LLMを活用したDeep Researchエージェント開発-設計、アーキテクチャ、実装について

大規模言語モデル(LLM)の急速な進化は、近年、人間が数時間を要するような複雑な調査・分析プロセスを自律的に完了させるDeep Research(ディープリサーチ)エージェントという新しいカテゴリーのAIシステムを誕生させました。これらのエージェントは、従来の検索エンジンや受動的な質問応答システムが持つ限界をはるかに超え、情報収集と知識創出の方法を根本から変革する可能性を秘めています。ビジネス戦略の立案、専門分野の調査、学術研究の文献レビューなど、多岐にわたる領域でイノベーションを劇的に加速させるものと期待されています。
今回は、このDeep Researchエージェントについて、その基本概念から設計原則、主要なアーキテクチャコンポーネント、そして具体的な実装アプローチを解説します。さらに、開発における技術的課題とその解決策も詳細に掘り下げます。
従来システムとDeep Researchの違い
近年、大規模言語モデル(LLM)の発展を背景に登場したDeep Research エージェントは、従来のシステムとは一線を画す革新的な情報探索技術です。このセクションでは、Deep Researchエージェントの具体的な定義とその主要な特徴を説明し、既存の検索エンジンやRetrieval-Augmented Generation(RAG)システムとの違いについて詳細に解説します。
Deep Researchエージェントの定義と主要な特徴
Deep Researchエージェントは、LLMを認知コアとして活用し、動的な推論、適応的な計画、多段階の情報検索とツール利用、そして構造化された分析レポートの生成を通じて、複雑な情報収集タスクに取り組むAIエージェントと定義されます。これは、人間が数時間~数週間を要するような複雑な調査・分析プロセスを、わずか数分で自律的に完了させる、プロアクティブなAIシステムの到来を告げるものです。従来のシステムがユーザーのクエリに受動的に応答するのに対し、Deep Researchエージェントは、与えられた高レベルの目標を、人間が行うような多段階の調査・分析プロセスに自律的に分解し、実行します。その最終的な成果は、単なる情報の一覧ではなく、要点が整理され、論理的に構成された完成度の高いレポートである点が特徴です。
その主な機能は以下の通りです。
- 多段階の調査と情報統合: ユーザーのクエリを、必要な調査範囲を定義した複数のステップに分解します。各ステップで信頼性の高い情報源からデータを収集・分析し、得られた情報を反復的に統合・要約します。このプロセスは、人間が思考を巡らせるかのように、次に探求すべき情報や矛盾点を特定しながら進行します。
- 多様なデータ形式への対応: テキスト情報だけでなく、PDF、画像、グラフ、図表といった視覚情報も読み解き、分析する能力を備えています。これにより、より深い知見の獲得が可能となります。
- 自動レポート生成: 調査完了後、要約や出典情報を含む完成度の高いレポートを自動で生成します。この機能により、調査結果を即座に活用できる形にすることで、作業効率を劇的に向上させます。

従来の検索エンジン、RAGシステムとの比較
Deep Researchエージェントは、そのアプローチが従来の検索エンジンやRAGシステムとは根本的に異なります。
RAGの課題: 従来のRAGシステムは、ユーザーの質問を直接ベクトル化し、事前にインデックス化された限定的なドキュメント群(コーパス)とのマッチングを行います。このアプローチは、社内文書のQ&Aなど、特定のドメイン知識を補強する目的には非常に効果的です。しかし、複数の要素を含む複雑な質問に対しては検索精度が著しく低下するという課題を抱えています。また、リアルタイムの情報を参照するには不向きであり、あくまで事前にインデックス化されたデータに依存します。RAGでは、情報検索と推論が離散的かつ連続的な段階で発生しますが、Deep Researchエージェントでは、これらが相互依存的に連続的に共進化する点が異なります。
Deep Researchエージェントの計画モジュール: Deep Researchエージェントの最大の革新は、「計画モジュール」の存在です。このモジュールは、ユーザーの質問に含まれる複数の要素を分解し、それぞれに対応するサブクエリを生成します。これにより、RAGが苦手とする複雑な、多要素を含む質問に対しても、効果的に回答を生成することが可能になります。この計画モジュールは、タスクを解決可能なサブタスクに分解するメタLLMとして機能し、より複雑な問題に対応できるエージェントの基盤を築いています。
リアルタイム性: Deep Researchエージェントは、リアルタイムでのウェブ検索と情報収集を前提として設計されています。これにより、最新のニュースやトレンドといった、RAGのコーパスには含まれない鮮度の高い情報に基づいた調査が可能です。
AI主導の検索プロセス: 従来の検索やRAGがユーザー主体の検索であるのに対し、Deep ResearchはAI主体で検索プロセスを進行させます。この特性は、ユーザーが特定の分野について深く知らない場合でも、エージェントが自律的に必要な情報を掘り下げてくれるため、より深い知見の獲得につながります。
これらの違いを以下の表にまとめます。
| 特徴 | Deep Researchエージェント | 従来の検索エンジン | RAGシステム |
|---|---|---|---|
| 自律性 | AI主導(プロアクティブ) | ユーザー主導(受動的) | ユーザー主導(受動的) |
| 計画能力 | 多段階の複雑な計画 | 単一クエリ(単一ステップ) | 単一クエリ(単一ステップ) |
| 主要な知識源 | パブリックウェブ(リアルタイム)と内部データ | パブリックウェブ(リアルタイム) | 限定された事前インデックス化コーパス |
| 推論能力 | 複雑な情報統合、多段階の自己修正 | 単純なキーワードマッチング | 文脈に沿った情報補強 |
| 主要な出力 | 構造化されたレポート、洞察 | 関連ウェブページのリスト | 質問への直接回答 |
Deep Researchのコア技術
Deep Researchエージェントは、複雑な情報収集タスクを自律的に遂行するために、いくつかの高度なコア技術を統合しています。これらの技術は、従来の検索システムや受動的なAIアシスタントとは一線を画す、プロアクティブな問題解決能力の基盤となります。
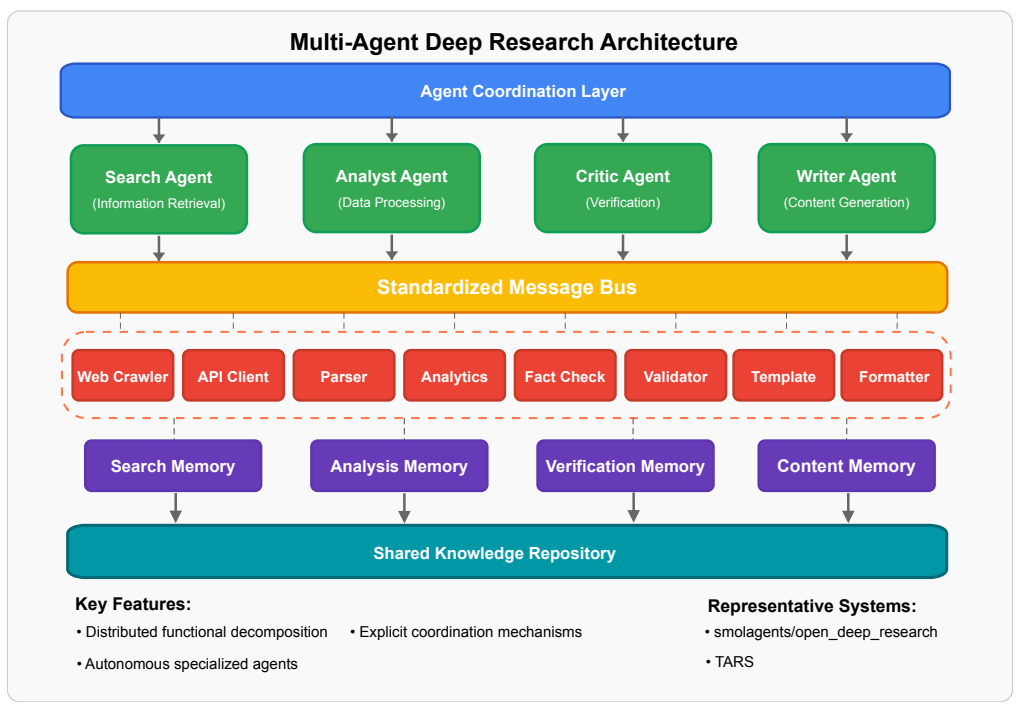
マルチエージェントシステム(MAS)フレームワーク
Deep Researchエージェントが高度なタスクを効率的に処理できるのは、その背後にあるマルチエージェントシステム(MAS)のおかげです。単一のエージェントでは、複雑なリサーチタスクの規模、複雑性、および並列性を効率的に処理することは困難であり、MASはこの課題を解決します。MASは、大規模な調査タスクを複数の小さな、専門化されたサブタスクに分解し、それぞれを目的別に構築された個別のエージェントに割り当てます。これにより、タスク完了までの時間を短縮し、トークン負荷を分散させることが可能になります。
高度な推論・計画パラダイム
Deep Researchエージェントの知能を測る指標は、その推論と計画能力の洗練度です。単純なChain-of-Thought (CoT)のような線形的な思考プロセスでは、複雑なタスクを効率的に管理することはできません。
- Tree-of-Thoughts (ToT): ToTは、複数の推論経路を並行して探索し、有望な経路を深掘りし、効果のない経路を途中で切り捨てる非線形的なアプローチです。
- Graph-of-Thoughts (GoT): GoTはToTのさらに進んだ形態であり、推論ステップを動的な有向非巡回グラフ(DAG)として表現します。これにより、複雑な依存関係や、さらなる分析を必要とするサブ問題のみを選択的に展開することが可能になります。GoTは、CoTやToTの利点を統一的なフレームワークに統合することで、計算リソースが最も必要な場所に割り当てることを可能にします。また、GoTのような構造化推論は、マルチエージェントシステムのアルゴリズム的な基盤を形成し、タスクを構造化されたサブ問題に分解し、依存関係を管理するための枠組みを提供します。
ツール利用と環境インタラクション
LLMが外部ツールや環境と連携する能力は、Deep Researchエージェントの重要な要素です。
- Model Context Protocol (MCP): オープンスタンダードであるMCPは、AIエージェントが「プラグアンドプレイ」でツールを利用できるマーケットプレイスの形成を可能にします。これにより、カスタムツールの統合にかかる開発リソースを削減し、コアコンポーネントの開発に集中することを可能にします。
- 情報源の活用: Deep Researchエージェントは、LLMを認知コアとして活用し、APIベースの検索とブラウザベースのウェブ探索を組み合わせて情報を収集します。APIベースの検索(例:Google Search API, arXiv API)は、構造化された高速かつ効率的なデータ取得に優れますが、ブラウザベースのウェブ探索は、人間のようなウェブページ操作をシミュレートし、動的または非構造化コンテンツのリアルタイム抽出を可能にします。
主要システムの実装例
主要なDeep Researchシステムは、異なるアプローチでこれらのアーキテクチャを実現しています。
- Deep Cognition: このシステムは、人間とAIのインタラクション自体をインテリジェンスの根本的な次元として再概念化し、Deep Researchタスクにおける「認知オーバーサイト」パラダイムを提唱しています。AIの推論を可視化し、任意の時点での介入を可能にする透明で制御可能かつ中断可能なインタラクション、きめ細かい双方向対話、そしてシステムがユーザーの行動を観察・適応する共有された認知的コンテキストという3つの主要なイノベーションを実装しています。ユーザー評価では、透明性、きめ細かいインタラクション、リアルタイム介入などの指標でベースラインを大幅に上回る性能を示しました。
- OpenAI Deep Research: 強化学習ベースでファインチューニングされたo3推論モデルを中心としたシングルエージェントアーキテクチャを採用しています。動的適応型の反復的な研究ワークフロー、強化されたコンテキストメモリと堅牢なマルチモーダル処理能力、そしてウェブブラウジングと組み込みプログラミングツールを組み合わせた包括的なツールチェーン統合が特徴です。これにより、複雑な多段階のタスクを自律的に完了させることが可能です。
- Google Gemini Deep Research: Gemini 2.0/2.5 Proを基盤モデルとし、100万トークンまでのコンテキストウィンドウをサポートしています。強化学習によるファインチューニングで計画と適応型研究能力が向上し、数千の論文を効率的に分析し、体系的な文献レビューを自動化する能力を持っています。
- Grok DeepSearch: リアルタイム情報検索とマルチモーダル推論を組み合わせたフレームワークで、低品質情報のフィルタリング、マルチモーダル入力収集、クロスソース検証、マルチモーダル統合を行うセグメントレベルのモジュール処理パイプラインを提供します。また、軽量な検索と集中的な分析モードを適応的に切り替える動的リソース割り当ての機能も備え、多層的な整合性検証や自己反省機能を通じて、事実の正確性を高めています。
技術的課題と解決策
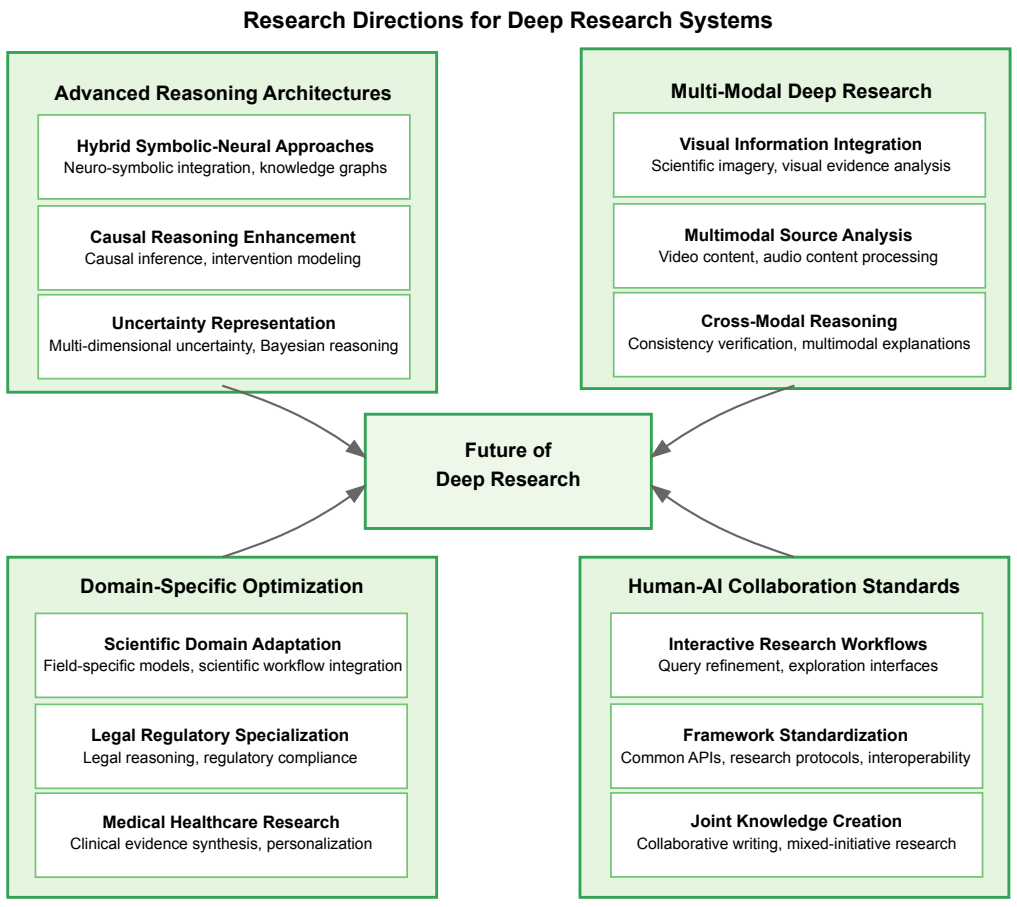
Deep Researchエージェントは、高度な情報収集と分析を自律的に行う一方で、その開発と運用にはいくつかの重要な技術的課題が存在します。これらの課題への対処が、エージェントの信頼性、効率性、および実用性を決定します。
ハルシネーション(事実の不正確性)対策
ハルシネーション、すなわち事実に基づかない情報を生成する現象は、Deep Researchエージェントの信頼性にとって最大の脅威です。特に、調査結果の正確性が生命線となる専門分野では、多層的な対策が不可欠です。
- プロンプト設計: LLMに対し、不明な場合は「わかりません」と回答する、推測や仮説を禁止するなどの明確な指示を与えることで、ハルシネーションを抑制できます。
- RAGの実装: エージェントの回答をモデルの内部知識に依存させるだけでなく、外部の信頼できる情報源から検索・参照したデータに「グラウンディング」させることは、ハルシネーションを大幅に削減する最も効果的な手法の一つです。
- マルチエージェントによるクロスチェック: 複数の専門化されたエージェントが互いの出力を事実確認する手法は、システム全体の信頼性を高めます。例えば、Grok DeepSearchは、各ソースの信頼性を評価し、複数の情報源で主要な主張を検証することで、単一ソースからのエラーを大幅に削減しています。また、自己反省機能を通じて、モデルが矛盾や不確実性を検出した場合に検索戦略を再計画し、以前の推論を修正することが可能です。
長時間タスクにおけるオーケストレーションと状態管理
Deep Researchエージェントは、人間が数時間かけて行うような多段階の調査・分析プロセスを数分間で自律的に実行するため、数分間にわたる長時間実行タスクを処理します。このため、状態管理、障害からの回復、最終出力の一貫性確保が重要です。
- 状態管理: オーケストレーターはすべてのサブタスクの進捗と結果を共有された状態で管理する必要があります。解決策の一つとして、「仮想ファイルシステム」を共有ワークスペースとして利用し、エージェント間で情報を蓄積・共有する方法があります。
- 障害回復: 単一エージェントの失敗によってタスク全体が最初からやり直されることのないよう、システムは堅牢な非同期タスクマネージャーを備えている必要があります。これにより、タスクを中断することなく、エラーから適切に回復し、作業を継続できます。
- タスクの調整と重複: 指示が不明確な場合、サブエージェントは作業を重複させたり、重要な情報を見逃したりする可能性があります。これを防ぐためには、オーケストレーターに明確な目標、出力形式、タスクの境界を詳細に定義することが不可欠です。
コスト、パフォーマンス、スケーラビリティの最適化
Deep Researchエージェントは、その多段階の性質と多数のLLM呼び出しにより、リソース集約的なシステムです。そのため、計算リソースとトークン使用量の賢明な最適化が不可欠です。
- 並列処理: マルチエージェントアーキテクチャは、作業を複数のエージェントに分散させ、並列処理を可能にすることで、タスク完了までの時間を短縮し、トークン負荷を分散させます。
- スケーリングルール: クエリの複雑性に応じてオーケストレーターが適切なリソースを割り当てるように、プロンプトに明示的なルールを組み込むことが重要です。これにより、単純な事実調査に過剰な計算リソースを浪費することを防げます。
- ハイブリッドモデル戦略: 小さく安価なモデルを初期のタスクや情報検出に利用し、より強力で高価なモデルを複雑な推論に限定的に使用するハイブリッドなアプローチも、コスト効率の高い対策として有効です。
Human-AI Collaboration (人間とAIの協調)の重要性
Deep Researchの進歩は、純粋な自律性のみでは達成されず、補完的な人間の判断と機械の処理能力を活用する「認知的パートナーシップ」から高度なインテリジェンスが生まれると示唆されています。
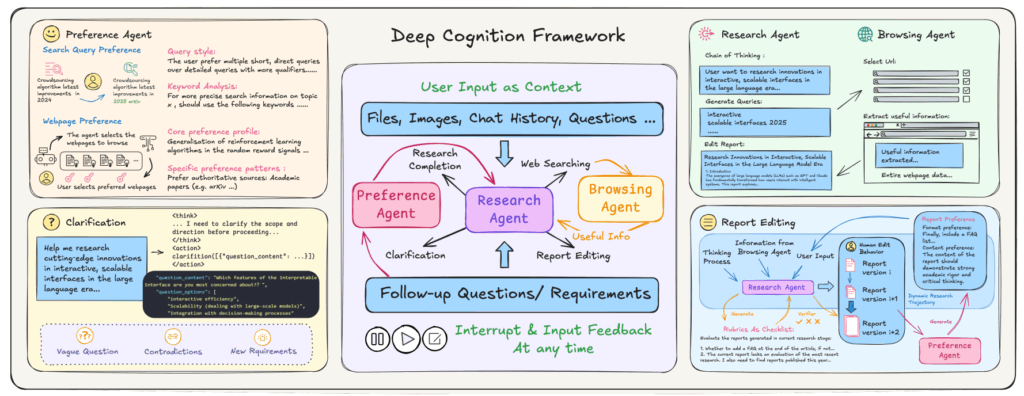
- Deep Cognitionの「認知オーバーサイト」パラダイム: Deep Cognitionは、人間とAIのインタラクション自体をインテリジェンスの根本的な次元として再概念化し、「認知オーバーサイト」パラダイムを提唱しています。これは、人間がAIの思考プロセスを戦略的な介入を通じてガイドするモードであり、人間が指示を出す役割から認知的な監視者に変化します。
- 人間の専門知識の統合: 従来のシステムが採用する「入力-待機-出力」パラダイムでは、不透明な処理が人間とAIのコラボレーションを阻害するため、重要な瞬間に人間のドメイン専門知識を活用できることが求められます。
- 透明性、リアルタイム介入、きめ細かいインタラクションの優位性: Deep Cognitionは、AIの推論を可視化し、任意の時点での介入を可能にする透明で制御可能かつ中断可能なインタラクション、きめ細かい双方向対話、およびシステムがユーザーの行動を観察・適応する共有された認知的コンテキストという3つの主要なイノベーションを実装しています。ユーザー評価では、Deep Cognitionが透明性、きめ細かいインタラクション、リアルタイム介入などの指標で従来のシステムを大幅に上回る性能を示しました。
- ユーザーの「ハンズオン」と「ハンズオフ」モードの切り替え: ユーザー行動分析では、参加者が研究フェーズに応じて、戦略的に手動介入(「ハンズオン」モード)とAIに任せる(「ハンズオフ」モード)を切り替えていることが明らかになりました。これらの知見は、AIの進歩が純粋な自律性だけでなく、人間とAIの協力関係によってさらに促進されることを示唆しています。
実践的アプローチとツール
Deep Researchエージェントの開発を検討する機械学習エンジニアのために、その性能を客観的に評価し、効率的に構築するための実践的なアプローチと利用可能なツールを以下に紹介します。
Deep Researchシステムの評価ベンチマーク
Deep Researchシステムの性能を客観的に評価することは、開発プロセスにおいて不可欠です。
- LiveDRBench: 科学トピックや公共の関心事に関する検索・推論の集中度が高い100のクエリで構成され、主要な主張の精度と網羅性で評価されます。OpenAIのモデルが平均F1スコア0.55で最高の性能を示しました。
- BrowseComp / BrowseComp-ZH: マルチステップのオープンエンドなウェブ検索能力を評価するベンチマークです。回答が意図的に難しく設定されており、高度な推論と戦略的計画を要求します。BrowseComp-ZHは中国語ウェブに特化しており、OpenAI Deep Researchは高いスコアを達成しています。
- Humanity’s Last Exam (HLE): 既存の知識やオンライン検索だけでは解決できない専門家レベルの質問に焦点を当て、Deep Researchエージェントの深い推論能力をテストします。OpenAI Deep Researchは26.6%、Perplexity Deep Researchは21.1%の正答率を報告しています。
- DeepResearch Bench: レポートの網羅性、洞察力、可読性、指示への準拠といった質をLLMジャッジで評価します。Open Deep Researchは、このベンチマークで全体スコア0.4344を達成し、#6位にランクインしています。
オープンソースフレームワークの活用
カスタムエージェントをゼロから構築する労力を削減するため、既存のオープンソースフレームワークの活用が推奨されます。
- LangChain: 「ディープエージェント」構築のための基盤フレームワークとして注目されており、システムプロンプト、計画ツール、サブエージェントの生成、仮想ファイルシステムなど、Deep Researchエージェントの中核コンポーネントを内蔵しています。
- LlamaIndex: 特にエンタープライズデータ上の知識アシスタント構築に特化しており、社内文書や複雑な財務報告書などの独自のデータを効率的に解析・索引化する能力で知られています。
- GPT Researcher: ウェブおよびローカルでのDeep Researchを行い、引用付きの詳細なレポートを生成する自律エージェントです。ツリーライクな探索パターンを採用し、並列処理によってタスク完了までの時間を短縮します。
- AI-Researcher: 文献レビューからアイデア生成、アルゴリズム設計・実装、結果分析、そして論文作成に至るまで、科学研究のライフサイクル全体を自動化する包括的な研究エコシステムを提供しています。Claude, OpenAI, Deepseekなど複数のLLMプロバイダーをサポートしています。
- Open Deep Research (ODR): ユーザーからの自然言語プロンプトを受け取り、インターネットベースのコンテンツを自律的に検索・利用してプロンプトに対応するシステムです。改善版のODR+では、質問分解、反復的なサブソリューション検索、応答合成の3つのモジュールを導入し、複雑なマルチホップ質問への対応能力を向上させています。
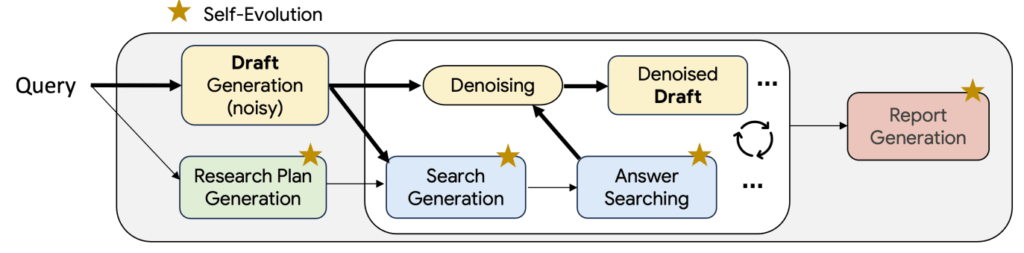
Test Time Diffusion Deep Researcher (TTD-DR)
TTD-DRは、人間の研究プロセス(検索、推論、複数回の改訂という反復的な性質)に着想を得た、複雑な研究レポート生成のためのフレームワークです。これは、レポート生成を拡散プロセスとして概念化し、初期のドラフトを外部情報を取り込む「デノイジング(ノイズ除去)」によって繰り返し洗練します。さらに、エージェントワークフロー内の各コンポーネント(研究計画、質問生成、回答、最終レポート生成)は自己進化的アルゴリズムによって最適化され、高品質なコンテキストを提供します。TTD-DRは、広範なベンチマークで最先端の結果を達成し、OpenAI Deep Researchを凌駕する性能を示しています。
おわりに
Deep Researchエージェントは、LLMの推論能力を最大限に活用し、人間の行うような複雑な調査・分析プロセスを自動化し、構造化されたレポートを生成する最先端のAI技術です。これは情報探索と知識合成のパラダイムを根本から変革し、学術研究、市場分析、ジャーナリズムといった幅広い分野に大きな影響を与えるでしょう。
今後、この分野はさらに急速な進化を遂げると予測されており、機械学習エンジニアは以下の研究・開発領域に注目することが推奨されます。
- 推論能力の向上: 自己評価と自己修正が可能な、GoT(Graph-of-Thoughts)に代表されるような、より洗練された推論モデルへの移行が進むと考えられます。
- ツールエコシステムの拡大: MCP(Model Context Protocol)のようなオープンプロトコルが普及するにつれて、AIエージェントが「プラグアンドプレイ」で利用できるツールのマーケットプレイスが形成され、開発の柔軟性がさらに高まるでしょう。
- コストとスケーラビリティの最適化: 長時間実行タスクをよりコスト効率良くするための研究が継続的に行われ、新たなモデルアーキテクチャや効率的な並列化手法が登場する可能性があります。
- マルチモーダル機能の強化: エージェントは、静的な画像だけでなく、動画、音声、センサーデータといった多様な形式の情報をリアルタイムで処理し、研究分野だけでなく、ロボティクスや自律システムといった領域へと応用範囲を広げていくでしょう。
- ヒューマンAIコラボレーションの継続的な重要性: 人間の専門知識と判断をシステムに統合するための透過的かつ制御可能なハイブリッドフレームワークの開発は、引き続き重要な研究課題です。Deep Cognitionのようなシステムは、人間がAIの思考プロセスを戦略的に監視・介入することで、共同作業の効率を大幅に向上させることを示しています。
Deep Researchエージェントの時代は、自律的かつ知的に世界に働きかける能力に価値が見出される、新たな技術エコシステムの到来を意味します。
More Information
- arXiv:2506.12594, Renjun Xu et al., 「A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications」, https://arxiv.org/abs/2506.12594
- arXiv:2506.18096, Yuxuan Huang et al., 「Deep Research Agents: A Systematic Examination And Roadmap」, https://arxiv.org/abs/2506.18096
- arXiv:2506.18959, Weizhi Zhang et al., 「From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents」, https://arxiv.org/abs/2506.18959
- arXiv:2507.15759, Lyumanshan Ye et al., 「Interaction as Intelligence: Deep Research With Human-AI Partnership」, https://arxiv.org/abs/2507.15759
- arXiv:2507.16075, Rujun Han et al., 「Deep Researcher with Test-Time Diffusion」, https://arxiv.org/abs/2507.16075
- arXiv:2508.04183, Abhinav Java et al., 「Characterizing Deep Research: A Benchmark and Formal Definition」, https://arxiv.org/abs/2508.04183
- arXiv:2508.10152, Doaa Allabadi et al., 「Improving and Evaluating Open Deep Research Agents」, https://arxiv.org/abs/2508.10152
- arXiv:2508.12752, Wenlin Zhang et al., 「Deep Research: A Survey of Autonomous Research Agents」, https://arxiv.org/abs/2508.12752
関連記事

scikit-upliftで始めるアップリフトモデリング入門
データ駆動型の意思決定において、機械学習モデルは「どの顧客が商品を購入する可能性が高いか」という相関関係の予測に広く活用されています。しかし、マーケティング施策や介入の予算を真に最適化するためには、「我々の施策(介入)に […]

LLM時代の自律型コーディング・エージェントはソフトウェア開発の在り方をどのように変えるか?
大規模言語モデル(LLM)の目覚ましい進化は、ソフトウェア開発(Software Development)の領域に根本的な変化をもたらしています。これまで、AIによるコーディング支援の多くは、自然言語の記述を静的なコード […]

機械学習における分布シフト(分布外データ)への対応
機械学習(ML)モデル、特に深層ニューラルネットワーク(DNN)は、コンピュータービジョンや自然言語処理といった多岐にわたる分野で、これまでにない成功を収めています。これらのモデルは通常、i.i.d.(独立同分布)という […]