理的推論:
- RuleTaker、ProofWriter、FOLIO、LogicNLI、LogicPro などは、明確な論理的正確さを追求し、制御された環境で推論の基礎を評価
- 単純な演繹的ステップから、LogicPro のような複雑な多段階かつプログラム的な推論へと進化しています。
- 専門的・常識的推論:
- StrategyQA、ANLI、CommonGen、HellaSwag などは、形式論理を超えた、人間が日常的に行うニュアンスに富んだ推論(因果関係、常識知識、数学的計算)を評価
- この分野は比較的新しく、LLMベースの評価者やマハラノビス距離のような専門的な指標が導入されています。
- 数学的推論: MathQA、GSM-Symbolic、MathEval、Mathador-LM、MATH、GSM8K などが挙げられます。
- 因果推論: Corr2Cause や CLadder、CRAB などが因果関係の理解を評価します。
- 応用的・文脈的推論:
- ARC、SuperGLUE、HotpotQA、BIG-Bench Hard、LiveBench などは、情報検索、統合、推論、合成の全パイプラインを評価する、実世界のタスクを模倣した複雑な多面的な問題に焦点を当てています。
- これらのベンチマークはウェブスケールのデータに基づき、統合的推論を要求します。
- LiveBench のように、データ汚染を防ぐためにライブのプライベートクエリを使用する動的なベンチマークの重要性が増しています。
ドメイン特化型ベンチマーク (Domain-Specific Benchmarks)
このカテゴリは、特定の専門分野におけるLLMの知識の深さと、その知識を応用する能力に焦点を当てています。特定の業界向けアプリケーションを開発する際に、モデルの専門性を評価するために不可欠なベンチマーク群です。
主な対象分野として、自然科学、人文社会科学、工学技術などが挙げられます。ドメイン特化型ベンチマークは、特定の業務や専門知識が求められる場面でLLMがどれだけ有効に機能するかを、深く、かつ実践的に評価するための基盤となります。
自然科学 (Natural Sciences)
自然科学分野のベンチマークは、LLMに対して抽象的な推論、記号操作、複雑な因果連鎖の追跡能力を要求します。数学、物理学、化学、生物学といった論理的で構造化された知識体系が、モデルの知識ベースと推論能力にとって大きな課題となります。
- 数学 (Mathematics):
- 評価の難易度は、小学校レベルの文章問題 (GSM8K) から、高校・大学入試レベル (MATH)、学部レベル (U-MATH)、さらにはトップレベルの数学者が設計した最先端の数学問題 (FrontierMath) へと段階的に上昇しています。
- 物理学 (Physics):
- 数学的な計算能力だけでなく、物理法則への深い概念的理解が求められます。図やグラフの分析を必要とする多モーダルな問題を含むベンチマーク (PhysReason, PhysicsArena) が重要な役割を果たしています。PhysicsArenaでは、変数特定、物理プロセスモデリング、推論ベースの解決という3段階で評価する詳細なパラダイムも導入されています。
- 化学 (Chemistry):
- 伝統的な問題解決能力に加え、事実の正確性、文献理解、安全性といった社会的側面が重視されます。不正確な化学情報が実世界で直接的な害につながる可能性があるため、モデルの信頼性や倫理的整合性が評価基準に含まれます。
- 例えば、ChemSafetyBenchは、有害な化学知識を扱う際のモデルの安全性と責任を評価する先駆的なベンチマークです。
- 生物学 (Biology):
- 科学文献の読解能力が主に評価されます。
- 特に、遺伝子やタンパク質からなる複雑な生物学的経路の推論能力を問うBioMazeのようなベンチマークは、モデルに複雑なネットワークの理解を要求します。
人文科学・社会科学 (Humanities & Social Sciences)
この分野は人間中心のドメインであり、LLMの共感的理解、倫理的判断、実世界の問題解決能力が評価されます。
- 法学 (Law):
- 法的知識の記憶・理解・応用能力を評価します。LegalBenchは米国の法制度におけるリーガル推論タスクに特化しており、CaseGenは訴訟書類の自動生成能力を評価します。
- 知的財産 (Intellectual Property, IP):
- 特許、著作権、商標など多様な分野を扱います。PatentEvalは特許要約の生成能力を評価し、IPBenchは情報処理から創造的生成までをカバーする包括的なタスク分類を導入しています。
- 教育 (Education):
- 実際の教育現場での応用能力を評価します。EduBenchは、問題解決や個別学習支援といった生徒向けのシナリオから、教材生成といった教師向けのシナリオまで、9つのコアな教育シナリオをカバーしています。
- 心理学 (Psychology):
- 心理カウンセリングのシナリオにおける対話能力 (CPsyCoun) や、LLMが持つ性格や価値観、感情といった人間的な属性を測定するベンチマーク (Psychometrics Benchmark) があります。
- 金融 (Finance):
- 金融ニュースの分析 (BBT-CFLEB) から、深いドメイン知識を要求される株価予測 (PIXIU FLARE)、金融知識と実践能力を総合的に問うFinEvalまで、幅広いタスクが含まれます。
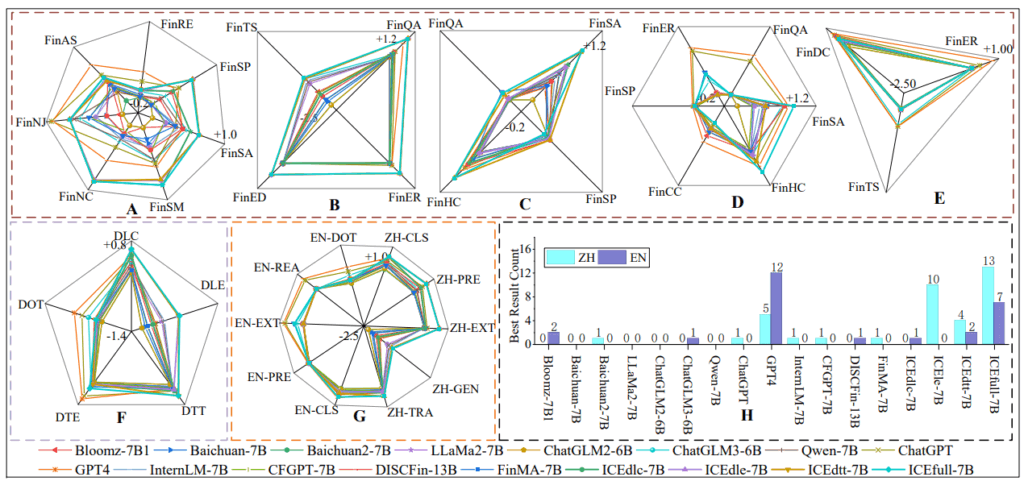
工学・技術 (Engineering & Technology)
工学・技術分野は、LLMの論理的厳密性、機能的正確性、そして深い専門知識を試すための重要な領域です。この分野のアプリケーションは厳密な構文や物理法則に支配されるため、評価フレームワークも成熟しています。
- ソフトウェア開発 (Software Development):
- データベース操作 (Database Systems):
- 自然言語の指示からSQLクエリを生成するText-to-SQL変換が主要な評価タスクです。Spiderがその標準的なベンチマークであり、BIRDはより現実的な企業のワークフローを取り入れて難易度を高めています。
- 専門工学 (Specialized Engineering Disciplines):
- 電気・電子工学: Verilogのようなハードウェア記述言語 (Hardware Description Languages, HDL) の生成能力 (VerilogEval) や、電力システムの複雑な故障診断タスク (ElecBench) を評価します。
- 機械・製造工学: CAD (Computer-Aided Design) ソフトウェアのスクリプト生成能力を評価するCADBenchのようなベンチマークがあります。
ターゲット特化型ベンチマーク (Target-specific Benchmarks)
このカテゴリは、モデルの安全性、信頼性、エージェント能力といった、特定の機能横断的な側面に焦点を当てて評価を行います。LLMが実世界で責任を持って、かつ効果的に機能するための非機能要件(セキュリティ、公平性など)や、自律的な行動能力を評価するために用いられます。これは、LLMを高リスクな実世界のシナリオに展開する際に、その安全性と信頼性、そして自律的な運用能力を検証するための重要なセキュリティチェックポイントとしての役割を担います。
リスクと信頼性 (Risk & Reliability)
LLMが実世界のアプリケーションに導入されるにつれ、幻覚(Hallucination)、バイアス、敵対的入力への脆弱性、プライバシー侵害といったリスクが顕在化しています。リスクと信頼性の評価は、これらの問題を体系的に特定し、定量化することを目的としています。
- 安全性 (Safety)
- 評価内容: LLMは、有用性と無害性のバランスを取るために安全アラインメントに依存していますが、有害コンテンツを含む訓練データに起因する脆弱性を内包しています。安全性の評価では、有害なコンテンツの生成防止能力や、モデルの安全制限を意図的に迂回する「ジェイルブレイク攻撃」への耐性など、モデルの「無害性」と倫理的な振る舞いを保証する能力が問われます。
- 代表的なベンチマーク: 初期のベンチマークは、HateCheckのように手動で作成された静的なテストケースに依存していました。その後、ToxiGenのようにLLMを用いて大規模な敵対的・暗黙的な有害コンテンツを生成するアプローチが登場し、テストの規模と複雑さが向上しました。さらに、JailbreakBenchやHarmBenchは、多様な敵対的プロンプト技術を体系的に統合し、モデルの脆弱性を診断したり、自動レッドチーム評価のための標準フレームワークを提供したりしています。
- 幻覚 (Hallucination)
- 評価内容: LLMの幻覚は、出力が検証可能な事実と矛盾する「事実幻覚」と、ユーザーの指示や提供された文脈から逸脱する「忠実性幻覚」の2つに大別されます。
- 代表的なベンチマーク: TruthfulQAは、人間が一般的に抱く誤解をモデルが模倣する幻覚を特定します。FActScoreは、長文生成の出力を原子的な事実に分解し、外部知識ソースと照合することで事実性を評価します。また、REALTIMEQAは、スポーツや金融など、常に情報が更新される分野において、古い知識に起因する幻覚を評価することに特化しています。
- ロバスト性 (Robustness)
- 評価内容: モデルが意図的に作られた敵対的な入力、プロンプトのわずかな変化、あるいは訓練データとは異なる分布のデータに直面した際に、性能がどれだけ安定しているかを評価します。
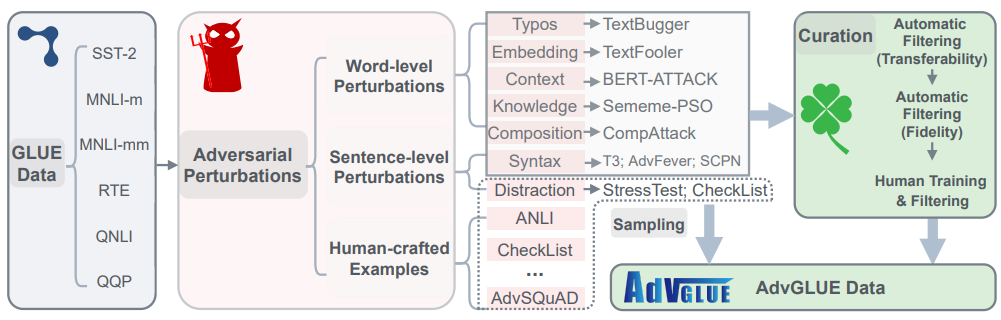
- 代表的なベンチマーク: AdvGLUEは、既存のベンチマークタスクに14種類のテキストベースの敵対的攻撃を適用し、モデルの脆弱性を明らかにしました。PromptRobustは、プロンプトの言い回しをわずかに変えるだけでモデルの出力が大きく変化する現象を調査し、プロンプトに依存しない安定したモデルの必要性を強調しています。
- データ漏洩 (Data Leak)
エージェント能力 (Agent)
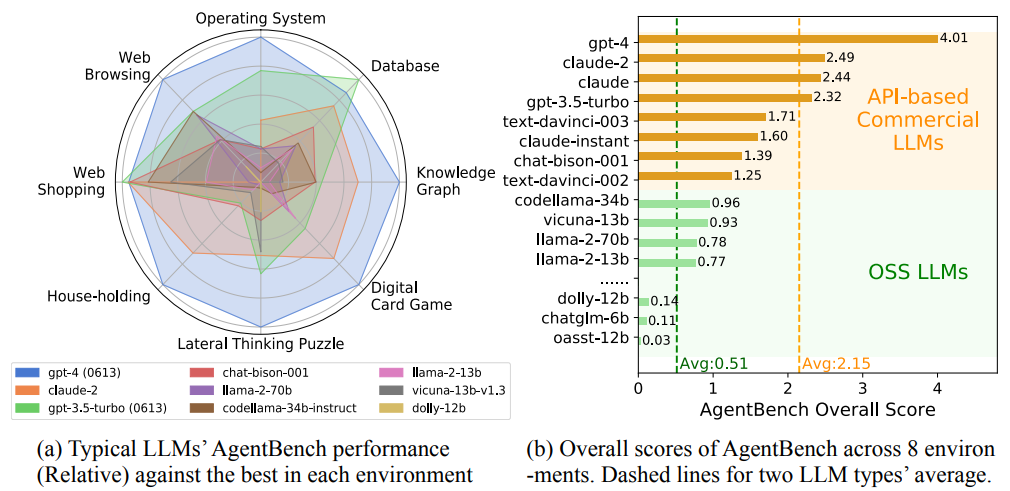
この評価カテゴリは、LLMを単なる受動的な「チャットボット」としてではなく、複雑な目標を達成するために計画を立て、ツールを使用し、外部環境と動的に対話し、自律的に行動する「エージェント」として評価するものです。
- 計画と推論: エージェントが複雑なタスクを複数のステップに分解し、行動計画を立てる能力を評価します。FlowBenchは、構造化されたワークフロー知識を活用して計画を立てる能力を評価し、Robotouilleは、行動の結果が遅れて現れるような非同期環境での計画能力をテストします。
- 外部制御とツール利用: エージェントが外部のツールやアプリケーションを操作してタスクを遂行する能力を評価します。SPA-BenchやMobile-Benchは、スマートフォン上の単一または複数のアプリを操作する能力を測定し、BrowseCompはウェブブラウザをツールとして使い、情報を検索する能力を評価します。
- マルチエージェント連携: 複数のエージェントが協調、競争、交渉を行うシナリオでの能力を評価します。MultiAgentBenchは、様々なタスクにおけるエージェント間の協調行動を評価します。
- 統合的な問題解決: 計画、ツール利用、対話といった複数の能力を統合し、現実世界の複雑な問題を解決する総合的な能力を評価します。AgentBenchは、コーディング、ゲーム、ウェブ操作など複数のドメインにまたがる環境で、多ターンにわたる計画・意思決定能力を評価します。TravelPlannerは、旅行計画という実世界に近いタスクを通じて、ツール利用、情報統合、制約処理といった能力を包括的にテストします。
LLMベンチマークの課題
現在のLLMベンチマークは急速に進化していますが、依然としていくつかの深刻な課題に直面しており、LLMを実世界に展開する上で考慮すべき重要な点です。
データ汚染と「カンニング」問題
多くのベンチマークは、LLMの事前学習データと同じく、大規模なウェブデータから構築されています。そのため、評価データがモデルの学習データに意図せず混入してしまう「データ汚染(Data Contamination)」や「データ漏洩(Data Leakage)」が深刻な問題となっています。
この問題により、モデルが評価用の質問と回答を単に「記憶」してしまい、ベンチマークスコアが実力以上に高く評価される可能性があります。その結果、モデルが未知のタスクや状況にどれだけ適応できるかという真の汎化能力を正確に評価できなくなります。この課題は、知識、推論、自然科学など、多くの分野で顕著です。
この「カンニング」問題に対処するため、専門家がウェブ検索では容易に答えが見つからないように設計した「Google-Proof」なベンチマーク(例: GPQA)や、進行中のプログラミングコンテストの問題を使用するLiveCodeBench、常に新しい非公開データで評価を行うLiveBench のような、動的なベンチマークの開発が進められています。
静的評価とリアルタイム情報の乖離
ほとんどの既存ベンチマークは、特定の時点での知識や状況の静的なスナップショットに基づいています。しかし、現実世界の情報は絶えず変化しています。そのため、モデルが最新のニュースや市場データのような、刻々と変化するリアルタイムの情報をどれだけ正確に理解し、利用できるかを評価するのは困難です。
この課題は、LLMが動的な実世界のシナリオに対応する能力を予測することを難しくし、特に金融、ニュース、医療など、情報の鮮度が重要となるドメインでのLLM運用において大きな制約となります。したがって、静的なデータセットから脱却し、動的かつ継続的な評価を行うフレームワークへの移行が不可欠です。
評価方法の限界と「LLM-as-a-Judge」の課題
現在の評価手法には、いくつかの方法論的な限界が存在します。
- 閉鎖型評価の限界:
多肢選択式質問(MCQA)のような閉鎖型の評価形式は、大規模な評価を自動化しやすくスケーラブルですが、モデルの能力を表面的なレベルでしか捉えられない可能性があります。例えば、モデルが首尾一貫した説明を生成する能力や、自身の回答の不確実性を認識する能力といった、より深い理解力や表現力を測ることは困難です。これにより、真の理解よりもパターンマッチングに長けたモデルが過大評価されるリスクがあります。 - 「LLM-as-a-Judge」の課題:
MT-Bench などで採用されている、GPT-4のような高性能LLMを評価者として利用する「LLM-as-a-Judge」アプローチは、人間の判断と高い相関を示す一方で、その信頼性には懸念が指摘されています。最大の課題は、評価が評価者LLM自身の生成パターンやスタイルを循環的に検証してしまう「自己参照的な罠」に陥るリスクです。これにより、評価対象モデルの真の能力よりも、評価者モデルとの「親しみやすさ」が優先され、評価結果に偏りが生じる可能性があります。実際に、LLMが生成した評価レポート内で自己矛盾が見られるケースも報告されています。
文化的・言語的偏見
多くのベンチマークは、依然として西洋中心・英語中心の視点を反映しており、これが評価の公平性を損なう一因となっています。異なる文化や言語基盤を持つモデルの性能を公平に評価することが難しく、グローバルな応用を目指す上での障壁となっています。
多言語対応のベンチマーク(例: Xtreme, MDIA)が登場しているものの、課題は残ります。特に、言語の構造的な違い(例: 英語のような分析的言語と、形態が豊富な膠着語)が性能評価に歪みをもたらす「類型学的バイアス」が指摘されています。これにより、言語の多様性が単なるメタデータとして扱われ、その本質的な構造が評価に反映されないリスクがあります。法学、金融、心理学 といった専門分野でも、多言語・多文化に対応したベンチマークは依然として不足しています。
プロセス信頼性と説明可能性の欠如
現在の評価の多くは、モデルが生成した最終的な回答の正しさにのみ焦点を当てています。しかし、特に医療、法務、金融といった高リスクなドメインでは、その結論に至った思考プロセスや推論連鎖の信頼性が極めて重要です。
現状では、モデルの思考プロセス(Chain-of-Thought)の忠実性(faithfulness)、論理的一貫性、効率性を評価するための指標や手法が不足しています。モデルがなぜその結論に至ったのかを説明する説明可能性(Explainability)は、透明性と信頼性を確保するために不可欠であり、将来のベンチマークでは、単に出力を評価するだけでなく、その推論プロセス自体を精査することが求められます。
LLMベンチマークの未来
LLMベンチマークは、モデルの進化に合わせて、より洗練された評価へと移行しています。未来のベンチマークは、現在の課題を克服し、より信頼性の高いAIの構築を支援するために、以下の方向性へと発展していくでしょう。
動的かつインタラクティブな評価フレームワークの採用
静的なデータセットに基づく評価は、データ汚染という深刻な課題に直面しています。評価データがモデルの学習データに含まれることでスコアが誇張され、真の汎化能力を測定できない問題です。この課題に対処するため、LLMの評価は、継続的に新しい未見のデータストリームを使用する動的なベンチマークへと移行することが不可欠です。
その代表例が、ライブの非公開ユーザー-クエリを使用する LiveBench や、進行中のプログラミングコンテストの問題を用いる LiveCodeBench です。これらのアプローチは、データ汚染のリスクを本質的に低減します。
さらに、モデルの受動的な知識だけでなく、能動的な適応能力を測るために、インタラクティブな環境での評価が重要になります。例えば、AR-Bench や TextGames のように、エージェントが環境からのフィードバックに基づいて計画し、行動し、戦略を適応させる能力を評価するフレームワークが、モデルの真の汎化能力と適応性を測る上で中心的な役割を担うでしょう。
推論プロセスと説明可能性の重視
現在のベンチマークの多くは、最終的な回答の正しさに重点を置いていますが、これには限界があります。特に医療や法務といった高リスクなドメインでは、結論に至るまでの思考プロセスや推論連鎖の信頼性が極めて重要です。
未来のベンチマークは、最終出力だけでなく、その回答に至るまでの推論プロセスの忠実性(faithfulness)、論理的一貫性、効率性を評価する指標の開発が求められます。この方向性における有望なアプローチとして、モデルが検証可能なプログラム形式で推論を生成する LogicPro のようなプログラムガイド付きの評価が挙げられます。また、モデルの意思決定にどの知識や文脈が影響を与えたかを解明する因果追跡(causal tracing)のような手法も、信頼性と透明性の高いAIシステムを構築する上で不可欠となります。
推論と行動・ツールの統合
LLMの役割は、単なる「知識ベース」から、外部のツールやシステムと対話し、自律的にタスクを遂行する「エージェント」へと進化しています。この変化に伴い、評価の次なるフロンティアは、推論と行動の統合にあります。
未来の評価では、SCITOOLBENCH が示すように、モデルがAPIなどの外部ツールを呼び出して複雑な科学計算を解決する能力や、FEABench のようにシミュレーションソフトウェアを操作して検証可能な結果を導き出す能力が問われます。これは、推論が具体的な物理的またはデジタルな行動に直接影響を与えるシナリオを意味し、推論、計画、およびエージェンシーの融合を評価することに繋がります。
倫理的・社会的価値との整合と包括性
LLMが社会システムに深く統合されるにつれて、評価は技術的な能力測定から、「いかに責任を持って機能すべきか」という問いに答えるものへとシフトする必要があります。モデルの性能評価は、安全性、公平性、プライバシー保護といった社会的な価値との整合性を重視するようになります。
多くの既存ベンチマークが抱える文化的・言語的偏見 を克服し、多言語・多文化に対応した包括的な評価フレームワークの構築が不可欠です。特に、言語の構造的な違いが性能評価に与える「類型学的バイアス」を避け、言語の多様性を単なるメタデータとして扱うのではなく、評価の核心的な変数として組み込む必要があります。これは、グローバルに展開されるLLMアプリケーションの健全な発展のために極めて重要です。
おわりに
今回は、大規模言語モデルのベンチマークについて、その重要性から分類、課題、そして未来の方向性までを包括的に解説しました。ベンチマークが基礎的な言語能力から専門領域の習熟度や安全性といった信頼性まで、LLMの能力の進歩を反映しています。
しかし、一般的なベンチマークが深さを犠牲にして広さを追求する傾向があることや、動的な実世界のリスクを静的な評価では捉えきれないといった課題も浮き彫りになっています。
LLMが社会技術システムに深く統合されるにつれ、評価の焦点は「モデルが技術的に何ができるか」から「いかに責任を持って機能すべきか」へと移行する必要があります。未来のベンチマークには、モデルの進化に対応するダイナミズム、結果を説明する因果関係、偏見を避ける包括性、そしてリスクを予測するロバスト性が求められます。技術的厳密性と社会的価値の整合性が、次世代の信頼できるAIを構築する鍵となります。
More Information
- arXiv:2508.15361, Shiwen Ni et al., 「A Survey on Large Language Model Benchmarks」, https://arxiv.org/abs/2508.15361
関連記事

Ollama: ローカルPCでLLMを動かしてみる!
Ollamaは、ローカルPCでオープンソースの大規模言語モデル(LLM)を簡単に利用できる、非常に魅力的なツールです。今回は、Windows環境にOllamaを導入し、LLMを利用する方法について紹介します。 Ollam […]

LLMLingua: LLMのためのプロンプト圧縮技術
昨今、大規模言語モデル(LLM)は、様々なアプリケーションで活用されています。LLMの能力を最大限に引き出すため、Chain-of-Thought (CoT) や In-Context Learning (ICL)、Re […]

PySR: シンボリック回帰とは何か?
シンボリック回帰(Symbolic Regression、記号回帰とも呼ばれます)は、データを説明する数式を自動的に見つけ出す機械学習手法です。この手法では、関数の形式を事前に決めることなく、与えられたデータに最も合う数 […]