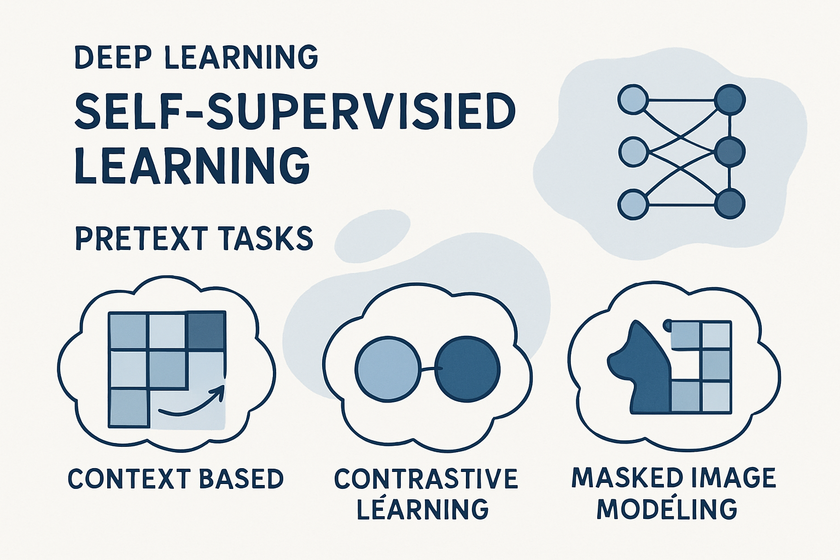
アノテーション不要 - 機械学習エンジニアのための自己教師あり学習入門
近年、深層学習は様々な分野で目覚ましい進歩を遂げていますが、その成功の多くは大量のラベル付きデータに大きく依存しています。しかし、このデータの収集とアノテーション作業は非常に費用と時間がかかり、さらにアノテーションのバイアスやデータプライバシーの問題も引き起こす可能性があります。例えば、高品質な画像セグメンテーションデータセット一つを構築するだけでも、数百万ドル規模の費用が必要とされるほどです。
こうした課題を解決する強力なアプローチとして、自己教師あり学習(Self-Supervised Learning: SSL)が注目を集めています。SSLは、人間による手動のアノテーションを必要とせず、大規模な教師なしデータから汎用的な表現を学習することを目的とした教師なし学習の一種です。データ自体が持つ相関関係から「擬似ラベル」や「事前タスク」と呼ばれる教師信号を自動的に生成し、それを用いてモデルを訓練します。
SSLは、コンピュータビジョン(CV)や自然言語処理(NLP)の分野で大きな成功を収め、近年では音声・言語処理、推薦システム、時系列分析、表形式データなど、多岐にわたるドメインへと応用範囲を広げています。特に近年目覚ましい発展を遂げ、その性能は一部の教師あり学習手法に匹敵、あるいは凌駕するまでになっています。
実務者にとって、SSLの導入は、データ収集とアノテーションにかかる労力を大幅に削減し、よりロバストで汎用性の高いAIモデルを効率的に構築するための鍵となります。本記事では、この革新的な学習パラダイムである自己教師あり学習の基本から応用までを、実践的な視点を踏まえつつ解説します。
自己教師あり学習の基本~事前タスクと擬似ラベル~
自己教師あり学習(SSL)がどのように機能するのか、その基本的な枠組みを理解することは、実践への第一歩です。SSLは、人間による手動のアノテーションなしに、大量の未ラベルデータから有用な情報や汎用的な特徴表現を学習することを目的としています。
SSLの一般的なパイプライン
SSLのプロセスは、主に2つのフェーズで構成されます。
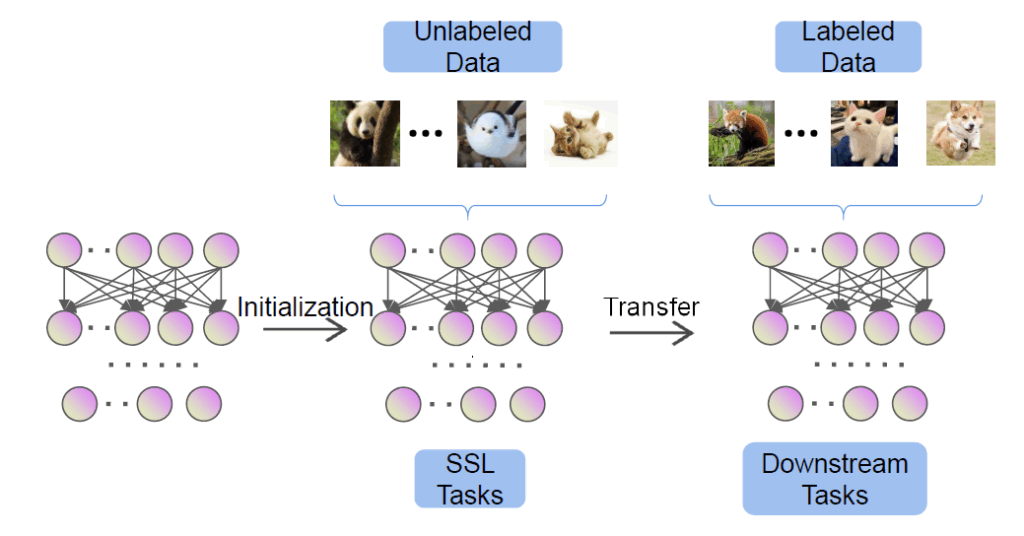
- 事前学習(Pre-training)フェーズ: まず、大量の未ラベルデータを使用してモデルを学習させます。このフェーズでは、データ自体が持つ構造やパターンから「教師信号」を自動的に生成し、それを使ってモデルを訓練します。
- 下流タスク(Downstream Task)フェーズ: 事前学習で得られたモデルは、特定の目的のために用意された少量のラベル付きデータを用いて、ファインチューニングされるか、あるいは直接評価されます。
事前タスク(Pretext Task)とは
SSLの中心となる概念が「事前タスク(Pretext Task)」です。これは、モデルがデータから汎用的な表現を学習するために設計された、補助的なタスクです。事前タスクは、それ自体が最終的な目標ではありませんが、これを解く過程でモデルが入力データの高レベルな理解を獲得し、結果として堅牢で汎化可能な特徴を学習できるように設計されています。
例えば、画像の一部を隠して残りの部分から隠された部分を予測する「マスク予測」や、画像を回転させてその回転角度を予測する「回転予測」などが事前タスクとして用いられます。これらのタスクは、モデルが画像の局所的な特徴だけでなく、全体的な構造や意味的な関連性を理解することを促します。
擬似ラベルの自動生成
事前タスクの大きな特徴は、その「教師信号」、すなわち「擬似ラベル」が人間による手作業なしに、入力データ自身の特定の属性から自動的に生成される点です。例えば、画像の回転角度がそのまま擬似ラベルになったり、同じデータから異なる方法で生成された2つのビューの一貫性を最大化することが擬似ラベルとして機能したりします。これにより、大規模なデータセットであっても、アノテーションにかかる時間やコストを大幅に削減できます。
下流タスクへの転移と利点
事前学習によって獲得された汎用的な特徴表現は、その後、画像分類、音声認識、推薦システムなど、特定の目的を持つ下流タスクに応用されます。この「転移学習」のアプローチには、いくつかの大きな利点があります。
- 高速な収束: 大規模な未ラベルデータで事前学習されたモデルは、良い初期化点となるため、ターゲットとなるタスクでの学習(ファインチューニング)をより速く収束させることが可能です。
- 過学習の軽減: 限られたラベル付きデータしかない場合でも、事前学習によって学習済みの判別しやすい特徴を用いることで、過学習(オーバーフィッティング)を軽減し、よりロバストなモデルを構築できます。
- 汎用性の高いモデル: 事前学習によってデータが持つ本質的な構造を捉えることで、特定のタスクに特化しすぎず、多様なタスクに適用可能な汎用性の高いAIモデルの構築が可能になります。
この基本的な枠組みを理解することで、自己教師あり学習がいかにしてデータアノテーションの課題を克服し、効率的かつ強力なAIモデル開発を可能にするかが見えてきます。
自己教師あり学習の主要アプローチ
自己教師あり学習(SSL)は、人間によるアノテーションを不要にするその特性から、多様なアプローチが研究されています。ここでは、主要な学習パラダイムとその特徴を簡潔にまとめます。
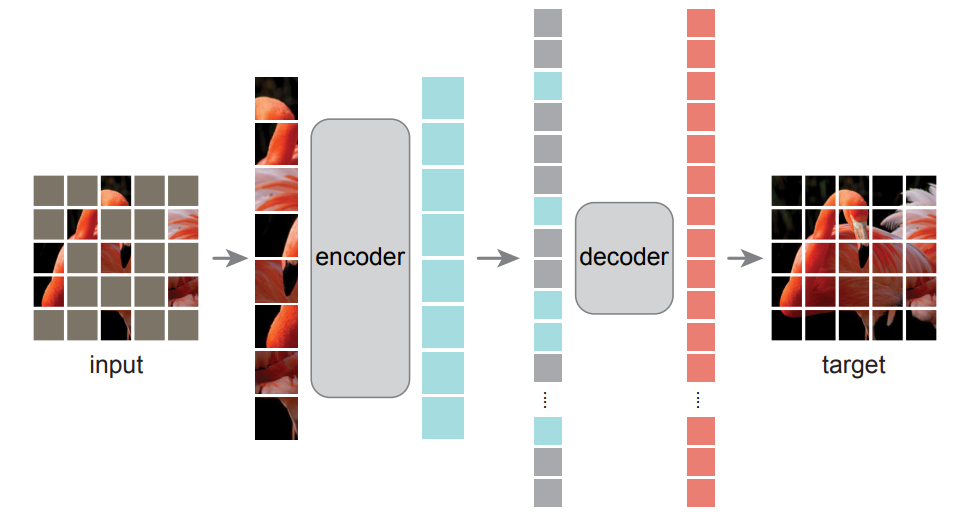
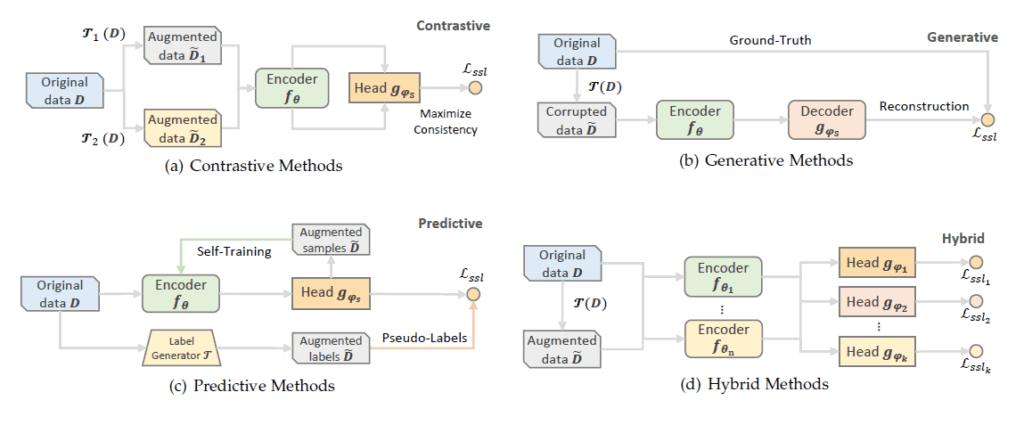
1. 生成ベース(Generative Methods)
生成ベースのSSLは、入力データが持つ隠れた構造を理解し、その表現を学習することを目的としています。具体的には、元のデータに意図的に破損(ノイズ付加、一部のマスクなど)を与え、そこから元のデータを再構築するようモデルを訓練します。これにより、モデルはデータの包括的な理解を深めます。
- 仕組み: エンコーダーが入力データを潜在表現に変換し、デコーダーがその潜在表現から元の(またはクリーンな)データを再構築します。この再構築誤差を最小化するように学習を進めます。
- 代表例:
- Masked Autoencoders (MAE): このアプローチは、画像や時系列データの一部を意図的にマスクし、残りの部分からマスクされた部分を予測・再構築します。特にVision Transformers (ViTs)と組み合わせて用いられることが多く、非常に高いマスキング率(例えば75%)でも効果的に機能し、大規模モデルの効率的な学習を可能にします。
- Word2Vec / BERT: 自然言語処理(NLP)分野では、Word2Vecのように文脈語から単語を予測したり、BERTのように文章の一部をマスクしてそれを予測するような手法も、生成ベースの一種として分類されます。
- 利点: データ構造の深い理解を促し、欠損値補完や新しいデータ生成にも応用可能です [ユーザー提供情報]。特に画像や動画、時系列データにおいて、強力な特徴表現を学習する上で優れた性能を示しています。また、限られたデータしかないシナリオにおいても効果的であるとされています。
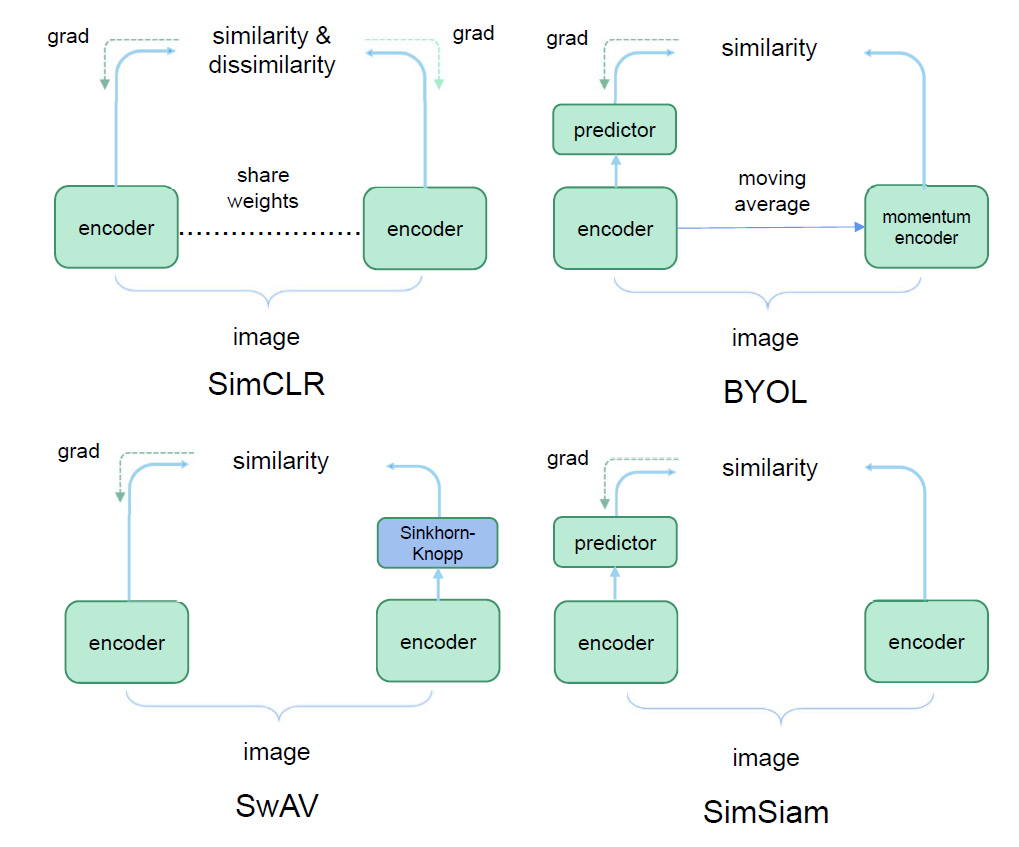
2. 対照ベース(Contrastive Learning: CL)
対照ベースのSSLは、「似ているべきもの」は近く、「似ていないべきもの」は遠くという直感に基づいて、データの識別的な特徴表現を学習します。
- 仕組み: 同じデータポイントから異なるデータ拡張(例:ランダムクロップ、色調変更、ガウスぼかしなど)を適用して複数の「ビュー」を生成します。これらのビューをポジティブペア(互いに似ているべきデータポイント)とし、異なるデータポイントから生成されたビューをネガティブペア(似ていないべきデータポイント)と定義します。モデルはポジティブペア間の類似性を最大化し、ネガティブペア間の類似性を最小化するように訓練されます。
- 代表例:
- SimCLR: 強力なデータ拡張戦略と大規模なミニバッチを活用し、同じ画像から生成された異なるビューをポジティブペアとして、それ以外のミニバッチ内のサンプルをネガティブペアとして扱います。
- MoCo: メモリキューとモメンタムエンコーダーを利用することで、大規模なバッチサイズに依存せず、効率的に多数のネガティブサンプルを管理します。
- BYOL: ネガティブサンプルを明示的に使用せず、2つのネットワーク(オンラインネットワークとターゲットネットワーク)がお互いの出力を予測し合うことで学習を進めます。ターゲットネットワークはオンラインネットワークの重みの移動平均として更新されます。
- 利点: 非常に識別的な特徴表現を学習するのに効果的です。これにより、画像分類やクラスタリングなど、多くの下流タスクで高い性能を発揮します。データ量の増加に伴って性能が大幅に向上することが示されており、スケーラビリティに優れています。
3. 予測ベース(Predictive Methods)/コンテキストベース(Context Based)
予測ベースのSSLは、データの一部から別の部分を予測することで、そのデータが持つ隠れた構造やパターンを学習します。
- 仕組み: モデルは入力データ内の特定のコンテキストに基づいて、将来のデータ、欠損しているデータ、または関連する属性を予測するように訓練されます。これにより、モデルはデータ内の依存関係やシーケンスパターンを把握します。
- 代表例:
- Contrastive Predictive Coding (CPC): 特に音声や時系列データにおいて、過去のデータコンテキストから未来のサンプルを潜在空間で予測する手法です。予測の際に、予測されたサンプルを他のランダムなサンプルと対比させる(対照学習の要素を取り入れる)ことで、より情報量の多い表現を獲得します。
- Word2Vec: 文脈単語からターゲット単語を予測するContinuous Bag-of-Words (CBoW)や、ターゲット単語から文脈単語を予測するSkip-gramなどもこの範疇に含まれます。
- 回転予測(RotNet): 画像の回転角度を予測する事前タスクも予測ベースの例です。これにより、モデルは画像の内容を理解しないと正しい回転角度を予測できないため、汎用的な視覚特徴を学習します。
- 利点: 特に系列データの時間的な依存関係や構造を学習するのに有効です。時系列データにおいては、異常検知や予測タスクに非常に適したアプローチとされています。

4. ハイブリッドアプローチ(Hybrid Methods)
ハイブリッドアプローチは、上記の複数のSSL戦略を組み合わせて使用することで、それぞれの長所を活かし、よりロバストで汎用的な特徴学習を実現します。これは、複数の事前タスクを同時に最適化するマルチタスク学習の一種と考えることができます。
- 仕組み: 例えば、生成ベースの再構築タスクと対照ベースの識別タスクを組み合わせることで、データの局所的な詳細と大域的な意味的関係の両方を学習させることができます。
- 代表例:
- GCMAE (Global Contrast Masked Autoencoder): 画像の一部をマスクして再構築するMasked Autoencoder (MAE)と、グローバルな対照学習を組み合わせることで、病理画像から局所的特徴と大域的特徴の両方を効率的に抽出します。
- ESLA (Enhanced SSL with Masked Autoencoders) や HSL (Hybrid SSL Framework): これらもMAAEと対照学習を統合し、データ拡張中の競合する特徴の問題に対処しつつ、モデルの汎化能力と表現学習能力を向上させます。
- クロスモーダル学習: 動画と音声、または動画とテキストなど、異なるモダリティ間の同期や対応関係を予測するタスクを対照学習と組み合わせることで、より豊かなマルチモーダル表現を学習します。
- 利点: 個別のアプローチでは捉えきれない複雑なデータ特性を学習できる可能性があります。複数の教師信号を利用することで、より包括的な自己教師を提供し、スケーラビリティと下流タスクでの性能向上が期待できます。
様々なモダリティにおける事例
自己教師あり学習(SSL)は、人間によるアノテーションの必要性を低減するというその本質から、多岐にわたるデータモダリティに応用され、各分野の課題解決に貢献しています。ここでは、業務で直面する可能性のある具体的なデータタイプに焦点を当て、SSLの主要な応用例とそのメリットを説明します。
1. 音声データ (Audio SSL)
音声データは、話者の多様性、環境ノイズ、言語の違いなど、現実世界に内在する多くの不確実性により、深層学習手法の適用が特に困難なモダリティの一つです。しかし、SSLはこのような課題に対し、汎用的な特徴表現の学習を通じて有効な解決策を提供しています。
- 応用例:
- 自動音声認識(ASR)
- 話者識別
- 音声感情認識
- 音響シーン分類
- 音声分離
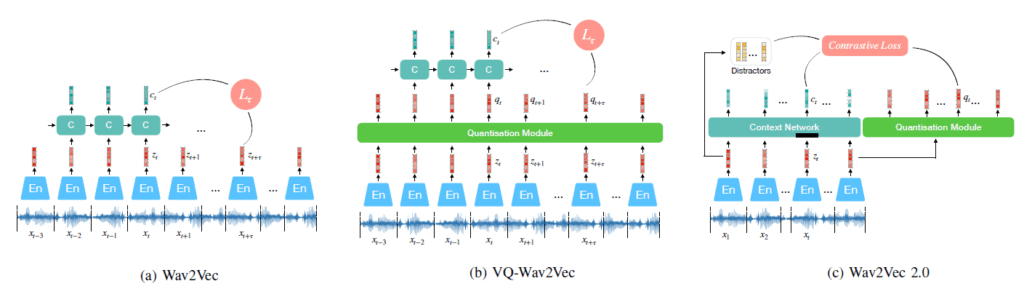
- Wav2Vec 2.0:
- SSLの代表的な成功例であり、ASRタスクにおいて教師あり学習手法の性能を上回る結果を示しました。
- 生の音声波形を直接入力とし、特定のタスクを意識しない潜在表現を学習します。これにより、手作業での特徴抽出(hand-crafted, engineered features)の必要性を大幅に低減し、表現の汎化能力を向上させます。
- InfoNCE損失を用いた対照学習(Contrastive Learning)フレームワークであり、1次元CNNとTransformerを組み合わせたアーキテクチャを採用しています。
- 利点:
- ラベル付けの困難さや、話者間のばらつき、ノイズなどの不確実性が特徴の音声データから、汎用的な表現を効率的に学習できるため、様々な下流タスク(例: 異常検知、音声合成など)への応用が期待されます。
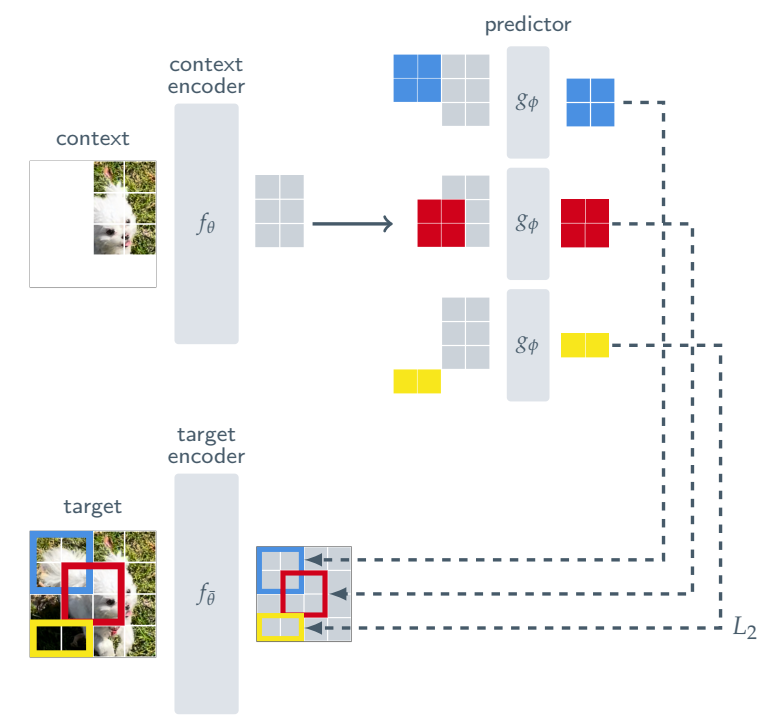
2. 画像・動画データ (Vision/Video SSL)
画像や動画は、コンピュータビジョン(CV)分野においてSSLが最も早くから大きな成功を収めてきたモダリティです。特に、動画データはその時間的な要素が加わるため、画像ベースの手法を単純に拡張するだけでは解決できない固有の課題が存在します。
- 応用例:
- アクション認識
- 画像/動画キャプション生成
- 物体検出 および 意味的セグメンテーション
- 動画の再生速度分類 や時間順序検証 など、時間的な理解を要するタスク。
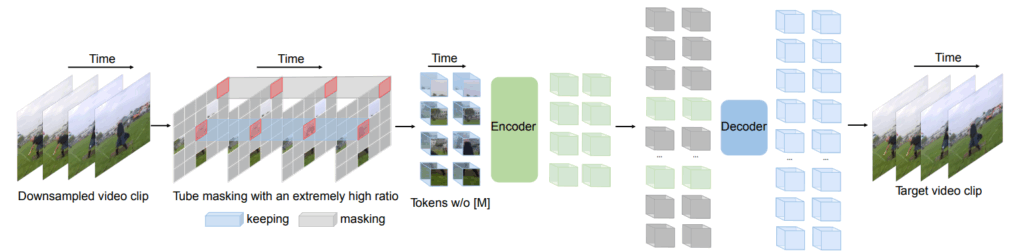
- VideoMAE (Masked Autoencoders for Video):
- 画像領域で成功したMasked Autoencoders (MAE) の動画版です。
- 動画の時空間パッチの一部を意図的にマスクし、残りの部分からマスクされた部分をピクセルレベルで再構築することで、動画理解のための強力な表現を学習します。
- Vision Transformer(ViT)をバックボーンとして採用し、特に動画の時間的な要素の学習に重点を置いています。
- RGBフレームとモーションだけでなく、オーディオやテキストなどの追加モダリティを用いることで、学習された特徴の汎化能力がさらに向上することが示されています。
- 利点:
- 大規模な教師なし動画データから、アクション認識などの下流タスクに直接利用できる汎用的な表現を学習できるため、アノテーションにかかる時間とコストを大幅に削減します。
3. 推薦システム (Self-Supervised Recommendation, SSR)
推薦システムは、ユーザーにパーソナライズされたアイテムを提案する上で、データスパース性(データがまばらで不足している問題)という深刻な課題に直面しています。SSLは、この課題を克服し、推薦品質を向上させるための有望な技術として注目されています。
- 応用例: ユーザーへのアイテム推薦。
- 課題解決:
- 推薦システムにおけるデータスパース性の解決に大きく貢献します。
- SSLは、アノテーションされたデータに対する推薦システムのニーズと非常によく合致しています。
- 仕組み:
- ユーザーとアイテムの相互作用グラフやシーケンスデータに対し、様々な自己教師ありタスク(pretext tasks)を適用します。
- 生成ベース: BERTから着想を得たBERT4Rec のように、破損した入力(例: マスクされたアイテム)から元のプロファイルを再構築します。
- 対照ベース: データ拡張によって生成された異なる「ビュー」間で類似性を最大化することで、識別的な特徴表現を学習します。
- 予測ベース: 現在のエンコーダーパラメータに基づいて情報量の多いサンプルを予測したり、ジェネレーターを介して擬似ラベルを生成し、エンコーダーをガイドします。
- 利点:
- 少量のラベル付きデータでも良好な推薦結果を生成できる、効率的なモデルの学習を可能にします。
- 軽量なアーキテクチャでも推薦性能を向上させることができるため、実用的なシステム構築に適しています。
4. 表形式データ (Tabular Data SSL)
表形式データは、画像や音声のような空間的・時間的な明示的構造を持たないため、SSLの適用が特に難しい領域とされてきました。各列が独自の機能を持つため、その関係性を学習することは困難です。
- 特徴:
- 非シーケンシャルな表形式データ(Non-Sequential Tabular Data, NS-TD)は、他のモダリティのような明示的な構造や関係性を持たないため、SSLの適用が特に難しい領域です。
- 応用例:
- 金融分野における不動産評価など、ドメイン知識に基づく事前タスクを設計することで、実用的な問題に応用されています (ソースには直接的な例示はありませんが、SSLが医療やリモートセンシングなど様々な分野で活用されていることから、その汎用的な応用可能性は示唆されています)。
- 一般的な予測型SSLでは、マスクされた特徴の予測や、潜在空間での摂動、事前学習済み言語モデルの内部構造を利用するなどの方法が提案されています。
- SCARF:
- 特徴のランダムな破損を利用した対照学習という概念は、表形式データにおける予測学習のアプローチの一つとして有効です。これにより、様々な表形式ドメインへの汎化能力を強化できると考えられます。
- 利点:
- ラベル付けが困難な実世界の表形式データから、有用な特徴を自動抽出する可能性を秘めています。
- 少量のラベル付きデータしかないシナリオや、機械学習・深層学習モデルが性能を発揮しにくい低リソース環境においても、堅牢な性能を発揮します。
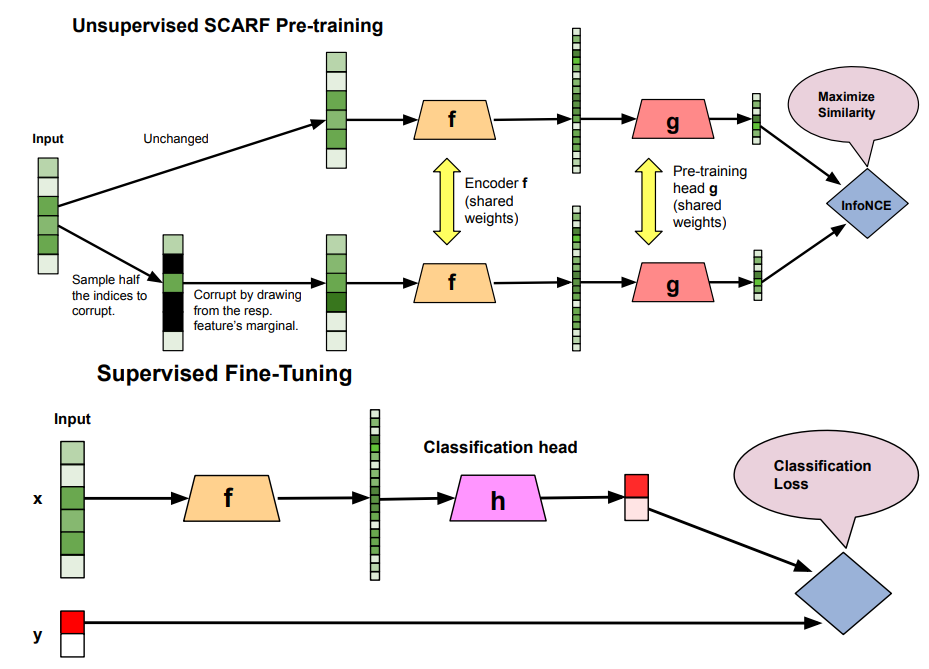
5. グラフデータ (Graph SSL)
グラフデータは、ノードとエッジによって表現される複雑な関係性を持つ構造データであり、ソーシャルネットワークから分子構造まで、多岐にわたる分野で利用されています。SSLは、このグラフ構造の深い理解を要するタスクにおいて、大きな可能性を秘めています。
- 応用例:
- ソーシャルネットワーク分析、分子構造予測、推薦システム、不正検出など、複雑な関係性を持つグラフ構造データに幅広く応用されます。
- ノード分類、リンク予測、グラフクラスタリング など、多岐にわたる下流タスクに適用可能です。
- 仕組み:
- SSLは、ノード特徴の予測、リンク予測、グラフのグローバル構造の識別など、グラフ固有の知識を活用した事前タスクを通じて学習が行われます。
- グラフオートエンコーディング(GAE)の手法では、低次元のノード表現を再構築し、元の特徴サイズと一致させることで再構築誤差を最小化します。
- 対照学習は、ノードレベルおよびグラフレベルで、ポジティブペアとネガティブペア間の類似性を最大化/最小化することで、識別的な表現を学習します。
- 近年では、大規模言語モデル(LLM)とグラフニューラルネットワーク(GNN)を統合したグラフ言語モデル(GLM)も開発されており、言語モデリング(自己回帰およびマスク言語モデリング)とグラフの事前学習を組み合わせることで、グラフタスクにおけるLLMの能力を向上させています。
- 利点:
- グラフ構造の深い理解を要するタスクにおいて、手動での特徴設計なしに高性能なモデルを構築できるため、複雑なデータからの知見抽出を加速します。
- 教師なしデータから文脈的かつ堅牢な表現を学習し、汎化能力を高めます。

実践によるメリット
自己教師あり学習(SSL)は、特に大規模なラベル付きデータセットの必要性という課題に対する強力な解決策として注目されています。人間の認知能力に触発され、人手によるアノテーションを必要とせずに、大規模なデータから汎用的な表現を学習することを目的としています。
SSLを日常の開発に取り入れることで、以下のような具体的なメリットが期待できます。
- アノテーションコストと時間の劇的な削減:
教師あり学習アルゴリズムの成功は、通常、アノテーションに多大な労力を要する大規模なデータに依存しています。特にビデオデータの場合、アノテーションの取得は費用が高く、多大な労力を必要とするため、課題となります。SSLは、人手によるアノテーションを必要とせずに大規模なデータから汎用的な表現を発見することを目指しており、これは費用と時間がかかるタスクです。SSLは、手動のラベルへの依存を減らし、アノテーションのボトルネックを解消するために、大量のラベルなしデータでのトレーニングを可能にします。例えば、100万を超える高品質な画像セグメンテーションデータセットの構築には数百万ドルかかる可能性があり、このプロセスは時間と非効率性が伴います。SSLはデータ自体に内在する関係性を活用することで、手動ラベリングの必要性を排除し、モデルトレーニングのためのスケーラブルでリソース効率の高い代替手段を提供します。 - 汎化能力の向上:
SSLは、学習した知識やスキルを異なるコンテキストの理解に応用する能力である「汎化」につながる動的な構造を作成します。SSLは、学習した表現が十分な汎化能力と識別性を持つことを保証します。人為的に生成されたアノテーションは、バイアスのかかった学習や、ドメイン汎化能力とロバスト性の低下につながる可能性がありますが、SSLはアノテーションを必要としない表現学習の方法を提供します。SSLによって事前学習されたモデルは、少量のラベル付きデータでも満足のいく性能を達成できることが示されており、未知のドメインやタスク、限られたラベル付きデータしかないシナリオにおいてもモデルの性能を高く維持できます。特にVision Transformer(ViT)においては、SSLは大量のラベルなしデータを活用し、ロバストで汎化可能な特徴表現を育成することを可能にします。 - データ効率の改善:
SSLを利用することで、下流タスクでのモデルのファインチューニングに必要なラベル付きデータの量が大幅に減少します。SSLは、手動アノテーションのコストを削減しつつ、汎化能力を提供することでデータ効率を向上させます。事前学習とファインチューニング戦略に基づき、たとえ少量のラベル付きデータであっても、高い性能を達成できる可能性があります。特にラベル付きデータが限られているか、収集が困難な状況では、SSLは教師あり学習モデルと同等かそれ以上の性能を達成する可能性を示しています。これは、手動でのデータアノテーションが現実的ではないが、高性能なコンピュータービジョンモデルが必要な実際のシナリオにおいて特に価値があります。 - ロバスト性の強化:
SSLは、データから十分に汎化され、識別性のある表現を抽出することを保証し、データに内在するノイズや摂動に対するモデルの頑健性を向上させる可能性があります。自己教師あり学習の利用は、モデルのロバスト性と不確実性を向上させることが示されています。特に多モーダル表現のロバスト性向上において、SSLは有望な結果を示しています。Vision Transformer(ViT)のコンテキストでは、SSLは、手動ラベリングを必要とせず、データ内の固有の関係性を活用することで、ロバストで汎用的な特徴表現を獲得することを可能にします。SSLのデータ拡張戦略は、モデルがラベルなしデータからよりロバストで汎化可能な表現を獲得するのに役立ちます。 - モデルの初期化:
SSLパラダイムは、まずある先行タスク(Pretext Tasks)を解くことでユニバーサルな表現を生成できるモデルを学習することを目指します。この先行タスクで生成された事前学習済みモデルは、新しいデータを理解するために特徴表現を抽出するために使用されます。次に、認知発達と同様に、事前学習済みモデル(以前の知識)の汎化を通じて新しいコンテキストを理解するために使用するプロセスとして「下流タスク」が存在します。大規模なラベルなしデータで事前学習されたモデルは、ファインチューニング時の良好な初期値を提供し、学習の高速化と収束の安定化に寄与します。
課題と今後の展望
自己教師あり学習(SSL)は、機械学習の分野で目覚ましい進歩を遂げていますが、その実用化とさらなる発展には、いくつかの課題と今後の研究方向性が存在します。
現在の課題
- 計算リソースの要求:
大規模なデータセットを用いた事前学習プロセスは、依然として莫大な計算資源を必要とします。特に、Siamese Network(シャムネットワーク)のような2つのエンコーダーを使用するモデルは、そのアーキテクチャの特性上、高い計算負荷を伴います。高品質な画像セグメンテーションデータセットの構築に数百万ドルかかる場合があるように、データアノテーションにかかる費用と時間は非常に高額で、非効率的です。SSLは手動ラベリングの必要性を減らすことで、この課題を緩和しますが、学習自体には依然として大規模なリソースが必要です。 - 事前タスクとデータ拡張の選択:
特定のデータセットや下流タスクに最適な事前タスクやデータ拡張戦略の選択は、未だに経験的な試行錯誤に依存している部分が大きいです。例えば、画像データではランダムクロップと色歪みの組み合わせが効果的であることが示されていますが、時系列データでは、回転やクロップがデータの時間的依存関係を破壊する可能性があるため、慎重な設計が必要です。時系列データにおいては、最適なデータ拡張方法やその組み合わせを特定するための合理的な評価フレームワークの構築が今後の課題として挙げられます。非シーケンシャルな表形式データでは、特定のシナリオに適したSSL手法やハイパーパラメータ(例:マスキング比率、バッチサイズ)の選択は依然として不明瞭です。 - 解釈可能性:
SSLによって学習された特徴表現が具体的に何を捉えているのか、特にマルチモーダルな設定において、その内部動作を完全に理解することはまだ難しい課題です。SSLモデルの性能評価は通常、下流タスクでの性能によって行われますが、これはモデルが具体的に何を学習したかについての洞察を提供しません。異なるSSLアルゴリズムをどのように理解し、統一するかという理論的な課題も残されており、表現が十分な汎化能力と識別性を持つことを保証しつつ、その内部メカニズムを解明する包括的な理論的枠組みの発展が求められています。
将来の方向性
- よりシンプルでエンドツーエンドなアプローチ:
大規模な事前学習済みバックボーンモデルへの依存を減らし、計算コストを削減するための研究が進められています。BYOL、SimSiam、Barlow Twinsといった非対照的SSL手法は、負例を必要とせずに競争力のある、あるいはそれ以上の性能を達成できることが示されており、より完全な情報を表現に組み込む可能性を秘めています。これらのアプローチは、モデルトレーニングの簡素化と効率化に貢献します。 - マルチモーダルな大規模基盤モデル:
異なるモダリティ(例:動画、音声、テキスト)を統一的に学習し、汎用的な基盤モデルを構築する研究が活発です。動画アノテーションの困難さや、異なるモダリティ間の相互補完性を考慮し、自己教師ありマルチモーダル学習(SSML)は、人手によるアノテーションなしで大規模なマルチモーダルデータから学習する強力な手段となります。大規模言語モデル(LLM)の発展は、自己教師あり学習を介したマルチモーダルLLMの拡大を後押ししており、統一されたアーキテクチャや目的関数の設計が、様々なモダリティに対応できる適応性の高いモデルの実現を促進します。 - ノイズへの頑健性:
ウェブから収集されることが多いノイズの多いペアデータからの学習に対する頑健性の研究が重要です。人間がアノテーションしたデータにはバイアスが含まれる可能性があり、それがモデルの汎化能力やロバスト性を低下させることもあります。SSLはモデルのロバスト性を向上させる可能性を秘めていますが、ノイズ耐性の限界を理解し、高品質なデータを効率的に識別・利用するデータフィルタリング手法や、データ拡張戦略の開発が不可欠です。 - 長期的な時系列・動画表現の学習:
短いクリップだけでなく、より長い時間コンテキスト全体から表現を学習するアプローチが求められています。動画データの時間的次元は、モーションや環境ダイナミクスを伴うため、特徴学習をより複雑にします。時系列データもまた、季節性、トレンド、周波数ドメインといった独自の特性を持ちます。過去の時系列データから未来のパターンを予測する自己回帰型予測のようなタスクや、時間的な関係性をマイニングするアプローチは、長期的な依存関係を捉える上で有効です。将来の研究では、これらのデータの固有のバイアスをSSLに組み込むことで、より深い理解と汎化能力を持つ表現の学習が期待されます。
おわりに
自己教師あり学習(SSL)は、AI開発におけるデータ収集とモデル学習のパラダイムを大きく変革しています。手動アノテーションの費用と時間を大幅に削減しつつ、大規模なラベルなしデータから普遍的で汎用的な特徴表現を学習する強力な手段となります。実務者がSSLの原理と手法を理解し、自身のプロジェクトに導入することで、開発プロセスを効率化し、限られたラベル付きデータでも高性能で頑健なAIシステムを構築できるでしょう。今後もSSLは、マルチモーダル学習や多様なデータタイプ(時系列、表形式など)への適用を通じて進化を続け、AIの新たな可能性を切り開いていくと期待されます。
More Information
- arXiv:2203.01205, Shuo Liu et al., 「Audio Self-supervised Learning: A Survey」, https://arxiv.org/abs/2203.01205
- arXiv:2203.15876, Junliang Yu et al., 「Self-Supervised Learning for Recommender Systems: A Survey」, https://arxiv.org/abs/2203.15876
- arXiv:2207.00419, Madeline C et al., 「Self-Supervised Learning for Videos: A Survey」, https://arxiv.org/abs/2207.00419
- arXiv:2301.05712, Jie Gui et al., 「A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends」, https://arxiv.org/abs/2301.05712
- arXiv:2304.01008, Yongshuo Zong et al., 「Self-Supervised Multimodal Learning: A Survey」, https://arxiv.org/abs/2304.01008
- arXiv:2306.10125, Kexin Zhang et al., 「Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects」, https://arxiv.org/abs/2306.10125
- arXiv:2402.01204, Wei-Yao Wang et al., 「A Survey on Self-Supervised Learning for Non-Sequential Tabular Data」, https://arxiv.org/abs/2402.01204
- arXiv:2403.16137, Ziwen Zhao et al., 「A Survey on Self-Supervised Graph Foundation Models: Knowledge-Based Perspective」, https://arxiv.org/abs/2403.16137
- arXiv:2408.17059, Asifullah Khan et al., 「A Survey of the Self Supervised Learning Mechanisms for Vision Transformers」, https://arxiv.org/abs/2408.17059
関連記事

Mixture of Experts (MoE) - 混合専門家モデルとは何か?
大規模言語モデル(LLM)は、自然言語処理からコンピュータビジョン、さらにそれ以上の領域に至るまで、様々な分野で大きな進歩を遂げています。LLMの驚異的な能力は、そのモデルサイズ、多様なデータセット、そしてトレーニング中 […]

「AI Agent vs. Agentic AI」: AIの進化形態を徹底解説
AI技術は目覚ましい進化を遂げ、今やビジネスに深く浸透しています。日々の定型業務の自動化から、データに基づいた戦略立案に至るまで、AIはもはや欠かすことのできないツールと言えるでしょう。 このような中、最近「AI Age […]

コンテキスト・エンジニアリングの構造化手法
AIを使っていて、「期待した結果が返ってこない」、「何度もやり取りを繰り返してしまう」と感じたことはないでしょうか。多くの場合、その原因は「プロンプトの書き方」ではなく、AIに与える「コンテキスト(背景情報)の不完全さ」 […]