Reranking モデルの進化: 古典的手法から大規模言語モデルまで

現代のデジタル社会において、情報を的確に見つけ出す 情報検索(IR: Information Retrieval)システムは、検索エンジンから知識管理プラットフォームに至るまで、欠かせない存在です。特に、大規模言語モデル(LLM)を活用した RAG(Retrieval Augmented Generation: 検索拡張生成) の普及により、その重要性はさらに高まっています。
こうしたシステムで回答の精度を左右するのが「Reranking(リランキング/再順位付け)」という工程です。RAG パイプラインにおいて、検索ステップで抽出されたドキュメントの精度は、最終的な回答の質に直結します。初期の高速な検索で得られた膨大な候補を Reranker(リランカー)が精査し、真に関連性の高い順に並べ替えることで、システムの出力品質は劇的に向上します。
今回は、初期の統計的な手法から最新の LLM ベースの手法に至るまでの進化の軌跡と、実用化に向けたヒントを詳しく解説します。
1. Reranking の基本概念と役割
RAG(検索拡張生成)パイプラインにおいて、Reranking(再順位付け)は「検索(Retrieval)」と「生成(Prompt/Output)」の間に位置する極めて重要なコンポーネントです,。下図に示されるように、ユーザーのクエリに対してドキュメントを収集した後、LLMに渡す直前のプロセスとして配置されます,。
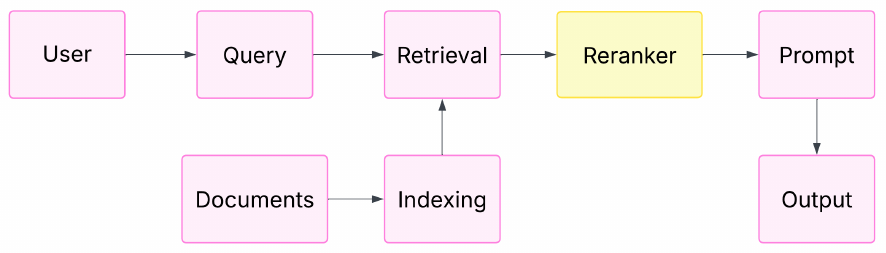
Reranking の主な目的は、初期の検索ステップで得られた膨大な候補ドキュメント群の中から、LLMが正確な回答を生成するために真に必要なコンテキストを精査し、絞り込むことです。通常、初期の検索フェーズでは速度を優先して広範な候補を収集するため、結果にはノイズが含まれがちです。Reranker はこれらの候補をより詳細に評価し直し、最も関連性の高い情報を上位に並べることで、システム全体の精度を最大化する役割を担っています。
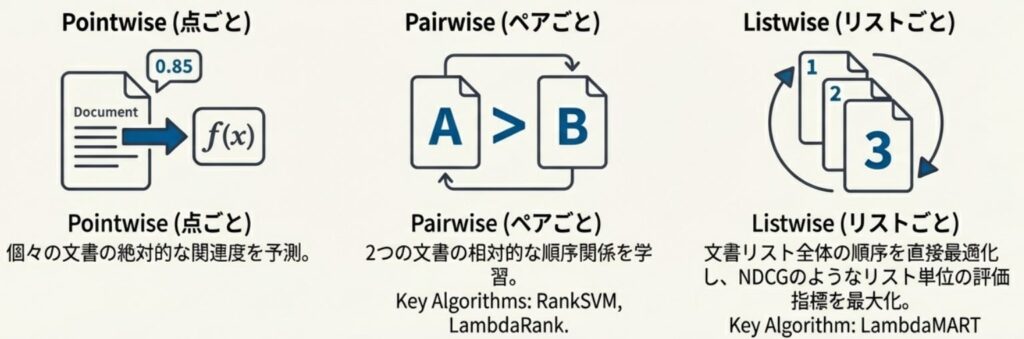
この「どのように並び替えるか」という評価戦略には、機械学習の LTR (Learning to Rank) という分野で培われた、主に以下の3つのアプローチが存在します。
- Pointwise(ポイントワイズ):
各ドキュメントを1つずつ独立して評価する手法です。特定のクエリに対して、そのドキュメントがどれだけ関連しているかを分類や回帰によってスコアリングし、その値に基づいて並び替えを実施します。シンプルで計算コストも抑えられますが、ドキュメント同士の相対的な関係を考慮できないという課題があります。 - Pairwise(ペアワイズ):
2つのドキュメントをペアにして比較し、どちらがより関連しているかを判断する手法です。ドキュメント間の相対的な順序を学習できるため、Pointwise よりも精緻なランキングが期待できます。 - Listwise(リストワイズ):
ドキュメントのリスト全体を一度に考慮し、最適な並び順を直接最適化する手法です。リスト内のドキュメント同士の相互関係を最も深く捉えることができるため、非常に高い精度を実現できるアプローチとして知られています。
これらの基礎的な概念は、単なる数値計算から始まり、現在のDeep Learningや LLM を活用した高度な意味理解へと進化する過程で、常に重要な指針となっています。
2. Deep Learning による精緻な意味理解
2010年代半ばから、Deep Learning の台頭により Reranking 技術は劇的な進化を遂げ、クエリとドキュメント間の複雑な意味的関係を捉えることが可能になりました。これまでの統計的手法から、ニューラルネットワークを用いたより高度な表現学習へとシフトしたのです。
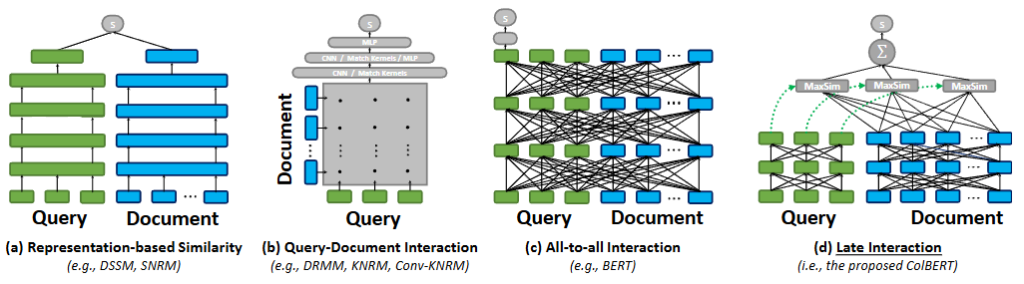
Cross-Encoder による深い相互作用
この分野で中心的な役割を果たしたのが、BERT を代表とする Cross-Encoder(クロスエンコーダー) です。Cross-Encoder は、クエリとドキュメントを一つのペアとして同時にエンコードするアーキテクチャを採用しています。
- トークンレベルの相互作用: Transformer の自己注意機構(Self-Attention)を活用することで、クエリ内の各単語とドキュメント内の各単語がどのように関連しているかをトークン単位で詳細に分析します。
- 高精度なスコアリング: この深い相互作用により、単なるキーワードの一致を超えた精緻な適合性スコアを算出できるのが最大の特徴です。
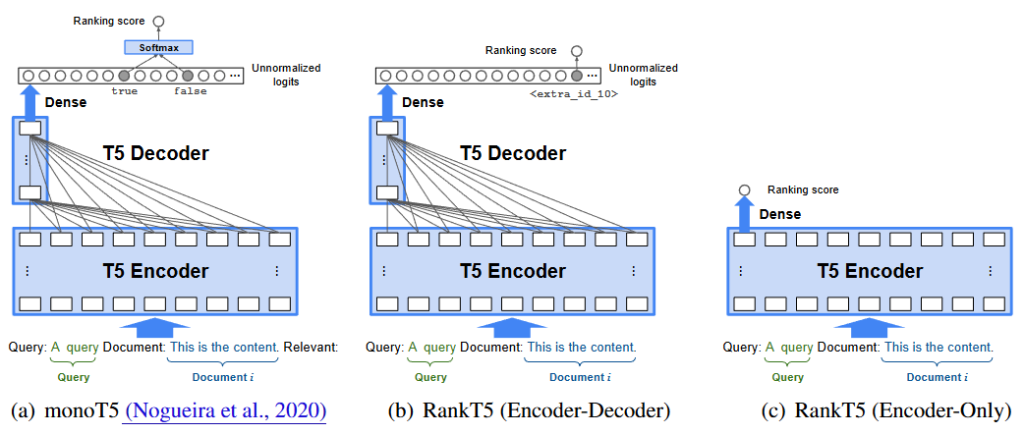
「生成」としてランキングを解く T5
続いて登場したのが、T5 (Text-to-Text Transfer Transformer) のような 生成型 Reranker(Sequence-to-Sequence モデル) です。この手法では、ランキングを「テキストからテキストを生成するタスク」として再定義します。
- 適合性の判別: クエリとドキュメントのペアを入力し、モデルにそれが関連しているかどうかを「True(真)」か「False(偽)」というテキストで出力させます。
- 確率の活用: 実際に順位を付ける際は、モデルが「True」という単語を生成する確率(対数尤度)を適合性スコアとして利用します。これにより、大規模な事前学習によって得られた豊かな言語理解能力を、そのままランキング精度に転換できるという利点があります。
効率性とレイテンシのトレードオフ
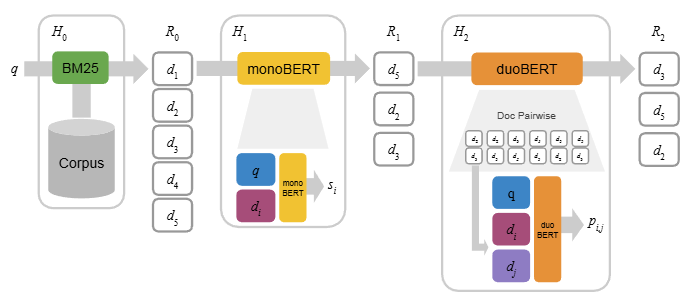
これらのDeep Learning モデルは非常に高い精度を誇る一方で、実運用における計算コスト(レイテンシ)の増大という大きな課題を抱えています。特に Cross-Encoder は、検索された全ての候補ペアに対して重い推論を実施する必要があるため、リアルタイム性が求められるシステムではボトルネックになりがちです。
この課題に対する有力な解決策が、ColBERT に代表されるアーキテクチャです。ColBERT は「Late Interaction(遅延相互作用)」という仕組みを導入し、クエリとドキュメントを独立してエンコードしながらも、トークン間の類似度を効率的に計算します。これにより、ドキュメント側の計算を事前に実施(Precomputation)しておくことが可能となり、精度を維持しつつ検索速度を大幅に向上させています。また、まずは高速な検索で少数の候補に絞り込み、その後に強力なモデルで再評価を実施する「多段パイプライン」の検討も、実務では非常に重要です。
3. LLMベースの Reranker とその革新
LLM(大規模言語モデル)の急速な進化は、Reranking の手法にもパラダイムシフトをもたらしました。その中心にあるのが、個別のドキュメントにスコアを付けるのではなく、与えられたドキュメントのリスト全体を一括で評価して並べ替える Listwise Reranking です。
指示(Prompting)によるゼロショットの実現
これまでの手法では、特定のタスクに合わせてモデルを学習(Fine-tuning)させる必要がありました。しかし、RankGPT に代表される LLM ベースの Reranker は、適切な「指示(Prompt)」を与えるだけで、追加学習なしのゼロショットで高度な並べ替えを実施できます。これにより、エンジニアは専用モデルを構築する手間をかけずに、最新の LLM(GPT-4 など)が持つ深い意味理解能力を検索システムに即座に取り入れることが可能になりました。
あなたには、大規模検索エンジンにおける再ランキング(re-ranking)を担当してもらいます。
ユーザの検索意図を正確に理解し、意味的な関連性を最優先して文書を順位付けしてください。
以下の検索クエリに対して、最も関連性の高い文書から順に文書IDを並べ替えてください。
出力は文書IDの順序のみとし、追加の説明は行わないでください。
[検索クエリ]
生成AIを用いた情報検索におけるランキング手法
[文書]
(A) BM25を用いた従来型検索アルゴリズムの評価。
(B) ChatGPTを用いた検索結果の再ランキング手法(RankGPT)の提案。
(C) 生成モデルによる文章要約の最新手法。
(D) Transformerを用いた文書分類タスクの応用例。「スライディングウィンドウ」による制約の克服
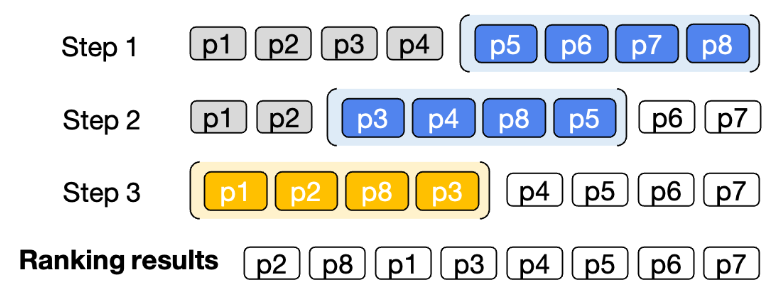
LLM を Reranker として使用する際の最大の課題は、一度に入力できる文字数(コンテキスト長)の制限です。検索された膨大なドキュメントを一度にプロンプトへ詰め込むことは、モデルの限界を超えてしまうため現実的ではありません。
この問題を解決するために提案されたのが、スライディングウィンドウ(Sliding Window)という手法です。これは、リストの一部を少しずつずらしながら段階的に評価し、最終的にそれらの結果を統合して全体の順位を決定するアプローチです。この工夫により、LLM の能力を最大限に活かしつつ、大量の候補ドキュメントを効率的に処理できるようになりました。
オープンソースモデルの台頭と効率化
現在では、GPT-4 のようなクローズドなモデルだけでなく、Llama をベースにしたオープンソースの Reranker も登場しています。例えば、RankVicuna は RankGPT を「教師」として学習(知識蒸留)することで、オープンソースでありながら高品質なリストワイズ・リランキングを実現しました。さらに、RankZephyr のように、より少数のパラメータでありながら特定の条件下で GPT-4 を上回る精度を出すモデルも開発されており、実務における選択肢は様々な形に広がっています。
このように、LLM ベースのリランキングは「指示」ひとつで実装できる手軽さと、文脈を深く読み解く圧倒的な精度の高さを両立させ、RAG システムの性能を一段上のレベルへと引き上げています。
4. 知識蒸留による軽量化と最適化
最新の LLM(大規模言語モデル)をベースとした Reranker は圧倒的な精度を誇りますが、実務への導入には大きな壁があります。それは、膨大なパラメータを持つモデルをそのまま推論に使用すると、計算コストや処理待ち時間(レイテンシ)が非常に大きくなってしまうという点です。特にリアルタイム性が求められる高スループットな検索システムにおいて、これは深刻な課題となります。
実用的な解決策としての「知識蒸留」
この課題に対する有力な解決策が、知識蒸留(Knowledge Distillation) という手法です。これは、巨大で高精度なモデル(教師モデル)が持つ知見を、より軽量な小型モデル(生徒モデル)へと継承させる技術を指します。これにより、T5 や LLaMA といったモデルの軽量版をベースにしながらも、巨大な LLM に匹敵する性能を持つ Reranker を構築することが可能になります。
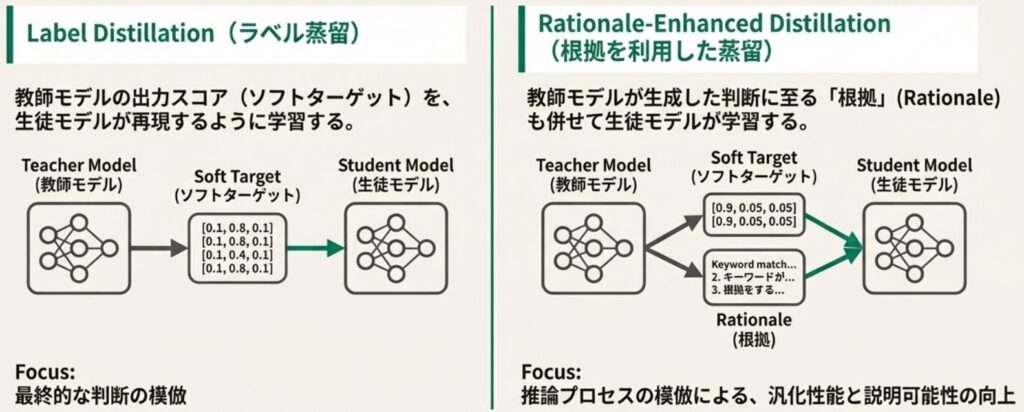
推論能力を継承させる「根拠(Rationale)」の活用
最近の研究では、単に「どのドキュメントが上位か」という結果だけを教えるのではなく、「なぜそのドキュメントが関連しているのか」という思考プロセス(Rationale: 根拠) を学習させる手法が注目されています。
- Rationale-Enhanced Distillation: 教師役の LLM が、特定のクエリとドキュメントのペアに対して関連性の判断根拠を生成します。生徒モデルはこの根拠をセットで学習することで、限られたパラメータ数でも高度な推論能力を獲得できるようになります。
- 精度の逆転現象: 例えば「KARD」という手法で学習した 250M(2.5億)パラメータの T5 モデルは、単純に微調整を実施しただけの 3B(30億)パラメータのモデルを上回る精度を記録したという報告もあります。
- 説明性の向上: 判断の根拠を学習に取り入れることで、従来のブラックボックスなモデルと比べて、なぜその結果になったのかという透明性や説明性も高まります。
実務におけるメリットとモデルの選択肢
蒸留によって最適化されたモデルは、低いレイテンシで動作しながらも、医療や金融といった特定のドメインや高度な知識を必要とするタスクにおいて非常に高い性能を発揮します。現在では、GPT-4 などの知見を蒸留して作られたオープンソースの Reranker も様々な形で提供されており、開発者はコストと精度のバランスを見ながら最適なモデルを選択できるようになりました。
このように、知識蒸留は LLM の知性を「民主化」し、実際のプロダクトに耐えうる速度とコストで、最高峰の検索体験を実現するための鍵となっています。
おわりに
Reranking 技術は、初期の統計的な手法からDeep Learning、そして最新の LLM(大規模言語モデル)へと劇的な進化を遂げてきました。この進化により、単なるキーワードの一致を超えた、文脈に沿った深く複雑な意味的関係を捉えることが可能になっています。一方で、最新のモデルほど計算コストやレイテンシが大きく、リアルタイムでの運用が難しいといった課題や、バイアスの増幅といった実務上の問題も依然として残っています。
これからの検索システム構築においては、LLM が持つ高度な推論能力を活用しつつ、知識蒸留などの手法によって実行効率を最大化し、そのバランスを最適化することが成功の鍵となるでしょう,。効率的でありながら洗練された判断ができるモデルの普及は、より透明で信頼性の高いシステムの実現にも寄与します。
More Information
- arXiv:2512.16236, Tejul Pandit, Sakshi Mahendru, Meet Raval, Dhvani Upadhyay, 「The Evolution of Reranking Models in Information Retrieval: From Heuristic Methods to Large Language Models」, https://arxiv.org/abs/2512.16236
関連記事

ローカルLLMはソフトウェア開発に活用できるのか?
近年、大規模言語モデル(LLM)の進化は目覚ましく、多くの分野でその活用が期待されています。しかし、その強力な性能を享受するには、クラウドベースでの運用が主流であり、API利用コストや外部APIへソースコードを送信するこ […]

KAN: Kolmogorov–Arnold Networks
ディープラーニングモデルの多くは、多層パーセプトロン(MLP)に大きく依存していますが、MLPには、解釈が難しさや、Transformerなどのモデルでは埋め込みパラメータ以外のほぼすべてのパラメータを消費してしまうとい […]

自然言語タスクとプロンプト戦略
今回は、自然言語処理の各タスクについて、有効なプロンプト設計についてまとめていく。まず、代表的なプロンプトテクニックをまとめ、その後タスクごとにどのようなプロンプト戦略が有効か見ていくことにする。 代表的なプロンプトテク […]